4단계 - 배열 크기를 자동으로 늘린다.
if (size == contacts.length) 만약 사이즈가 배열 길이랑 같다면
배열이 꽉 찼다면 기존 배열보다 50% 큰 배열을 새로 만든다.
/ 2 → >> 1
나누기보다 비트 이동 연산이 더 빠르다
5 + (5 >> 1) = 7
5 / 2contacts: 기존 배열 주소
arr: 새 배열 주소
기존 배열 대신 새 배열을 연락처 저장 배열로 사용한다.
contacts = arr;
기존 배열은 주소를 잃어버려 garbage가 된다.
garbage가 많이 생기는 방식이어서 바람직하지는 않다
http://localhost:8080/contact/index.html
@RequestMapping("/contact/add")
public Object add(String name, String email, String tel, String company) {
// 배열이 꽉 찼다면, 기존 배열보다 50% 큰 배열을 새로 만든다.
if (size == contacts.length) {
int newCapacity = contacts.length + (contacts.length >> 1);
String[] arr = new String[newCapacity];
// 기존 배열의 값을 새 배열로 복사한다.
for (int i = 0; i < contacts.length; i++) {
arr[i] = contacts[i];
}
// 기존 배열 대신 새 배열을 연락처 저장 배열로 사용한다.
contacts = arr;
}
contacts[size++] = createCSV(name, email, tel, company);
return size;
}
5개 넘게 만들어도 잘 됨
5단계 - 배열 크기를 늘리는 코드를 별도의 메서드로 분리한다.
• 메서드로 분리한 이유
⇒ 코드의 기능을 명확하게 설명하고 싶을 때도 메서드를 활용하여 코드를 분리한다.
ContactController.grow()
// 기능
// - 배열의 크기를 늘린다.
// - 기존 배열의 값을 복사해온다.
//
String[] grow() {
// 배열이 꽉 찼다면, 기존 배열보다 50% 큰 배열을 새로 만든다.
int newCapacity = contacts.length + (contacts.length >> 1);
String[] arr = new String[newCapacity];
// 기존 배열의 값을 새 배열로 복사한다.
for (int i = 0; i < contacts.length; i++) {
arr[i] = contacts[i];
}
return arr;
} // 기능
// - 배열의 크기를 늘린다.
// - 기존 배열의 값을 복사해온다.
//
String[] grow() {
// 배열이 꽉 찼다면, 기존 배열보다 50% 큰 배열을 새로 만든다.
int newCapacity = contacts.length + (contacts.length >> 1);
String[] arr = new String[newCapacity];
// 기존 배열의 값을 새 배열로 복사한다.
for (int i = 0; i < contacts.length; i++) {
arr[i] = contacts[i];
}
return arr;
} @RequestMapping("/contact/add")
public Object add(String name, String email, String tel, String company) {
// 배열이 꽉 찼다면,
if (size == contacts.length) {
contacts = grow(); // 메서드 이름에서 해당 코드에 대한 설명을 짐작할 수 있다.
}
contacts[size++] = createCSV(name, email, tel, company);
return size;
}remove 메서드로 따로 분리한 이유도 같다.
@RequestMapping("/contact/delete")
public Object delete(String email) {
int index = indexOf(email);
if (index == -1) {
return 0;
}
remove(index); // 메서드 이름으로 코드의 의미를 짐작할 수 있다. 이것이 메서드로 분리하는 이유이다.
return 1;
}한 번에 그렇게 짠 게 아니라 짜놓고 계속 메소드로 빼내고 그런 거...
6단계 - 배열 크기를 계산하는 코드를 별도의 메서드로 분리한다.
• 메서드로 분리한 이유
⇒ 코드의 기능을 명확하게 설명하고 싶을 때도 메서드를 활용하여 코드를 분리한다.
// 기능
// - 주어진 배열에 대해 50% 증가시킨 새 배열의 길이를 알려준다.
int newLength(int oldCapacity) {
return oldCapacity + (oldCapacity >> 1);
}보통 메서드 이름은 명령 형태의 동사구로 짓는다.
물론 명사구나 전치사구 형태로 짓는 경우도 있다.
