JPA 소개
자바는 객체 지향적인 언어
데이터베이스는 관계형 DB
이 둘의 패러다임이 다르다
객체와 관계형 데이터베이스의 차이
1. 상속
2. 연관관계f
3. 데이터 타입
4. 데이터 식별 방법
객체는 상속관계가 있지만, 관계형 데이터베이스에서는 객체지향에서 말하는 상속관계는 없다.(비슷하게 슈퍼타입 서브타입으로 만들 수는 있음)
객체는 참조를 사용, 테이블은 외래 키를 사용해 JOIN을 해야됨.
보통 객체를 테이블에 맞추어 모델링. (테이블에서 사용하는 데이터나 객체가 가지고 있는 데이터가 다르기 때문에 DB를 사용한다면 테이블에 맞추어 설계. 그렇지 않으면 SQL문법 사용하기 귀찮아짐).
이는 객체다운 모델링은 아니다. 객체는 참조로 연관관계를 모델링 한다. 객체 안에서는 복잡한 변환 가정이 필요없다.
또한 객체는 자유롭게 객체 그래프를 탐색할 수 있어야 한다. 하지만 SQL은 처음 실행하는 SQL에 따라 탐색 범위가 결정 된다.
객체 답게 모델링 할 수록 관계형 데이터베이스 매핑 작업만 늘어난다.
이런 문제들을 해결한 것이 ORM기술 즉 JPA이다.
ORM?
- Object - relational mapping (객체 관계 매핑)
- 객체는 객체대로 설계, 관계형 DB는 관계형 DB대로 설계
- ORM 프레임워크가 중간에서 매핑

생산성의 증가 : 따로 SQL을 짤 필요가 거의 없음.
- 저장 persist
- 조회 find
- 삭제 remove
- 수정은 객체의 정보 변경
유지보수 : SQL의 경우 전부 다 바꿔줘야되지만, JPA의 경우 필드 추가만 하면 됨.
JPA는 객체지향 언어와 관계형 DB의 패러다임 불일치를 해결
상속, 연관관계, 데이터 타입, 데이터 식별 방법의 차이점을 전부 해결해준다.
1차 캐시와 동일성 보장
- 같은 트랜잭션 안에서는 같은 엔티티를 반환 - 약간의 조회 성능 향상
- DB Isolation Level이 Read Commit이어도 애플리케이션에서 Repeatable Read 보장
트랜잭션을 지원하는 쓰기 지연(transactional write-behind)
INSERT
- 트랜잭션을 커밋할 때까지 INSERT SQL을 모음
- JDBC BATCH SQL 기능을 사용해서 한번에 SQL 전송
UPDATE
- UPDATE, DELETE로 인한 로우(ROW)락 시간 최소화
- 트랜잭션 커밋시 UPDATE, DELETE SQL 실행하고, 바로 커밋
지연 로딩(Lazy Loading)과 즉시(Eagle) 로딩
- 지연 로딩: 객체가 실제 사용될 때 로딩
- 즉시 로딩: JOIN SQL로 한번에 연관된 객체까지 미리 조회
정리
중요한 점!!
JPA를 한다고 해서 절대 RDB를 몰라도 되는 것이 아님. 오히려 SQL을 잘 알아여 JPA에서 자동으로 만들어주는 쿼리를 생각할 수 있고, 매칭이 된다.
JPA와 RDB를 잘 공부해라.
JPA
JPA는 특정 데이터베이스에 종속 x
각각의 데이터베이스가 제공하는 SQL문법과 함수는 조금씩 다르다.
ex) MySQL의 VARCHAR, 오라클의 VARCHAR2 , 문자열 자르기 표준 SUBSTRING(), 오라클은 SUBSTR(), 페이징 MySQL은 LIMIT , Oracle은 ROWNUM
옵션으로 넣을 수 있는 설정.
hibernate.show_sql
hibernate.format_sql
hibernate.use_sql_commentsEntityManagerFactory emf = Persistence.createEntityManagerFactory("persistenceUnitName");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try{
//... logic
tx.commit();
} catch(Exception e) {
tx.rollback
} finally{
em.close();
emf.close();
}위의 코드는 순수하게 JPA를 사용하고 있는 모습이고, 실제로 스프링과 함께 사용하게 된다면 위의 코드가 대부분 사라지게 될 것이다.
