2022-01-18(화) 10주차 2일
어제 FileOutputStream, FileInputStream으로 바이트 스트림을 다뤘다.
오늘은 FileReader, FileWriter를 사용해서 캐릭터 스트림을 다루겠다.
FileReader, FileWriter를 안 써도 파일로 출력하고 읽어들이는 데 전혀 지장이 없다.
단, 텍스트에 한정해서 문자에 한정해서 파일로 출력하고 파일로 읽어들일 때 편리한 기능이 추가됐다.
FileReader / FileWriter
04-입출력스트림 / 17 페이지
문자열 (JVM: UTF-16) → 바이트 배열로 변환 → FileOutputStream → 텍스트 파일
'바이트 배열로 변환 ⟶ FileOutputStream'
⟹ 이 기능이 결합된 게 FileWriter
✔ 개발자가 문자를 출력하기 위해 바이트 배열로 변환할 필요가 없다.
문자열 (JVM: UTF-16) ← UTF-16 문자열 변환 ← FileInputStream ← 텍스트 파일
'UTF-16 문자열 변환 ⟵ FileInputStrea'
⟹ 이 기능이 결합된 게 FileReader
✔ 개발자가 바이트 배열을 자바 스트링(UTF-16)으로 변환할 필요가 없다.
com.eomcs.io.ex03
먼저 상속 관계를 파악해야 된다.
FileWriter
https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/io/FileWriter.html
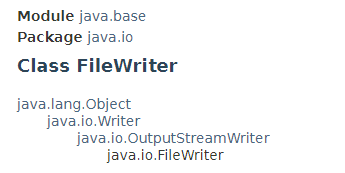
🔹 Constructor
new FileWriter(File file)
new FileWriter(new File(파일 경로)) 파일 객체를 만들어서 넘겨준다
어느 경로에 어떤 이름의 파일로 출력할 건지
파일에 대한 정보를 담은 객체를 넘겨주면 된다
파일 객체를 만들어서 파일을 어느 경로 밑에 만들 건지 경로 정보를 파일 객체에 담아서 넘기면 된다
파일 경로를 갖고 있는 파일 객체를 넘겨주면 된다
new FileWriter(String fileName)
파일 이름 자체를 바로 넘겨줘도 된다
파일의 경로를 문자열로 바로 넣어도 된다
FileWriter(String fileName, boolean append)
append 하면 기존에 있는 걸 지우지 말고 이어서 출력하겠다는 뜻
append 안 주면 무조건 기존에 파일이 있으면 지워버리고 새로 출력하겠다는 거
FileWriter(String fileName, Charset charset)
출력할 때 어떤 character set으로 출력할 건지 지정하는 거
설정하지 않으면 UTF-8로 출력
아무것도 안 적으면 file.encoding에 설정된 값으로 출력된다
FileWriter은 다른 Writer가 필요 없다. 데코레이터로 안 쓴다는 거.
FileWriter 자체가 주객체. 실제 데이터가 있는 곳.
주객체 → data sink stream class
누군가 데이터를 보내온 걸 중간에 가공해서 내보내고 읽어들이고
중간에서 읽어온 걸 가공해서 리턴하고 출력할 걸 가공해서 리턴
중간에서 데이터를 처리하는 거 → data processing stream class
System.getProperty("file.encoding")
System 클래스에 static 메서드를 사용해서 file.encoding을 알아낸다.
왜 new System 안 합니까?
JVM system은 하나
JVM을 여러 개 띄우는 게 아님
현재 실행하는 JVM system에서 정보를 추출할 때는 System 클래스의 static 메서드를 사용한다.
System을 여러 개 만드는 게 아님.
FileWriter.write(int)
int 4바이트 중에서 앞의 2바이트는 버린다.
뒤의 2바이트는 UTF-8로 변환되어 파일에 출력된다.