// 기능
// - 배열의 크기를 늘린다.
// - 기존 배열의 값을 복사해온다.
//
String[] grow() {
int newCapacity = newLength(contacts.length);
String[] arr = new String[newCapacity];
for (int i = 0; i < contacts.length; i++) {
arr[i] = contacts[i];
}
return arr;
}굳이 newCapacity라는 임시 변수 안 만들고 바로 집어 넣기
// 기능
// - 배열의 크기를 늘린다.
// - 기존 배열의 값을 복사해온다.
//
String[] grow() {
String[] arr = new String[newLength(contacts.length)];
for (int i = 0; i < contacts.length; i++) {
arr[i] = contacts[i];
}
return arr;
}다시 아래처럼 바꾸기
지금 단계에서는 이 정도만...
newLength() ← 메서드 이름으로 코드의 의미를 짐작할 수 있다.
// 기능:
// - 배열의 크기를 늘린다.
// - 기존 배열의 값을 복사해온다.
//
String[] grow() {
String[] arr = new String[newLength()]; // 메서드 이름으로 코드의 의미를 짐작할 수 있다.
// 기존 배열의 값을 새 배열로 복사한다.
for (int i = 0; i < contacts.length; i++) {
arr[i] = contacts[i];
}
return arr;
}
// 기능:
// - 주어진 배열에 대해 50% 증가시킨 새 배열의 길이를 알려준다.
int newLength() {
return contacts.length + (contacts.length >> 1);
}메서드를 호출해서 속도를 떨어뜨리는 대신 코드의 가독성이 좋아진다.
최적화(optimizing) vs 리팩토링(refactoring)
코드의 가독성 중요!!
최적화(optimizing)
‐ 실행 과정을 단축
‐ 자원(메모리) 사용 최소화
• 목표: 실행 속도 향상
• 단점: 코드를 읽기 어렵다. → 기능 추가/변경/삭제가 어렵다. → 유지보수에 시간이 많이 든다.
⇒ 사람을 더 투입하면 된다.
• 비용: 더 적은 자원(CPU, 메모리)을 사용
리팩토링(refactoring)
‐ 코드를 유지보수하기 쉽게 더 잘게 분리한다.
• 목표: 코드의 가독성, 재사용성 향상
• 단점: 실행 단계가 더 많아진다. → 실행 속도가 느려진다. → 블레이드 시스템, 그리드 컴퓨팅
⇒ 메인모드 추가하면 쉽게 해결
• 비용: 유지보수에 시간이 더 적게 소요된다.
하드웨어보다 인건비가 더 비쌈
지금은 리팩토링 시대
속도가 느리면 그 부분만 최적화를 진행하면 된다.
최적하는 초보자가 하는 게 아니라 경력자가...
유지보수가 좋은 코드를 작성하는 게 더 중요
속도와 메모리 크기는 얘기하지말기
따로 주석을 달 필요 없이 뭐하는 애인지 명확
7단계 - 배열을 복사하는 코드를 메서드로 분리한다.
Arrays.copyOf(기존 배열, 새 배열)
argument를 잘못 입력할 경우를 대비해서 다음 코드를 추가한다.
target 배열이 source 배열보다 작은 경우, 반복할 때 오히려 target 배열 만큼만 반복해야 된다.
원래는 source 배열 만큼 반복문을 돌릴 건데,
target 배열이 source 배열보다 작은 경우, target 배열 만큼만 돌리겠다.
• 이렇게 하는 이유?
메서드를 만들 때 그 메서드를 잘못 사용하는 경우까지 고려해서 코드를 짜야 한다.
잘못 동작하는 것을 방지
// 기능:
// - 배열을 복사한다.
//
void copy(String[] source, String[] target) {
// 개발자가 잘못 사용할 것을 대비하여 다음 코드를 추가한다.
// 즉 target 배열이 source 배열보다 작을 경우 target 배열 크기만큼만 복사한다.
int length = source.length;
if (target.length < source.length) {
length = target.length;
}
for (int i = 0; i < length; i++) {
target[i] = source[i];
}
} // 기능:
// - 배열의 크기를 늘린다.