주의
- EntityManagerFactory는 하나만 생성해서 애플리케이션 전체에서 공유
- EntityManager는 쓰레드간에 공유하면 안됨(사용하고 버려야 한다)
- JPA의 모든 데이터 변경은 꼭 트랜잭션안에서 실행해야 한다.
JPA는 JPQL로 쿼리를 만들수 있다. SQL문과 거의 비슷하다고 볼 수 있어서 SQL을 잘 알면 금세 익힐 수 있다.
- JPA를 사용하면 엔티티 객체를 중심으로 개발
- 문제는 검색 쿼리. 검색할 때도 테이블이 아닌 엔티티 객체를 대상으로 검색
- 모든 DB 데이터를 객체로 변환해서 검색하는 것은 불가능
- 애플리케이션이 필요한 데이터만 DB에서 불러오려면 결국 검색 조건이 포함된 SQL이 필요
- JPA는 SQL을 추상화한 JPQL이라는 객체 지향 쿼리 언어 제공
- SQL과 문법 유사 SELECT, FROm, WHERE, GROUP BY, HAVING, JOIN 지원
- JPQL은 엔티티 객체를 대상으로 쿼리, SQL은 데이터베이스 테이블을 대상으로 쿼리
JPQL은 뒤에서 다루겠다.
영속성 컨텍스트(Persistence Context)
JPA를 이해하는데 가장 중요한 용어.
엔티티를 영구 저장하는 환경 -> 엔티티를 영속성 컨텍스트에 저장한다는 개념.
J2SE 환경
EntityManager와 Persistence Context 1:1 매칭
스프링 프레임워크의 환경
EntityManager를 통해 Persistence Context와 N 대 1 매칭
엔티티의 생명주기
비영속(new/transient) - PersistenceContext와 전혀 관계가 없는 새로운 ㅏㅇ태
영속(Managed) - PersistenceContext에 관리되는 상태
준영속(detached) - PersistenceContext에 저장되었다가 분리된 상태
삭제 - 삭제된 상태
Member member = new Member(); // 비영속 상태. JPA와 아무 관련 없음
em.persist(member); // 영속 상태 PersistenceContext에 관리되고 있는 상태, 아직 DB에 저장되지는 않음.
em.detach(member); //PersistenceContext에서 분리, 준영속 상태
em.remove(member); // 객체를 삭제한 상태persist를 통해 엔티티를 조회하면 영속 컨텍스트에서 1차 캐시에서 조회를 한다.
만약 1차 캐시에 member가 있다면 반환, 없다면 DB에서 조회후 1차 캐시에 저장한뒤 반환한다.
영속 엔티티의 동일성 보장
같은 트랜잭션에서는 1차 캐시로 반복 가능한 읽기(REPEATABLE READ)등급의 트랜잭션 격리 수준을 데이터베이스가 아닌 애플리케이션 차원에서 제공
쓰기 지연
JPA는 INSERT 쿼리들을 모아서 commit 시점에 날린다.
Dirty Checking(변경 감지)
JPA는 찾아온 데이터를 변경하면 commit 시점에 dirty checking을 통해서 업데이트 쿼리를 날린다.
flush()를 날리며 엔티티와 스냅샷(최초로 영속 컨텍스트에 들어온 상태)을 비교해서 달라진 점이 있다면 update를 날려준다.
그래도 persist로 호출해야 하지 않나? 결론부터 말하자면 더티 체킹을 활용하라.
flush
영속성 컨텍스트의 변경내용을 데이터베이스에 반영하는 것
2가지 모드
FlushModeType.AUTO(기본값) 사실 바꿀일 없다고 보면 됨.
FlushModeType.COMMIT
변경 감지
수정된 엔티티 쓰기 지연 SQL 저장소에 등록,
쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송(등록, 수정 삭제 쿼리)
em.flush() - 직접 호출
트랜잭션 커밋 - 플러시 자동 호출
JPQL 쿼리 실행 - 플러시 자동 호출
주의
플러시가 호출된다고 해서 영속성 컨텍스트가 비워지는 것은 아니다. persistence context의 변경 내용을 데이터베이스에 동기화 할 뿐이다.
