
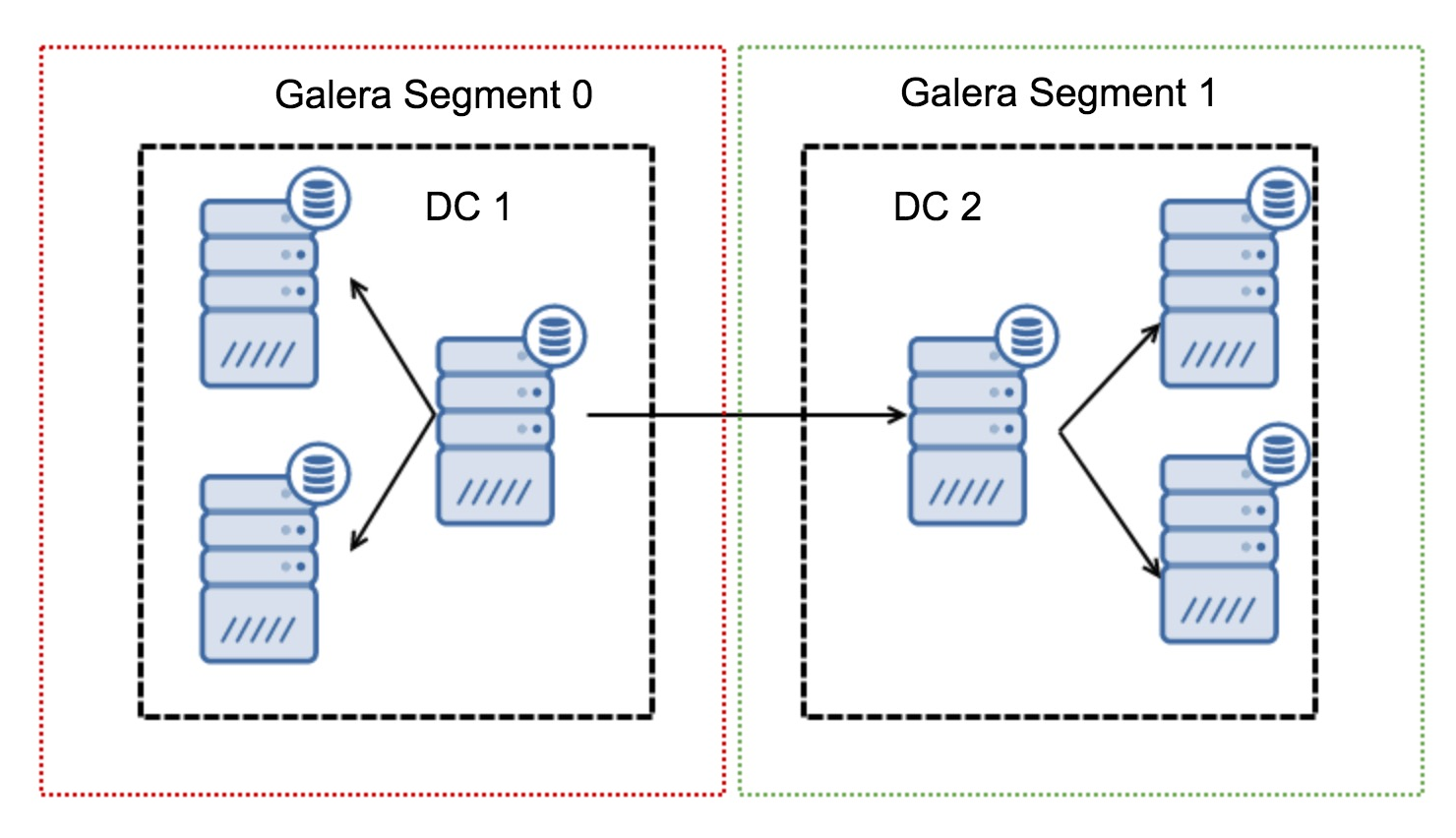
Segment
1. Cluster의 상위 집합이라고 할 수 있는 segment 내에서, 하나의 노드는 다른 모든 노드에 all to all pattern으로 문의하게 된다.
2. WAN 환경에서 하나의 segment만 운용 하더라도 master node 문제 시 차기 master를 선출하는 과정에는 문제가 없지만, 1) 대역폭에 따른 데이터 전송량의 문제 2) 노드에 문제가 생겼을 때 다른 노드에서 가용 데이터 전송량을 효율적으로 끌어오는 목적에서 segment를 분할하는 것이 좋다고 한다.