이클립스에서 JVM을 실행할 때는 file.encoding=UTF-8
이클립스가 그렇게 설정함
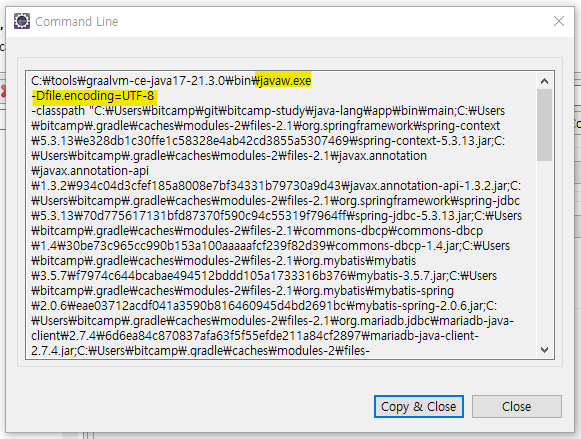
java.exe도 JVM이고 javaw.exe도 JVM이다.
javaw.exe ← 윈도우 프로그램에서 실행할 때 쓰는 JVM
이클립스가 윈도우 프로그램이니까
명령창에서 바로 실행할 때는 java.exe 쓰면 됨
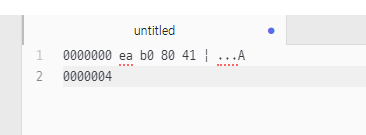
FileWriter.write(int)
04-입출력스트림 / 19 페이지
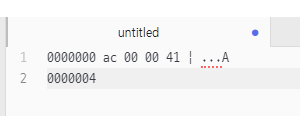
write(0x7a6bac00)
‐ 앞의 2바이트(7a6b)는 버린다.
‐ 뒤의 2바이트(ac00)은 UTF-8(eab080) 코드 값으로 변환되어 파일에 출력된다.
write(0x7a5f0041)
‐ 앞의 2바이트(7a5f)는 버린다.
‐ 뒤의 2바이트(0041)는 UTF-8(41) 코드 값으로 변환되어 파일에 출력된다.
그림으로 자꾸 그려보기
java -cp bin/main com.eomcs.io.ex03.Exam0110

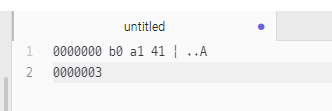
만약 file.encoding 옵션을 설정하지 않으면 OS의 기본 문자집합으로 자동 설정된다.
'가'
UTF-16BE : ac 00
MS949, EUC-KR : b0 a1
UTF-8 : ea b0 80
java -Dfile.encoding=UTF-8 -cp bin/main com.eomcs.io.ex03.Exam0110

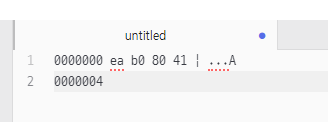
JVM을 실행할 때 입출력을 할 때 어떤 문자 집합으로 변환할 건지 설정하는 게 file.encoding
com.eomcs.io.ex03.Exam0111.java
character stream - 출력할 문자 집합 설정하기
출력 스트림 객체를 생성할 때 문자 집합을 지정하면 UCS2 문자열을 해당 문자집합으로 인코딩 한다.
Charset.isSupported("문자집합") 지원하는지 여부 확인하고 쓰기
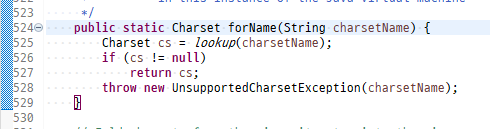
Charset.forName(String charsetName)
FileWriter(String fileName, Charset charset)
file.encoding과 상관없이 charset에 설정된 대로 출력한다는 거
Charset는 추상클래스
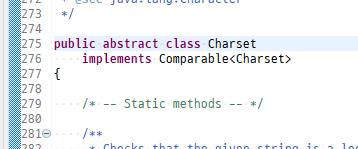
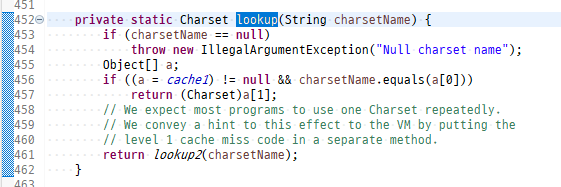
Charset 객체 만드는 과정이 복잡
Charset.forName(String charsetName) ← 팩토리 메서드
Charset 객체를 만들어주는 공장 메서드
팩토리 메서드 설계 기법
객체 생성 과정이 복잡할 때 new 라는 명령을 통해서 생성하는 게 아니라 static 메서드 안에서 객체를 생성해서 리턴한다.
객체 생성 방법이 복잡할 때 이 방법을 많이 사용한다.
com.eomcs.io.ex03.Exam0112.java
character stream - 출력할 문자 집합 설정하기
FileReader
04-입출력스트림 / 20 페이지

🔹 Constructor
FileReader(File file)
FileReader(String fileName)
new FileReader(파일경로)
파일경로를 직접 넘겨준다.
new FileReader(new File(파일경로))
파일경로를 담은 File 객체를 만들어서 넘겨준다.