이런 매커니즘이 가능한 이유는 바로 커밋 직전에만 동기화 하면 되기 때문이다.
준영속 상태
영속 상태의 엔티티각 영속성 컨텍스트에서 분리(detached)
영속성 컨텍스트가 제공하는 기능을 사용하지 못함.
준영속 상태를 만드는 방법 몇가지
em.detach(entity); //특정 엔티티만 준영속 상태로 전환
em.clear(); //영속성 컨텍스트를 초기화
em.close(); //영속성 컨텍스트를 종료엔티티 매핑
@Entity가 붙은 클래스는 JPA가 관리하는 엔티티
- JPA를 사용해서 매핑할 클래스는 @Entity를 무조건 붙여야된다.
- 기본 생성자가 필수(pulbic, protected)
- fianl 클래스, enum, interface, inner 클래스 사용 x
- 저장할 필드에 final 사용 x
@Table은 엔티티와 매핑할 테이블 지정
- name : 매핑할 테이블 이름 (기본은 엔티티 클래스 이름 사용)
필드와 컬럼 매핑
@Column은 필드와 컬럼을 매핑
- name 속성으로 필드의 이름과 컬럼의 이름을 매핑시킬 수 있음. 없으면 기존 필드이름 사용
- insertable,updatable : 등록 변경 가능 여부,
- nullable(ddl) : null 값 허용 여부
- unique(ddl) : 간단하게 유니크 제약 조건을 걸고 싶을때 사용...(잘 사용은x, 테이블에 많이 사용)
- length(ddl) : 길이 설정 가능
- columnDefinition : 컬럼 정보를 직접 줄 수 있음. ex) varchar(100) default 'EMPTY'
- percision, scale(ddl) : precision은 소수점을 포함한 전체 자 릿수를, scale은 소수의 자릿수
@Enumerated
- enum 타입 매핑할 때 설정. EnumType.STRING (타입 값 이름 저장) , EnumType.ORDINAL (기본값, 타입 값의 순서를 저장)
- 중요!! 무조건 STRING으로 변경해서 사용해라. ORDINAL로 사용하면 문제가 생길 확률이 높음.
@Lob 데이터베이스 BLOB, CLOB 타입과 매핑
- 매핑하는 필드 타입이 문자면 CLOB, 나머지는 BLOB 매핑
이제는 거의 사용하지 않는 것
@Temporaljava.util.Date, java.util.Calendar 매핑, 자바8 시간, 날짜 타입 등장 이후로 안씀
-@transient 필드 매핑 x , 데이터베이스에 저장,조회 x
데이터베이스 스키마 자동 생성
- 애플리케이션 로딩시점에 DB 자동 생성 기능을 제공.
- 테이블 중심 -> 객체 중심
- 데이터베이스 방언을 활용해 데이터베이스에 맞는 적절한 DDL 생성.
- 이렇게 생성된 DDL은 개발 환경에서만 사용 해야 됨.
- 생성된 DDL은 운영 서버에서는 사용하지 않거나 적절히 다듬은 후에 사용해야됨.
hibernate.hbm2ddl.auto=옵션 //
create - 기존 테이블 삭제 후 다시 생성(Drop + Create)
create-drop - create와 같으나 종료 시점에 테이블 drop
update - 변경분만 반영
validate - 엔티티와 테이블이 정상 매핑되었는지만 확인
none - 사용하지 않음 , 관례상 적는거임. 사실 주석을 하거나, 아무거나 없는걸 넣는것과 같음.
//운영 장비에서는 절대 create, create-drop, update 사용하면 안된다.
// 개발 초기는 create 또는 update, 테스트 서버는 update , validate
// 스테이징과 운영서버는 validate 또는 none
// 사실은 개발 단계에서나 조금 사용하지 다른 상황에서는 거의 사용하지 말자DDL 생성 기능
- @Column(nullable=false, length=10)등..
- DDL 생성 기능은 DDL을 자동 생성할 때만 사용되고 JPA의 실행 로직에는 영향을 주지 않는다.
