문제
문자열이 팰린드롬(뒤집어도 같은 문자열)이면 true, 아니면 false를 반환
- 대소문자 구분 없음
- 영문과 숫자만 취급
풀이
Trial 1st (List 활용)
입출력 예시를 보면 특수문자가 포함되어 있는데, 문제에서는 영문과 숫자만 취급하라고 했으므로 영문과 숫자만 새 리스트에 append 해준다. 관련된 함수는 2개가 있다.
(1) isalpha()
문자열이 영어 혹은 한글이면 참, 아니면 거짓
(2) isalnum()
문자열이 영어 혹은 한글 혹은 숫자이면 참, 아니면 거짓
isalnum() 을 통해 영문과 숫자만 찾아서, lower()를 이용해서 소문자로 변환한 후, 새로운 리스트에 넣어준다. (내가 헷갈려서 찾아본 것: capitalize()는 첫 문자를 대문자로 만들고 나머지 문자를 소문자로 변환한다.)
# 리스트 선언
str = []
# 영문 및 소문자만 찾아서 영문이라면 소문자로 변환하여 리스트에 넣어줌
for char in s:
if char.isalnum():
str.append(char.lower())n번의 비교를 통해 조건에 부합하는지 판단하는 상황이므로
반환 기본 값을 True로 해놓고 조건이 안 맞을 시 False를 반환하는 기법을 사용한다.
문자열 길이가 홀수라서 문자 1개가 남는 경우에 대비해 반복 조건은 len(str)>1 로 잡아준다.
위에서 정제한 문자열의 양 끝을 비교해야 하는데, 리스트를 따로 복사하지 않고 pop(0)과 pop()을 이용해 하나의 리스트에서 모두 해결한다.
# 팰린드롬 유무 판별 (문자열 양끝이 같지 않을 시 false 반환 후 종료)
while len(str) > 1:
if str.pop(0) != str.pop():
return False
# 팰린드롬 유무 판별 (발견하지 못했다면 True 반환 후 종료)
return True전체 코드는 다음과 같다.
class Solution:
def isPalindrome(self, s: str) -> bool:
# 리스트 선언
str = []
# 영문 및 소문자만 찾아서 영문이라면 소문자로 변환하여 리스트에 넣어줌
for char in s:
if char.isalnum():
str.append(char.lower())
# 팰린드롬 유무 판별 (문자열 양끝이 같지 않을 시 false 반환 후 종료)
while len(str) > 1:
if str.pop(0) != str.pop():
return False
# 팰린드롬 유무 판별 (발견하지 못했다면 True 반환 후 종료)
return True깔끔한 코드지만 주어지는 문자열 길이는 1 <= s.length <= 2 * 105 이다. 리스트의 pop(0) 연산이 O(n) 복잡도를 가지기 때문에, 문자열이 길어질수록 복잡도가 크게 증가할 것이다.