FileReader.read()
04-입출력스트림 / 21 페이지
JVM 파라미터
file.encoding = ?
JVM 문자열 = UTF-16
FileReader는 문자에 따라서 1바이트 읽기도 하고 3바이트 읽기도 함
FileInputStream read() 메서드와 다른 점이다.
Atom 설정할 때 UTF-8로 설정해놔서 UTF-8이 아닌 건 깨짐
com.eomcs.io.ex03.Exam0122.java
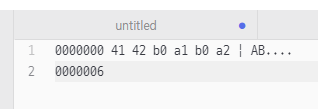
다음과 같이 잘못되었다는 의미로 특정 값(fffd)으로 변환한다.

FileReader 영어는 1바이트, 한글은 3바이트 읽는다
String(char value[], int offset, int count)
클라우드 스토리지에 있는 거 쓰면 입출력을 다룰 일은 없음
영어 한글 상관없이 40개
com.eomcs.io.ex03.Exam0420.java
▪ FileReader.read(CharBuffer target) : int
CharBuffer
캐릭터버퍼
FileReader.read()
① 텍스트 파일을 읽어서 1개의 char 타입 리턴
② char[] 개수만큼 저장
③ CharBuffer
커서(cursor) : 텍스트를 출력할 위치 / 텍스트를 읽은 위치
커서가 있는 위치부터 데이터를 읽는다
문자열을 뽑아내고 싶음
커서를 파일의 시작으로 돌린 후(flip()) 문자를 읽어야 한다.
커서가 있는 위치부터 출력
커서가 있는 위치부터 데이터를 읽는다
버퍼에서 문자열을 뽑아내고 싶음
문자열을 뽑으려면 커서를 파일의 시작으로 돌린 후 문자를 읽어야 한다
읽으려면 flip 해줘야 됨
안 그럼 안 읽힘
read() 메서드가 파일에서 데이터를 읽어서 버퍼에 채울 때마다 커서의 위치는 다음으로 이동한다.
버퍼의 데이터를 읽으려면 커서의 위치를 처음으로 되돌려야 한다.(flip)
flip() 메서드를 호출하여 커서를 처음으로 옮긴다. 그런 후에 버퍼의 텍스트를 읽어야 한다.
com.eomcs.io.ex03.Exam0430.java
BufferedReader 데코레이터를 붙이면 더 편함
FileReader에 BufferedReader를 붙이면 한 줄씩 읽을 수 있다
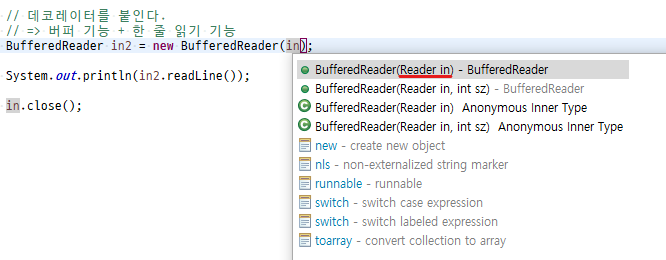
BufferedReader(Reader in)
BufferedReader의 생성자는 Reader를 원한다
Reader의 자손들 다 가능
FileReader와 BufferedReader 데코레이터
<<abstract>> Reader
FileReader
CharArrayReader
PipedReader
StringReader
BufferedReader ← 데코레이터

FilterReader ← 데코레이터
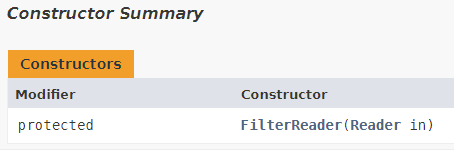
생성자에서 다른 Reader를 요구하면 다 데코레이터
FileReader in = new FileReader();
BufferedReader in2 = new BufferedReader(in);FileReader 객체에 데코레이터인 BufferedReader를 붙인다.
com.eomcs.io.ex04
데코레이터 안 썼을 때랑 썼을 때 차이
com.eomcs.io.ex04.Exam0110.java
FileOutputStream.write(int) : 맨 끝 1바이트를 출력하는 메서드이다.
‐ 파라미터의 타입이 int라고 해서 4바이트를 출력하는 것이 아니다.
