연관관계 매핑
연관관계 매핑시 고려사항 3가지
• 다중성
• 단방향, 양방향
• 연관관계의 주인
연관관계의 종류
• 다대일: @ManyToOne
• 일대다: @OneToMany
• 일대일: @OneToOne
• 다대다: @ManyToMany (실무에서는 사용x)
다대일
- 가장 많이 사용하는 연관관계
- 다대일의 반대는 일대다
- 외래 키가 있는 쪽이 연관관계의 주인
- 양쪽을 서로 참조하도록 개발
@ManyToOne < ---------> @OneToMany(Mappedby)
@JoinColumn일대다
- 일대다 단방향은 일대다(1:N)에서 일(1)이 연관관계의 주인
- 테이블 일대다 관계는 항상 다(N) 쪽에 외래 키가 있음
- 객체와 테이블의 차이 때문에 반대편 테이블의 외래 키를 관리하는 특이한 구조
- @JoinColumn을 꼭 사용해야 함. 그렇지 않으면 조인 테이블 방식을 사용함(중간에 테이블을 하나 추가함)
일대다 단방향 매핑의 단점
- 엔티티가 관리하는 외래 키가 다른 테이블에 있음
- 연관관계 관리를 위해 추가로 UPDATE SQL 실행
- 일대다 단방향 매핑보다는 다대일 양방향 매핑을 사용하자
일대다 양방향 정리
- 이런 매핑은 공식적으로 존재X
- @JoinColumn(insertable=false, updatable=false)
- 읽기 전용 필드를 사용해서 양방향 처럼 사용하는 방법
- 다대일 양방향을 사용하자
일대일
-
일대일 관계는 그 반대도 일대일
-
주 테이블이나 대상 테이블 중에 외래 키 선택 가능
-
외래 키에 데이터베이스 유니크(UNI) 제약조건 추가
-
일대일: 주 테이블에 외래 키 단방향 정리
-
다대일(@ManyToOne) 단방향 매핑과 유사
-
다대일 양방향 매핑 처럼 외래 키가 있는 곳이 연관관계의 주인
-
반대편은 mappedBy 적용
주 테이블에 외래 키
- 주 객체가 대상 객체의 참조를 가지는 것 처럼 주 테이블에 외래 키를 두고 대상 테이블을 찾음
- 객체지향 개발자 선호
- JPA 매핑 편리
- 장점: 주 테이블만 조회해도 대상 테이블에 데이터가 있는지 확인 가능
- 단점: 값이 없으면 외래 키에 null 허용
대상 테이블에 외래 키
- 대상 테이블에 외래 키가 존재
- 전통적인 데이터베이스 개발자 선호
- 장점: 주 테이블과 대상 테이블을 일대일에서 일대다 관계로 변경할 때 테이블 구조 유지
- 단점: 프록시 기능의 한계로 지연 로딩으로 설정해도 항상 즉시 로딩됨(프록시는 뒤에서 설명)
다대다
- 관계형 데이터베이스는 정규화된 테이블 2개로 다대다 관계를 표현할 수 없음
- 연결 테이블을 추가해서 일대다, 다대일 관계로 풀어내야함
- 객체는 컬렉션을 사용해서 객체 2개로 다대다 관계 가능
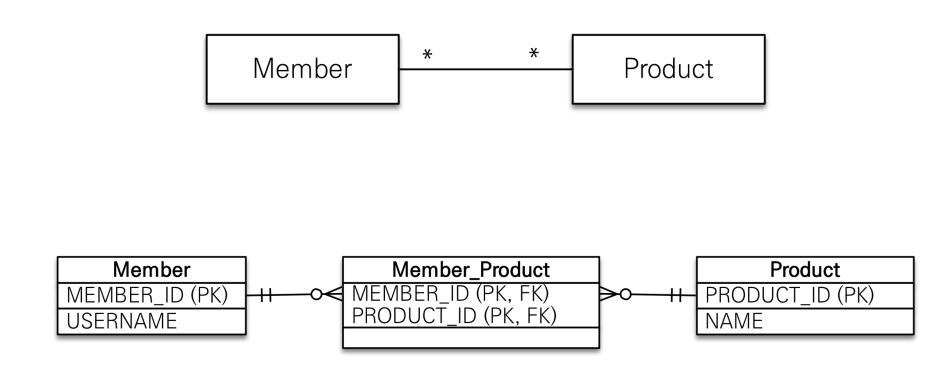
다대다 관계는 그렇게 사용하지 말고, 연결 테이블용 엔티티 추가(연결 테이블을 엔티티로 승격)
- @ManyToMany -> @OneToMany, @ManyToOne
중간의 Member_Product 엔티티를 만들어 풀어내면 된다.
