DenseNet
DenseNet은 CVPR-2017에 best paper를 받은 모델로
"Densely Connected Convolutional Networks” 라고도 합니다.
당시의 CNN 연구가 구조적으로 더 깊고 정확한 성능을 낼 수 있는 방법에 대해
input layer 와 output layer가 direct하게 연결될 수 있는 shorter connection 개념에 집중해, 효율적으로 학습하는 형식으로 발전하고 있습니다.
이때의 네트워크 들은 점점 깊어지고 정확해지며,
짧은 connection들을 많이 사용하기 시작했습니다.
(ResNet이 굉장한 성능을 보여줬었습니다.)
이러한 observation 들을 가지고 많이 연결을 하여 각 layer 간의
최대한의 정보흐름을 이용하자는 것이 DenseNet 입니다.
DenseNet의 장점
1. vanishing gradient(기울기 소실)를 방지할 수 있습니다.
2. feature propagation을 강화할 수 있다.
3. feature의 재사용이 권장된다.
4. 파라미터 수를 많이 줄일 수 있다.
4개의 대표적인 데이터셋(cifar-10, cifar-100, SVHN, ImageNet)에서 모두 좋은 성능을 거두었으며, 당시 최신 기술의 성능이면서도 계산 복잡도를 엄청나게 낮추었습니다.
DenseNet 구조
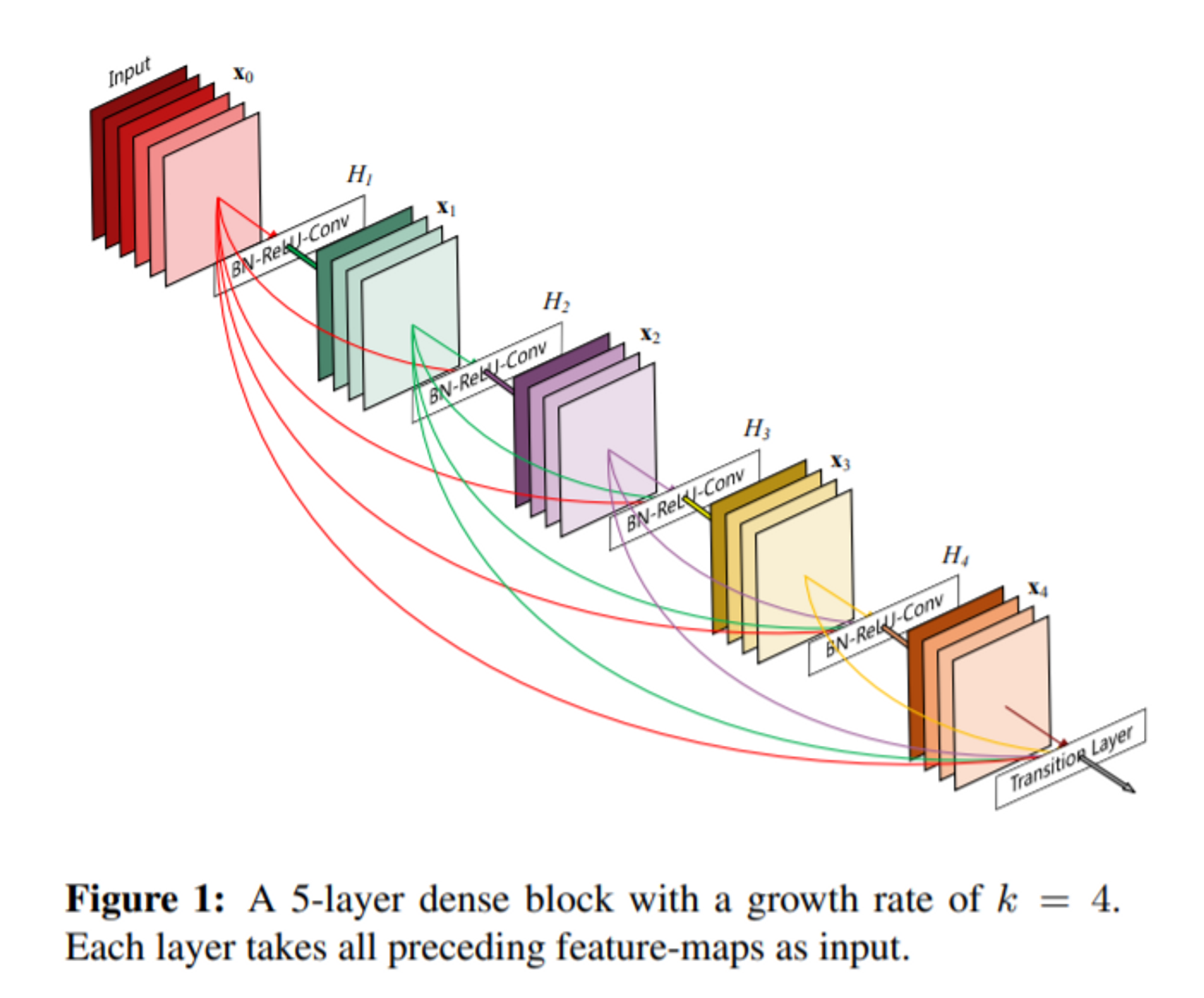
논문 앞면에 바로 보이는 이 블럭들이 DenseNet의 구조도입니다.
input부터 output까지 전부 L(L+1) / 2 개의 connection이 보이는 걸 확인할 수 있습니다.
앞서 나온 ResNet과의 가장 큰 차이점은 connection 방식입니다.
