각 프로그래밍 언어에는 라이브러리 함수 형태로 정렬 알고리즘을 제공한다
실무에서는 정렬 알고리즘 개념과 고나련 라이브러리가 내부적으로 어떻게 동작하는지를 어느 정도 아는 데 집중하기 바란다.
버블 정렬(bubble sort)
- 버블 정렬은 시간 복잡도가 O(n²)으로 비효율적 알고리즘. 단순하지만 느리기 때문에 실제 응용프로그램에 적용하지 않음.

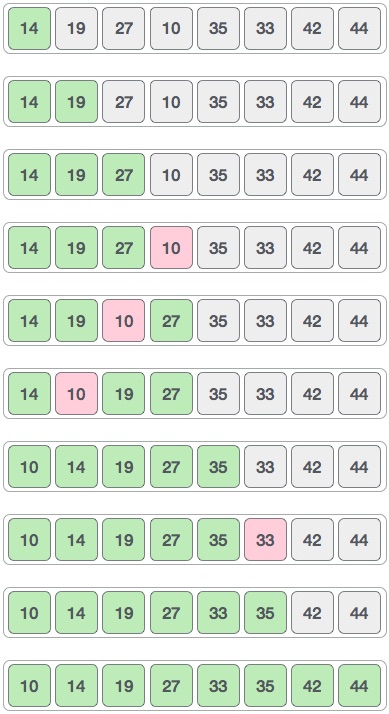
선택 정렬(selection sort)
-
선형 탐색을 응용한 알고리즘
-
이해하기 쉽지만 반복문 2개를 중첩하여 사용하므로 시간 복잡도가O(n²)이다.
-
또한 처음에 가장 작은 요소를 찾기위해 선형탐색을 이용하므로 알고리즘 실행속도가 느려진다.

삽입 정렬(insertion sort)
- 삽입 정렬에서는 가장 작은 숫자를 찾기 위해 배열의 모든 숫자를 확인할 필요가 없다. 시간 복잡도는 O(n²)이며 선택 정렬보다 더 효율적인 정렬 알고리즘.

셀 정렬(shell sort)
- 삽입 정렬을 더 효율적으로 실행하는 알고리즘
- 요소를 몇개의 단위로 묶은 후 단위마다 삽입 정렬을 실행함
- 이후 단위 요소 수를 줄여 묶은 후 삽입 정렬을 실행
- 단위 요소 수가 1이 될 때까지 실행하면 정렬이 완료됨
| 최선 | 평균 | 최악 | |
|---|---|---|---|
| 삽입 정렬 | O(n) | O(n²) | O(n²) |
| 셀 정렬 | O(n) | O(n^1.5) | O(n²) |


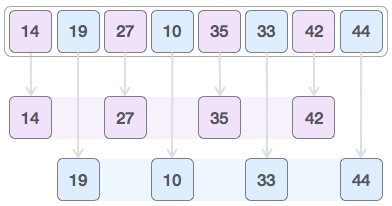

병합 정렬(merge sort)
-
데이터를 반으로 나누어 정렬을 수행하는 알고리즘
-
분할 정복(divide and conquer)방식을 사용한다.
-
모든 배열에 하나의 숫자만 남을 때까지 반복해서 반으로 나눈다.
-
그 후 다시 결합하며 정렬해 나감.
-
재귀 함수를 사용하여 입력 데이터를 계속 나누므로 알고리즘의 시간 복잡도가 재기 횟수에 따라 달라지며, 일반적인 시간 복잡도는 O(nlogn)이다.


