
지난 시간에는 크롤링을 위한 준비를 해보는 시간이였다면 이번 시간에는 실질적으로 우리가 html형태로된 웹사이트에서 원하는 정보만 뽑아오는 방법을 함께 알아보려 한다. 어떻게 보면 이번 시간이 실질적인 crawling의 시작이라고 볼 수도 있으니 모두 집중해서 우리가 원하는 정보를 얻어보도록 하자!
준비물 챙기기!

이렇게 입력하고 쉘을 실행하면
이젠 조금 익숙한 빈페이지가 우리를 반겨준다!
내가 정보를 긁어오고 싶은 사이트에 접속하기

지난시간에 봤던대로 url을 daum의 sports news로 지정해 주자!
이제 이런식으로 daum sports news에 들어오게 되었다.
이게 str이면 안되는 거잖아
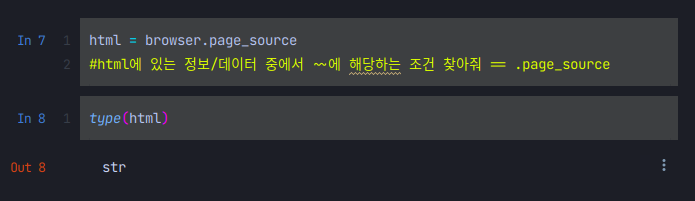
호기롭게 html이라는 변수에 page_source를 담아 주었는데 이럴수가 type이 str이라니... 이렇게되면 crawling이 사실상 지옥에서온 split문법의 연속 이라는 건가...?

지금까지 이렇게 잘따라왔는데 이게 str이면 말이 안되는 거잖아요

자네가 bs4 안쓴건.. 말이.. 되고?
bs4를 사용하자.
세상은 사실 우리가 생각하는 것보다 훨씬 윤택하다. bs4도 그러하다.

bs4를 install하고 BeautifulSoup을 임포트 해오자
그후로는 soup이라는 변수에 html을 넣고 뒤에는 'html.parser'라고 적어준다면 우리는 BS에게
html을 html.parser 기준으로 읽어줘
라고 부탁한 것과 같다. 다시 type을 찍어보면 bs4.BeautifulSoup으로 나오게 된다. type자체가 str에서 BS로 바뀌게 된 것이다. 이제는 진짜로 우리가 갖고오고싶은 정보를 가져오기만 하면 된다.
crawling 기본 문법