기본 키 매핑
@Id
@GeneratedValue
크게 두가지가 있다.
직접할당 -> @Id만 사용
자동생성 -> @GeneratedValue 사용
- IDENTITY : 데이터베이스에 위임, MYSQL
- SEQUENCE : 데이터베이스 시퀀스 오브젝트 사용, ORACLE, (@SequenceGenerator 필요)
- TABLE : 키 생성용 테이블 사용. (@TableGenerator 필요, 모든 데이터베이스에 적용 가능. 성능 문제)
- AUTO : 방언에 따라 자동 지정, 기본값
AUTO를 빼면 기본으로 3가지가 있음.
SEQUENCE를 직접 안만들면 hibernate_sequence라는 시퀀스를 적용해줌. 직접 지정할 수도 있음.
@SequenceGenerator(
name = “MEMBER_SEQ_GENERATOR",
sequenceName = “MEMBER_SEQ", //매핑할 데이터베이스 시퀀스 이름
initialValue = 1, allocationSize = 1)권장하는 식별자 전략
- 기본 키 제약 조건: null 아님, 유일, 변하면 안됨.
- 자연키는 이런 조건을 만족하는 것을 찾기 어렵다. 대리키를 사용하자.
- Long + 대체키 + 키 생성전략 사용
IDENTITY전략의 특징
- 기본 키 생성을 데이터베이스에 위임.
- JPA는 보통 트랜잭션 커밋 시점에 INSERT SQL 실행
- 데이터베이스에 INSERT SQL을 실행한 이후에 ID 값을 알 수있다.
- 따라서 IDENTITY 전략은 em.persist() 시점에 즉시 INSERT SQL 실행하고 DB에서 식별자를 조회
SEQUENCE전략의 특징
- 데이터베이스에서 시퀀스의 next value를 가져온다.
- 영속성 컨텍스트에 모았다가 쿼리를 날릴 수 있음.
- 시퀀스의 값을 가져오기 위해 계속 네트워크를 타면 성능 문제가 생길 수 있지 않나?
- allocationSize (시퀀스 한 번 호출에 증가하는 수, 미리 지정된 사이즈만큼 한번에 땡긴다.)
- default값은 50, 1~50을 사용하게 된다는 뜻이다. 이러면 DB를 직접 호출하지 않고 메모리를 호출한다는 뜻이다.
연관관계 매핑
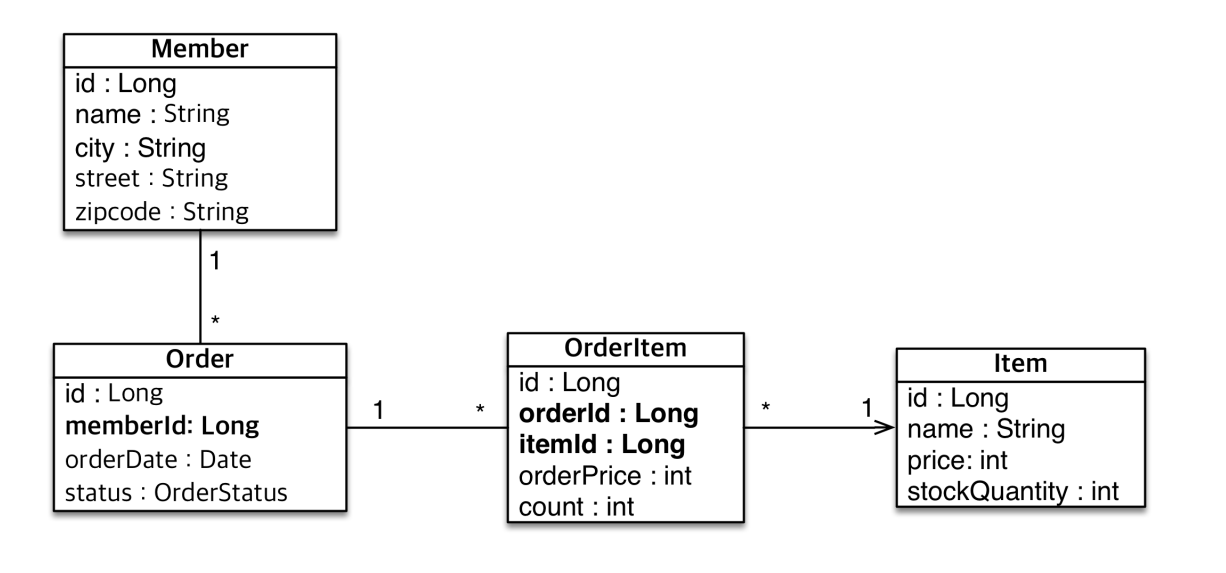
위의 테이블 매핑을 많이 봤을 것이다. 이것은 일반적인 관계형 DB에서의 관계를 나타낼때 만들 수 있는 테이블일 것이다. 하지만 JPA에서는 이런 식으로 매핑하지 않는다.