// - 기존 배열의 값을 복사해온다.
//
String[] grow() {
String[] arr = new String[newLength()];
copy(contacts, arr);
return arr;
}com.eomcs.lang.ex07
com.eomcs.lang.ex07.Exam0110.java
Toggle Breakpoint
Context menu (컨텍스트 메뉴)
컨텍스트 메뉴 또는 상황에 맞는 메뉴는 그래픽 사용자 인터페이스 안에서 어떠한 항목을 클릭할 때 뜨는 팝업 메뉴로, 메뉴를 호출한 동작, 응용 프로그램의 실행, 선택된 항목의 상
황에 따라 다양한 선택 사항을 나열하여 보여준다. 바로 가기 메뉴라고도 한다.
Step Over
Step Into
주석을 달았다는 건 딱 봤을 때 뭐하는 함수인지 잘 모르겠다는 거
→ 유지보수에 힘들다는 거
메서드
static이 안 붙은 메소드는 static이 안 붙은 메소드를 호출할 수 있다.
main처럼 static이 붙어 있는 메소드는 static이 안 붙어 있는 메소드를 호출할 수 없다.
리턴할 필요 없으면 리턴 타입을 void로 한다.
public static void main(String[] args) {
Scanner keyScan = new Scanner(System.in);
System.out.print("밑변의 길이? ");
int len = keyScan.nextInt();
keyScan.close();
for (int starLen = 1; starLen <= len; starLen += 2) {
// 별 앞에 공백 출력
printSpaces((len - starLen) / 2);
// 별 출력
printStars(starLen);
// 출력 줄 바꾸기
System.out.println();
}
} static int getSpaceLength(int total, int starLen) {
return (total - starLen) / 2;
} public static void main(String[] args) {
Scanner keyScan = new Scanner(System.in);
System.out.print("밑변의 길이? ");
int len = keyScan.nextInt();
keyScan.close();
for (int starLen = 1; starLen <= len; starLen += 2) {
// 별 앞에 공백 출력
printSpaces(getSpaceLength(len, starLen));
// 별 출력
printStars(starLen);
// 출력 줄 바꾸기
System.out.println();
}
}com.eomcs.lang.ex07.Exam0210.java
파라미터 변수의 타입과 개수와 순서에 맞게 값을 넘겨줘야 한다.
타입, 개수, 순서 일치해야 됨!!
만약 변수의 타입과 값의 타입이 다르면 컴파일 오류!
만약 변수의 개수와 값의 개수가 다르면 컴파일 오류!
변수 선언 순서와 값의 순서가 다르면 컴파일 오류!
값을 리턴하지 않는 메서드에 대해 변수를 선언하면 컴파일 오류!
[리턴 타입] 메소드명(파라미터 선언) {
메소드 바디
}실행 과정
1) hello() 메서드의 블록으로 간다.
2) 메서드 바디를 실행한다.
3) 다시 원래 위치(호출했던 위치)로 돌아온다.
4) 다음 줄을 실행한다.
Debug
Step Over : 코드를 실행하고 다음으로 가는 거
Step Into : 코드 안으로 들어가는 거
내가 짠 코드를 확인하거나 남이 짠 소스코드를 확인하고 싶을 때 안으로 들어가는 거
안으로 들어간 상태에서 Step Over 클릭
Step Return : 안으로 들어간 거에서 한 번에 나오고 싶을 때
메서드 종류?
1) 클래스 메서드
‐ 클래스에 소속되어 있다.
‐ 모든 인스턴스가 공유한다.
‐ static이 붙는다.
2) 인스턴스 메서드
‐ 특정 인스턴스에 대해 사용한다.
‐ static이 붙지 않는다.
자바스크립트에서는 파라미터가 없는 메소드도 아규먼트를 넘겨주면 에러가 안 나는데 자바는 에러남
hello 메서드는 파라미터 변수가 없기 때문에 호출할 때 값을 넣으면 컴파일 오류!
hello(100); ← 컴파일 오류!