상속관계 매핑
- 관계형 데이터베이스는 상속 관계 x
- 슈퍼타입 서브타입 관계라는 모델링 기법이 객체 상속과 유사
- 상속관계 매핑 : 객체의 상속과 구조를 DB의 슈퍼타입 서브타입 관계를 매핑
3가지 방법
1. 각각 테이블로 변환 -> 조인 전략
2. 통합 테이블로 변환 -> 단일 테이블 전략
3. 서브타입 테이블로 변환 -> 구현 클래스마다 테이블 전략
3가지 방법은 테이블은 다르지만, 객체는 전부 하나의 형태이다. JPA는 어떤 방법으로 구현하든 전부 지원을 한다.
JPA의 기본은 단일 테이블 전략이다.
@Entity
@Inheritance(starategy=InheritanceType.JOINED)
public class Item {
@Id @GeneratedValue
private Long id;
private Long name;
private int price
}
@Entity
public class Book extends Item {
private String ISBN;
private String author
}
@Entity
public class Movie extends Item {
private String actor;
private String direcotr;
}
@Entity
public class Album extends Item {
private String artist;
}- 상속관계 매핑은 위의 코드처럼 이루어진다.
- extends를 해서 받으면 3가지 전략 타입을 선택해서 테이블을 생성한다.
- @Inheritance의 starategy=InheritanceType.JOINED, SINGLE_TABLE, TABLE_PER_CLASS 3가지 전략이 존재
- @DiscriminatorColumn(name=“DTYPE”)
- @DiscriminatorValue(“XXX”)
- Discriminator전략 - value는 자식쪽에, column은 부모쪽에.
조인 전략
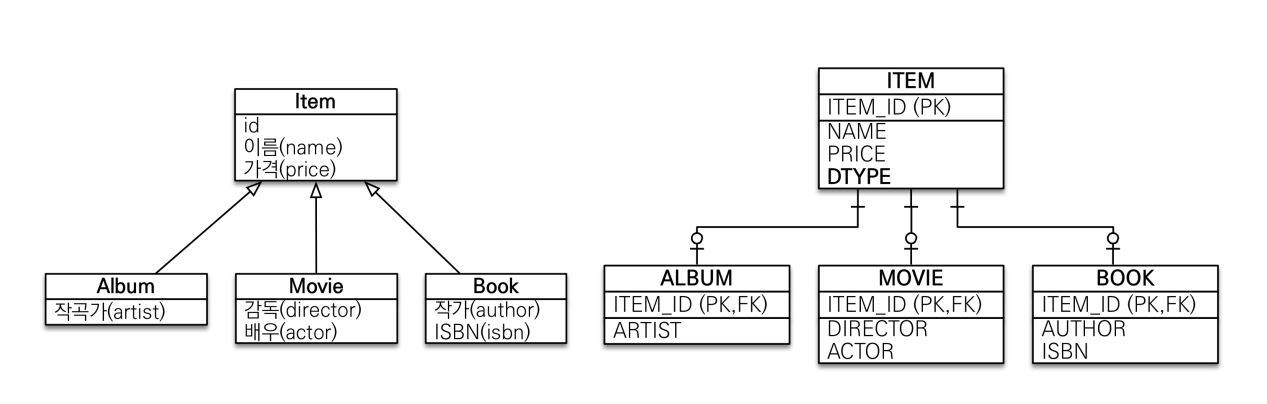
장점
- 테이블 정규화가 잘 되있다.