‐ 오직 맨 끝 1바이트만 출력한다.
com.eomcs.io.ex04.Exam0120.java
FileInputStream.read() : int
리턴 타입이 int 라 하더라도 1바이트를 읽어 리턴한다.
1바이트를 읽어 4바이트 메모리에 담아서 리턴한다.
read() 메서드를 호출할 때마다 이전에 읽은 바이트의 다음 바이트를 읽는다.
파일의 끝에 도달하면 -1을 리턴한다.
com.eomcs.io.ex04.Exam0210.java
1바이트가 아니라 4바이트 전체를 출력하고 싶다.
맨 끝에 있는 1바이트만 출력하니까 비트 이동시켜서 맨 끝으로 보낸다
24비트 이동
16비트 이동
8비트 이동
비트 이동 연산자
맨 뒤로 보낸다
밀려나간 애들은 버려진다
각 바이트를 맨 끝으로 이동한 후 출력한다.
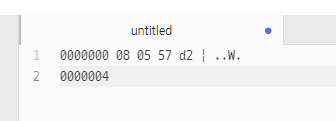
com.eomcs.io.ex04.Exam0220.java
24비트 이동
16비트 이동
8비트 이동
한 번에 4바이트를 읽어서 int로 만드는 방법 없습니까?
Integer에 파라미터로 바이트 배열을 받아서 바꾸는 메서드 없음
com.eomcs.io.ex04.Exam0310.java
데이터 출력 - long 값 출력
out.write((int)(money >> 56)); // 00000000|00000000|016bcc41e9000000000000|00000000|016bcc41e90000
56비트 이동하면 맨 끝에 00이 출력된다.
다른 방법 없습니까?
없음
(int)(money >> 56) 여기서 int 형변환 빼면 에러
write(int) 메서드는 파라미터로 long 값을 못 받음. int로 형변환 해줘야 됨.
(money >> 56) int로 형변환 하는 순간 앞에 4 byte 날아감
어차피 맨 끝 1바이트만 출력하는 거라 앞에 4 byte 날아가도 상관없음
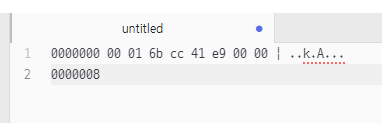
com.eomcs.io.ex04.Exam0320.java
FileInputStream.read() : int
1바이트를 읽어 리턴한다.
메서드의 리턴 타입이 int라 하더라도 1바이트를 읽어 리턴한다.
read() 메서드를 호출할 때마다 이전에 읽은 바이트의 다음 바이트를 읽는다.
왼쪽으로 56비트 이동
왼쪽으로 48비트 이동
...
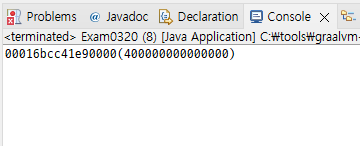
com.eomcs.io.ex04.Exam0410.java
데이터 출력 - String 출력
write() ← 메서드 오버로딩 (method overloading)
같은 기능을 하는 메서드에 대해서 파라미터 개수, 타입이 다르더라도 같은 이름을 부여하여 메서드를 호출할 때 일관되게 호출할 수 있도록 일관성 있는 프로그램을 짜도록 지원하는 문법
같은 이름을 가진 메서드가 있더라도 매개변수의 개수 또는 타입이 다르면 같은 이름을 사용해서 메서드를 정의할 수 있다.
FileOutputStream.write(byte[]) 배열의 값 전체를 출력한다.
com.eomcs.io.ex04.Exam0420.java
FileInputStream.read(byte[]) : int 리턴 값은 읽은 바이트의 개수이다.
‐ 버퍼가 꽉 찰 때까지 읽는다.
‐ 버퍼 크기보다 파일의 데이터가 적으면 파일을 모두 읽어 버퍼에 저장한다.
‐ 리턴 값은 읽은 바이트의 개수이다.
최대 배열 개수만큼 읽을 수 있다. 개수를 지정하지 않으면 꽉 찰 때까지 읽는다.
바이트 배열에 들어있는 값을 사용하여 String 인스턴스를 만든다.
new String(바이트배열, 시작번호, 개수, 문자코드표)
바이트 배열의 인코딩 문자 집합을 파라미터에 정확하게 알려준다.
바이트 배열을 UCS2 문자 배열로 만들어 String 객체를 리턴한다.
