※ 수업 과제로 진행한 2인1조 텀프로젝트의 결과이며, "3. 모델 구성 (방법론)" 이후의 설명 텍스트를 제외한 모델 및 코드, 기타 설명은 모두 직접 제작했습니다.
1. 문제 정의 (분류/예측)
가위, 바위, 보의 세 가지 손동작 이미지를 분류할 수 있도록 CNN 모델을 만드는 것을 목표로 한다. 즉, 모델이 손동작 이미지를 입력으로 받아 세 집단(가위,바위,보) 중 어디에 해당하는지 분류할 수 있도록 한다.
데이터셋은 tensorFlow_datasets에서 가져온 rock_paper_scissors 데이터셋을 사용하였다. rock_paper_scissors 데이터셋은 손동작(가위/바위/보) 이미지정보와 각 이미지에 해당하는 ClassLabel정보를 제공하는 데이터셋으로 총 2892개의 instance를 포함한다.
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow.keras as keras
import numpy as np
import matplotlib.pyplot as plt아래 변수를 통해 모델에 사용되는 hyper parameter를 설정한다.
# Hyper Parameter Configuration
EPOCHS = 30
BATCH_SIZE = 322. 데이터 (Dataset 설명)
rock-paper-scissors 데이터셋의 이미지 정보를 독립변수, ClassLabel정보를 종속변수로 한다.
이미지 정보는 RGB 방식의 300x300 컬러 이미지이며, 한 픽셀을 표현하기 위에 3개의 채널이 부여되어 있다.
ClassLabel정보는 클래스 0,1,2 중 하나를 나타내고, 각각은 rock, paper, scissor에 대응한다.
데이터셋 불러오기
tensorflow_dataset으로부터 rock_paper_sicissors 데이터셋을 불러온다.
as_supervised=True를 설정하여 (image, label)의 튜플 형태를 반환한다.
split=['train', 'test']를 통해 rock-paper-scissors의 test set과 train set을 각각 ds_train, ds_test에 할당한다.
(ds_train, ds_test), ds_info = tfds.load(
'rock_paper_scissors',
split=['train', 'test'],
# shuffle_files=True,
as_supervised=True,
with_info=True,
)데이터셋 image의 shape와 dtype을 확인한다.
사진 한 장의 크기는 300x300이며, 채널 수는 3(RGB)이다.
# print(ds_info)
image_shape = ds_info.features['image'].shape
image_dtype = ds_info.features['image'].dtype
print(f'image shape: {image_shape}')
print(f'image dtype: {image_dtype}')image shape: (300, 300, 3)
image dtype: <dtype: 'uint8'>train set과 test set의 데이터 개수를 확인한다.
# print(ds_train)
num_train = ds_info.splits['train'].num_examples
print(f'num of train: {num_train}')
# print(ds_test)
num_test = ds_info.splits['test'].num_examples
print(f'num of test : {num_test}')num of train: 2520
num of test : 372label의 정보를 확인한다.
모델의 목표는 사진을 가위, 바위, 보 중 하나로 분류하는 것이므로 class는 0, 1, 2이고 수는 3개이며 각각은 rock, paper, scissor와 대응한다.
CLASS_NUM = ds_info.features['label'].num_classes # = 3
CLASS_NAMES = ['rock', 'paper', 'scissors']
print(f'num of class: {CLASS_NUM}\n')
for i in range(CLASS_NUM):
print(i, CLASS_NAMES[i])num of class: 3
0 rock
1 paper
2 scissorstrain set 첫 번째 데이터의 image와 label을 직접 확인해본다.
plt.figure(figsize=(3, 3))
for image, label in ds_train.take(1):
plt.imshow(image)
print(CLASS_NAMES[label.numpy()])scissors
train set의 맨 앞 8개 데이터의 image와 label을 직접 확인해본다.
plt.figure(figsize=(12, 7))
i = 1
for image, label in ds_train.take(8):
plt.subplot(2, 4, i)
i += 1
# plt.axis('Off')
label = CLASS_NAMES[label.numpy()]
plt.title(f'{label}')
plt.imshow(image)
# 이후에 batch size 설정 이후 데이터를 하나씩 꺼낼 수 없기 때문에,
# 미리 test set의 첫 번째 데이터를 꺼내어 변수에 저장했다.
for image, label in ds_test.take(1):
test_image0 = image.numpy()
test_label0 = label.numpy()데이터 전처리
형변환: 기존 image는 정수(tf.uint8) 자료형으로 표현되는데, 이후의 정규화를 위해 실수(tf.float32)로 바꾼다.
