cs-tips
1.컴공 잡지식 시리즈 소개

학교 수업을 들으면서, 개발을 하면서, 공부를 하면서 얻은 여러 잡지식들을 공유하는 시리즈입니다.
2.Removing File / Directories in Linux
학교에서 VM을 할당받으면 맨날 리눅스 VM이었다.다행히 첫 수업에서 VSC 활용법을 자세히 알려줬었기 때문에 터미널에서 cmd 입력하면서 파일 관리를 할 일은 거의 없었지만...가끔 VM을 내 실수로 터뜨려버릴때 putty로 원격 접속을 해가지고 분석하거나 특정 파일
3.GUI 없이 heaptrack으로 메모리 누수 확인하기
C++로 작성된 프로그램을 수정하는 개별연구를 진행하다가 메모리 누수를 프로파일링 해야 할 일이 생겼었는데, 이때 사수님이 heaptrack이라는 프로그램을 추천해줬다.한글로 된 heaptrack 사용법 1한글로 된 heaptrack 사용법 2위 링크를 가지고 사용법을
4.standard stream redirection / pipelining
다들 linux를 쓰는 저마다의 이유가 있겠지만... 나같은 경우에는 다음과 같다.linux command가 window command보다 사용하기 편해서linux os 구조를 window os 구조보다 더 잘 알고 있어서 관련 문제 해결이 좀 더 용이해서mac이 없어
5.backing field, 그리고 이에 따른 property들의 initialization 여부
Kotlin 공부 중에 backing field에 관한 내용이 나왔는데, 이에 대해 만족스러울 정도로 분석한 하나의 글이 없어서 직접 분석해본 후 정리해 봤다.간단히 말하자면 class의 property (혹은 attribute)를 접근하거나 읽으려고 할 때 호출되는
6.argument / keyword-argument unpacking parameters
우리가 foo를 다음과 같이 정의했다고 해보자.이렇게 정의하면 다음과 같이 호출하면뒤의 '위치'상 과도한 개수의 parameter들은 args에 들어가게 할 수 있다. 이때 args의 type은 tuple이며, 만약 초과된 parameter이 없으면 empty tupl
7.Domain-Driven Design
프로그램 디자인 방식 중 하나다.business domain과 일치하게 소프트웨어를 모델링 하는 것이다. 여기서 business domain이란... 그냥 유사한 업무의 집합이다.기본적으로 loose decoupling, 그러니까 서로 다른 domain간의 의존성은 최
8.Factory and Repository in software design
같은 개념을 공유하는 다양한 object들이 각기 다른 환경에서, 다른 작업을 하는 경우는 꽤 흔하다. 예를들어 배랑 차는 둘 다 '운송'을 할 수 있지만, 어디서 어떻게 운송을 하는지는 다 다르다.이를 각 class에 대해 일일이 구현하는 것은 프로그램을 매우 복잡하
9.git - remote 및 repository 관련 여러 상호작용
git과 관련된 협업을 어떻게 해야하는지 따로 공부하는 과정에서 알게 된 점 몇가지를 여기에 정리했다.처음 git을 하면서 가장 많이 써본 명령어는... github에서 남의 repository를 fork 후 git clone이었다. 이때 git clone은 단순히 해