• 현재 방식은 객체 설계를 테이블 설계에 맞춘 방식
• 테이블의 외래키를 객체에 그대로 가져옴
• 객체 그래프 탐색이 불가능
• 참조가 없으므로 UML도 잘못됨
객체지향 설계의 목표는 자율적인 객체들의 협력 공동체를 만드는 것이다.
객체의 참조와 테이블의 외래키를 매핑
단방향 연관 관계
예시
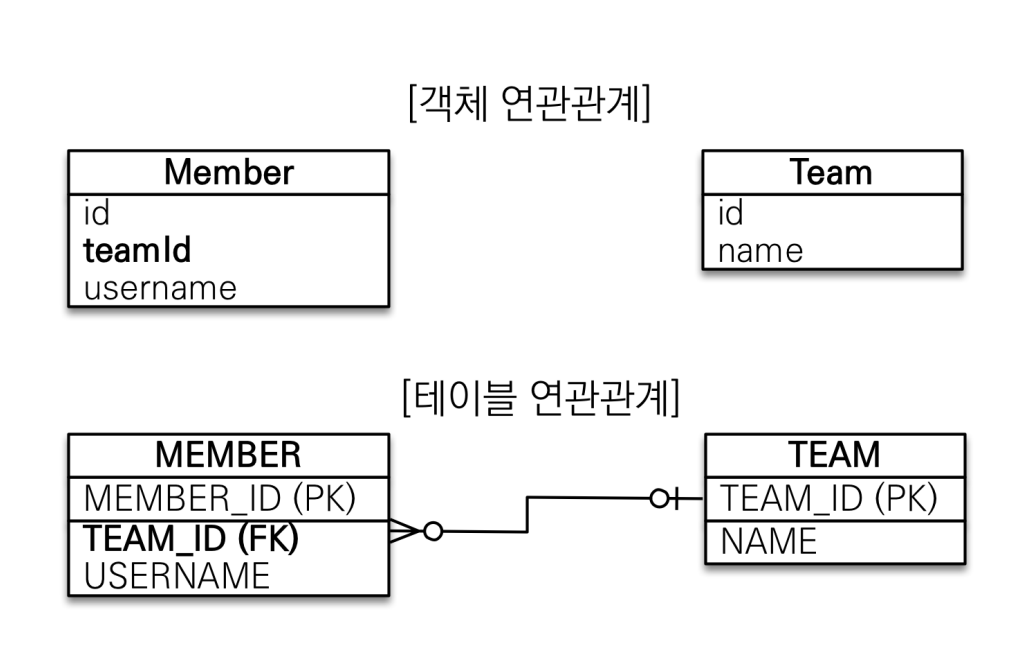
멤버는 팀의 pk를 외래키로 가지고 있다. Member (N) : TEAM(1) 의 관계
이 상황에서 객체로 매핑을 시켜준다면
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
private int age;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
...
}객체의 연관관계 매핑은 바로 이런 식으로 객체를 필드값으로 받는 것.
@ManyToOne - 멤버는 FK로 TEAM을 받는 것이기때문에, 1대 N의 관계에서 N이라는 것.
@JoinColumn(name = "TEAM_ID")로 무엇과 조인되는 컬럼인지 알려주는 것
핵심은 외래키와 객체의 매핑. 이것을 잘 기억하자!