값을 리턴하지 않는 메서드에 대해 변수를 선언하면 컴파일 오류!
hello 메서드는 값을 리턴하지 않기 때문에 변수로 값을 받으려 하면 컴파일 오류!
int i;
i = hello(); ← 컴파일 오류!
파라미터는 로컬 변수!
메서드를 실행할 때 사용할 값을 외부로부터 받기 위해 선언한 로컬 변수.
메서드를 실행할 때 생성되고 메서드 실행이 끝나면 제거된다.
프로그램 엔트리 포인트
public static void main(String[] args)
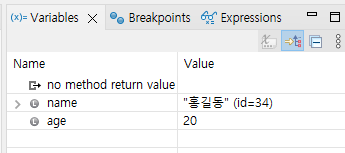
현재 실행하고 있는 메서드의 변수
hello 끝나서 사라짐
파라미터의 타입, 개수, 순서가 일치해야 한다.
리턴한 후에 작업을 수행할 수 없다.
return 문장 다음에 또 문장이 오면 안 됨
Unreachable code
리턴 타입과 다른 타입의 변수로 값을 받으려 하면 컴파일 오류!
com.eomcs.lang.ex07.Exam0240
Step Return : 메서드 들어간 김에 실행하고 나오라는 거
메서드 : 가변 파라미터
com.eomcs.lang.ex07.Exam0250
[리턴타입] 메서드명(타입... 변수) {...}
⟹ 0 개 이상의 값을 받을 때 선언하는 방식
⟹ 메서드 내부에서는 배열처럼 사용한다.
0 개 이상이니까 안 줘도 됨
가변 파라미터 자리에 배열을 직접 넣어도 된다.
다른 타입은 안된다. 컴파일 오류!
0251번 새로 만듦
com.eomcs.lang.ex07.Exam0251
가변 파라미터에 배열을 넘길 경우 그 배열을 그대로 받아 사용한다.
package com.eomcs.lang.ex07;
// # 메서드 : 가변 파라미터
//
public class Exam0251 {
// 가변 파라미터에 배열을 넘길 경우
// 기존 배열을 그대로 사용할까? 아니면 파라미터로 받은 배열을 복제해서 사용할까?
// => 가변 파라미터에 배열을 넘길 경우 그 배열을 그대로 받아 사용한다.
static void hello(String... names) {
for (int i = 0; i < names.length; i++) {
names[i] += "^^";
System.out.printf("%s님 반갑습니다.\n", names[i]);
}
}
public static void main(String[] args) {
String[] arr = {"김구", "안중근", "윤봉길", "유관순"};
// 가변 파라미터에 배열을 넘길 경우
hello(arr);
System.out.println("-------------------");
for (String value : arr) {
System.out.println(value);
}
}
}com.eomcs.lang.ex07.Exam0260
메서드 : 가변 파라미터 vs 배열 파라미터
배열 파라미터의 메서드를 호출할 때는 오직 배열에 담아서 전달해야 한다.
아예 컴파일이 안 됨
com.eomcs.lang.ex07.Exam0270
가변 파라미터의 단점
가변 파라미터는 메소드당 한 개만 선언 가능
배열 파라미터는 여러 개 선언 가능
가변 파라미터는 반드시 맨 끝에 와야 한다.
결론!
‐ 메서드에 가변 파라미터는 한 개만 사용할 수 있다.
‐ 가변 파라미터는 반드시 맨 뒤에 와야 한다.
‐ 그 이유는 복잡한 사용을 막기 위해!
가변 파라미터 사용 예
PrintStream java.io.PrintStream.printf(String format, Object... args)

아무거나 올 수 있어서 Object
배열 파라미터는 순서에 상관 없다.
com.eomcs.lang.ex07.Exam0280
메서드 : 메서드 중첩 호출
메서드를 호출하는 문장의 가장 안쪽부터 실행된다.
