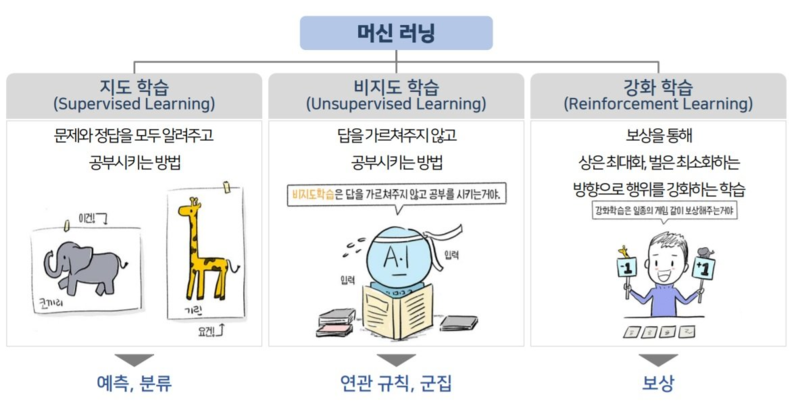
Supervised Learning : 지도학습
문제와 정답을 같이 학습시켜서 머신러닝을 진행하는 기법. Input data와 Label( 또는 class) 정보를 입력하여 학습하고, 새로운 데이터가 들어오면 label을 예측합니다.
주가하락세 전환 팩터의 경우, 크롤링한 feature(문제)와 주가하락세 여부(정답)를 학습시켜서 알아보고 싶은 팩터의 feature를 넣었을 때 주가하락세인지 아닌지를 파악하는 지도 학습이 필요합니다.
Dimension Reduction : 차원 축소
데이터의 크기(row 수)는 같으나 Feature(column수)가 많아지게 되면 적은 데이터로 공간(차원)을 표현하게 됩니다. 이 경우 과적합(Overfitting) 이 발생할 수 있는데 이러한 문제를 차원의 저주라고 합니다.
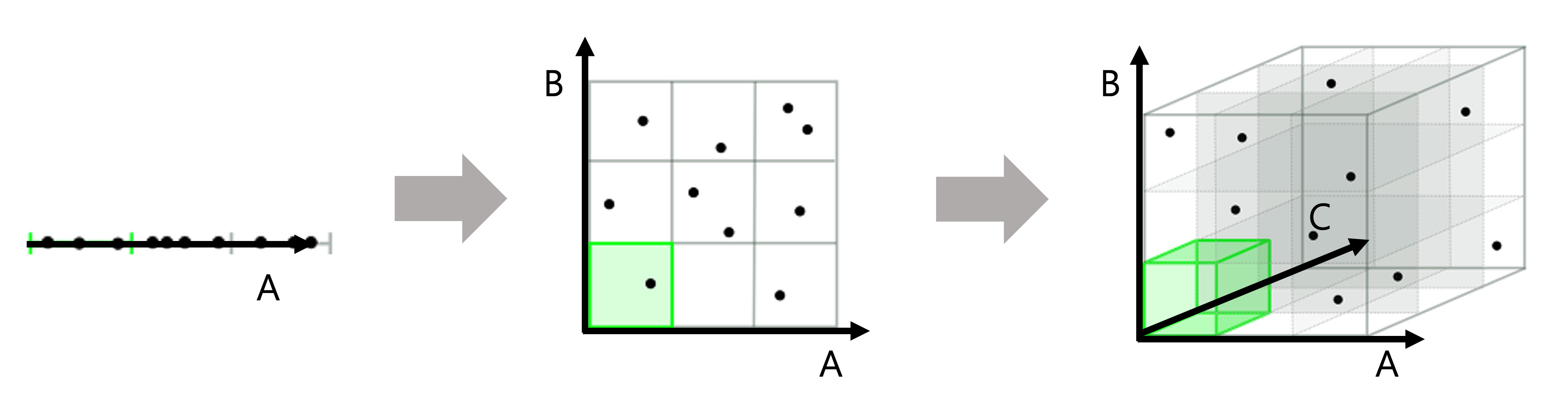
이외에도 많은 feature를 가지게 되면 특성끼리 상관관계가 높은 다중 공산성의 문제가 있을 수 있고 알고리즘의 복잡성을 증가시켜 오히려 예측 성능을 낮추게 됩니다. 이러한 문제점들을 해결하기 위해 차원의 수를 줄이는 방법인 차원 축소 방법이 사용되고 있습니다.
-
Feature Selection : 불필요한 특성은 제거하고, 데이터의 특징을 잘 나타내는 특성만 선택. Filter method, Wrapper method, Embedded method
-
Feature Extraction : 원래의 특성을 조합하여 데이터를 가장 잘 표현할 수 있는 중요한 성분들을 가진 새로운 특성을 추출하는 것을 말합니다. 기존 변수들과 완전히 다른 값을 가지게 되어 추출된 변수의 해석이 어렵다는 단점이 있습니다. 대표적인 방법으로 PCA, SVD, LDA, t-SNE 기법 등이 있습니다.
저희는 이 중에서 Decision Tree에서 Feature Importance를 뽑아서 적절한 feature들을 고르는 Feature Selection방법을 선택했습니다.
Feature Extraction의 경우 어떤 방식으로 feature가 제외되었는지 영업적으로 설명하기 어려운 문제가 있어서 제외하였습니다.
Oversampling
차원 축소와 더불어 데이터의 크기(row 수) 자체도 증가시키는게 필요합니다. 차원 축소 만으로는 차원의 저주를 해결하기 힘들기 때문입니다. 이런 방법 중 하나가 Oversampling입니다.