작성자가 장담하는데 정말로 이것만 다 안다면 크롤링은 끝났다고 봐도 무방하다. 정말이다.
앞으로의 실습에서 실제로 어떻게 사용가능한지 확인해보도록 하자.
다시우리의 browser로 돌아가 개발자 도구를 열어보자.
여기서 f12를 누르게 되면
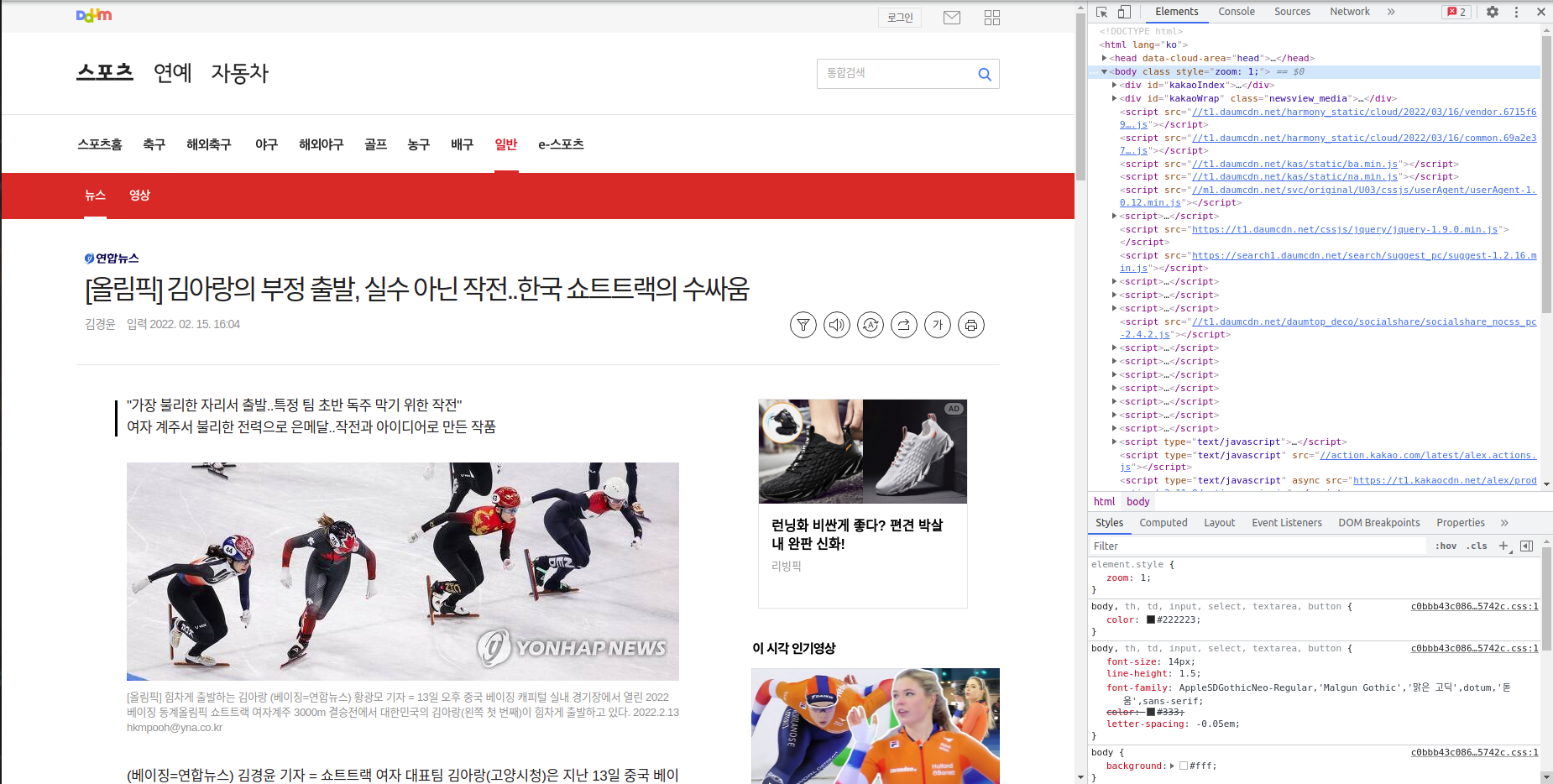
우리는 이렇게 해당하는 page가 사실 html문서로 되어있다는 사실을 알수 있음과 동시에 우리가 어떤식으로 scope를 줄여나가야 하는지 감이 올것이다.
우선 나는
[올림픽] 김아랑의 부정 출발, 실수 아닌 작전..한국 쇼트트랙의 수싸움
이렇게 제목에 해당하는 정보를 크롤링 해오고 싶다.
우선 이제목의 위치를 알아야 한다.
원하는 정보의 위치 찾기.
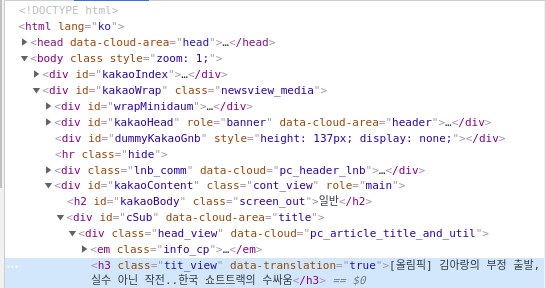
이렇게 내가 찾고싶은 제목과 일치하는 html부분을 찾았다. 찾아서 행복하지만, 복잡해서 머리가 아파오는것 같다. 이제는 다른걸 볼 필요가없다.
scope를 줄여나가자
말 그대로 범위를 줄여나가야 한다. 예를 들어
"서울에 사는 김서방을 찾아줘"=> 100만명
"그중 키가 182.7인 김서방을 찾아줘" => 3만명
"키가 182.7인 김서방중 30살 이상인 김서방을 찾아줘" => 8천명
"30살 이상인 김서방중 합정에 사는 김서방만 찾아줘" => 300명
"합정에 사는 김서방중 프론트엔드 개발자 김서방만 찾아줘" => 4명
"프론트엔드 개발자 김서방중 스타트업에서 일하는 김서방만 찾아줘" => 1명
왜 이런 예시를 들었을까?? 사실 크롤링은 서울에사는 김서방을 찾는 과정과 매우 비슷하다, 아니 똑같다.
이런식으로
조건을 추가할수록 우리는 범위를 줄여 나갈 수 있다.
그리고 이게 크롤링의 전부이다.
실질적으로 제목을 가져오기 전에 문법을 다시한번 확인한뒤 시작해 보도록 하자
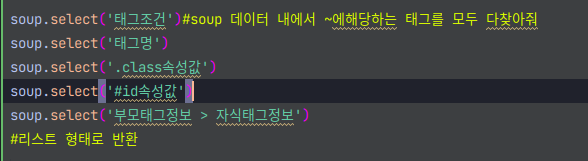
크롤링 코드

우선 div태그안에 있는것 같다. len 으로 길이를 확인해 보자! 1이되어야 우리가 원하는 제목일 테니까!

