웹 크롤러
- 하나의 페이지를 가져오고, 그 페이지가 가르키는 모든 페이지를 가져오는 방식을 재귀적으로 동작
- 웹을 돌아다니며 끌어 모은 데이터를 DB에 저장하여 검색기능지원
루트집합이라는 출발점의 URL 집합을 가진다. 루트집합은 여러 페이지로 연결되는 아주 큰 사이트와 고립된 아주 작은사이트들로 이루어져있다
문제점
-
A -> B -> C -> A 로 링크가 되면 무한루프의 굴레에 빠지기때문에 웹서버에 부담을 주게된다.
-
따라서 방문했던 페이지를 재방문 하지않도록 처리하는 알고리즘 기법이 필요하다
- 트리와 해시테이블 : URL을 빨리 찾아볼수있도록 해줌
- 느슨한 존재 비트맵 : 각 URL은
존재비트를 가짐. 존재비트의 유무로 방문여부 판단. - 파티셔닝 : 웹의 부분을 담당하는 컴퓨터, 크롤러를 배치하여 나눠서 크롤링. 및 서로 도와주거나 상호간의 정보 교환
- 별칭과 로봇순환 : 기본포트, index.html 등 다른 URL이 같은 URL을 가르키는경우
-
URL 정규화 : 표준 URL로 정규화 하여 같은 URL리소스를 가르키는 다른 URL의 중복을 제거함
-
파일 시스템 링크 순환 :
subdir/이/로 링크된경우 sub/sub/sub/sub...로 연결될 위험이 있다 -
동적 웹공간 : 평범한 파일처럼 보이는 게이트웨이 애플리케이션에 접근했을때, 가상의 URL을 가지는 새로운 HTML을 만들어 고의로 크롤러를 루프로 빠트릴수도있다
해결방안
- URL 정규화 : URL을 표준형태로 변환하여 중복제거
- 너비우선 크롤링 : 너비우선탐색(BFS)으로 스케쥴링 하여 루프위험을 최소화.
- 너비우선과 깊이우선탐색 : https://yunyoung1819.tistory.com/86
- throttling : 일정시간동안 로봇이 가져올수있는 페이지(접근, 중복) 숫자를 제한한다.
- URL 크기제한 : 순환으로 길어지는 URL의 길이를 일정길이(보통 1KB)로 제한시킬수있다.
- 블랙리스트 : 문제를 일으키는 URL들은 블랙리스트에 추가 (주로 사람손이 필요)
- 패턴 발견 :
sub/sub/sub/sub...또는sub/img/sub/img/sub/img...등 특정 반복패턴의 주기가 발견된다면 크롤러는 이를 거절함 - 콘텐츠 지문 :
checksum이라는 페이지의 요약을 가져와 기존에 보았던 체크섬인지 비교하여 비교한 체크섬이면 크롤링을 패스한다.
https://coding-lks.tistory.com/146 - 사람의 모니터링 : 진단 및 로깅을 통해 모니터링이 가능하도록 설계
로봇의 HTTP
- 많은 로봇들이 요구사항이 적은 HTTP/1.0요청을 사용하며, HTTP를 최소 한도로만 지원하려함
- 로봇의 신원, 능력, 출신을 알려주는 헤더(ex. User-Agent, From, Accept, Referer)를 전송함
- 가상호스팅(하나의 서버에 여러개의 도메인을 호스팅)이 많아,
Host헤더를 지원해야함 - 조건부 요청(시간이나 엔터티 태그를 비교)을 함으로써 기존에 긁은 내용이 업데이트 되지않았다면 재검색을 하지않는 방법으로 검색하는 콘텐츠의 총량을 줄인다
- 로봇은
200 OK나<meta http-equiv="" content="" URL="">같은 HTTP응답을 다루기도한다. - 웹 관리자는 로봇이 사이트에 방문할것을 알고 로봇의 요청을 다루기위한 전략을 세워야한다.(풍부한 기능을 갖추지 못한 브라우저나 로봇에도 대응)
로봇의 부적절한 동작
- 오래된 URL
- 길고 잘못된 URL
- 호기심이 지나친로봇
- 동적 게이트웨이 접근
로봇 차단
- 문서루트 최상단에
robot.txt파일을 선택적으로 제공하여, 로봇의 접근을 제어할수있다. - robot.txt파일은 최상단에서 단 1개만 존재한다
- 로봇은 페이지 요청전 robot.txt를 검사하여 권한이 부여된 내용만 검색한다
- 로봇이 http get요청으로 robot.txt를 요청하며,
200이면 제한규칙에 따라 크롤링,404가 뜬다면 제한없이 크롤링,401또는 403이 뜬다면 완전히 제한,503이 뜬다면 크롤링을 미룸,3XX이 뜬다면 리다이렉트를 따라가도록 동작한다
robots.txt 포맷
주석줄 + 규칙줄 + 빈줄로 구성
# 주석
User-Agent : slurp
User-Agent : webcrawler
Disallow : /private-
User-Agent : 로봇의 이름이 매치되는 문자를 포함하는 문자열이라면 접근제한 (대소문자 구분 X)
User-Agent : bot은Bot,Robot,Bottom,Spambot등 부분문자열로 포함하는 모든 단어에 매칭됨을 유의해야함
-
Disallow, Allow : User-Agent다음줄에 오며 허용사항을 명시적으로 기술함 (대소문자 구분)
Disallow : /tmp는http://www.aaa.com/tmp,http://www.aaa.com/tmp/...,http://www.aaa.com/tmpspc/...모두 매칭됨
-
유의사항
- 명세가 발전함에 따라 다른 필드가 추가됨, 로봇은 이해하지못하는 필드는 무시해야함
- 한줄을 여러줄로 나누는것은 허용하지않는다
- 주석은 어디든 사용가능
캐싱
robot.txt를 가져올때 주기적으로 가져오되, 캐싱을 한다. 캐시된 사본은 Expires헤더값 만큼 캐싱되어 사용된다.
