우선, 인기도 기반 추천 엔진의 특징에 대해서 알아봅시다.
인기도 기반 추천 엔진
- 특징
- 전체적인 인기도 설정 기준(평점, 매출, 판매량 등)에 따라 추천되므로 cold start 이슈가 존재하지 않음
- 사용자 정보에 따라 확장 가능
- 개인화되어 있지는 않음
- 아이템 분류 체계가 존재하면 쉽게 확장 가능
- 인기도를 다른 기준으로 바꾸어 다양한 추천 유닛 생성 가능
이제 본격적으로 TMDB 데이터를 가지고 인기도 기반 추천 엔진을 만들어보겠습니다.
TMDB 데이터
위 데이터셋은 크게 다음과 같이 구성되어있습니다.
https://www.kaggle.com/datasets/tmdb/tmdb-movie-metadata
- tmdb_5000_credits.csv: 각 영화의 고유 id, 제목, 영화별 캐스팅, 제작진 정보
- tmdb_5000_movies.csv: 각 영화의 고유 id, 제작 예산, 장르, 홈페이지, 키워드, 개요, 인기도, 제작사 정보, 원제, 제작언어
colab에서 각 데이터를 자세히 살펴보겠습니다.
import pandas as pd
import numpy as np
movies = pd.read_csv("./tmdb_5000_movies.csv")
credits = pd.read_csv("./tmdb_5000_credits.csv")
movies.head(2)
movies.shape
movies 데이터 프레임의 shape은 (4803, 20)으로, 총 4803개의 영화에 대한 정보가 20개의 column에 저장되어있는 것을 확인할 수 있습니다.
그런데, genres column을 보면 genre 정보 이외에 id 정보도 포함되어있습니다. 따라서 genre 정보만 따로 뽑아 새로운 column으로 만들어주도록 하겠습니다.
먼저, 다음 함수를 정의합니다.
import json
def add_genre_name(j):
genres = []
ar = json.loads(j)
for a in ar:
genres.append(a.get("name"))
return " ".join(sorted(genres))- json.loads(): json string을 python dictionary로 변환
movies['genres']에 위 함수를 적용합니다.
movies['genres_name'] = movies.apply(lambda x: add_genre_name(x.genres), axis=1)
genre의 이름들만 잘 저장된 것을 확인할 수 있습니다. 이제, movies 데이터 프레임은 21개의 column을 가지고 있습니다.
credits도 간단히 살펴보겠습니다.

credits의 shape은 (4803, 4)로, 총 4803개의 영화에 대한 정보가 4개의 column에 저장되어있는 것을 확인할 수 있습니다. 다행히 숫자상으로는 credits와 movies의 row 갯수가 동일합니다.
데이터를 더 편하게 관찰하기위해 두 데이터프레임을 join 하겠습니다. 각 영화는 id를 unique한 key값으로 가지고 있으므로, id를 기준으로 join을 수행합니다. 이 때, id가 movies 데이터 프레임에서는 'id' column에, credits 데이터 프레임에는 'movie_id' column에 저장되어있는 것에 주의합니다.
movie_credits = pd.merge(movies, credits, left_on='id', right_on='movie_id')movie_credits의 shape은 (4803, 25)로 잘 join된 것을 확인할 수 있습니다.
또한, movie_credits['id'].nunique()의 결과값이 4803이므로 중복된 영화는 없는 상황입니다.
25개의 특징 중에서, 영화 인기도(선호도)와 관련이 적어보이는 특성을 우선 제거하겠습니다.
movie_credits = movie_credits.drop(columns=['homepage', 'title_x', 'title_y', 'status','production_countries', 'production_companies'])info(), describe()를 이용해 movie_credits을 다시한번 살펴봅니다.
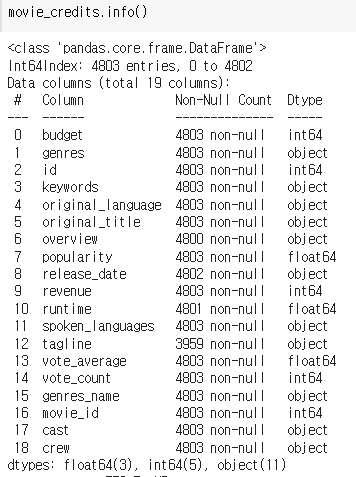
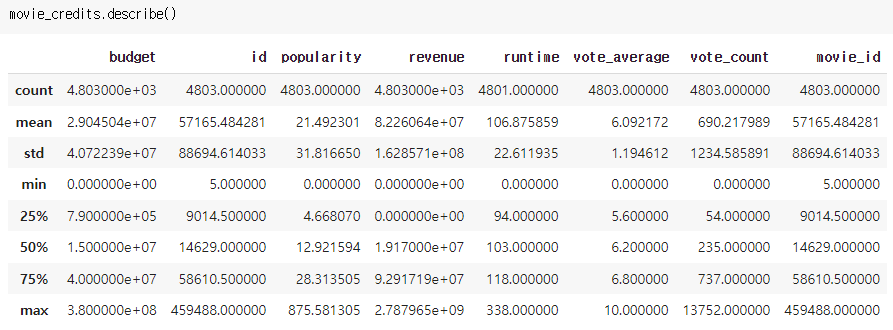
8개의 수치형 특성에 대해 mean, std 등의 정보가 잘 나타나는 것을 볼 수 있습니다.