정규화: [0, 255] 사이의 수로 나타낸 색을 [0, 1] 범위의 실수로 변환한다.
크기조절: 모델 학습시간을 줄이기 위해 300x300 크기의 사진을 100x100 크기로 줄인다.
(참고로, 사진의 크기가 일정하지 않은 경우에 tf.image.resize 함수를 활용하여 이를 통일할 수 있다.)
INPUT_IMG_SIZE = 100
def normalize_img(image, label):
# Make image color values to be float.
image = tf.cast(image, tf.float32)
# Make image color values to be in [0..1] range.
image = image / 255.
# Make sure that image has a right size
image = tf.image.resize(image, [INPUT_IMG_SIZE, INPUT_IMG_SIZE])
return image, labeltrain set과 test set을 각각 정규화하고, batch size를 적용한다.
이외 전처리 코드는 Keras로 MNIST에서 신경망 훈련을 참고했다.
ds_train = ds_train.map(normalize_img,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(num_train)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)3. 모델 구성 (방법론)
CNN이 MLP와 다르게 이미지의 공간정보를 유지한 채 학습을 진행하게 할 수 있도록 한다. 따라서 손동작(가위,바위,보)이미지 분류 문제를 다루기 위해 CNN이 더 적합하고 판단하여 CNN을 사용하였다.
CNN의 층은 열다섯개로 이루어져있으며 층의 종류는 keras.layers.Conv2D, keras.layers.MaxPooling2D, keras.layers.Flatten, keras.layers.Dropout, keras.layers.Dense가 있다.
이 네트워크의 첫번째 층인 keras.layers.Conv2D는 (이미지높이, 이미지너비,컬러채널)크기의 텐서(tensor)를 입력으로 받아 이 값을 input_shape매개변수에 저장한다. 3x3크기의 필터 32개를 활용하여 특징을 추출하고, padding='same'을 설정하여 출력의 크기가 입력과 같게 만든다.
두번째 층인 keras.layers.MaxPooling2D는 2x2크기의 필터를 이용하여 maxpooling를 실시한다. 출력의 크기를 줄임으로써
학습의 속도를 높이고, 사소한 변화가 영향을 미치지 않도록 하여 과적합을 방지하도록 한다.
세번째 층은 keras.layers.Conv2D로 첫번째 층에서 input_shape=(INPUT_IMG_SIZE, INPUT_IMG_SIZE,3)을 없애준 것과 동일하다.
네번째 층인 keras.layers.MaxPooling2D은 두번째 층과 동일하다.
다섯번째 층인 keras.layers.Conv2D는 세번째 층과 동일하다.
여섯번째 층인 keras.layers.MaxPooling2D은 두번째 층과 동일하다.
일곱번째 층인 keras.layers.Conv2D은 필터 64개를 이용하는 점만 제외하면 세번째 층과 동일하다.
여덟번째 층인 keras.layers.MaxPooling2D은 두번째 층과 동일하다.
아홉번째 층인 keras.layers.Conv2D은 일곱번째 층과 동일하다.
열번째 층인 keras.layers.MaxPooling2D은 두번째 층과 동일하다.
열한번째 층인 keras.layers.Flatten은 (3, 3, 64)의 shape을 가진 이미지 포맷을 3x3x64의 픽셀의 1차원 배열로 변환한다. 이 층은 이미지에 있는 픽셀의 행을 펼쳐서 일렬로 늘린다고 볼 수 있다.
열두번째 층인 keras.layers.Dropout은 신경망에 있는 input layer나 hidden layer의 일부뉴런을 생략하고 줄어든 신경망을 통해 학습하게 하며, rate로 0.5를 설정하여 50%의 노드들을 생략하여 드롭아웃을 적용한다. 드롭아웃을 통해 과적합을 방지하는 효과도 기대할 수 있다.