- 가장 JPA와 유사한 모델링
- 외래 키 참조 무결성 제약조건 활용가능
- 저장공간 효율화
단점
- 조회시 조인을 많이 사용, 성능 저하
- 조회 쿼리가 복잡함
- 데이터 저장시 INSERT SQL 2번 호출
JPA 스펙상은 DTYPE을 넣어야 된다고 되있지만, 하이버네이트가 그것이 필수적이지 않게 만들어 준다..
단일 테이블 전략
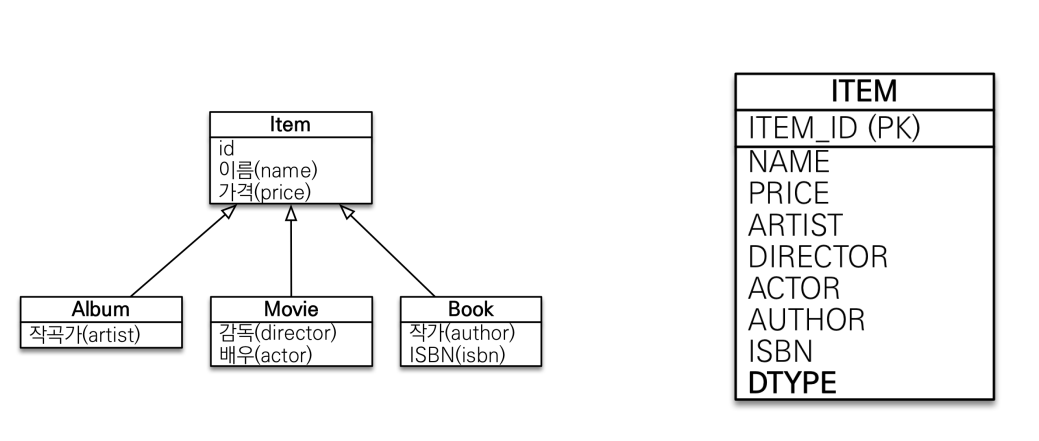
장점
- 조인이 필요 없으므로 일반적으로 조회 성능이 빠름
- 조회 쿼리가 단순함
단점
- 자식 엔티티가 매핑한 컬럼은 모두 null 허용
- 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다. 상황에 따라서 조회 성능이 오히려 느려질 수 있다.
단일 테이블 전략은 DTYPE이 필수다. 아니면 Album, movie, book을 구별을 못한다.
구현 클래스마다 테이블 전략
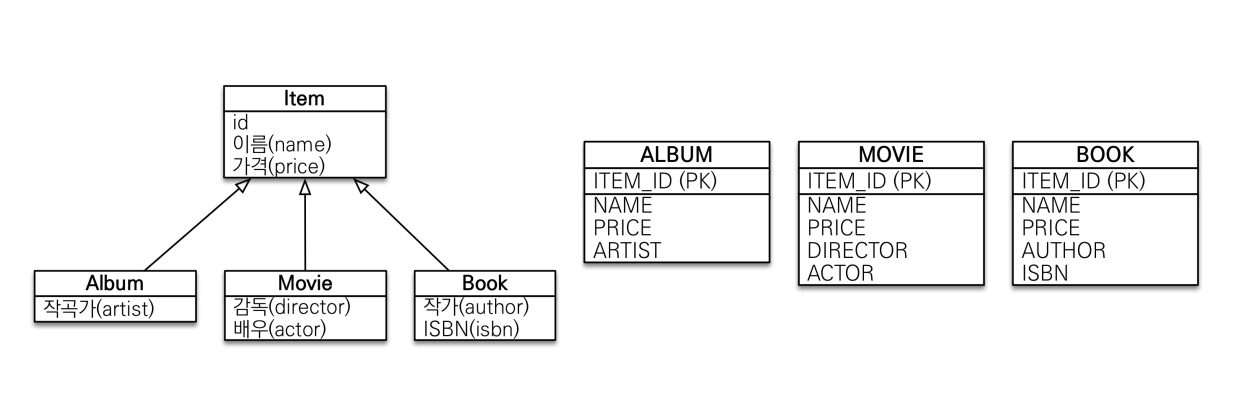
ITEM 클래스를 추상 클래스로 바꿔줘야 한다. 또한 DiscriminatorColumn이 의미가 없어 사용할 필요 없다.
