
Write scale-out
1. 앞서 이야기한 replication은 주로 read를 scale-out하는 목적이지 write를 scale-out하지는 않는다. 이론적으로는 가능하다고 하는데 wrset, 2phase commit을 사용하는 virtual-synchronouse 작업이 모든 노드에 write를 강제하는 작업이 너무 느려서 현상적으로 그렇다는 것 같다
2. write scale-out을 위해서 생각할 수 있는 첫 번째로 샤딩이 있는데 예를 들어 현재 A,B,C 병원의 DB를 다르게 운용한다고 했을 때, DB 간 크기가 고르지 못하게 저장하는 문제가 있을 수 있다. 한 병원에서 환자, 차트, 오더 등의 정보를 독립적으로 저장하는 것도 샤딩이라 할 수 있는데 개념적인 차원에서만 짚고 넘어가자.
Spider engine
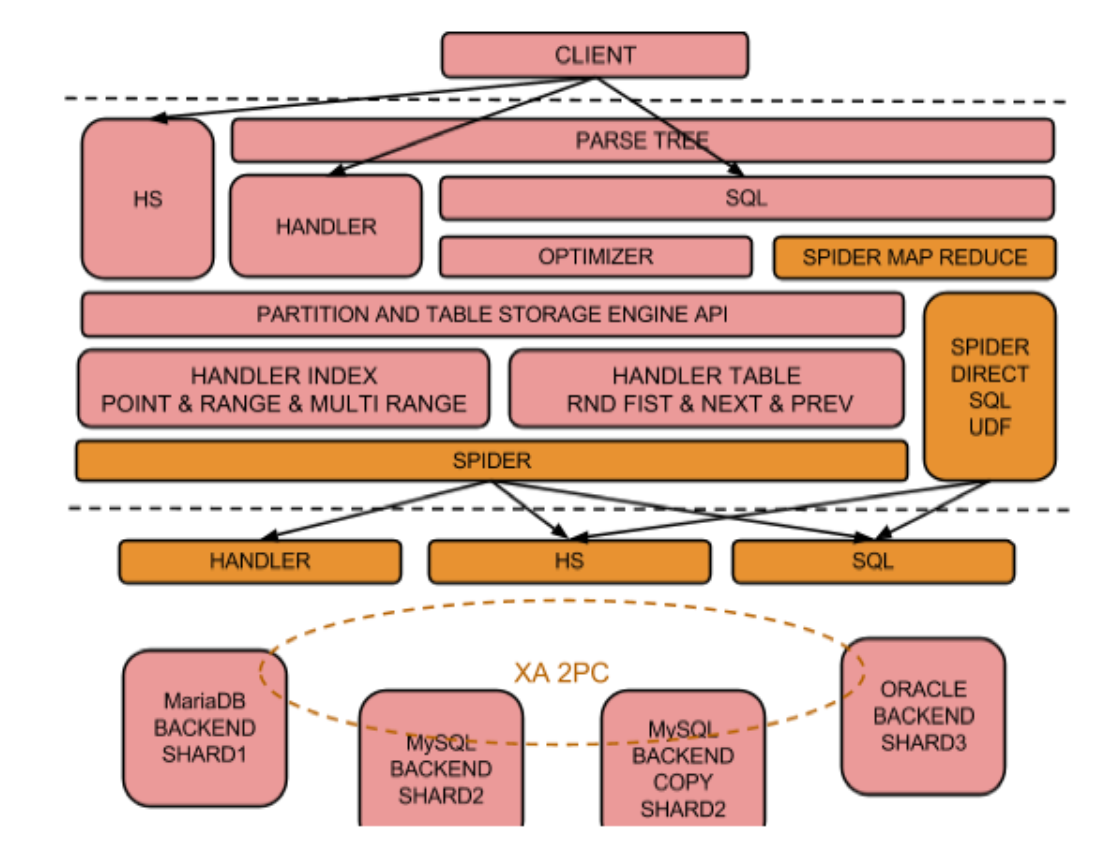
1. MariaDB에서 샤딩을 이용한 가장 정직한? 분산 저장 방법은 spider engine으로 보인다. Spider engine은 여러개의 노드로 나눠 저장한 데이터들을 하나의 노드에서 가상 테이블로 가공해 사용하는 것으로 보인다.
2. 이 때 spider 노드의 하위 노드가 반드시 하나이거나 spider engine을 사용할 필요는 없는데, 앱 A의 spider node가 앱 B의 DB를 federation-setup 혹은 one-node-sharding해서 쓰는 방법도 있다고 한다. 여러모로 view table이 생각나는데 기술적으로도 비슷한지 확인할 필요가 있어 보인다.
3. 위 아키텍처에서 흥미로웠던 부분으로
Spider를 optimizer와 DB 노드들 간의 'proxy'로 취급하는 점
분산 처리 시스템에서 확인할 수 있었던 'map reduce'가 내장되어 있다는 점
등이 있다.
Topology
1. Primary node에 spider engine과 HA proxy를 운용하는 것을 기본적인 robust한 구조로 확인할 수 있었는데 spider engine 자체에서는 복잡함을 이유로 high availability feature를 포기했다는 글도 확인할 수 있었다.
2. 너무 많은 쓰레드에 따른 급격한 퍼포먼스 감소를 여기서는 "TCP socket overflow"라고 하는데 웹 서버의 어떤 유명한 문제와 닮아 있다. MariaDB 자체적으로도 connection pool과 thread pool 튜닝을 지원하는 것 같은데, 아무래도 HA proxy에서 든든한 국밥의 향기가...