열세번째 층인 keras.layers.Dense는 512개의 노드를 가지고, 입력과 출력을 연결하는 역할을 한다. 따라서 이 층을 fully-connected layer라고 부른다.
열네번째 층인 keras.layers.Dropout은 열두번째 층과 동일하다.
열다섯번째 층인 keras.layers.Dense는 CLASS_NUM개(3개)의 노드를 가지는 소프트맥스(softmax)층이다. 이 층은 3개의 확률을 반환하고 반환된 값의 전체 합은 1이다. 각 노드는 현재 이미지가 3개 클래스 중 하나에 속할 확률을 출력한다.
모델
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(32, 3, padding='same', activation='relu',
input_shape=(INPUT_IMG_SIZE, INPUT_IMG_SIZE, 3)))
model.add(keras.layers.MaxPooling2D((2, 2)))
model.add(keras.layers.Conv2D(32, 3, padding='same', activation='relu'))
model.add(keras.layers.MaxPooling2D((2, 2)))
model.add(keras.layers.Conv2D(32, 3, padding='same', activation='relu'))
model.add(keras.layers.MaxPooling2D((2, 2)))
model.add(keras.layers.Conv2D(64, 3, padding='same', activation='relu'))
model.add(keras.layers.MaxPooling2D((2, 2)))
model.add(keras.layers.Conv2D(64, 3, padding='same', activation='relu'))
model.add(keras.layers.MaxPooling2D((2, 2)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dropout(0.5))
model.add(keras.layers.Dense(512, activation='relu'))
model.add(keras.layers.Dropout(0.5))
model.add(keras.layers.Dense(CLASS_NUM, activation='softmax'))
model.summary()
## 신기하게도 64->32처럼 노드 수를 줄이면 성능이 안좋고 overfitting이 발생하지만,
## 64->128처럼 늘리면 성능도 좋고 training accuracy가 1.00이 나오지 않았다.Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 100, 100, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 50, 50, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 50, 50, 32) 9248
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 25, 25, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 25, 25, 32) 9248
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 12, 12, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 12, 12, 64) 18496
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 6, 6, 64) 36928
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 3, 3, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 576) 0
_________________________________________________________________
dropout (Dropout) (None, 576) 0
_________________________________________________________________
dense (Dense) (None, 512) 295424
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_1 (Dense) (None, 3) 1539
=================================================================
Total params: 371,779
Trainable params: 371,779
Non-trainable params: 0
_________________________________________________________________모델의 layer배열을 살펴보고, 각 layer에 대한 입력과 출력의 shape을 시각화한다.
keras.utils.plot_model(model, show_shapes=True, dpi = 70)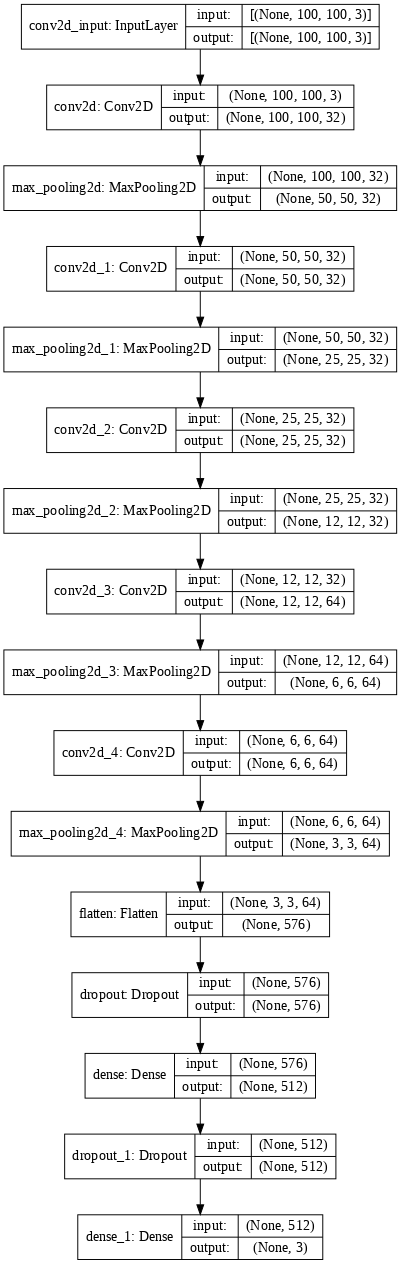
모델을 훈련하기 전에 필요한 몇가지 설정이 컴파일 단계에서 추가된다.