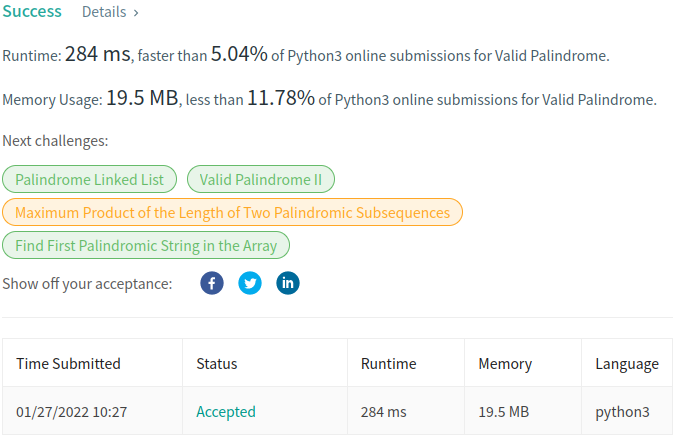

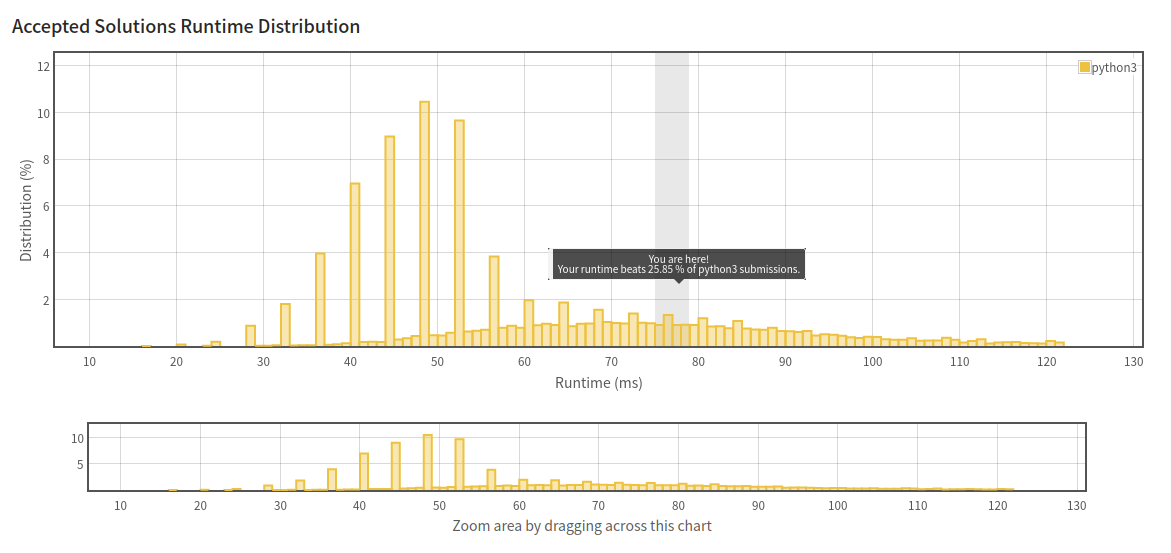
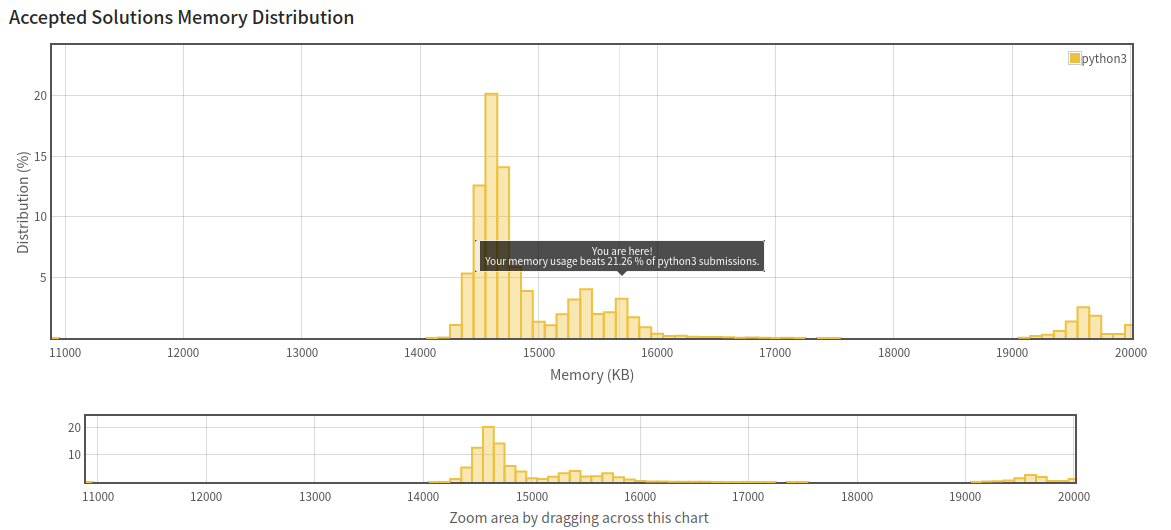
런타임이 284~680ms나 되고, 680ms는 정답자 분포 차트에서는 아예 열외인 속도이다.
