
http 는 여러 언어와 문자로 된 국제문서의 전송을 지원해야한다.
엔터티 본문은 단순 비트들로 채워져있는데, 이 장에서는 이를 문자언어로 지원해주는 문자집합 인코딩과 언어태그에 관해 알아보자
문자집합
서버는 아래 헤더를 통해 문서의 문자와 언어를 알려준다
- Content-Type의 charset
- Content-Language
Content-Type: text/html; charset=UTF-8클라이언트는 아래 헤더를 통해 사용가능한 인코딩 알고리즘과 언어를 명시한다
- Accept-Charset
- Accept-Language
Accept-Language : fr, en; q=0.8 // q값을 통해 프랑스어를 1순위(1.0) 영어를 2순위(0.8)로 둔다
Accept-Charset : iso-8859-1, utf-8charset : 엔터티 콘텐츠의 비트들을 특정 문자로 변환(디코딩) or 문자를 비트로 변환(인코딩) 할 수 있는 알고리즘
MIME charset : 인코딩과 문자집합의 결합. HTTP는 표준화된 MIME charset 값을 사용한다.
us-ascii, iso-8859-n, utf-8 등등이 있다.
utf-8: 주로 쓰이는 UCS(유니코드)를 표현하기위한 가변길이 문자 인코딩. 통상적인 7바이트 아스키 문자열에 대한 하위호환성이 있다.
문자 디코딩
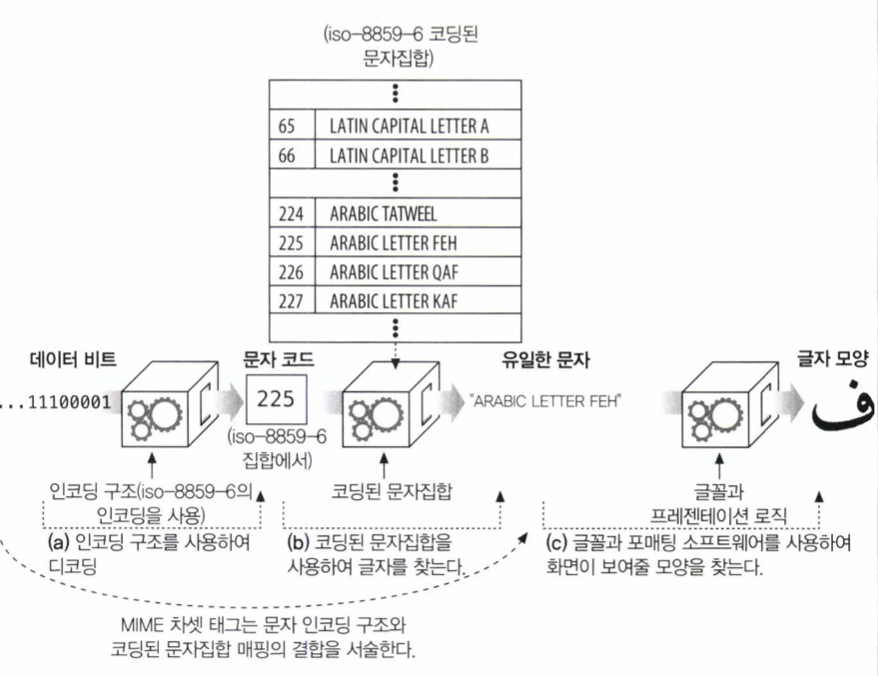
- 엔터티 본문에 해당하는 비트들은 특정 문자집합(charset)의 식별될수있는 문자 코드로 변환됨(255)
- 앞에서 식별된 문자코드(255)에 해당하는 값 "ARABIC LETTER FEH"를 찾고
- 글꼴 포매팅 S/W를 통해 해당되는 글자모양을 찾는다.
-
여기서 HTTP는 언어의 라벨 전송에만 관여한다(255와 "ARABIC LETTER FEH"까지). 글자의 모양을 표현하는 일은 HTTP와 무관함.
-
charset을 잘못 지정하면 엉뚱한 언어가 나옴.(같은 비트더라도 charset에 따라 다른 언어를 나타냄)
헤더와 META태그
-
Content-Type : 서버가 클라이언트에게 MIME-charset을 명시해준다.
만약 명시되어있지 않다면 수신자는 문서의 콘텐츠로부터 문자 집합을 추측한다.
html콘텐츠 라면 아래 meta 태그에서 찾을수있다.
<meta http-equiv="Content-Type" content="text/html" charset="utf-8" />
Content-Type 헤더가 없고 html콘텐츠가 아니라면 텍스트를 스캐닝해 패턴을 찾아내고,
패턴을 찾지 못했다면 iso-8859-1인것으로 가정한다. -
Accept-Charset : 대부분의 클라이언트는 모든 문자 체계를 지원하지않는다. 따라서 지원가능한 MIME-charset을 명시해줘야한다.
아래는 클라이언트가 서유럽, 가변길이 유니코드 모두 호환됨을 말해준다.
두 인코딩 구조중 어떤것으로 반환할지는 서버 자유이다
Accept-Charset : iso-8859-1, utf-8
문자집합
- 문자 : 기본단위로, 한 문자는 여러가지 다른 쓰기 형태를 가질 수 있다. ex) 소문자 a의 여러 형태
- 글리프 : 각 글자를 그리는 특정한 방법. 연자..?
- 코딩된 문자 : 정수를 글자로 대응. 코드번호로 인덱싱된 배열의 원소들을 문자열화 한것.
- 코드 공간 :
- 코드 너비
- 사용가능 문자집합
- 코딩된 문자집합
- 문자 인코딩 구조
언어태그
표준화된 문자열. (kr, en, fr...)
- Content-Language : 엔터티가 어떤 언어 사용자를 대상으로 하는지. 또 텍스트 뿐만 아니라 오디오, 영상 등등에 해당함.
사용된 언어 모두를 뜻하는게 아닌. 사용 의도에 따라 표기하는것이 맞다. - Accept-Language : 클라이언트 측에서 선호되는 언어 제약
언어태그
언어태그는 하이픈으로 분리된 하나 이상의 서브태그들로 이루어져있다.
- 첫번째 서브태그(주 서브태그) : ISO 639 표준화 된 언어 토큰
- 두번째 서브태그(선택적) : ISO 3166 국가코드와 지역표준 집합에서 선택된 국가 토큰
- 세번째 서브태그 : 8자 이하 알파벳과 숫자로 이루어져있고 그 외 규칙은 없음
대소문자 구분은 없으나, 언어는 소문자, 국가는 대문자로 표기함(언어 : fr / 국가 : FR)
국제화된 URI
오늘날 대부분 URI는 US-ASCII 문자들의 제한적인 집합으로 이루어져있다.
ASCII는 아래 처럼 구성되어있다.
- 예약된 문자 :
;/?:@&... - 예약되지 않은 문자 :
A-Za-z0-9-_!~...
URI 이스케이핑, 역이스케이핑
이스케이핑은 예약된 문자 or 지원하지 않는 글자들을 URI에 안전하게 삽입 할 수 있는 방법.
% + 16진수 글자 2자로 이루어져있음.
역 이스케이핑을 2번 하지않도록 주의해야함. 2번 역이스케이핑시 데이터손실 발생 (32 -> %20 -> %25 ? ?)
