1. Ensemble Learning
- 여러 개의 기본모델을 활용하여 하나의 새로운 모델을 만들어내는 개념
- Test데이터에 대해 다양한 의견(예측값)을 수렴하기 위해 overfitting이 잘되는 모델을 기본적으로 사용
- 가장 많이 사용되는 모델: 랜덤포레스트, boosting
1) 종류
<Tree기반의 단일 모델(패키지 함수)>
- Bagging: 모델을 다양하게 만들기 위해 데이터를 재구성
- RandomForest: 모델을 다양하게 만들기 위해 데이터 뿐만 아니라, 변수도 재구성
- Boosting: 맞추기 어려운 데이터에 대해 좀더 가중치를 두어 학습하는 개념
*Adaboost, Gradient boosting(Xgboost, LightGBM, Catboost)
<Ensemble의 한 개념>
- stacking: 모델의 output값을 새로운 독립변수로 사용
2. Bagging(bootstrap aggregating)
- 복원추출
- 전체데이터의 63%만 추출됨
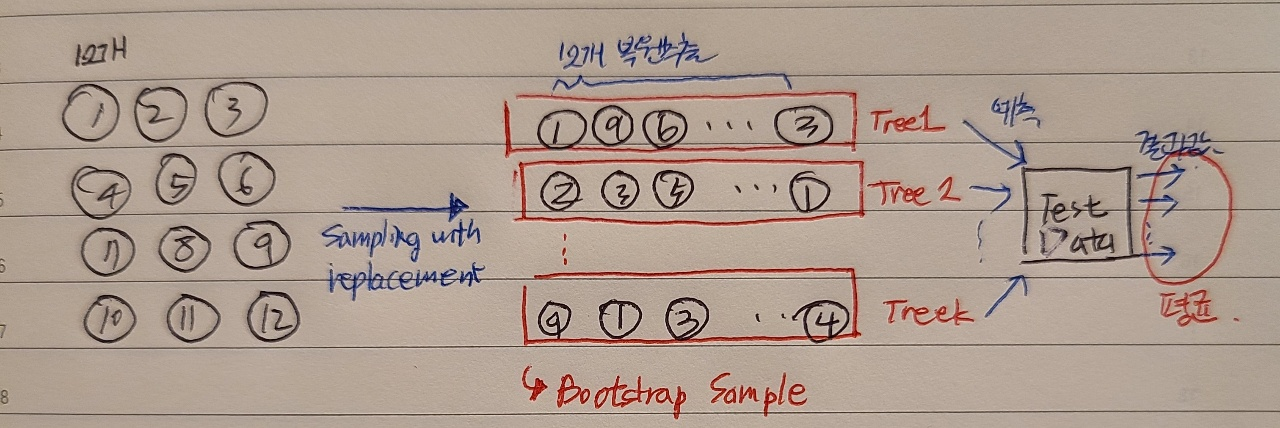
Out-Of-Bag error (OOB error)