중간에서 도와주는 도우미 플러그인
java.io 패키지는 데코레이턴 패턴으로 기능을 자유롭게 붙였다 뗄 수 있도록 기능을 추가
com.eomcs.io.ex05
com.eomcs.io.ex05.DataFileOutputStream.java
writeInt(int value)
int 값을 주면 상속받은 write() 메서드를 4번 호출해서 int 값을 출력하게 했다
writeLong(long value)
long 값 받아서 상속받은 write() 메서드를 8번 호출해서 출력하게 했다
writeBoolean(boolean value)
true면 1, false면 0
1바이트 출력하게 했다
writeUTF(String str)
문자열을 주면 알아서 UTF-8 바이트 배열로 뽑아내서
그 바이트 배열의 개수를 1바이트로 출력하고 (개수를 알아야 나중에 읽을 수 있음)
그 다음 바이트 배열을 출력하도록 했다

제일 먼저 이름 바이트 개수를 출력 (이름이 저장된 바이트 배열의 수)
0b → 11개

그 다음 11개가 이름

나이 : 00 00 00 1b → 16 + 11 = 27

성별 1바이트 출력
이것을 파일 포맷이라 부른다.
출력된 순서에 따라서 읽어야지 마음대로 읽으면 안 됨
출력된 순서에 따라서 그대로 읽어야 한다
이름이 저장된 바이트 배열의 수 만큼 배열을 준비한다
이름 배열 개수 만큼 바이트를 읽어 배열에 저장한다.
member.name = new String(buf, "UTF-8");
UTF-8 규칙에 따라서 어떤 문자에 대한 숫자값이 저장된 바이트 배열
'UTF-8 character set 코드가 저장된'
'UTF-8 문자코드가 저장된'
문자에 대해서 부여된 숫자
'가'
EUC-KR : b0 a1
UTF-16 : ac 00
UTF-8 : ea b0 80
UTF-8로 인코딩되었으니까 읽어서 UTF-16으로 바꿔서 JVM 문자열로 리턴해다오
그 다음 4바이트는 나이
하나의 int 값으로 저장
그 다음 1바이트는 성별
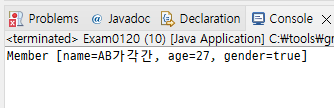
FileOutputStream을 상속받아서 DataFileOutputStream을 미리 만들었다.
원래 FileOutputStream은 문자열을 UTF로 출력하거나 4바이트 int값을 출력하거나 8바이트 long값을 출력하는 기능은 없는데 FileOutputStream을 상속받아서 기능을 확장한 게 DataFileOutputStream이다.
primitive type의 데이터 입출력
FileOutputStream에서 제공해주는 write()는 너무 불편함
DataFileOutputStream
FileOutputStream 상속받아서 DataFileOutputStream 만듦
기능 확장
4개 메서드 추가
writeUTF(String) 문자열을 UTF로 출력
writeInt(int) int값 출력
writeLong(long) long값 출력
writeBoolean(boolean) boolean값 출력
FileOutputStream을 직접 쓰는 것보다 기능을 확장한 DataFileOutputStream 쓰는 게 편하다.
com.eomcs.io.ex05.Exam0210.java
DataFileOutputStream을 이용하여 객체 출력 - 인스턴스의 값을 출력
com.eomcs.io.ex05.DataFileInputStream.java
FileInputStream
read() : int
read(byte[]) : int
DataFileInputStream
FileInputStream 상속받아서 DataFileInputStream 만듦
readUTF() : String UTF로 인코딩된 데이터를 읽어서 String 객체 리턴
readInt() : Int 4바이트를 읽어서 int값으로 리턴
readLong() : long 8바이트를 읽어서 long 변수에 담아서 리턴
readBoolean() : boolean 1 또는 0 읽어서 boolean값으로 리턴
com.eomcs.io.ex05.Exam0220.java
FileInputStream을 직접 써서 데이터를 읽는 것보다는 상속받아서 만든 DataFileInputStream을 사용해서 데이터를 읽는 게 훨씬 더 프로그래밍이 간결해진다.