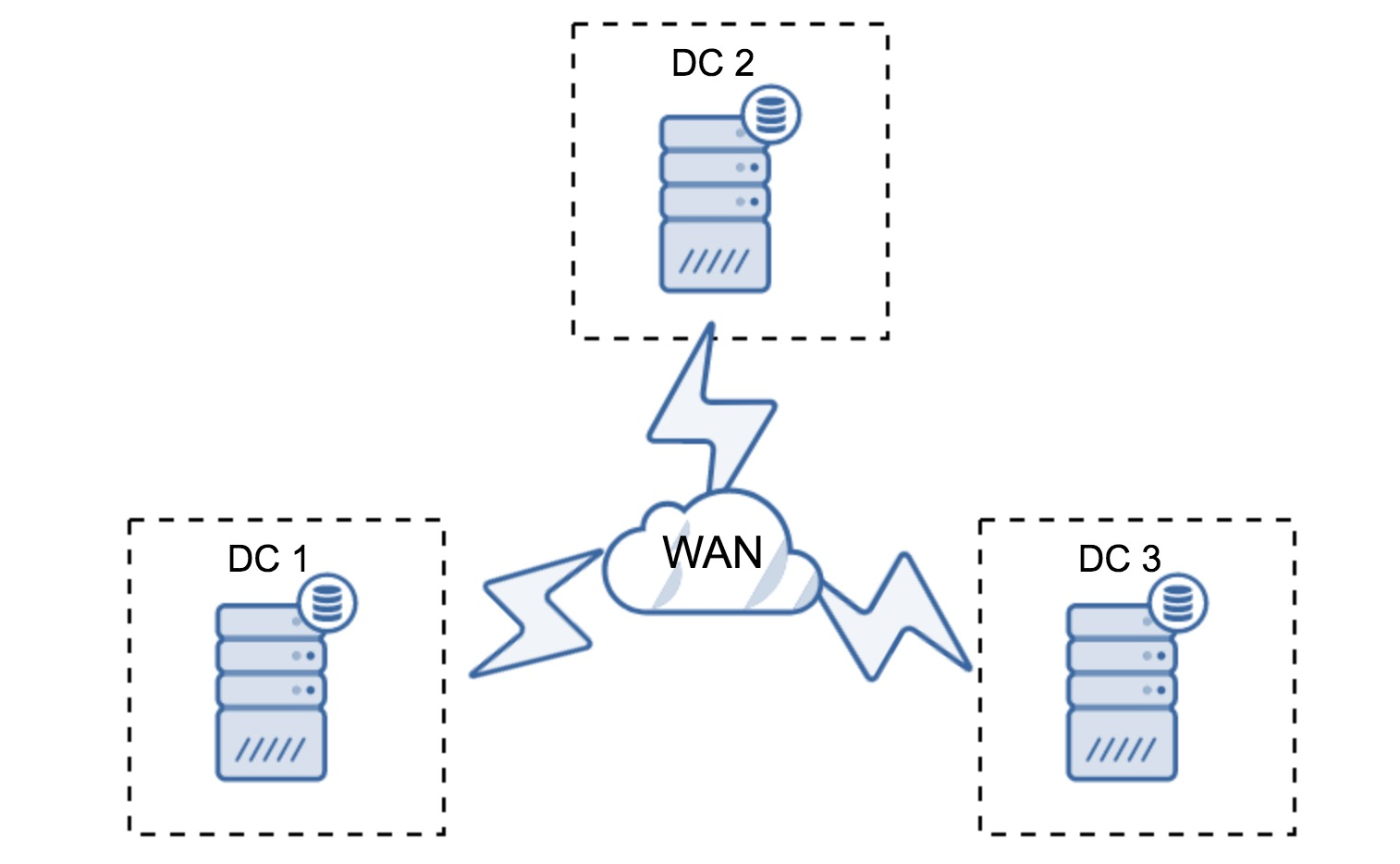
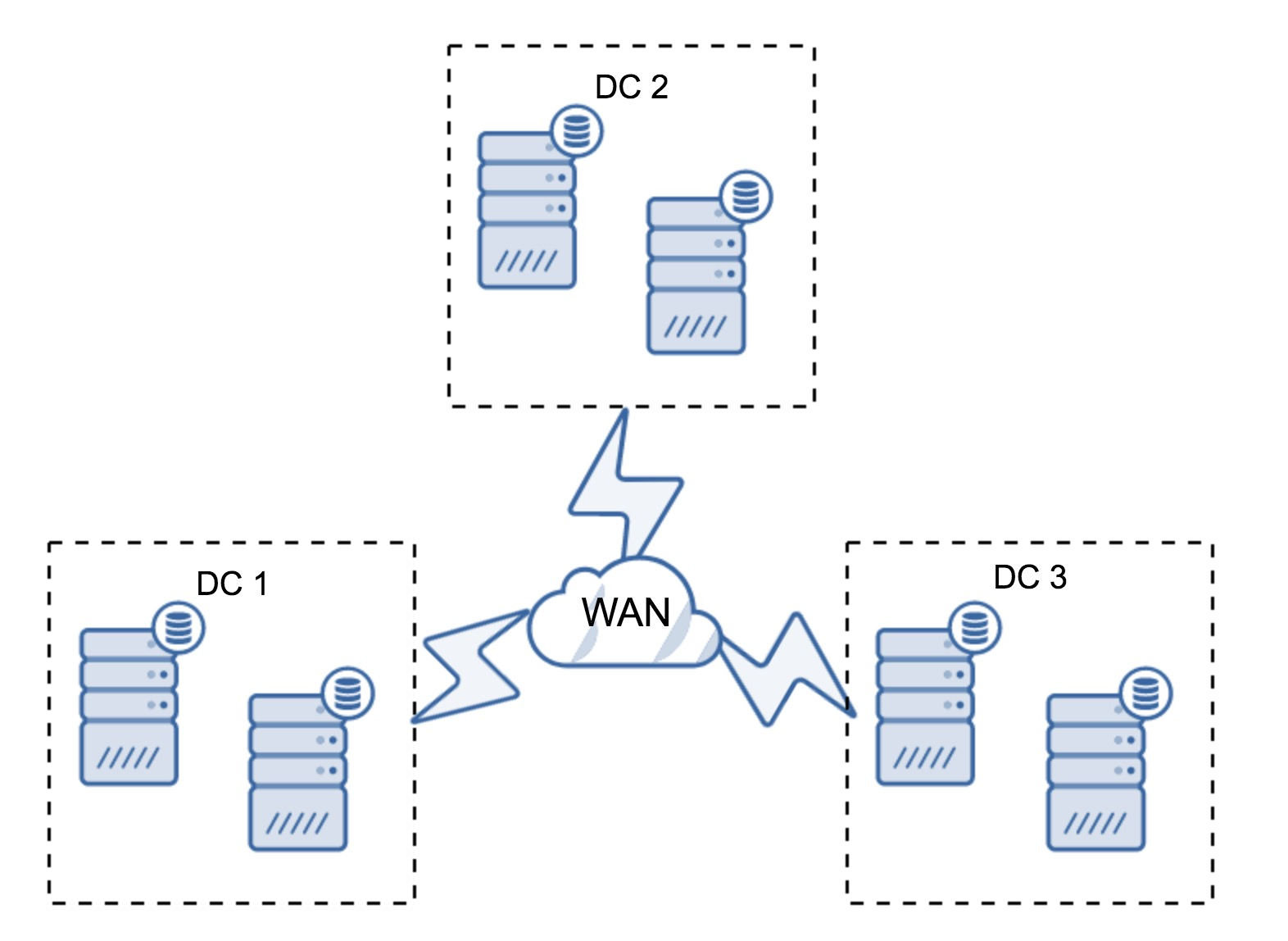
3. 일단 위 구조에서는 자동 절체를 목적으로 한다면 두 개가 넘는 DC가 필요하다는 점과 WAN으로는 (IST보다 상대적으로 dump에 가까운) SST 작업을 권장하지 않는다는 점을 기억하자.