popularity의 최저점은 0, 최고점은 약 875.6점 이네요 :) 평균값이 약 21.5점인 것으로 보아 최고점은 다른 점수들과 격차가 클 것 같습니다.
popularity가 중요한 기준이므로, 인기도를 기준으로 정렬합니다.
popularity = movie_credits.sort_values('popularity',ascending=False)
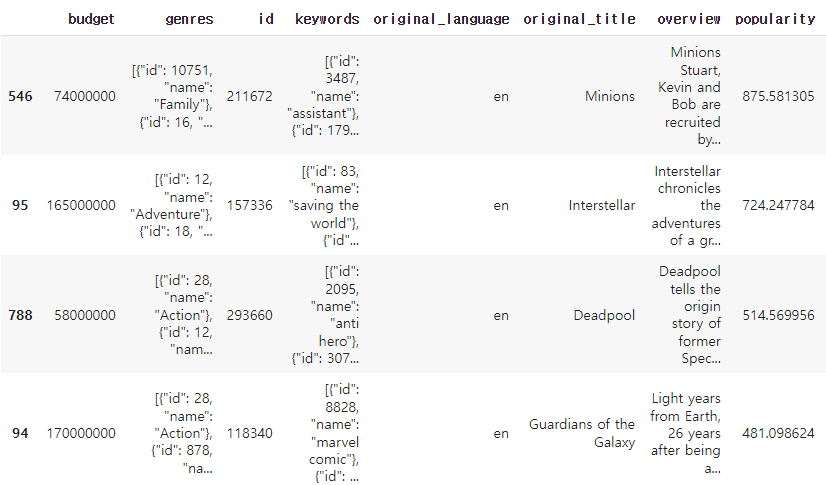
popularity의 상위점수들은 서로 차이가 큰 것을 확인할 수 있습니다.
popularity 점수를 기준으로 상위 10개 영화를 뽑아보겠습니다.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(12,6))
ax=sns.barplot(
x=popularity['popularity'].head(10),
y=popularity['original_title'].head(10),
palette = "Set2"
)
plt.title('Most Popular by Popularity', weight='bold')
plt.xlabel('Score of Popularity', weight='bold')
plt.ylabel('Movie Title', weight='bold')
plt.savefig('best_popular_movies.png')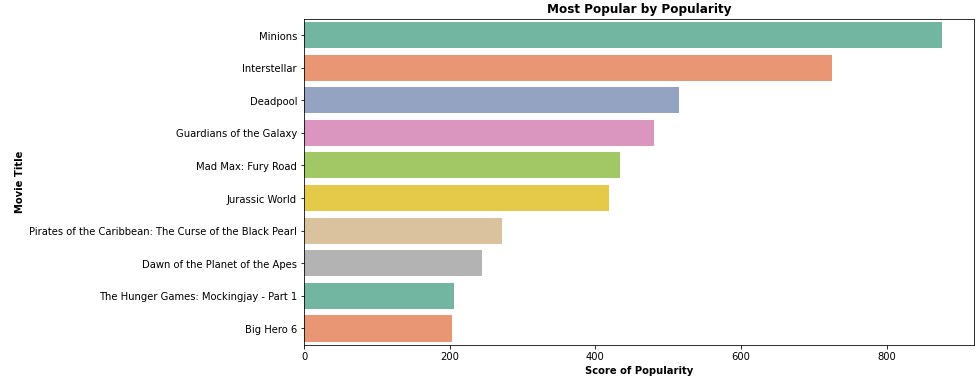
사용자에 대한 정보가 없고, popularity를 기준으로 추천을 한다면 위 영화들을 추천할 수 있을 것입니다.
좀 더 세분화해서 각 장르별로 popularity 점수가 높은 영화를 추천한다면 어떻게 해야할까요?
다음 함수를 통해 구현해볼 수 있습니다.
def reco_top_scored_one(n, genre=None):
if genre is None:
return popularity["original_title"].head(n)
else:
return popularity[popularity['genres_name'].str.contains(genre)]["original_title"].head(n)액션 영화 중에서 popularity를 기준으로 추천을 한다면 다음 영화들을 추천할 수 있습니다.

다음에는 popularity를 포함하여 좀 더 다양한 요인들을 고려 + 모델링을 통해 추천 엔진을 만들어보겠습니다 :-)