한 쪽 데이터 수가 적을때 여러 기법으로 학습에 충분한 데이터를 확보하여 클래스 불균형을 해소하는 방법입니다. 반대로 한쪽이 크면 줄여서 불균형을 해소하는 것은 undersampling이라고 합니다.
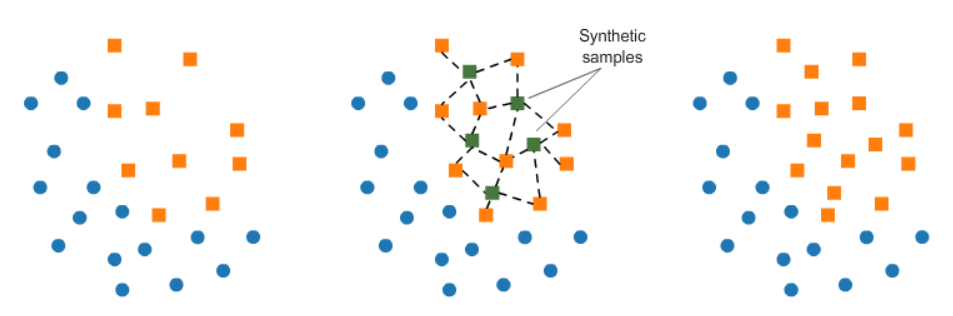
- SMOTE(Synthetic Minority Over-sampling Technique) : 적은 데이터 세트에 있는 개별 데이터들의 K 최근접 이웃(K Nearest Neighbor)을 찾아 이 데이터와 K개 이웃들의 차이를 일정 값으로 만들어 기존 데이터와 약간만 차이가 나는 새로운 데이터를 생성합니다. → 과적합 방지
!pip install -U imbalanced-learn
# imbalanced-learn 패키지
from imblearn.over_sampling import SMOTE
# SMOTE 객체 생성
smote = SMOTE(random_state=42)
# 샘플링
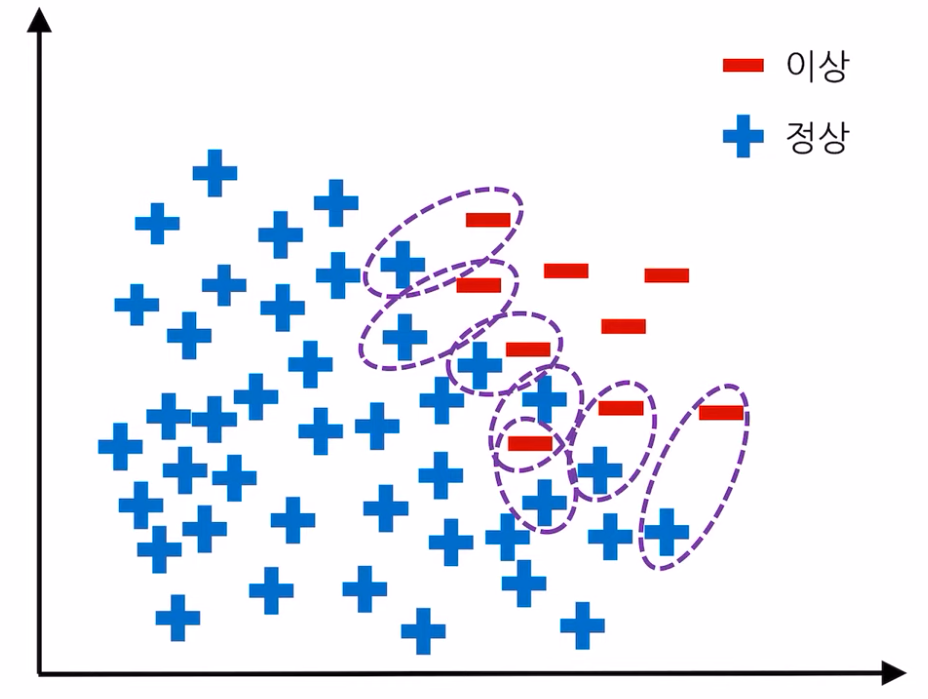
X_train_resampled, y_train_resampled = smote.fit_resample(X_train, y_train)- SMOTE-Tomek :Oversampling(SMOTE)과 Undersampling(Tomek Links)을 함께 수행하는 방법. SMOTE를 먼저 수행 후 두 샘플 사이에 기타 관측치가 없는 경우인 Tomek Link를 찾아서 다수 범주에 속하는 샘플을 제거합니다. 아래는 Tomek Links의 예시
from imblearn.combine import SMOTETomek
from imblearn.under_sampling import TomekLinks
smoteto = SMOTETomek(tomek=TomekLinks(sampling_strategy='majority'))
X_churn_smt, Y_churn_smt = smoteto.fit_resample(X_churn, Y_churn)- ADASYN(Adaptive Synthetic Sampling Approach) :
각 관측치마다 생성하는 샘플의 수가 다른 oversampling 방법(SMOTE는 마이너 클래스가 여러개면 생성 샘플 수 동일).
다수를 차지하는 클래스 주위에 해당 클래스가 아닌 소수의 다른 클래스가 있다면, 이 소수 클래스에 속한 인위적 (synthetic) 데이터를 많이 생성하여, 클래스 간의 경계를 더욱 확고히 하는 기법이다.
from imblearn.over_sampling import ADASYN
adasyn = ADASYN(random_state=22)
X_churn_ad, Y_churn_ad = adasyn.fit_resample(X_churn, Y_churn)