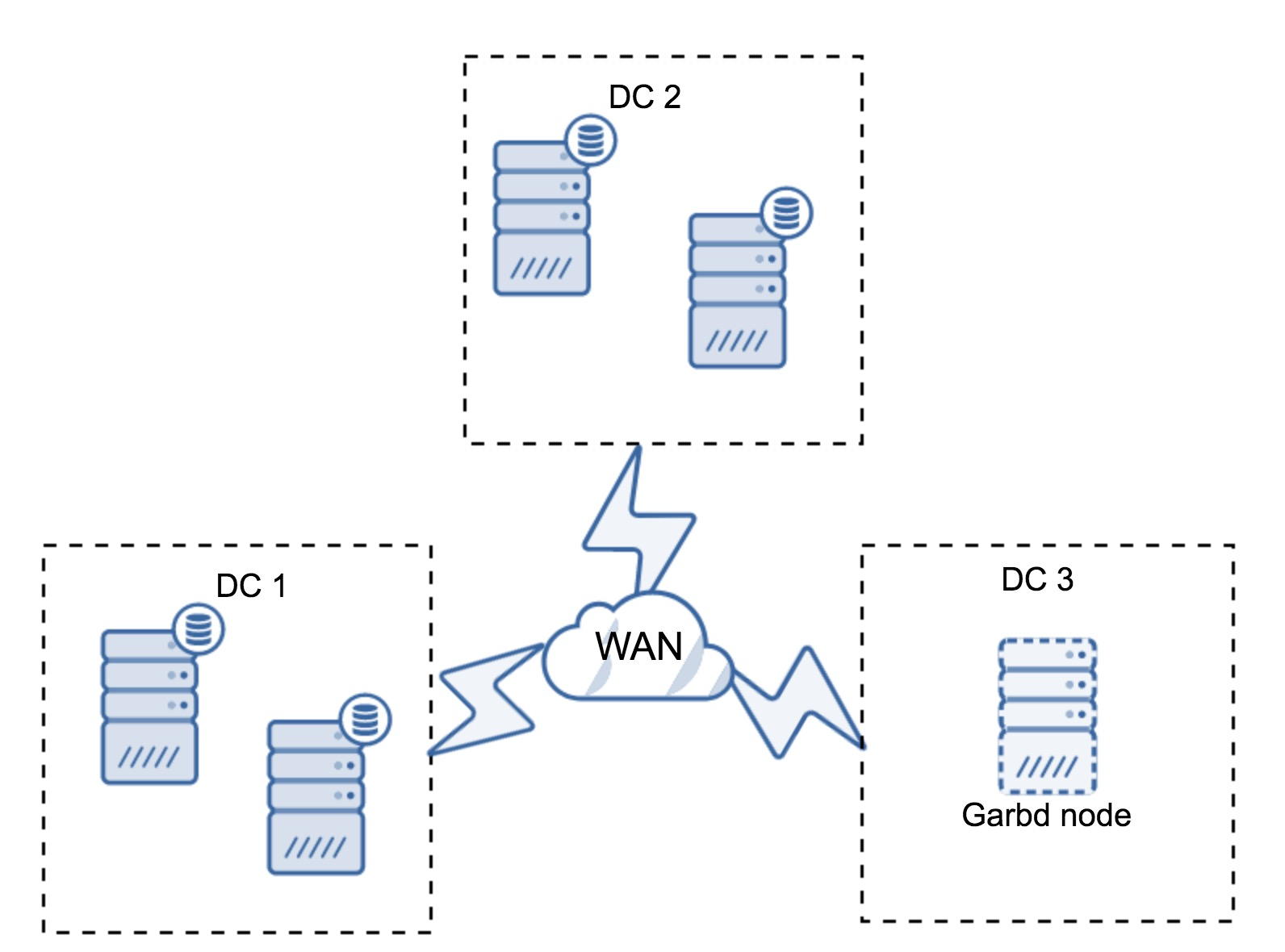
4. 결국 가장 효과적인 방법은 깍두기 역할의 Galera arbtrator(gardb)를 운용하는 것으로 보이는데, 이 자체는 노드는 아니고 백그라운드-서버-프로세스 개념의 daemon이라고 한다.