- TreeN에서 사용하지 않은 데이터로 Error율 계산
- Error율의 평균 값 -> OOB error를 성능지표로 활용
- 목적: 남는 데이터를 검증데이터로 활용하기 위함
Tree vs Bagging
- 깊이 성장한 Tree: overfitting이 크다= 분산이 강하다
- Bagging을 통해 Tree들의 편향을 유지시킴 -> 전체적인 분산을 감소시킬 수 있음
- 학습데이터의 noise에 강건해짐
- 단, 모형해석이 어려워짐
3. Random Forest
1) Bagging의 문제점
Bagging model(여러 트리들)의 분산은 각각 트리들의 분산과 그들의 공분산으로 이루어져 있음
-> 전체데이터에서 복원 추출했으나, 각각의 트리들은 중복되는 데이터를 다수 가지고 있기 때문에 독립이라는 보장이 없음
-> Cov(X,Y)=0 이라는 조건 만족하지 못함(즉, 비슷한 tree가 만들어질 확률이 높음)
-> Tree가 증가함에 따라 오히려 모델 전체의 분산이 증가할 수 있음
-> 각 Tree간 공분산을 줄일 수 있는 방법 필요함
2) 정의
- 데이터 뿐만 아니라, 변수도 random하게 뽑아서 다양한 모델을 만들자(base learner간의 공분산을 줄이자)