퀵 정렬(quick sort)
-
분할 정복 방식을 사용하는 또 다른 정렬 알고리즘
-
퀵 정렬 알고리즘의 시간 복잡도는 O(nlogn)이다.
퀵 정렬의 방식
-
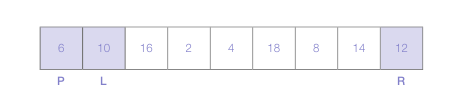
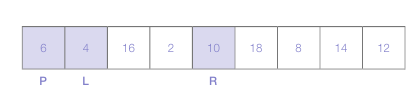
배열의 맨 왼쪽(오른쪽)을 선택하여 피벗(pivot)으로 정한다.
-
피벗을 정하고 나면 피벗 바로 오른쪽에 위치한 요소와 배열 맨 오른쪽에 위치한 요소를 선택해 left marker와 right marker로 정함.
-
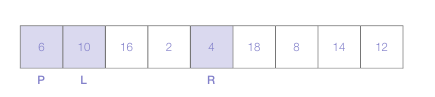
L 마커는 오른쪽으로 이동하며 피벗보다 크거나 같은 첫번째 숫자를 택함
-
R 마커는 왼쪽으로 이동하며 피벗보다 작은 숫자를 선택
-
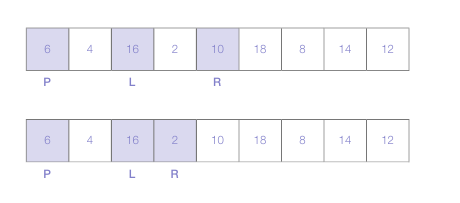
각 마커가 숫자를 선택하고 나면 L 마커의 숫자와 R 마커의 숫자 위치를 바꿈
-
이후 그 과정을 L,R 마커가 서로 교차하는 상태가 될 때까지 해 주면 된다.
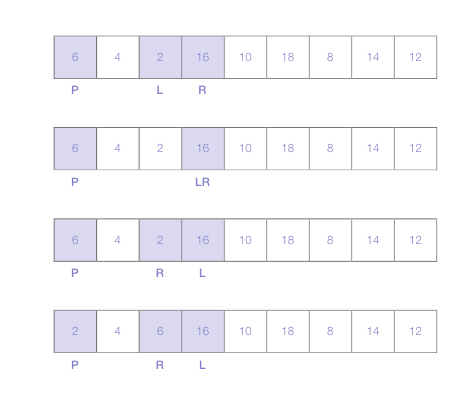
- 이렇게 되면 피벗이었던 6의 정렬은 끝난 것이다.
- 이렇게 마커를 사용하여 숫자를 선택하고 위치를 바꾸는 동작을 반복하면 피벗보다 작은 숫자는 배열의 왼쪽에, 피벗보다 큰 숫자는 배열의 오른쪽에 모이게 된다.
- 이제 6을 기준으로 왼쪽, 오른쪽 블록으로 나누어 배열의 맨 왼쪽 요소를 새로운 피벗을 삼아 같은 과정을 반복하면 된다.
힙 정렬(heap sort)
-
힙 데이터 구조의 각 노드를 최대 힙 혹은 최소 힙 상태로 정렬하는 방법을 뜻한다.
-
힙 정렬은 시간복잡도가 항상 O(nlogn)을 유지한다
-
전체 값을 대상으로 비교해 정렬하는 것이 아니라 가장 크거나 작은 값 기준으로 바로 옆에 있는 부모 및 자식 노드를 상대 비교하기 때문이다.
최대 힙 정렬 방식이다
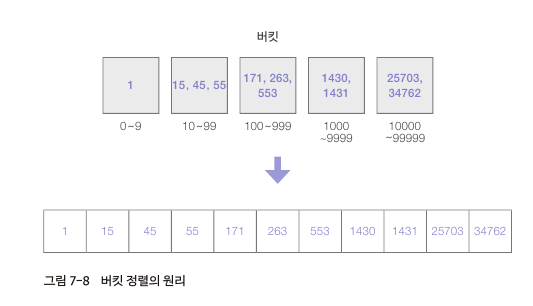
버킷 정렬(bucket sort)
- 요소들을 어떤 기준이 있는 버킷(여러 데이터를 저장하는 장소)에 나눠 넣은 후 다음 과정으로 정렬을 수행한다.
- 어떤 순서가 있는 버킷으로 사용할 기억 공간(배열이나 리스트 등...)을 준비함
- 버킷을 만들 때의 기준에 따라 요소를 분류해 넣음
- 버킷별로 요소를 정렬함
- 버킷 안에서 정렬한 요소를 버킷의 순서에 따라 나열해서 정렬을 완료함
- 보통 버킷 별로 나눈뒤, 다른 정렬 알고리즘을 사용하거나 다시 버킷 정렬을 재귀적으로 사용해 정렬한다.

이 버킷은 자릿수를 기준으로 버킷을 만들어 그에 해당하는 요소를 나눠 넣은 후 버킷 안에서 정렬해 정렬 처리 속도를 높이는 원리다.
기수 정렬(radix sort)
-
버킷 정렬과 기본 원리는 같다
-
특정 기준이 정해져 있는 버킷 정렬이라는 점에서 차이
-
요소값의 특정 자리수끼리(1의자리, 10의자리, 100의자리...) 비교해서 정렬한다.
-
요소값이 1의 자리인 숫자라면 그 앞에 0이 있다고 간주해 요소를 나눈다.
-
이렇게 계속 요소를 나누다 보면 순서대로 정렬하게 된다.