read 할 때마다 커서가 이동
파일 끝에서 읽으려고 하면 -1을 리턴
com.eomcs.io.ex06
java language specification 검색
https://docs.oracle.com/javase/specs/
git\bitcamp-study\java-lang\app\temp
com.eomcs.io.ex06.Exam0110.java
버퍼 사용 전 - 데이터 읽는데 걸린 시간 측정
데이터를 읽으려면 파일 시스템에 가서 물어봐야됨
jls11.pdf 파일이 몇 번 트랙에 몇 번 섹터에 저장됐는지
몇 번 트랙에 jls11.pdf이 있는지 알아내야 되고
몇 번 섹터에 있는지도 알아내야 됨
그 데이터가 저장된 트랙을 찾고 섹터를 찾아서 그 섹터를 따라가면서 읽어야 됨
시간이 얼마나 걸리는지 확인해보자
FileInputStream.read() : int 1바이트를 읽어 리턴한다.
333만 바이트를 읽으려면 333만 반복해야 된다.
반복문을 돌기 전에 현재 시간을 기록해두고
반복문이 끝나면 그 시간을 기록해서 끝난 시간에서 시작한 시간을 뺀다.
몇 번 호출했는지도 확인한다.
평균 읽기 시간 = data seek time + read time
data seek time : 데이터를 찾는 시간 ← 여기서 시간 많이 걸림
트랙을 찾고 섹터를 찾아야 돼서 시간이 많이 걸린다
FileInputStream.read() : int 1바이트를 읽어 리턴한다.
매번 1바이트마다 트랙을 찾고 섹터를 찾아야 돼서 오래 걸리는 거
시간을 줄이는 방법
찾았으면 1바이트만 읽지 말고 찾은 김에 왕창 읽어버리면 속도가 빠름
앞접시에 담을 수 있는 만큼 담아서
앞접시가 빌 때까지 갈 필요 없음
앞접시에 왕창 담아오는 게 낫다
통째로 갖다 놓으면 안 됩니까? 자리 차지해서 앞접시를 사용함
프로그래밍 세계에서 앞접시를 버퍼라고 한다.
중간 그릇을 만들어서 거기에 담는다.
중간 그릇에 담겨있는 걸 한 개씩 꺼내 쓰다가 다 떨어지면 다시 가서 왕창 담아온다.
이미 생활 속에서 많이 쓰는 방법...
com.eomcs.io.ex06.Exam0120.java
이번에는 1바이트씩 깨작깨작 읽지 말고 한 번에 8KB씩 읽는다
1 KB = 1024 byte
1000이 아니라 1024
비트를 쓰다 보니까
11 1111 1111 (10비트)
0 ~ 1023 (1024개)
0에서 1023이니까 개수로 따지면 1024
1024 x 8 = 8192 (8KB)
한 번에 8192바이트씩 읽으면 read() 메서드를 몇 번 호출하는지 보자
데이터 읽을 때 한 번에 왕창 바이트 배열 단위로 읽어오는 게 더 빠르다.
한 번 데이터를 찾았을 때 연속해서 데이터를 읽어버리는 게 속도가 더 빠르다.
매번 데이터를 찾아서 1바이트 읽는 것보다 한 번 데이터를 찾아서 연속적으로 왕창 읽어오는 게 속도가 더 빠르다.
버퍼를 쓰는 게 속도가 더 낫다!
com.eomcs.io.ex06.Exam0130.java
BufferedFileInputStream 사용 후 - 데이터 읽는데 걸린 시간 측정
BufferedFileInputStream
04-입출력스트림 / 25 페이지
FileInputStream
read()
BufferedFileInputStream
FileInputStream을 상속받아서 만들었다
buf : byte[] 버퍼 (바이트 배열)
read() 메서드 오버라이딩
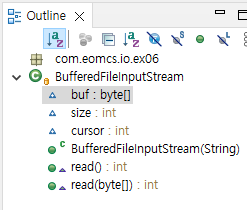
public class BufferedFileInputStream extends FileInputStream {① read()
BufferedFileInputStream에게 read() 요청
② call
FileInputStream.read(byte[]) 호출
③ 버퍼 크기 만큼 읽는다
버퍼 크기 만큼 읽어서 버퍼에 저장한다.