손실 함수(Loss function), 옵티마이저(Optimizer),지표(Metrics)를 추가한다. 손실함수는 sparse_categorical_crossentropy, 가중치 갱신 방식은 Stochastic Gradient Descent를 적용했다.
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy',
metrics=['accuracy'])학습
eopchs=EPOCHS을 설정하여 총 훈련횟수를 설정한다.
validation_dat=ds_test을 설정하여 각 epoch마다 검증데이터의 정확도가 함께 출력되게 한다.
history = model.fit(ds_train, epochs=EPOCHS, validation_data = ds_test)Epoch 1/30
79/79 [==============================] - 7s 22ms/step - loss: 1.1030 - accuracy: 0.3274 - val_loss: 1.0983 - val_accuracy: 0.3333
Epoch 2/30
79/79 [==============================] - 1s 11ms/step - loss: 1.0955 - accuracy: 0.3591 - val_loss: 1.0945 - val_accuracy: 0.4355
Epoch 3/30
79/79 [==============================] - 1s 10ms/step - loss: 1.0884 - accuracy: 0.3948 - val_loss: 1.0922 - val_accuracy: 0.3629
Epoch 4/30
79/79 [==============================] - 1s 11ms/step - loss: 1.0840 - accuracy: 0.4107 - val_loss: 1.0883 - val_accuracy: 0.3790
Epoch 5/30
79/79 [==============================] - 1s 11ms/step - loss: 1.0727 - accuracy: 0.4349 - val_loss: 1.0807 - val_accuracy: 0.5323
Epoch 6/30
79/79 [==============================] - 1s 11ms/step - loss: 1.0516 - accuracy: 0.4766 - val_loss: 1.0622 - val_accuracy: 0.6801
Epoch 7/30
79/79 [==============================] - 1s 11ms/step - loss: 0.9972 - accuracy: 0.5437 - val_loss: 1.0112 - val_accuracy: 0.5484
Epoch 8/30
79/79 [==============================] - 1s 11ms/step - loss: 0.8774 - accuracy: 0.6079 - val_loss: 0.8455 - val_accuracy: 0.7097
Epoch 9/30
79/79 [==============================] - 1s 11ms/step - loss: 0.6912 - accuracy: 0.7032 - val_loss: 0.6326 - val_accuracy: 0.7796
Epoch 10/30
79/79 [==============================] - 1s 11ms/step - loss: 0.5102 - accuracy: 0.7929 - val_loss: 0.4450 - val_accuracy: 0.8817
Epoch 11/30
79/79 [==============================] - 1s 11ms/step - loss: 0.3262 - accuracy: 0.8790 - val_loss: 0.3685 - val_accuracy: 0.8441
Epoch 12/30
79/79 [==============================] - 1s 11ms/step - loss: 0.2138 - accuracy: 0.9222 - val_loss: 0.4139 - val_accuracy: 0.7930
Epoch 13/30
79/79 [==============================] - 1s 10ms/step - loss: 0.1241 - accuracy: 0.9587 - val_loss: 0.1737 - val_accuracy: 0.9570
Epoch 14/30
79/79 [==============================] - 1s 11ms/step - loss: 0.1040 - accuracy: 0.9675 - val_loss: 0.2060 - val_accuracy: 0.9382
Epoch 15/30
79/79 [==============================] - 1s 10ms/step - loss: 0.0864 - accuracy: 0.9726 - val_loss: 0.2202 - val_accuracy: 0.9220
Epoch 16/30
79/79 [==============================] - 1s 11ms/step - loss: 0.0708 - accuracy: 0.9810 - val_loss: 0.1672 - val_accuracy: 0.9462
Epoch 17/30
79/79 [==============================] - 1s 10ms/step - loss: 0.0454 - accuracy: 0.9889 - val_loss: 0.1621 - val_accuracy: 0.9462