조금 더 성능 향상을 해보자. pop(0)의 시간을 줄이는 방법은 collections.deque를 쓰는 것이다. deque를 이용해서 다시 코드를 짜본다.
Trial 2nd (Collections.deque 활용)
아까는 리스트로 선언해줬지만(str=[] ), 이번에는 deque로 선언해준다.
str: Deque = cellections.deque()deque에도 append 연산자가 있으므로 영문과 숫자만 소문자로 변환해서 deque로 넣는 코드는 리스트와 동일하다.
# 영문 및 소문자만 찾아서 영문이라면 소문자로 변환하여 deque에 넣어줌
for char in s:
if char.isalnum():
str.append(char.lower())팰린드롬을 판별하는 구문도 동일하다. 다만 리스트에서 dequeue 연산은 pop(0)이었지만 deque에서 dequeue 연산은 popleft() 이다.
# 팰린드롬 유무 판별 (문자열 양끝이 같지 않을 시 false 반환 후 종료)
while len(str) > 1:
if str.popleft() != str.pop():
return False돌려보면 런타임이 리스트를 사용했을 때보다 훨씬 개선된 것을 확인할 수 있다. 최상은 아니지만 중간까지는 왔다.

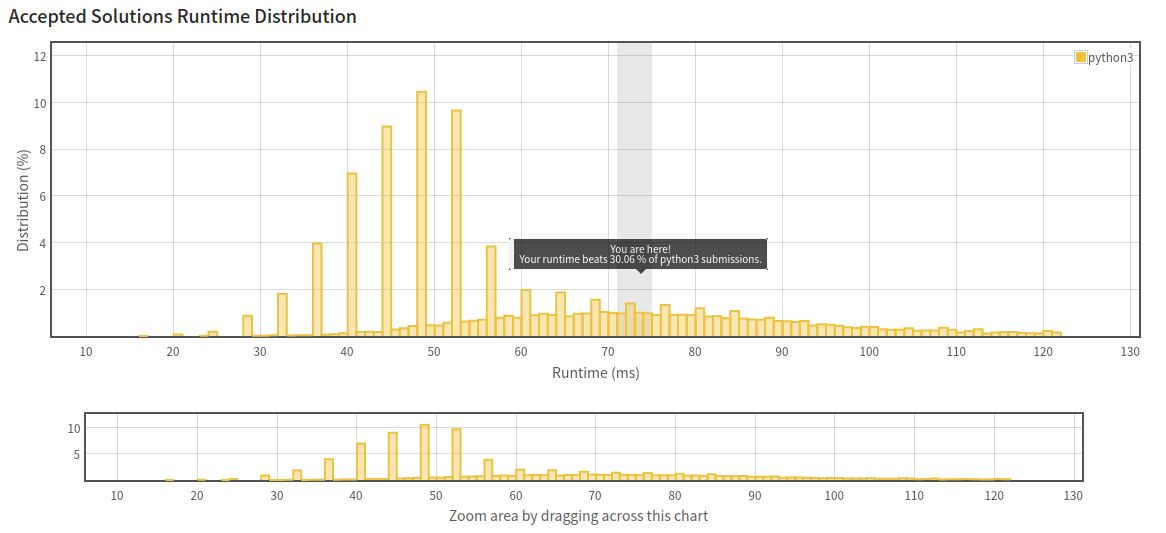
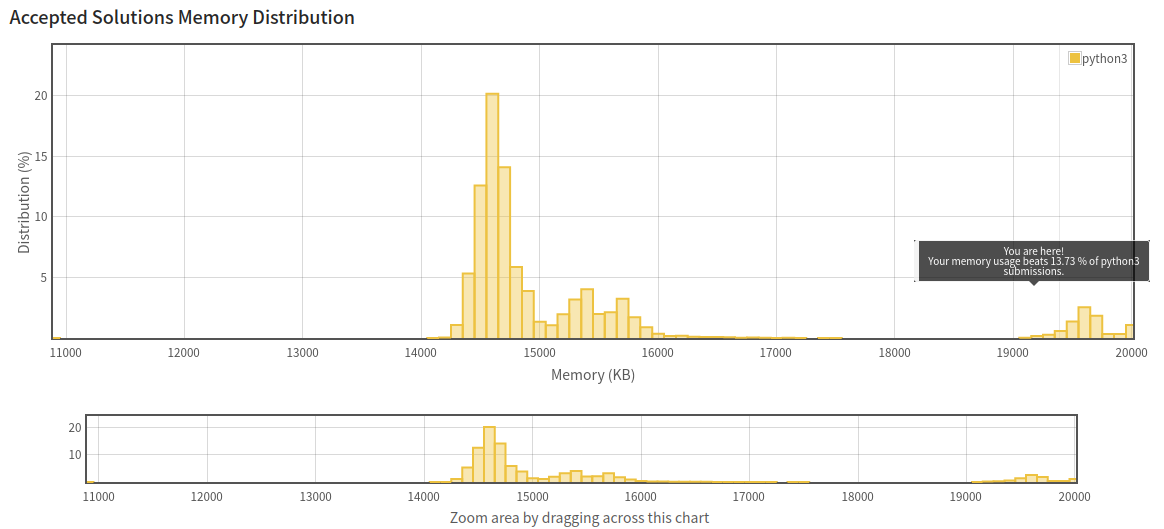
그런데 메모리 효율이 안 좋다. 겨우 차트인을 한 수준이다.
Trial 3rd
좀더 개선을 해보려면 반복문을 최대한 제거해준다.
for문을 돌리면서 문자와 숫자를 찾고, 소문자 변환을 해줬는데 문자열에 바로 lower()를 해준다.