result = plus(plus(plus(2, 3), 4), 5);
메서드 : call by value와 call by reference
com.eomcs.lang.ex07.Exam0310
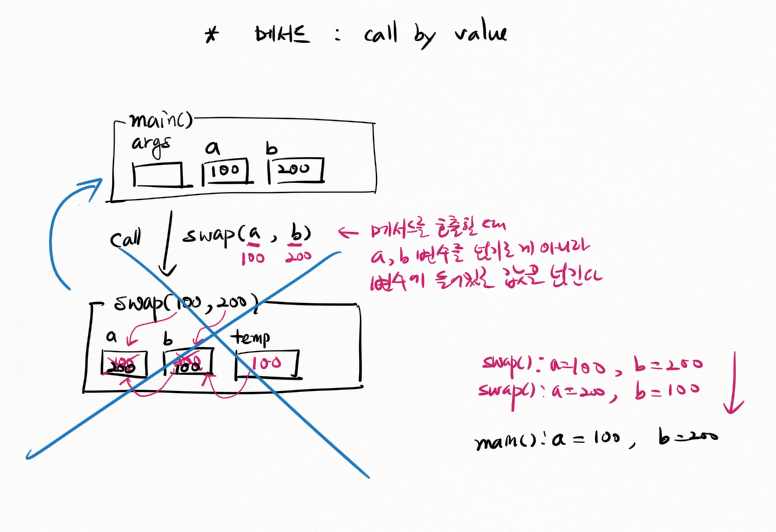
메서드 : call by value
swap의 호출이 끝나면 로컬 변수는 사라진다
call by value
아규먼트가 primitive data type인 경우, 메서드를 호출할 때 값을 넘긴다.
자바에서는 primitive data type에 대해서 메모리(변수) 주소를 넘기는 방법이 없다.
main 메소드에 있는 a, b는 전혀 상관없는 변수임
메서드를 호출할 때 a, b 변수를 넘기는 게 아니라 변수에 들어 있는 값을 넘긴다.
com.eomcs.lang.ex07.Exam0320
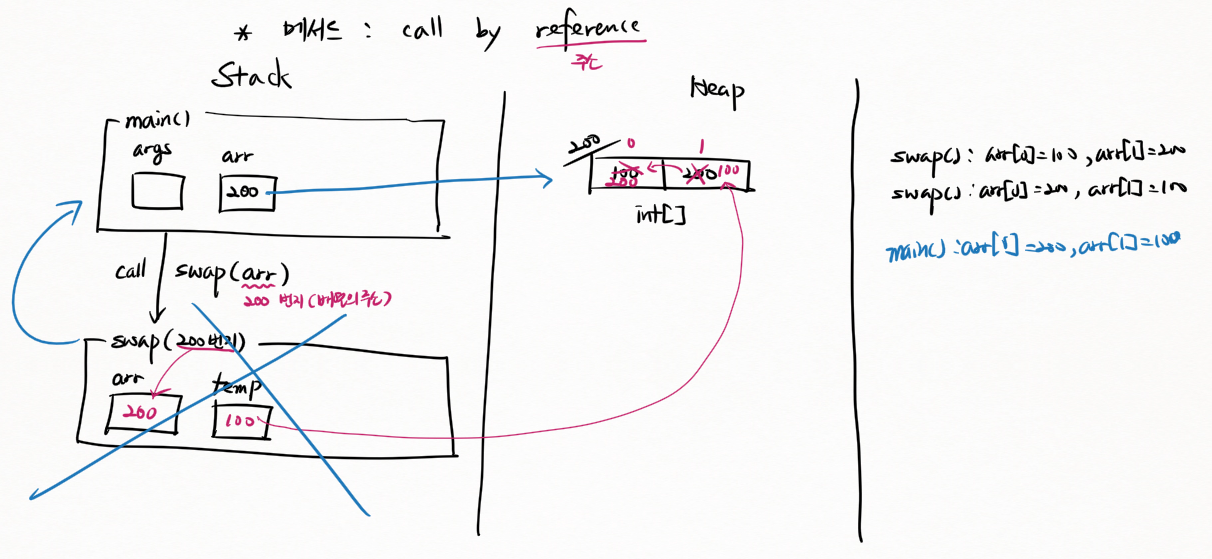
메서드 : call by reference
배열 인스턴스(메모리)를 넘기는 것이 아니다. 주소를 넘기는 것이다.