④ 버퍼에서 1개의 바이트 값을 꺼내 리턴
진열대 / 창고
창고에서 진열대(버퍼)에 놓을 만큼만 놓는다
창고에는 커피가 더 많이 있음 (파일)
당장 쓸 것만 진열대(버퍼)에 놓는다
손님이 달라고 하면 진열대(버퍼)에 있는 걸 준다
진열대가 비면 창고에서 꺼내서 진열대에 다시 채워 넣는다
그릇에 있는 메추리알 (버퍼)
냉장고에 있는 메추리알 (파일)
그릇에서 한 개씩 집어 먹다가 바닥이 보이면 냉장고에서 꺼내서 왕창 채워 넣는다.
com.eomcs.io.ex06.Exam0120.java
한 번에 8192 바이트를 왕창 읽어온다
BufferedFileInputStream를 만듦
원래 있던 메서드 FileInputStream.read(byte[]) 호출
바이트 배열에 담아라
파일에서 읽어서 바이트 배열에 담는다
바이트 배열에 있는 걸 리턴한다
또 달라고 하면 바이트 배열에 있을 걸 리턴한다
8192 바이트를 다 줄 때까지 바이트 배열에 있는 걸 리턴한다
더 이상 꺼낼 게 없으면 다시 요청
FileInputStream.read(byte[]) 호출
8192 바이트 채워줘
왕창 읽어서 채운다
채우고 다시 커서는 맨 앞으로 이동한다
바이트 달라고 하면 바이트 배열에 있는 거 주면 된다
언제까지? 8192 바이트를 다 줄 때까지
read() → 1개의 바이트 값을 꺼내 리턴
if (cursor == size) 만약 커서가 8192 번째에 놓여진다면
상속받은 read() 메서드를 호출해서 왕창 버퍼를 채운 다음에 커서는 다시 처음으로 이동시키고 커서가 가리키는 걸 리턴한다.
이렇게 프로그래밍을 짠 게 BufferedFileInputStream
size = read(buf) : 실제 버퍼에 읽은 개수
cursor : 앞으로 읽을 바이트의 인덱스
if (cursor == size) 가져온 거 다 읽었다는 뜻
super.read(buf) 상속받은 read() 메서드. 버퍼에 왕창 읽어온다
size = super.read(buf) size에 읽어온 개수 저장
(size = super.read(buf)) == -1 더 이상 읽어온 게 없었으면 -1 리턴
읽어왔으면 다음 문장으로 간다
cursor = 0; 커서는 다시 0으로 세팅
return buf[cursor++] & 0x000000ff;
buf[cursor++] 현재 커서가 가리키는 값을 리턴하는데
& 0x000000ff 왜 이걸 붙입니까?
파일에서 바이트 값을 꺼낼 때 주의할 점
04-입출력스트림 / 26 페이지
buf : byte[]
buf : 02 17 3f 08 ac 00 ea b0 80
int를 리턴하는 read() 라는 메서드가 있는데
커서가 가리키는 걸 리턴한다
int read() {
return buf[cursor];
}buf[i] (1 byte) → int (4 byte)
buf[i] 값을 4바이트 int 값으로 리턴한다는 거
buf[i] (1 byte) ---> int (4 byte)
02 00 00 00 02
17 00 00 00 17
3f 00 00 00 3f
08 00 00 00 08
ac 00 00 00 ac잘못됐다.
ac는 2진수로 10101100
10101100 ← 이 바이트의 값을 음수 -84로 인식한다.
첫 번째 비트는 부호 비트
부호비트가 1이면 음수
이 바이트의 값을 음수 -84로 인식한다.
음수로 만드는 법
양수값을 뒤집는다
0 → 1, 1 → 0
거기에 1을 더한다
음수 = 1의 보수 + 1
양수를 구하는 법
거꾸로 하면 된다
1을 뺀다
10101100 - 1 = 10101011
다시 뒤집는다
10101011 → 01010100 = 84
바이트 배열에 값이 들어
파일에서 읽어온 값을 음수 -84로 인식한다.
10101100 (1 byte)
11111111 11111111 11111111 10101100 (4 byte)
ff ff ff ac음수는 앞에 나머지 3바이트가 11111111이기 때문에 -84가 된다.