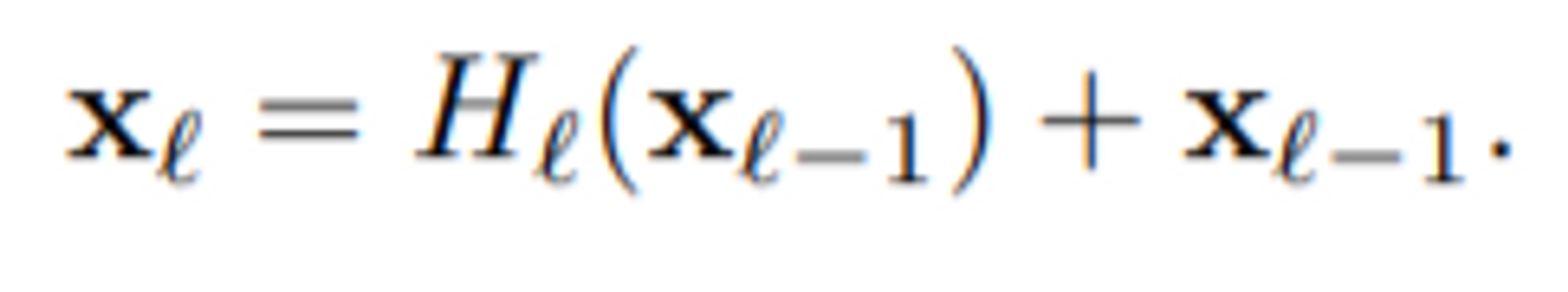
(ResNet의 connection 방식)
ResNet은 Conv layer를 거쳐 나온 output 피쳐맵 값들과 Conv layer를 거치기 전 input 피쳐맵 값들을 서로 element wise하여, 같은 자리의 값끼리 add하는 방식으로 connection을 해주어 다음 layer의 입력값으로 넣어주는 구조를 취했습니다.
(이렇게 잔차를 학습하는 형태를 만든다고 해서 ResNet이라는 이름이 붙었습니다.)
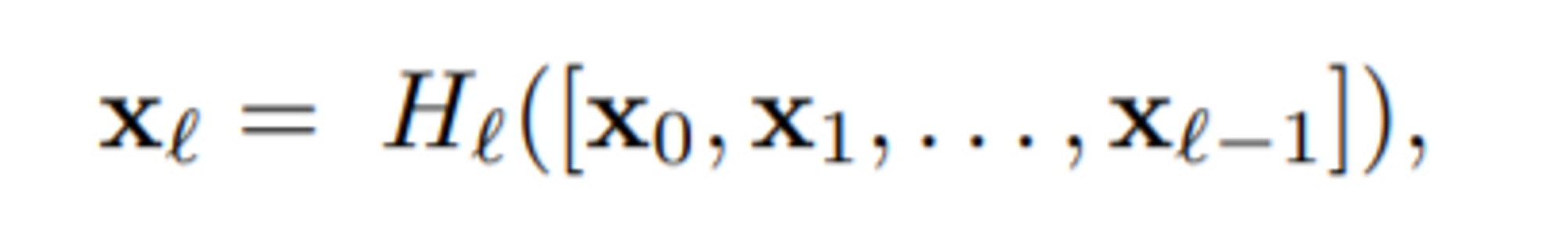
(DenseNet의 connection 방식)
input값 x0부터 순차적으로 보면, x0가 H1을 거쳐서 초록색의 피쳐맵 4장 x1을 생성합니다.이때 x1이 H2의 입력값으로 들어가기 전에 x0와 x1을 concatenate해줍니다.
(여기서 add해주는 ResNet과는 다른 방식입니다.)
이렇게 계속 h layer를 거칠때마다 이전에 입력값이었던 output 피쳐맵들을 계속 concat하여 입력해주는 것입니다. 이때 각 dense block에서 몇 개의 피쳐맵을 뽑을지 결정하는 하이퍼 파라미터는 논문에서 growth rate 'k'라고 하며, 이 값은 모델의 파라미터의 수에 직접적인 영향을 갖는 인자입니다.
ResNet과는 마찬가지로 반드시 같은 사이즈의 feature map끼리 connection이 통하고,
마지막 Dense block으로 output이 나오면, 끝의 Transition Layer 로 진입합니다.
Transition Layer
Transition Layer는 1x1 Conv layer -> 2x2 avgPooling(2stride) 로 구성되어있습니다.
transition layer는 Dense block에서 down sizing을 할 수 없으니, 1x1 Conv layer로 일단 한번 feature들을 정리해준 뒤 Pooling을 통해 half size로 줄이는 역할을 해줍니다.

위의 Dense block과 transition layer를 결합하여 최종적으로 위 사진과 같은 아키텍쳐가 됩니다.
DenseNet 강점
DenseNet은 굉장히 직관적입니다. 이전의 입력값을 넣어주고 그 입력값이 dense block을 거쳐 바뀐 값을 concat하여 원본 값과 바뀐 값을 함께 넣어 인코딩이 이루어집니다.
ResNet은 add함으로써 보존해야할 정보를 change하여 다음 layer에 전해주는데 반해,
DenseNet은 정보를 바꾸지 않으면서도 direct하게 하위의 모든 layer에 뿌려줍니다.
(information flow가 매우 잘 된다는 뜻입니다.)
이 방식의 장점은 information flow뿐만 아니라 gradient flow도 원만하게 해줍니다.
모델이 깊어질수록 초반부까지 gradient가 흘러가기가 힘든데, 최상단의 입력값이
최하단의 입력값에도 존재하니 gradient flow가 매우 좋은 이유입니다.
이런식으로 기울기가 잘 보존될 정도로 효율적이니 computational cost도 적습니다.