10.MySQL - CONCAT_WS
개인적으로 공부하다 발견해서 정리.column attribute를 separator을 사용해서 뭉쳐가지고 하나의 column attribute로 만들어버릴 때 사용된다. 이거랑 alias를 활용해가지고 새로운 field를 만드는게 가능함.밑의 경우, Address라는
11.Cuckoo Trie : Exploiting Memory-Level parallelism for Efficient DRAM indexing 정리
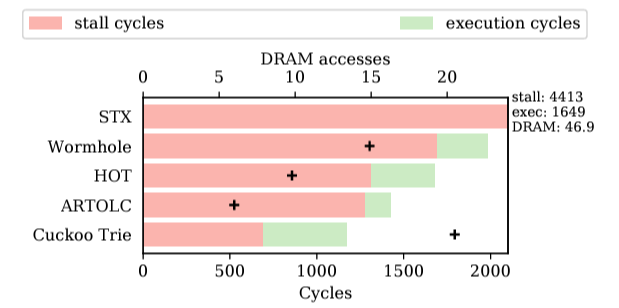
원본 논문DB는 query 처리를 가속화하기 위해 정렬된 index에 많이 의지함.query의 실행 시간 중 최대 94%가 indexing에 소요되고, DB 메모리 중 최대 55%가 indexing structure을 저장하는데 소요됨 → 빠르고 메모리 사용량이 적은
12.크롬 developer tool의 Pause on exceptions button 관련
내가 개인적으로 공부중인 JS 튜토리얼에 보면 다음 버튼이 크롬에 있다고 한다. 좋아보이는 기능이다. 하지만 해당 버튼은 최신 크롬에 없다. 대신 최신 크롬의 developer tool의 breakpoint 부분을 보면 다음과 같은 체크박스 2개가 있다. 바로 P
13.개인적으로 가장 편하다고 생각하는 JS 입력 처리
JS에서 출력은 쉽다. console.log문제는 입력. 개인적으로는 이것을 활용하는게 제일 좋아보인다.자 stdin은… 이제 하나의 array다.input은, 함수인데, lexical environment를 활용해 (closure) line에 접근이 가능한 함수이며,
14.C++ 배열 탐구와 배열로 이루어진 queue 만들기
하반기 채용 준비를 위한 여러가지 (임베디드/펌웨어 공부, OS/기조직 복습, STM32 보드 갖고 놀기 등등)을 하고 있는데... 그 중 하나가 코테 대비를 위한 알고리즘 풀이다.하이닉스가 C++만 허용한다고 하고, C/C++을 안 다뤄본 것도 아니고 (오히려 가장
15.alignment 맞추는 malloc, posix_memalign
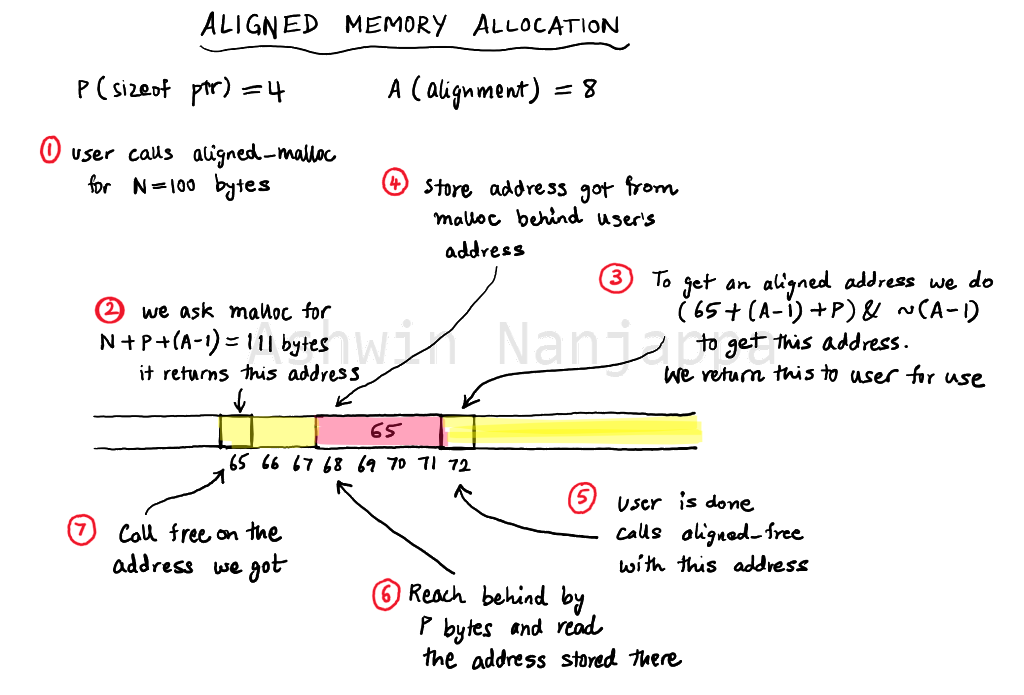
가끔 성능 최적화를 위해 혹은 동작 자체를 위해 aligned된 memory를 할당 할 필요가 있다. 대표적으로캐시 성능. 캐시 entry에 딱 맞는 데이터인데 alignment가 안 맞춰져 있으면 두 개의 캐시 entry를 써야 하는 불상사가 생길 수 있다. 용량도
16.C++ pair을 위한 hashing
이 글을 쓰게 된 경위는 이 문제를 풀면서 발생위 문제를 풀다보니 pair<string, string>을 위한 hash를 구해야 할 일이 생겼다. 문제는 C++에서 primitive type에 기반한 pair을 위한 hashing을 제공하지 않는다는 점.이거랑 약
17.VS Code C++ 실행/디버깅 편하게 하기 + 백준을 위한 redirection setup
알고리즘 문제를 풀 환경을 설정하다가 유용한 것 같아서 그리고 내가 나중에 까먹을 것 같아서 공유한다.검색하면 자주 보이는 CodeRunner을 사용하는 것이 아니라 C/C++ Runner이라는 확장자를 활용하는 방식이다. 매우 유용한 확장자라서 굳이 이 용도가 아니더