- 뽑을 변수의 수는 hyper parameter: 보통 p개인 경우, Root(p)개 선택
4. Boosting
- 오분류된 데이터에 초점을 맞추어 더 많은 가중치를 주는 방식
- 여러 모델들이 sequential하게 이뤄져 있음
- 초기에는 모든 데이터가 동일한 가중치를 갖지만, 각 round가 종료된 후 가중치와 중요도를 계산
- 복원추출시에 가중치 분포를 고려
- 오분류된 데이터가 가중치를 더 얻게 됨으로써, 다음 round에서 더 많이 고려됨
Boosting 기법들
- Boosting 기법들 간 차이: 오분류된 데이터를 다음 Round에서 어떻게 반영할 것인가의 차이
a) AdaBoost: 오분류된 데이터들에 더 큰 가중치를 주어 다음 Round샘플링에 반영
b) Gradient Boosting: 이전 Round의 합성 분류기의 데이터별 오류를 예측하는 새로운 약한 분류기를 학습
Gradient Boosting 종류
a) XGBoost
- Kaggle, KDD 등에서 우수한 성적을 내며 주목 받음
- Regularization term추가-> 복잡한 모델에 패널티 부여
- 과적합 방지
b) LightGBM - Leaf-wise loss 사용
- Overfitting에 민감하여, 대량 학습데이터를 필요로 함
c) Catboost(unbiased boosting with categorical features)
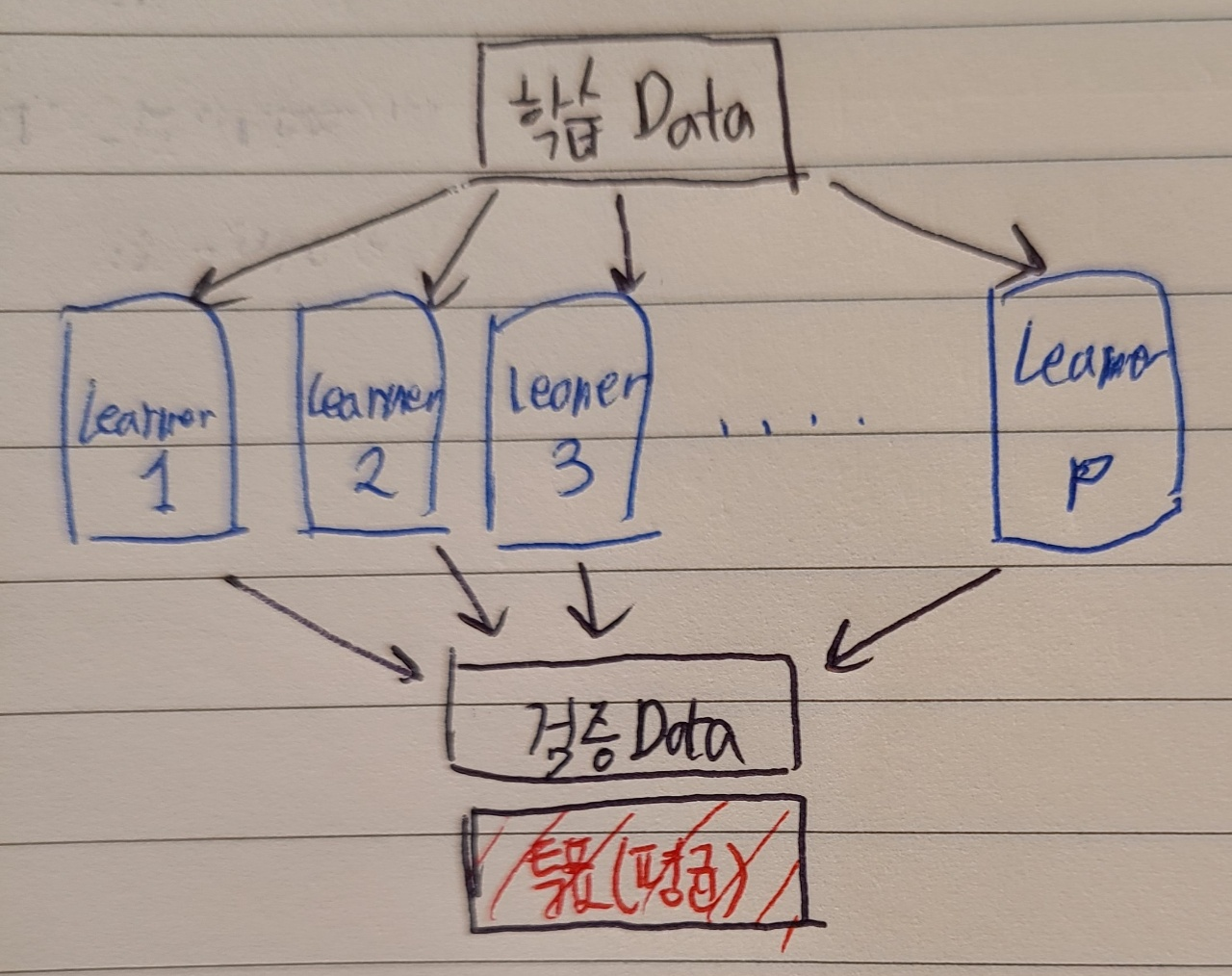
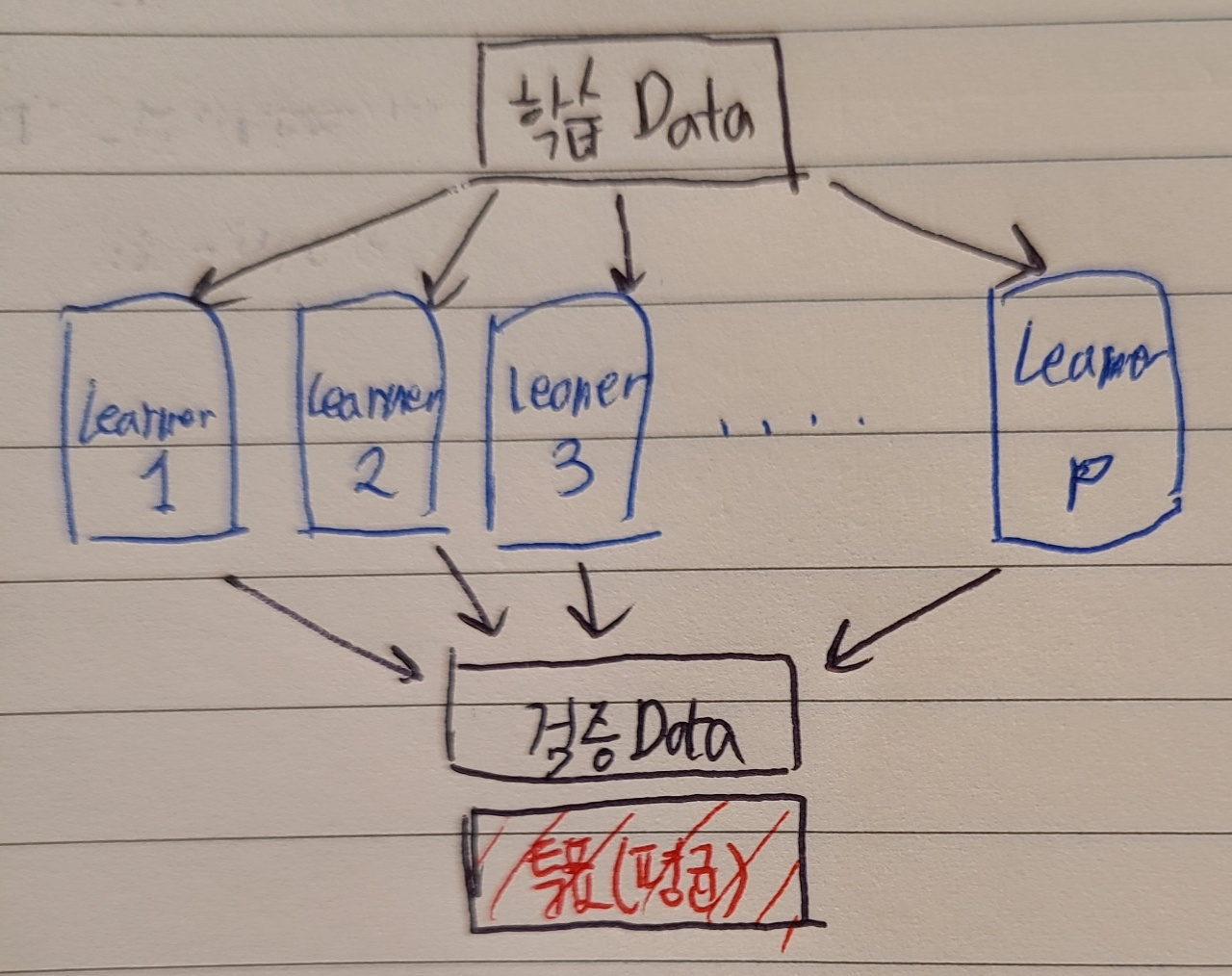
5. Stacking
- Meta Learner라고 불리며, 다양한 모델을 결합하여 사용하는 기법
- Learner: SVM, KNN, RF, GBM 등등으로
1) 동일
2) 학습데이터에 대해 다시 예측을 하고
3) 이를 통해 나온 prediction값을 변수로 사용해서 다시 학습을 시킴 -> 최종모델
<현업에서>
- 학습에 시간이 오래걸려서 비효율적임
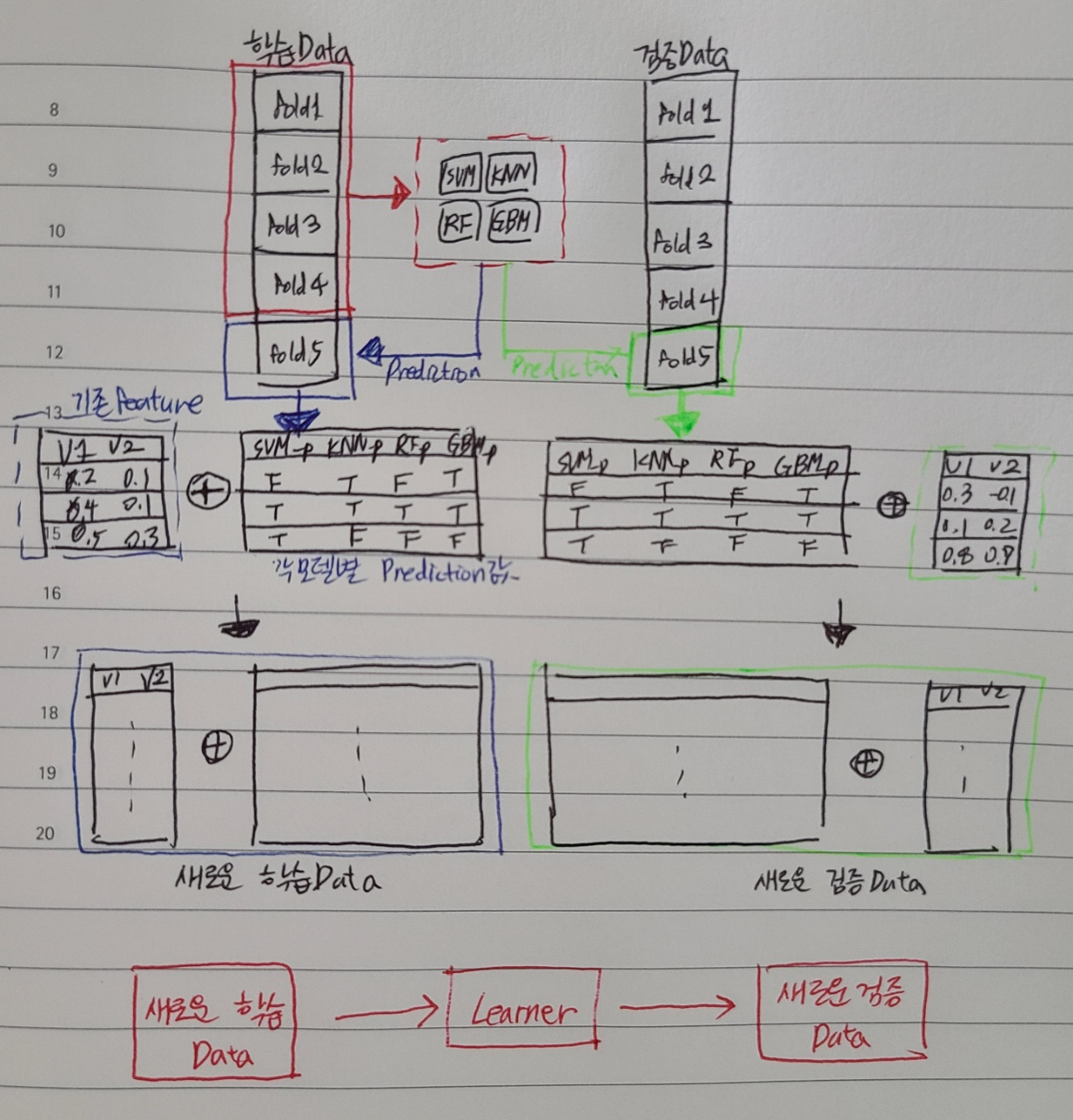
- 기존 feature를 사용하지 않고, 각 모델별 rpediction만을 사용하기도 함 -> 이 경우, 일반적으로, regression 모델 사용

SV Creator