장점
- 서브 타입을 명확하게 구분해서 처리할 때 효과적
- not null 제약조건 사용 가능
단점
- 여러 자식 테이블을 함께 조회할 때 성능이 느림(UNION SQL 필요)
- 자식 테이블을 통합해서 쿼리하기 어려움
이 전략은 데이터베이스 설계자와 ORM 전문가 둘 다 추천x
@MappedSuperclass
- 공통의 정보를 테이블마다 정의하면 반복작업
- 그것을 하나로 모아서 상속을 통해 재사용 가능
- 상속관계 매핑X
- 엔티티X, 테이블과 매핑X
- 부모 클래스를 상속 받는 자식 클래스에 매핑 정보만 제공
- 직접 생성해서 사용할 일이 없으므로 추상 클래스 권장
생성날짜, 수정날짜, 생성인, 수정인 등 공통적인 정보의 클래스
@MappedSuperclass
public abstract class BaseEntity {
private String createdBy;
private LocalDateTime createdDate;
private String lastModifiedBy;
private LocalDateTime lastModifiedDate;
}- 이 클래스는 상속받은 Entity에 자동으로 컬럼으로 포함된다.
- 테이블과 관계 없고, 단순히 엔티티가 공통으로 사용하는 매핑 정보를 모으는 역할
- 주로 등록일, 수정일, 등록자, 수정자 같은 전체 엔티티에서 공통으로 적용하는 정보를 모을 때 사용
- 참고: @Entity 클래스는 엔티티나 @MappedSuperclass로 지정한 클래스만 상속 가능
프록시
em.find(): 데이터베이스를 통해서 실제 엔티티 객체 조회
em.getReference(): 데이터베이스 조회를 미루는 가짜(프록시) 엔티티 객체 조회
실제 클래스를 상속 받아서 만들어짐.
실제 클래스와 겉 모양이 같다.
사용하는 입장에서는 진짜 객체인지 프록시 객체인지 구분하지 않고 사용하면 됨
프록시 특징
-
프록시 객체는 처음 사용할 때 한 번만 초기화
-
프록시 객체를 초기화 할 때, 프록시 객체가 실제 엔티티로 바뀌는 것은 아님, 초기화되면 프록시 객체를 통해서 실제 엔티티에 접근 가능
-
프록시 객체는 원본 엔티티를 상속받음, 따라서 타입 체크시 주의해야함 (== 비교 실패, 대신 instance of 사용)
-
영속성 컨텍스트에 찾는 엔티티가 이미 있으면 em.getReference()를 호출해 도 실제 엔티티 반환(한 트랜잭션 안에서 JPA는 항상 같음을 보장한다.)
-
영속성 컨텍스트의 도움을 받을 수 없는 준영속 상태일 때, 프록시를 초기화하면 문제 발생 (하이버네이트는 org.hibernate.LazyInitializationException 예외를 터트림)
clear, detach, close 등 영속성 컨텍스트를 비워버리거나 하면 예외..
-
프록시 인스턴스의 초기화 여부 확인
PersistenceUnitUtil.isLoaded(Object entity) -
프록시 클래스 확인 방법
entity.getClass().getName()출력(..javasist.. or HibernateProxy…) -
프록시 강제 초기화
org.hibernate.Hibernate.initialize(entity); -
참고: JPA 표준은 강제 초기화 없음
강제 호출: member.getName()
정리
사실 위에서 본 내용들을 거의 사용할 일은 없다. em.getReference()를 사용할까? 아니다. 그렇다면 왜 이런 것을 알아 보았는가? 바로 즉시로딩과 지연로딩 때문이다. 지금부터 알아보자.
즉시 로딩과 지연 로딩
//지연로딩 FetchType.LAZY
@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne(fetch = FetchType.LAZY) //**
@JoinColumn(name = "TEAM_ID")
private Team team;
..
}
//즉시 로딩 FetchType.EAGER
@Entity
public class Member {
@Id
@GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne(fetch = FetchType.EAGER) //**
@JoinColumn(name = "TEAM_ID")
private Team team;
..
}LAZY 로딩을 사용시
Team team = member.getTeam();
team.getName(); // 실제 team을 사용하는 시점에 초기화(DB 조회)
즉, 처음 쿼리문을 날릴때, join 쿼리를 날리지 않음.