137개면 해당하는 제목이 137번 반복될 리는 없고. 아직도 범위가 많이 넓은것 같다.
자세히 보니 div의 class명이 "headview"인것 같으니 조건을 추가해 보자

1이나왔다! 이게 맞는것 같다!
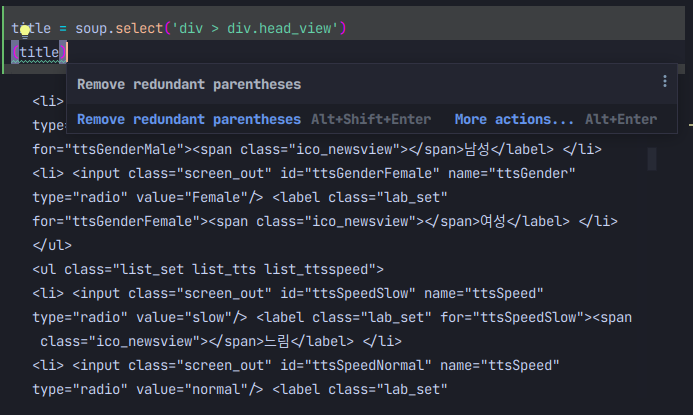
분명 하나인것 같기는 한데.. 우리가 원하는 제목만 가져오고 싶다. 그렇다면 조건을 추가하면 된다 앞에 보니 h3라는 태그가 있다 이것도 조건으로 추가해보도록 하자
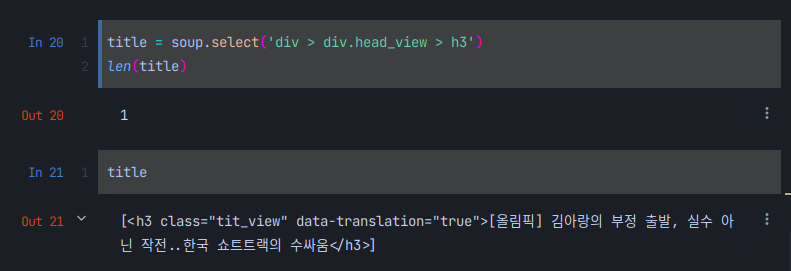
정말 거의다 온것 같지만 우리는 저런 html형식으로 원하는 것이 아닌 깔끔하게 제목만 가져오고 싶다. 그렇다면 어떻게 하면될까?
원하는 정보를 찾았다면 가공하자
다이아몬드도 가공 하지않으면 탄소 덩어리이자 비싼 광물일 뿐이다. 가공해서 이쁜 모양으로 깍고난뒤 반지위에 올라갈때야 비로소 영원한 사랑이란 의미를 지닌 결혼반지가 될 수 있는 것이다. 우리의 결과를 제련해 보자!
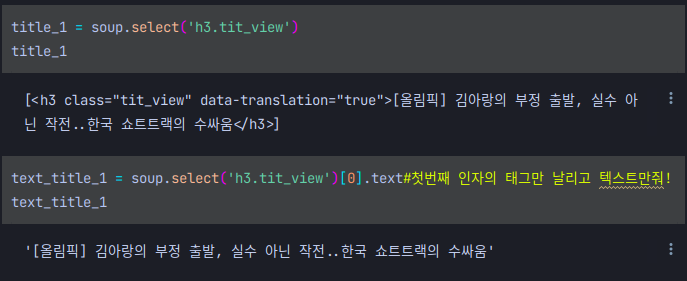
title_1이라는 변수에 값복사를 하고 (알고리즘 풀때 temp_num과 같은 맥락) [0]번째 index에서 .text로 테그를 다날리고 텍스만 반환해 달라고 하면 이렇게 우리가 원하는 결과인 해당기사에 대한 제목만 텍스트로 받아올 수 있다.
멀고도 험했던 기사에서 제목만 크롤링해오기 실습이 드디어 끝이난 것이다!
글을 마치며
처음에는 크롤링이라 하면 막연하고 두렵고 어려울것이란 생각만 했었는데 막상 여러실습을 통해서 내가 가져오고 싶은 기사의 제목 이라던가 여러 사이트의 정보들을 긁어올 수 있다는 사실에 많은 흥미와 재미를 느끼게 되었다. 작성자 뿐만이 아니라 이걸 읽는 사람들도 사실 크롤링은
조건을 추가해, 범위를 줄여 나가는 행위.
라는 것을 인지하며 함께 이렇게나 많은 정보의홍수 속에서 필요한 정보만을 쏙쏙 뽑아오는 영리한 개발자로 성장하길 소망한다!