양방향 연관관계
테이블의 연관관계는 외래키 하나로 양방향으로 조회할 수 있다. 하지만 객체에서는 맴버에서 팀으로 갈수는 있지만 팀에서 맴버로 갈 수는 없다.
@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
// 핵심
@OneToMany(mappedBy = "team")
List<Member> members = new ArrayList<Member>();
…
} 팀에서 맴버로 가는것은 @OneToMany이다. 그리고 맵되는 것을 이야기 해줘야 된다. 이때는 맴버의 team 필드에 매핑 되는 것이니 mappedBy = "team"이라 쓰면 된다.
-
객체 연관관계 = 2개
o 회원 -> 팀 연관관계 1개(단방향)
o 팀 -> 회원 연관관계 1개(단방향) -
테이블 연관관계 = 1개(FK하나로 끝이남)
o 회원 <-> 팀의 연관관계 1개(양방향) -
객체의 양방향 관계는 사실 양방향 관계가 아니라 서로 다른 단 뱡향 관계 2개다.
-
객체를 양방향으로 참조하려면 단방향 연관관계를 2개 만들어 야 한다
연관 관계의 주인
객체에 2개의 단방향 연관관계를 만들어 양방향 관계를 만들어냈다. 그렇다면 이때, 둘 중 하나로 외래 키를 관리해야 한다. 과연 누구로 관리해야 되는가?
답은 바로 외래 키이다. 외래 키가 있는 있는 곳을 주인으로 정하면 된다.
양방향 매핑 규칙
• 객체의 두 관계중 하나를 연관관계의 주인으로 지정
• 연관관계의 주인만이 외래 키를 관리(등록, 수정)
• 주인이 아닌쪽은 읽기만 가능
• 주인은 mappedBy 속성 사용X
• 주인이 아니면 mappedBy 속성으로 주인 지정
양방향 매핑시 가장 많이 하는 실수
- 연관관계의 주인에 값을 입력하지 않음. 즉 멤버에서 값을 넣지 않고, 팀에서 값을 넣어버림.
하지만.... 순수한 객체 관계를 고려하면 항상 양쪽 다 값을 입력해야 한다.
-
완전히 flush, clear하면 문제가 없다. 하지만 영속성 컨텍스트에서 flush 되기전에 찾게되면 SQL문이 날라가기전의 상태가 찾아져서 온다.
-
테스트 케이스에서는 JPA없이 순수한 자바코드로도 작성을 하는데, 이때 주인쪽에만 값을 넣으면 반대쪽(주인이 아닌 쪽)에서 값이 이상하게 나온다.
즉 양방향 연관관계에서는 항상 양쪽에 값을 설정하자
그런데, 두번이나 넣기 귀찮거나, 깜빡할 수 있다.
이럴때 연관관계 편의 메서드를 만들자.
Member(주인쪽)에서 Team과 관련된 값을 변경할때..
public void changeTeam(Team tema) {
this.team=team;
team.getMembers().add(this);
}
- 위 예제는 매우 간편하게 짠 로직이다. 조금 더 복잡하게 팀에 있나없나도 체크 가능..
- 위의 것은 Team의 setter인데, 로직이 들어갔기 때문에 setter라는 이름보다는 명확하게 이름을 지어주는 편이 낫다.
- 연관관계 편의 메서드는 어느쪽에 만들어도 상관은 없다. 다만 둘중에 한군데서만 해야된다.
주의점
양방향 매핑시에 무한 루프를 조심하자.
- toString(), lombok (롬복에서 toString을 쓸때는, 한쪽에 빼고 써라)
- JSON 생성 라이브러리(컨트롤러에서 엔티티를 바로 반영하면 문제가 생김. 다만 컨트롤러에는 엔티티 변경 자체를 안하는 식으로 로직을 짜기 때문에 큰 문제는 없음)
정리
- 단방향 매핑만으로도 이미 연관관계 매핑은 완료
- 양방향 매핑은 반대 방향으로 조회(객체 탐색 그래프) 기능이 추가된 것 뿐
- JPQL에서 역방향으로 탐색할 일이 많음(양방향이 필요하다는뜻..)
- 단방향 매핑을 잘 하고 양방향은 필요할 때 추가해도 됨(테이블에 영향을 주지 않음)
다음으로...