EAGER 로딩을 사용시
Team team = member.getTeam();
team.getName(); // 별다른 DB 조회 없이 조회됨.
처음 find를 할때 join문을 함께 날려서 조회 됨.
즉시로딩의 주의점
- 가급적 지연 로딩만을 사용 하라!
- 즉시 로딩을 적용하면 예상하지 못한 SQL이 발생
- 즉시 로딩은 JPQL에서 N+1 문제를 일으킨다.
- @ManyToOne, @OneToOne은 기본이 즉시 로딩 -> LAZY로 설정
- @OneToMany, @ManyToMany는 기본이 지연 로딩
N + 1 문제란?
Member를 조회했는데 거기에 딸린 Team을 같이 조회하는 쿼리문을 날린다. 만약 다른 연관된 테이블들이 더 있다면 그 개수 만큼(N개) 쿼리가 더 나갈 것이다.
처음 쿼리 하나(1)을 날렸는데 거기에 따른 N개의 쿼리가 나간다고 N+1문제이다. (1+N이어야 되는거같긴한데..)
3가지 해결점
- JPQL fetch 조인
- 엔티티 그래프 기능
- batch size
영속성 전이 : CASCADE
특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들고 싶을 때
종류
ALL : 모두 적용
PERSIST : 영속
REMOVE : 삭제
MERGE : 병합
REFRESH : REFREHS
DETACH : DETACH
CASCADE의 경우 소유관계가 하나일때 사용해도 되지만, 그렇지 않다면 사용하지마라. (단일 엔티티에 완전히 종속적일때)
고아 객체
-
고아 객체 제거 - 부모 엔티티와 연관관계가 끊어진 자식 엔티티를 자동으로 삭제
-
orphanRemoval = true
-
참조가 제거된 엔티티는 다른 곳에서 참조하지 않는 고아 객체로 보고 삭제하는 기능
- 참조하는 곳이 하나일 때 사용해야함!
- 특정 엔티티가 개인 소유할 때 사용
- @OneToOne, @OneToMany만 가능
참고: 개념적으로 부모를 제거하면 자식은 고아가 된다. 따라서 고아 객체 제거 기능을 활성화 하면, 부모를 제거할 때 자식도 함께 제거된다. 이것은 CascadeType.REMOVE처럼 동작한다.
영속성 전이 + 고아 객체
CascadeType.ALL + orphanRemovel=true
스스로 생명주기를 관리하는 엔티티는 em.persist()로 영속화, em.remove()로 제거
두 옵션을 모두 활성화 하면 부모 엔티티를 통해서 자식의 생명 주기를 관리할 수 있음
도메인 주도 설계(DDD)의 Aggregate Root개념을 구현할 때 유용
값 타입
JPA의 데이터 타입 분류
- 엔티티 타입
- @Entity로 정의하는 객체
- 데이터가 변해도 식별자로 지속해서 추적 가능
- ex) 회원 엔티티의 키나 나이 값을 변경해도 식별자로 인식 가능
- 값 타입
- int, Integer, String처럼 단순히 값으로 사용하는 자바 기본 타입이나 객체
- 식별자가 없고 값만 있으므로 변경시 추적 불가
- ex) 숫자 100을 200으로 변경하면 완전히 다른 값으로 대체
값 타입 분류
- 기본값 타입
- 자바 기본 타입(int, double)
- 래퍼 클래스(Integer, Long)
- String
- 임베디드 타입(embedded type, 복합 값 타입)
- 컬렉션 값 타입(collection value type)
기본 값 타입
- ex) String name, int age
- 생명주기를 엔티티의 의존
- ex) 회원을 삭제하면 이름, 나이 필드도 함께 삭제
- 값 타입은 공유하면X
- ex) 회원 이름 변경시 다른 회원의 이름도 함께 변경되면 안됨
@Embeddable
- 재사용성
- 높은 응집도
- 해당 값 타입만 사용하는 의미있는 메소드를 만들 수 있음
- 임베디드 타입을 포함한 모든 값 타입은, 값 타입을 소유한 엔티티에 생명주기를 의존함.
public class Hotel {
...
private String address1;
private String address2;
private String zipCode;
}
위 3개의 필드를 묶어서 하나의 클래스로
@Embeddable
public class Address {
private String address1;
private String address2;
private String zipCode;
}
그럼 호텔은 Address만 받으면 됨.
public class Hotel {
@Embedded
private Address address;
}- 엔티티가 아닌 타입을 한 개 이상의 필드와 매핑할 때 사용.