로봇 차단 펄코드?
로봇제어 META태그
권장사항, 필수는 X, 대소문자 구분 X, 중복 X
<meta name="robots" content="">- noindex : 해당 페이지를 무시
- nofollow : 이 페이지의 링크된 페이지를 무시
- index : 해당 페이지 허용
- follow : 링크된 페이지 허용
- noarchive : 캐시 사본생성 금지
- all : index + follw
- none : noindex + nofollow
로봇 에티켓 ?
검색엔진
- 엄청난 규모로 인해 검색엔진은 많은 장비를 똑똑하게 사용하여 요청을 병렬적으로 수행할수있어야한다.
- 검색엔진은
풀텍스트 색인이라는 로컬 데이터베이스를 생성한뒤, 크롤링된 결과를 이에 저장한다. - 검색엔진에 사용자가 입력단어를 요청하면 이 풀텍스트 색인 DB에 질의요청을 하게된다.
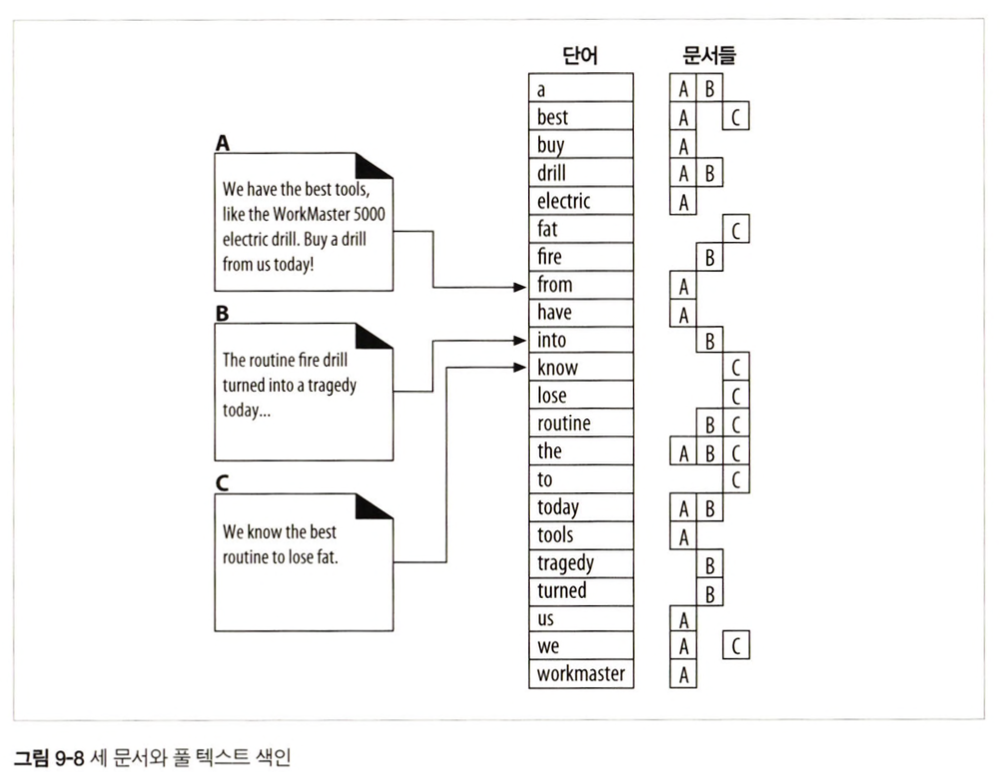
풀 텍스트 색인
A,B,C 3개의 사이트에 포함된 텍스트를 크롤링하면 오른쪽과 같은 풀텍스트 색인 DB가 생성된다.
각 단어를 포함하는 문서목록을 도출함.
질의 보내기
- 사용자가 Form으로 GET,POST요청을 이용해서 게이트웨이로 보내는형태.
- 이 게이트웨이는 질의를 추출하여 풀 텍스트 색인으로 요청하는 표현식을 반환함.
검색결과 정렬
- 요청된 질의를 해석해서 풀텍스트색인에서 검색을해도 위 그림처럼 수많은 사이트가 검색이된다. ("the"는 A,B,C 모두 검색됨).
- 따라서 해당 단어와 관련이 많은 결과순으로
관련도 랭킹이 메겨진다. - 이런 정렬과정에 크롤링된 수집 통계 데이터가 활용됨
스푸핑
SEO결과를 조작..?

프론트엔드개발