Epoch 18/30
79/79 [==============================] - 1s 11ms/step - loss: 0.0439 - accuracy: 0.9877 - val_loss: 0.2720 - val_accuracy: 0.9140
Epoch 19/30
79/79 [==============================] - 1s 11ms/step - loss: 0.0272 - accuracy: 0.9937 - val_loss: 0.1439 - val_accuracy: 0.9409
Epoch 20/30
79/79 [==============================] - 1s 11ms/step - loss: 0.0256 - accuracy: 0.9944 - val_loss: 0.1282 - val_accuracy: 0.9597
Epoch 21/30
79/79 [==============================] - 1s 11ms/step - loss: 0.0272 - accuracy: 0.9925 - val_loss: 0.1774 - val_accuracy: 0.9247
Epoch 22/30
79/79 [==============================] - 1s 11ms/step - loss: 0.0322 - accuracy: 0.9905 - val_loss: 0.1929 - val_accuracy: 0.9328
Epoch 23/30
79/79 [==============================] - 1s 11ms/step - loss: 0.0164 - accuracy: 0.9964 - val_loss: 0.1953 - val_accuracy: 0.9355
Epoch 24/30
79/79 [==============================] - 1s 11ms/step - loss: 0.0118 - accuracy: 0.9984 - val_loss: 0.2318 - val_accuracy: 0.9274
Epoch 25/30
79/79 [==============================] - 1s 11ms/step - loss: 0.0106 - accuracy: 0.9976 - val_loss: 0.1665 - val_accuracy: 0.9355
Epoch 26/30
79/79 [==============================] - 1s 11ms/step - loss: 0.0175 - accuracy: 0.9964 - val_loss: 0.1795 - val_accuracy: 0.9274
Epoch 27/30
79/79 [==============================] - 1s 11ms/step - loss: 0.0111 - accuracy: 0.9976 - val_loss: 0.1446 - val_accuracy: 0.9570
Epoch 28/30
79/79 [==============================] - 1s 11ms/step - loss: 0.0154 - accuracy: 0.9960 - val_loss: 0.1989 - val_accuracy: 0.9274
Epoch 29/30
79/79 [==============================] - 1s 10ms/step - loss: 0.0089 - accuracy: 0.9988 - val_loss: 0.1587 - val_accuracy: 0.9382
Epoch 30/30
79/79 [==============================] - 1s 11ms/step - loss: 0.0064 - accuracy: 0.9984 - val_loss: 0.1426 - val_accuracy: 0.94354. 분석 결과
처음에 만들었던 모델은 LeNet-5처럼 64개에서 시작하여 필터 개수를 점점 줄이는 방식으로 제작했다. 하지만 약 5번의 epoch 이후부터 train set의 accuracy가 지속적으로 1.00이 나오는 한편 val_accuracy는 그에 못미치는 overfitting이 발생했다. 따라서 rock_paper_scissors_cnn.ipynb의 layer 구성을 참고하여 이미지 크기를 줄이고(150x150), layer가 깊어질수록 필터개수를 늘리는 방식으로 학습하여 개선된 성능을 얻게 되었다.
하지만 위와 같은 방식 적용 이후에도 validation set의 loss나 accuracy가 train set에 비해 낮은 것을 통해 overfitting 문제가 완전히 해결되지 않았음을 확인했다. 따라서 dropout을 더 많은 layer 사이에 적용하고, 이미지 크기(100x100)와 필터개수를 더욱 줄여 현재 모델을 얻게 되었다.
평가
test set을 입력하여 모델의 성능을 확인해본다.
test_loss, test_acc = model.evaluate(ds_test, verbose=2)
print(f'\n테스트 정확도: {test_acc*100:.2f}%')12/12 - 0s - loss: 0.1426 - accuracy: 0.9435
테스트 정확도: 94.35%예측
훈련된 모델을 사용하여 test set에 대한 예측을 만든다.
predictions = model.predict(ds_test)
print(predictions)
print(len(predictions))[[3.5252521e-04 5.1728729e-04 9.9913019e-01]
[1.6796719e-12 9.9998891e-01 1.1073517e-05]
[2.9048510e-02 1.0746688e-02 9.6020478e-01]
...