- 엔티티의 한 속성으로 @Embeddable 적용시 필드에 @Embedded로 사용 가능
- 객체를 @Embedded로 활용하면 Address의 필드들이 컬럼으로 활용된다.
- 같은 @Embedded 타입이 두개라면? -> 오류가 난다.
- 이때,
@AttributeOverrdie로 설정 재정의를하면 사용 가능.``` @AttributeOverrides({ @AttributeOverride(name="address1", column=@Column(name="waddr1")), @AttributeOverride(name="address2", column=@Column(name="waddr2")), @AttributeOverride(name="zipcode", column=@Column(name="wzipcode")), }) ```@Embeddable은 왜 사용하는가?
@Embeddable을 사용하면 모델을 더 잘 표현할 수 있음.
개별 속성을 모아서 이해 -> 타입으로 더 쉽게 이해 가능
addr1, addr2, zipcode를 보고 주소로 이해 -> Address 타입을 보고 주소로 바로 이해
값 타입과 불변 객체
- 값 타입은 복잡한 객체 세상을 조금이라도 단순화하려고 만든 개념이다. 따라서 값 타입은 단순하고 안전하게 다룰 수 있어야 한다
- 기본 타입이나 Integer같은 wrapper class, String은 안전함.
- 임베디드 타입 같은 값 타입을 여러 엔티티에서 공유하면 위험함 (공유 참조)
- 사이드 임팩트가 발생한다.
- 항상 값을 복사해서 사용하면 공유 참조로 인해 발생하는 부작용을 피할 수 있다.
- 문제는 임베디드 타입처럼 직접 정의한 값 타입은 자바의 기본 타입이 아니라 객체 타입이다.
- 자바 기본 타입에 값을 대입하면 값을 복사한다.
- 객체 타입은 참조 값을 직접 대입하는 것을 막을 방법이 없다.
- 객체의 공유 참조는 피할 수 없다.
불변 객체
- 객체 타입을 수정할 수 없게 만들면 부작용을 원천 차단
- 값 타입은 불변 객체(immutable object)로 설계해야함
- 불변 객체: 생성 시점 이후 절대 값을 변경할 수 없는 객체
- 생성자로만 값을 설정하고 수정자(Setter)를 만들지 않으면 됨
- 참고: Integer, String은 자바가 제공하는 대표적인 불변 객체
값 타입 비교
동일성(identity) 비교: 인스턴스의 참조 값을 비교, == 사용
동등성(equivalence) 비교: 인스턴스의 값을 비교, equals()사용
값 타입은 a.equals(b)를 사용해서 동등성 비교를 해야 함
값 타입의 equals() 메소드를 적절하게 재정의(주로 모든 필드 사용)
값 타입 컬랙션
테이블은 컬랙션을 저장할 수 없다. 객체로는 하나로 표현되는 것이 테이블은 다르게 표현된다.