이걸 방지하기 위해서
-84가 아니라 ac로 하고 싶음
ac는 172
원래 172가 되어야 하는데 -84가 됨
이걸 보조하기 위해서 & 0x000000ff 하는 거
& : 둘 다 1일 때만 1이다. 둘 중에 하나라도 0이면 0이다.
ff ff ff ac = -84
& 00 00 00 ff
--------------
00 00 00 ac = 172앞에 3바이트를 0으로 날려버리는 효과
f를 다 날려버리고
어떤 값에 & 11111111을 하면 위에 있는 값을 그대로 통과시키는 효과
위에 있는 값을 그대로 수용하는 효과
그래서 마지막 바이트는 ff를 &시킨 거
ac가 그대로 통과
원래 ac 값을 온전히 지켜냄
바이트 배열에 저장된 걸 그냥 리턴하면 안 된다
바이트 배열 안에 있는 값을 그대로 리턴하면 안 된다
이런 문제가 있다
1 byte 값이 4 byte로 변환될 때
음수의 경우 앞의 3 byte가 모두 ff가 되는 문제 발생 ⟹ & 연산자로 앞 3 byte 제거
뒤에 순수 ac만 남겨두는 거
buf[cursor++] & 0x000000ff
& 0x000000ff 꼭 붙이기..
return buf[cursor++] & 0x000000ff;
// 위의 리턴 문장은 컴파일 할 때 아래의 문장으로 바뀐다.
// int temp;
// temp = buf[cursor];
// cursor++;
// return temp & 0x000000ff;cursor를 먼저 증가시키는 게 아님
일단 int 임시변수를 만들고 커서가 가리키는 버퍼의 값을 임시변수에 담는다
커서를 증가시킨다
temp & 0x000000ff 결과를 리턴한다
버퍼를 끝까지 다 읽으면 다시 상속받은 메서드로
다시 파일에서 바이트 배열로 데이터를 왕창 읽어 온다.
com.eomcs.io.ex06.Exam0130.java
실제 버퍼로 읽어온 횟수는 408번
Exam0120보다는 속도가 떨어지지만
그래서 1바이트씩 읽더라도 그렇게 속도가 떨어지지 않는 것이다.
1바이트씩 깨작깨작 가져오더라도 내부적으로 버퍼에 있는 걸 가져오기 때문에 속도가 떨어지지 않는다.
왕창 가져와서 버퍼에 담아놨다가 1바이트씩 준다.
다 떨어지면 또 왕창 가져온다.
똑같은 코드여서 속도가 훨씬 빠르다.
com.eomcs.io.ex06.Exam0210.java
BufferedFileOutputStream
com.eomcs.io.ex06.BufferedFileOutputStream.java
class BufferedFileOutputStream extends FileOutputStream
BufferedFileOutputStream
buf : bye[]
write() {...}
① write()
② 순차적으로 저장
버퍼를 사용하는 서브클래스의 특징에 맞춰서 메서드를 재정의한다.
버퍼를 사용할 때는 특히 주의해야 한다.
버퍼가 꽉 찼을 때만 파일로 내보내기 때문에
버퍼에 잔여 데이터가 남아 있을 수 있다.
버퍼의 잔여 데이터를 강제로 출력하도록 상속받은 다음 메서드를 재정의한다.
com.eomcs.io.ex06.Exam0310.java
com.eomcs.io.ex07
상속관계를 봐야 됨
상속을 통한 기능 확장의 한계
FileOutputStream
DataFileOutputStream
버퍼 기능 추가
BufferedFileOutputStream
DataBufferedFileOutputStream
상속의 한계점
데코레이터 패턴이 등장하게 된 이유
똑같은 코드를 복제하는 문제점 발생!
버퍼를 쓰면 빨라진다
버퍼를 안 쓰니까 시간이 오래 걸림
ByteArrayInputStream
파일 대신 메모리에서 데이터를 읽어들인다.
Stream API의 효용성
파일에서 데이터를 읽고 싶음
FileIntputStream read() 호출
바이트 배열에서 데이터를 읽을 때
byte[] → ByteArrayInputStream
파일에서 데이터를 읽을 때와 메모리에서 데이터를 읽을 때가 달랐는데
동일한 방법으로 데이터를 꺼낸다
1970년대 C를 창시한
키보드에서 데이터를 읽으나 하드디스크에서 데이터를 읽으나
방법이 다 다름
개발자들이 너무 불편
읽어오는 방법이 다 다름
일관된 방법으로 데이터를 읽자
그래서 나온 게 Stream API
프로세스(실행중인 프로그램) PipedInputStream
데이터를 읽는 대상(파일, 메모리, 프로세스 등)이 다르더라도
데이터를 읽는 방법은 같다! read() 호출
일관성 있는 프로그래밍 가능!
파일에서 데이터를 읽을 때는 FileIntputStream
Stream : 데이터의 흐름
상속을 통한 기능 확장의 한계 2
FileIntputStream