Proxy
1. DC 구성이 끝난 뒤에 앱과 cluster 사이의 연결을 블랙박스화 해주는 역할로 proxy를 도입한다.
2. proxy를 구성하는 두 방법 중에 최대 하나의 proxy만 기능하는 문제로 전자는 낭비에 가깝게 설명되고 있다.
3. 후자는 1) 효율적인 리소스 사용과 2) 하나의 proxy 문제 시 짝 server만으로의 전파 등의 장점이 있지만, unix socket을 설정해야 한다는 점에서 난이도가 높다고 한다.
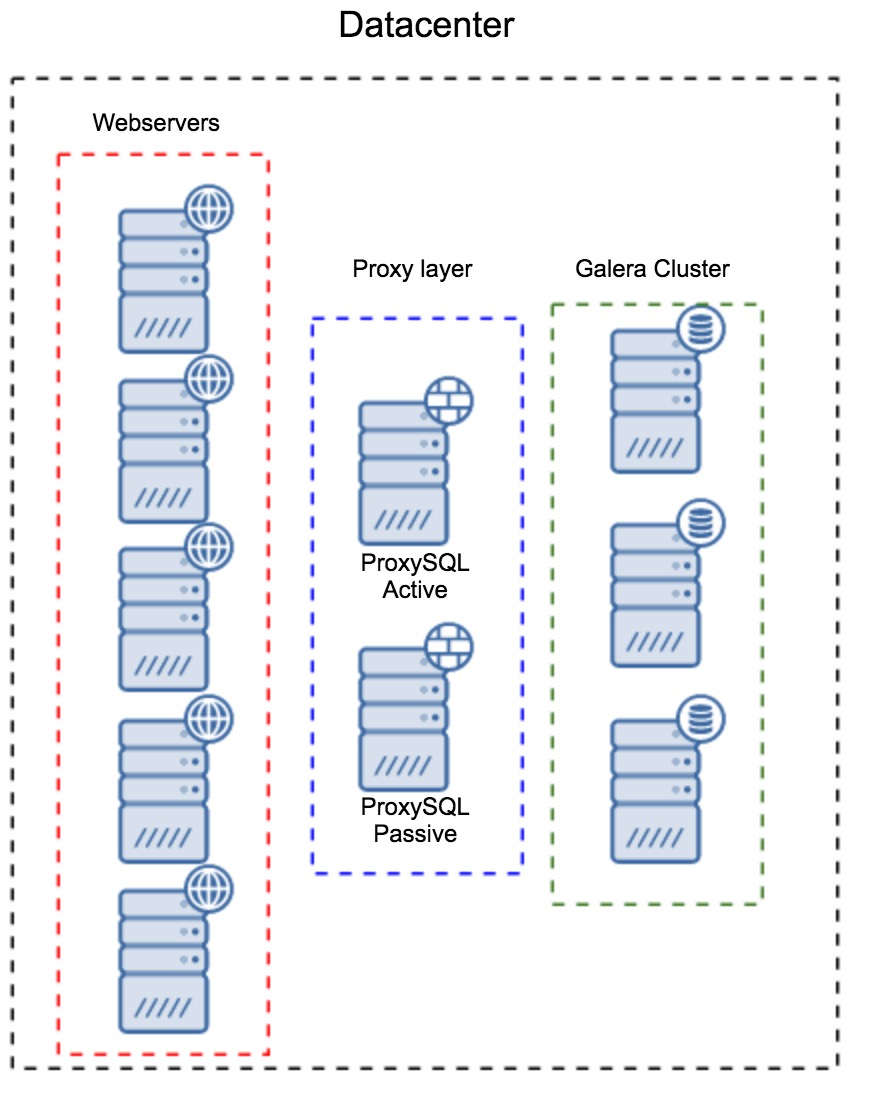
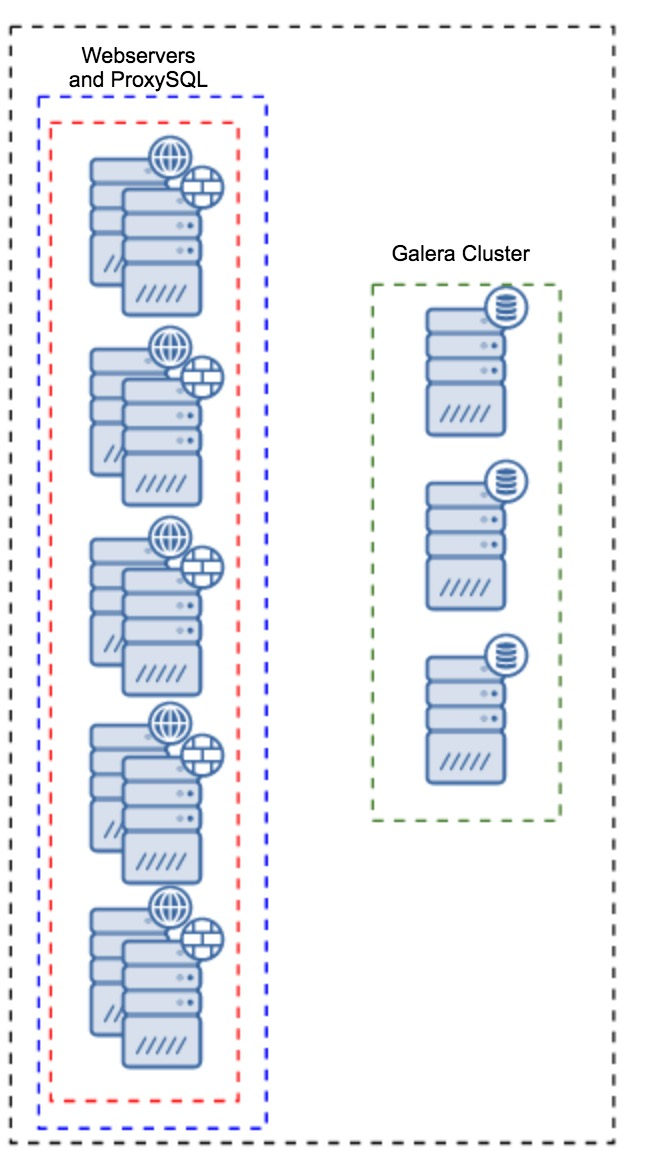
WAN replication
1. Galera cluster은 LAN을 기준으로 기본 설정을 제공해서 DC-DR를 나눠서 운영하는 등의 WAN 환경에서는 설정값 변경이 필요하다.
2. EVS는 인증-기반 복제의 핵심 개념인 group communication을 모니터링 및 제어하는 protocol이라고 한다.
- evs.suspect_timeout: 모든 노드들이 어떤 노드에 접근 불가능할 때, 의심하기 시작
- evs.inactive_timeout: 접근 불가능한 노드를 언제 퇴출할 것인가
- evs.send_window: 복제 시 얼마나 많은 패킷을 전송할 수 있을지
- evs.user_send_window: 그 중 얼마나 데이터(패킷에서 페이로드 개념으로 보임)에 할당할지
3. EVS가 조금 health check에 가깝게 이해됐다면, flow control은 복제 중에 뒤쳐지는 노드가 없도록 조절하는 feedback mechanism에 가깝게 이해됐다. gcs.fc_factor, gcs.fc_limit 등의 설정이 있으나 WAN을 사용하는 환경에서 flow control의 개입을 최소화 하라고 한다.
참고
https://severalnines.com/blog/multiple-data-center-setups-using-galera-cluster-mysql-or-mariadb/
https://severalnines.com/blog/architecting-failure-disaster-recovery-mysql-galera-cluster/
https://severalnines.com/blog/how-perform-failback-operation-mysql-replication-setup/
https://galeracluster.com/library/documentation/galera-parameters.html