그래서 "call by reference" 라 부른다.
main 메소드에서 사용하는 메모리가 준비가 된다
로컬 변수는 Stack이라는 공간에 만들어진다.
로컬 변수 arr ← 배열의 주소
배열은 다른 공간에 만들어진다.
Heap이라는 공간에 만들어진다.
main에 있는 변수도 200번지를 가리키는 거고 swap에 있는 변수도 200번지를 가리킨다.
swap(): arr[0]=100, arr[1]=200
swap(): arr[0]=200, arr[1]=100
main(): arr[0]=200, arr[1]=100호출이 끝난 순간 지우고 리턴한다
다시 메인으로 돌아왔다
메인에서도 200번지를 가리키고 있으므로 arr[0]=200, arr[1]=100
바뀐 값
주소를 넘겼기 때문
같은 메모리를 가리키기 때문에
JVM과 메모리 영역
com.eomcs.lang.ex07.Exam0410
메서드 : JVM 메모리
① 실행
JVM
② 운영체제에게 메모리 요청
운영체제가 메모리를 준비한다
③ RAM에서 사용하지 않는 영역을 찾아서 JVM에게 사용권을 부여한다.
④ 사용
사용 목적에 따라서 영역을 나눈다. 크게 3개로 나눔.
JVM은 OS가 빌려준 메모리를 사용하기 전에 목적에 따라 관리하기 쉽도록 나눈다.
1. Method Area
클래스 코드(바이트 코드)를 둔다. → 메서드 코드가 여기에 놓인다.
static 변수를 둔다.
2. Heap
인스턴스를 둔다. → 객체, 배열
new 라는 명령어로 만드는 애들이 다 올라간다
3. JVM Stack
메서드 실행 시 로컬 변수를 둔다.
클래스 실행 과정과 메모리 영역 - Exam0410
410번
$ java Exam0410
JVM
3등분
① Method Area에 메모리에 클래스 코드를 로딩한다. → "클래스 로딩"
이걸 클래스 로딩이라고 한다.
② main()을 찾아서 실행
③ main() 메소드가 사용할 로컬 변수 준비한다. (JVM Stack)
main() 메소드가 사용할 메모리를 준비한다.
④ swap() 호출 → 로컬 변수 준비
swap()을 호출하면 swap()이 사용할 메모리를 준비한다.
파라미터 변수 a, b, 변수 temp → 3개
⑤ swap() 호출 종료 → JVM Stack에서 제거한다.
메소드 호출이 끝나면 지운다.
⑥ main() 호출 종료 → JVM Stack에서 제거한다.
main() 메소드 호출이 끝나면
⑦ JVM 실행 종료 → JVM이 OS로부터 받은 메모리 반납 (OS가 회수한다.)
클래스를 먼저 메모리에 올려야 됨
메모리에 올려놓고 메모리에 올려
실제로는 우리가 사용하는 클래스가 다 올라가 있다
Heap에는 new 라는 명령어로 만드는 애들이 다 올라감
클래스 실행 과정과 메모리 영역 - Exam0420
$ java - Exam0420
① Exam0420 클래스를 Method Area 메모리에 로딩
② main() 호출
public static void main이 반드시 있어야 함
③ main()의 로컬 변수를 준비
main()이 호출되면 JVM Stack에 main()의 로컬 변수를 준비
main() 메서드 코드는 JVM Stack에 없음
④ getArray()의 로컬 변수 준비
변수 선언 => 변수를 만들라는 명령문
int 배열 주소를 담을 arr 변수를 JVM Stack 영역에 준비하라!
JVM Stack에 준비해!
⑤ int 배열 준비
new는 무조건 Heap
100, 200, 300 값을 담은 배열을 Heap 영역에 준비하라.
⑥ 주소 저장
Heap 영역에 준비한 배열 메모리의 주소를 JVM Stack 메모리에 있는 arr 변수에 넣어라.
⑦ 리턴한 배열 주소 저장
리턴값 저장됨
⑧ getArray() 호출 종료 → JVM Stack에서 제거한다.
배열 객체 (배열 인스턴스)
어디에서 만드는 게 중요한 게 아님
어느 방법이 더 소스 코드를 이해하기 좋으냐