[9.9998295e-01 1.7060782e-05 9.7506279e-09]
[2.2594936e-07 7.5626618e-01 2.4373356e-01]
[1.4398720e-06 3.5005957e-01 6.4993900e-01]]
372test set의 첫번째 image에 대한 예측을 확인한다. 예측은 3개의 숫자배열로 이고, 이 값은 'rock', 'paper', 'scissor'에 해당하는 모델의 신뢰도를 나타낸다.
print(predictions[0])[3.525252e-04 5.172873e-04 9.991302e-01]가장 높은 신뢰도를 가진 레이블을 불러온다.
CLASS_NAMES[np.argmax(predictions[0])]'scissors'test set의 첫번째 image와 label를 확인해보고, 앞의 코드에서 예측한 label과 실제 label이 일치하는지 확인한다.
plt.figure(figsize=(3, 3))
plt.imshow(test_image0)
print(CLASS_NAMES[test_label0])scissors
시각화
train set과 validatino set(test set)의 Epoch에 대한 Loss와 Accuracy를 시각화한다.
import pandas as pd
df_hist = pd.DataFrame(history.history)
df_hist['epoch'] = range(1, EPOCHS+1)
plt.figure(figsize=(15, 5))
plt.subplot(1,2,1)
plt.title('Loss according to Epoch')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.plot(df_hist['epoch'], df_hist['loss'], label='train')
plt.plot(df_hist['epoch'], df_hist['val_loss'], label = 'validation')
# plt.ylim([0, 1.5])
plt.grid(True)
plt.legend()
plt.subplot(1,2,2)
plt.title('Accuracy according to Epoch')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.plot(df_hist['epoch'], df_hist['accuracy'], label='train')
plt.plot(df_hist['epoch'], df_hist['val_accuracy'], label='validation')
plt.ylim(0, 1.05)
plt.grid(True)
plt.legend()
plt.show()
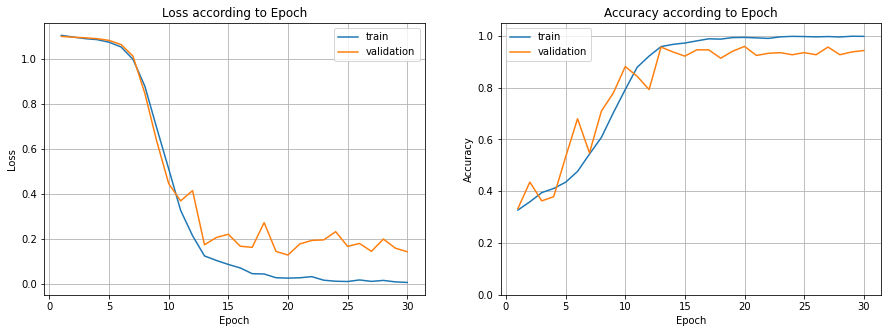
Loss 분석
epoch이 증가함에 따라 train set과 validation set의 loss는 감소하는 추세를 보인다. 즉, 학습을 진행함에 따라 모델의 오차가 점점 줄어든다는 것을 확인할 수 있다. 뿐만 아니라 11epoch부터는 train set의 loss가 validation set보다 항상 낮다는 것을 확인할 수 있다. 이는 학습이 진행될수록 상대적으로 train set에 더 적합한 모델이 만들어진다는 것을 의미한다.
Accuracy 분석
epoch이 증가함에 따라 train set과 validation set의 accuarcy는 증가하는 추세를 보인다. 즉, 학습을 진행함에 따라 모델의 성능이 점점 더 좋아진다고 볼 수 있다.
그리고 15epoch부터는 train set의 accuarcy가 validation set보다 항상 높다는 것을 확인할 수 있는데, 이는 학습이 진행됨에 따라 상대적으로 train set에 좀 더 적합한 모델이 만들어졌기 때문이라고 해석할 수 있다.
5. 참고자료
코드 출처
Keras로 MNIST에서 신경망 훈련 (tensorflow_datasets 가져오기)
항목 TensorFlow Datasets API 활용법
rock_paper_scissors_cnn.ipynb (모델구성 참고)
첫 번째 신경망 훈련하기: 기초적인 분류 문제 (목차 및 전체 구성 참고)
딥러닝 문서