str = s.lower()문자열에서 영문과 숫자 외의 문자는 제거하는 작업을 정규표현식으로 해준다. 표현식을 여러 방법을 사용할 수 있다.
str = re.sub('[^a-z0-9]', '', str)
str = re.sub('[\W]', '', str)
str = re.sub('[^\w]', '', str)
str = re.sub('[^\da-z]', '', str)\d는 [0-9]와 동일하고 \w는 [a-zA-Z0-9_]와 동일하며 \D와 \W는 부정(^)이다. 이때 \w와 \W는 _ 포함하는 것에 주의하자.
정규표현식은 아래 사이트에서 연습해 볼 수 있다.
RegExr: Learn, Build, & Test RegEx
마지막으로 pop 연산을 사용하지 않고 인덱스 슬라이싱을 사용해서 빠르게 비교해주고 T/F를 반환해준다.
return s == s[::-1]인덱스에서 -1은 뒤에서 첫번째를 의미한다. 시퀀스 객체의 길이가 얼마일지 정확히 알 수 없는 상황이므로 시작 인덱스와 마지막 인덱스를 모두 비워두고, 증감폭을 -1로 두어 -1, -2, -3.. 순서로 맨 뒤에서부터 차례대로 내려오게 한다.
class Solution:
def isPalindrome(self, s: str) -> bool:
# 문자열 소문자 변환
str = s.lower()
# 영문, 숫자 외 문자 제거
str = re.sub('[^a-z0-9]', '', str)
# 팰린드롬 유무 판별 (발견하지 못했다면 True 반환 후 종료)
return str == str[::-1]deque를 사용했을 때와 런타임은 비슷하지만 메모리 사용이 훨씬 개선된 것을 확인할 수 있다.