
예측 과정은 현재 시각(t_k)의 추정값(x_k^)이 다음 시각(t_k+1)에선 어떤 값이 될지 예측하는 것!
1. 예측값 계산

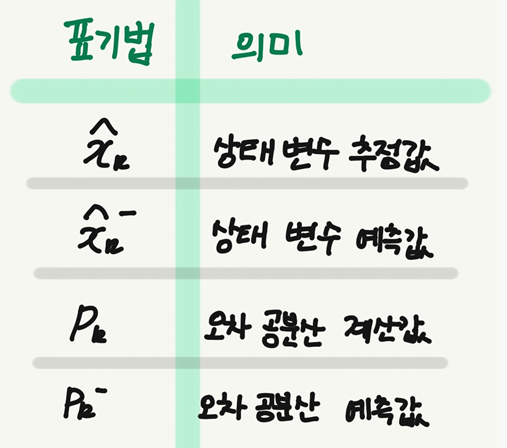
여기서 x_k-1^과 P_k-1는 Ⅲ. 추정값 계산, Ⅳ. 오차 공분산 계산에서 계산한 값
2. 예측과 추정의 차이
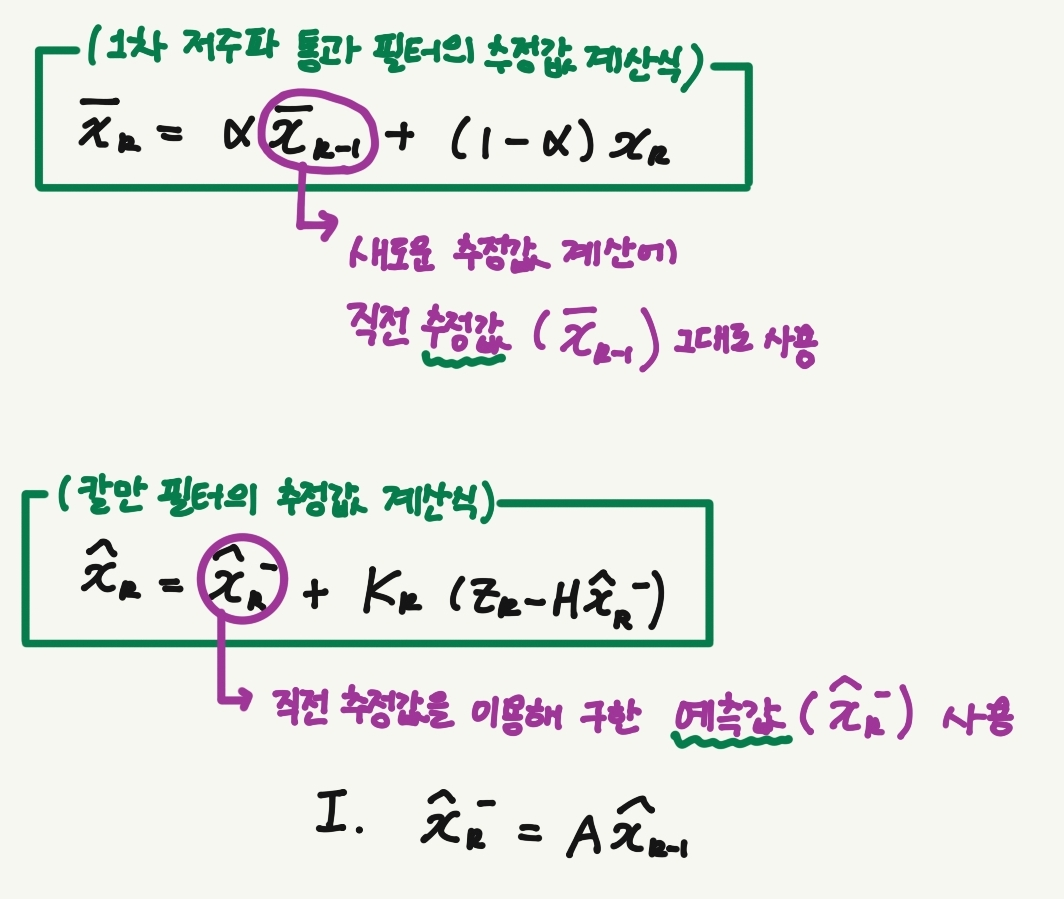
칼만 필터는 1차 저주파 통과 필터와 달리 추정값을 계산할 때 예측 단계를 거친다.
➡ 예측값을 사전 추정값(a priori estimate), 추정값을 사후 추정값(a posteriori estimate)이라고도 부름
추정 과정에서 사용되는 오차 공분산도 마찬가지!

추정: 같은 시각에 측정값을 받아 계산하는 과정 (하늘색 둥근 화살표)예측: 다음 시각으로 이동하면서 행렬 A를 거치는 과정 (연두색 직선 화살표)
1차 저주파 통과 필터와 달리 예측 과정 때문에 직전 추정값이 다른 값으로 바뀐다.
같은 시각에 있는 두 값 중, 추정 과정의 결과인 오른쪽에 있는 값이 칼만 필터의 최종 출력!
3. 추정값 계산식의 재해석
예측 단계의 계산식은 칼만 필터의 성능에 큰 영향!

위를 토대로 식을 아래와 같이 해석할 수 있다.
📌 칼만 필터는 측정값의 예측 오차로 예측값을 적절히 보정해서 최종 추정값을 계산한다.
이때 K_k(칼만 이득)이 예측값을 얼마나 보정할지 결정하는 인자!
이렇듯 추정값 계산식을 예측값의 보정 관점에서 보면, 추정값의 성능에 가장 큰 영향을 주는 요인은 예측값의 정확성
예측값을 구할 땐 시스템 모델의 A와 Q가 필요!
➡ 두 변수가 실제 시스템과 많이 다르면 예측값은 부정확하게 되고, 추정값도 엉뚱한 값을 갖게 된다.
따라서 칼만 필터의 성능은 시스템 모델에 달려있다!