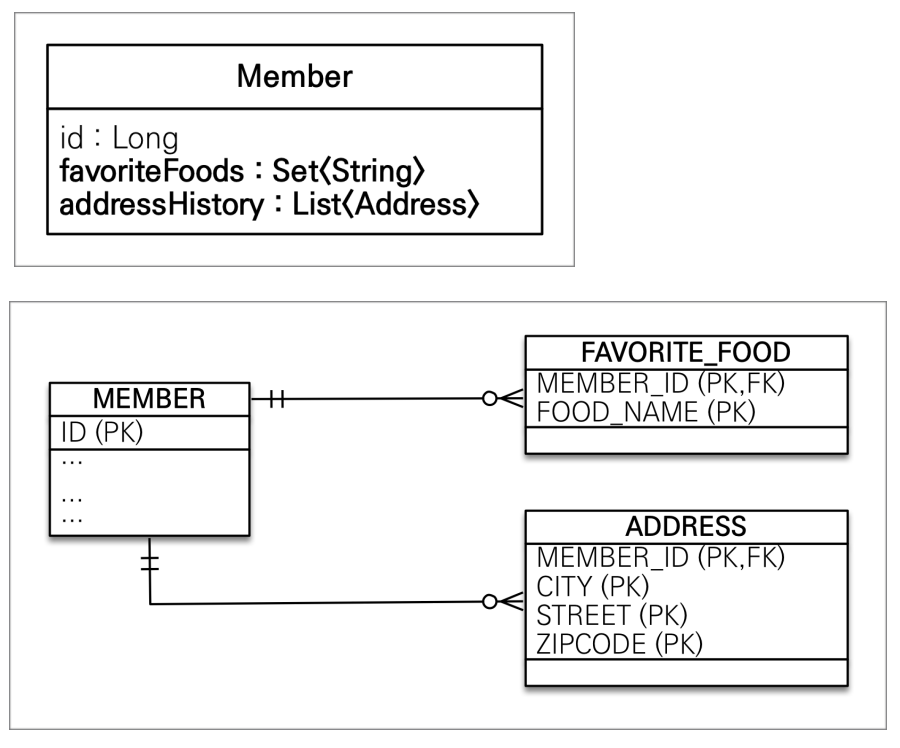
값 타입을 하나 이상 저장할 때 사용
@ElementCollection, @CollectionTable 사용
데이터베이스는 컬렉션을 같은 테이블에 저장할 수 없다.
컬렉션을 저장하기 위한 별도의 테이블이 필요함
위 그림을 나타낸 코드
@ElementCollection
@CollectionTable(name ="FAVORITE_FOOD", joinColumns =
@JoinColumn(name = "MEMBER_ID")
)
@Column(name="FOOD_NAME") //값타입이 하나(String), 그래서 컬럼 명을 바꿀 수 있음.
priavte Set<String> favoriteFoods = new HashSet<>();
@ElementCollection
@CollectionTable(name ="ADDRESS" joinColumns =
@JoinColumn(name = "MEMBER_ID")
)
priavte List<Address> addressHistory = new ArrayList<>();
- 외래키를 가지고 있어야되서 joinColumns를 넣어줘야됨.
- CollectionTable은 생성되는 table의 이름을 설정 가능.
컬랙션 사용
값 타입 조회 시, (값 타입 컬렉션도 지연 로딩 전략 사용, @ElementCollection에 전략이 Lazy로...)
값 타입 컬렉션은 영속성 전에(Cascade) + 고아 객체 제거 기능을 필수로 가진다고 볼 수 있다.
값 타입 수정 -> 수정시에는 그냥 새 객체를 넣어줘야됨. (이는 불변과 관련됨). setter를 열어두면 큰 문제가 생길 수 있음.
컬렉션 수정 -> Food의 값을 변경 하고싶을때, remove하고 add를 하자.
Member findMember = em.find(Member.class, member.getId());
findMember.getAddressHistory().remove(new Address("old1", "street", "10000"));
findMember.getAddressHistory().remove(new Address("old1", "street", "10000"));
- 삭제하고, 새 객체를 넣는것이다. 별 문제 없어 보인다.
- 문제는 쿼리를 보면 나타난다.
- 값 타입은 엔티티와 다르게 식별자 개념이 없다.
- 값은 변경하면 추적이 어렵다.
- 값 타입 컬렉션에 변경 사항이 발생하면, 주인 엔티티와 연관된 모든 데이터를 삭제하고, 값 타입 컬렉션에 있는 현재 값을 모두 다시 저장한다.
- 값 타입 컬렉션을 매핑하는 테이블은 모든 컬럼을 묶어서 기본
- 키를 구성해야 함: null 입력X, 중복 저장X
- 정말 단순할 때 사용하라.
값 타입 컬렉션 대신에 일대다 관계를 사용하는 것을 고려해라. 일대다 관계를 위한 엔티티를 만들고, 여기에서 값 타입을 사용 영속성 전이(Cascade) + 고아 객체 제거를 사용해서 값 타입 컬
렉션 처럼 사용
