추천 엔진
사용자가 관심있어 할만한 아이템을 제공해주는 자동화된 시스템 혹은 비즈니스의 장기적인 목표를 개선하기 위해 사용자에게 알맞은 아이템을 자동으로 보여주는 시스템
추천 엔진이 왜 필요할까요? 크게 다음 두가지 이유를 생각할 수 있습니다.
1. 사용자가 원하는 상품을 검색하는 수고를 덜어준다.
2. 신상품 등 다양한 아이템을 추천함으로써 마케팅 효과를 낼 수 있다.
추천은 결국 매칭의 문제이므로 사용자와 아이템에 대한 부가 정보들이 중요합니다.
따라서, 아이템에 대해서는 아이템 분류 체계, 사용자에 대해서는 개인정보(성별, 연령대 등)와 선호 아이템 정보(관심 카테고리, 클릭/구매 아이템 등)가 팔요합니다.
추천 알고리즘
- 컨텐츠 기반 (아이템 기반)
- 비슷한 아이템을 기반으로 추천 (개인화된 추천 X); 아이템 간의 유사도를 측정
- 단어 카운트, TF-IDF 카운트 등 NLP 테크닉이 필요할 수 있음
- 사용자 행동 기반: 클릭이나 구매 등의 사용자 행동을 기반
- 사용자와 아이템에 대한 부가 정보가 필수 (구현이 간단)
- decision tree나 deep learning을 이용하여 모델링을 할 수도 있음 실시간 & 효율적으로 추천 할 수 있도록 계산 방식 및 계산량을 잘 조절해야함
| 사용자가 수행한 행동을 기반으로 추천 | 사용자의 행동을 예측하여 추천 |
|---|---|
| 사용자가 이미 관심을 보인 특정 아이템 등을 기반으로 추천 | 사용자의 클릭 혹은 구매를 예측하여 추천 (지도 학습 문제로 접근) |
| 어떤 기준(레이블 정보)으로 추천을 할지가 중요 |
- 협업 필터링 (collaborative filtering): 평점 기반
| user 기반 (user to user) | item 기반 (item to item) |
|---|---|
| 비슷한 평점 패턴을 보이는 사람들을 기반으로 추천 | 평점 패턴이 비슷한 아이템들 기반으로 추천 |
| (사용자간 유사도를 측정) | (보통 아이템 수 < 사용자 수 user 기반 방식보다 더 안정적, 좋은 성능) |
- 협업 필터링의 문제점
- cold start 문제
- 사용자 관점: 사용자가 평점을 준 아이템이 없는 경우
- 아이템 관점: 아이템에 대하여 아직 평점을 준 사용자가 없는 경우
- 리뷰 정보의 부족
- 업데이트 시점: 사용자나 아이템이 추가될 때마다 다시 계산을 해주어야 함
- 확장성 이슈: 사용자가 많아지면 대용량의 컴퓨팅 자원이 필요함
- cold start 문제
- 구현 방법
| 메모리 기반 | 모델 기반 |
|---|---|
| 사용자 기반 또는 아이템 기반으로 사용자간 혹은 아이템간 유사도를 미리 계산 | 사용자 아이템 행렬에서 비어있는 평점들을 SGD를 사용하여 채움, SVD를 이용하여 구현됨 (혹은 오토인코더) |
| 구현과 이해가 상대적으로 쉬우나 스케일하지 않음 | 평점을 포함, 다른 사용자 행동을 예측하는 형태로 진화중 |
유사도 측정 방법
두 개의 비교대상을 n차원 상의 공간에서 유사도를 측정합니다.
1. cosine 유사도
cosine 유사도는 아래 그림과 같이 두 개의 비교대상을 벡터로 표현하고, 두 벡터 사이의 각도를 구해 유사도를 계산하는 방식입니다.
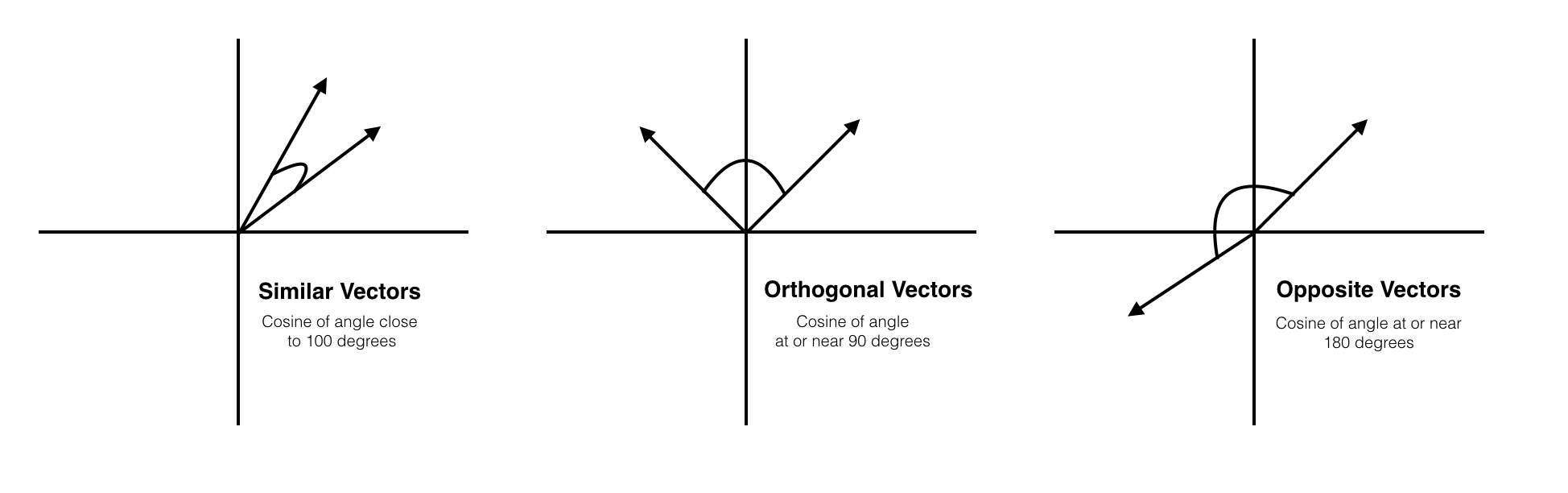
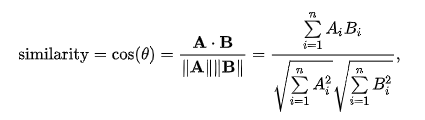
https://deepai.org/machine-learning-glossary-and-terms/cosine-similarity- 피어슨 상관계수
피어슨 상관계수는 -1에서 1까지의 값으로 두 개의 비교대상의 선형적 관계를 나타냅니다.
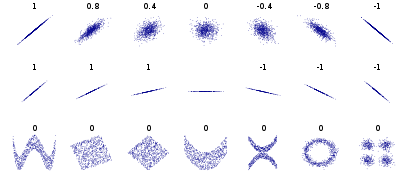
pair 형태로 주어진 데이터 에 대하여 피어슨 상관계수는 다음과 같이 구할 수 있습니다.
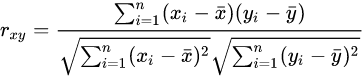
참고문헌

꾸준히!