
1. 오늘의 논문
The Youtube Video Recommendation System(RecSys 2010)
RecSys란?
추천시스템(Recommendation System)을 말합니다. AI(인공지능, Artificial Inteligence) 분야 중 하나로, NLU(자연어이해), CV(컴퓨터비전), NLP(자연어처리), NLG(자연어생성)와 함께 많은 사람들의 관심을 끄는 분야입니다. 하지만 논문 출처의 RecSys는 추천시스템 학회이자 국제포럼인 ACM RecSys를 말한 것이라고 생각하면 될 것 같습니다.
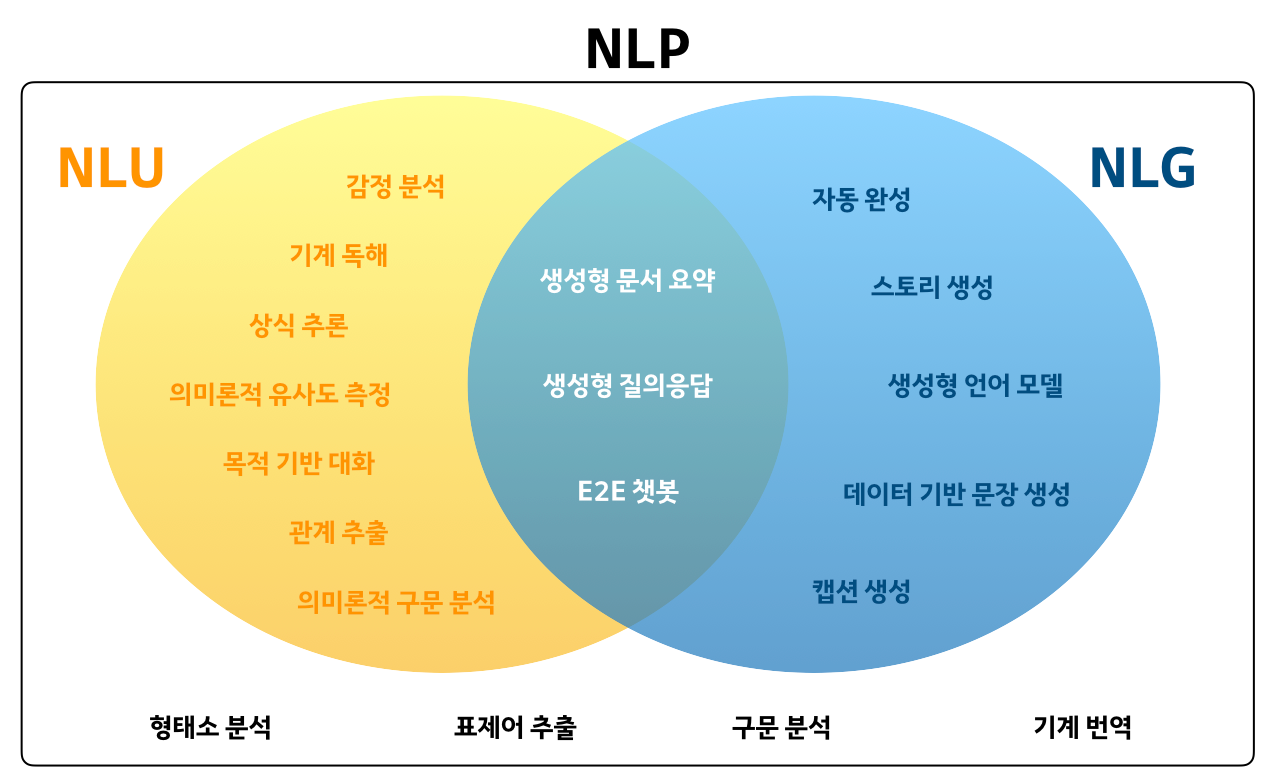
이미지 출처: https://hryang06.github.io/nlp/NLP/
이번 논문 리뷰에서 다룰 논문은 아래 3건 중 첫번째 논문입니다. RecSys 논문을 처음 보는 비전공자 시각으로 보기 때문에 가장 길이가 짧은 2010년 영어 논문 원문을 바탕으로 2016년 후속 논문, 그리고 최신 2019년 발표 내용을 참고하여 유튜브 추천 알고리즘의 기반인 Candidates Generating과 Ranking을 살펴봅니다. 정확한 이해 및 해석을 위한 논문 본문 링크는 아래에 있습니다.
- The YouTube Video Recommendation System(RecSys 2010)
- Deep Neural Networks for YouTube Recommendations(RecSys 2016)
- Recommending What Video to Watch Next: A Multitask Ranking System(RecSys, 2019)
참고로 2010 본문 중, 유튜브는 주로 홈페이지와 검색 페이지 두 곳을 통해 추천 컨텐츠를 제공한다고 합니다. 하지만 아쉽게도 현재는 논문이 작성된 이후로 10년이 지나 서비스가 개편되어 검색페이지 대신, 인기 트렌드 페이지가 랜딩됩니다. 이처럼 현재 서비스와 다소 차이가 있을 수 있지만 학문적 탐구를 위한 리뷰이기 때문에 계속 진행합니다.
*내용 중 Video 단어의 언급이 많은데 현재 기준으로 조금 어색한 느낌이라 컨텐츠(동영상)로 줄여 표현했습니다.
The YouTube Video Recommendation System(RecSys 2010)
여러분이 유튜브를 사용하는 이유는 무엇인가요? 2022년에도 구글 다음으로 가장 인기있는 웹사이트를 차지했다고 하는데요. 저는 요즘 레시피 검색과 음악 감상을 위해 주로 이용합니다. 본문에서는 아래 3가지 방법으로 사용자를 분류합니다.
- 타채널 유입을 통한 단일 컨텐츠 시청(어디에 올라간 유튜브를 보는 것)
- 특정 주제 관련 컨텐츠 조회(목적형 탐색)
- 흥미위주의 컨텐츠 시청
이 중 마지막이 추천시스템의 주요 타겟입니다. 본문의 표현에 의하면 “말로 표현할 수 없는 욕구(unarticulated want)”를 대변하는 시스템이죠.
💡 어느새 유튜브는 일상이 되어 누군가에게는 검색엔진으로서 역할도 하고 배경음악 라디오 역할도 하고 있습니다. 하지만 보통 기업들은 우리가 서비스를 본인의 의지대로만 이용하고 떠나는걸 원하지 않습니다. 최대한 서비스에 오래 머무르고, 원래 구매하려던 상품 외에 추가로, 충동적으로, 더 자주 구매하길 원하며 이따금 광고를 클릭하거나 광고를 팔기 위한 높은 트래픽을 만들어주길 원합니다. 이를 위해 컨텐츠 플랫폼 뿐만 아니라 많은 기업들이 추천시스템을 만드는 거죠. 물론 기본적으로 사용자들이 서비스를 행복하게 이용하길 바라는 마음도 있습니다🙂고객 입장에서도 내가 가려운지도 몰랐던 곳을 긁어주는 컨텐츠, 생각도 안했지만 마음에 쏙 드는 상품을 마다할 수 있을까요? 게다가 사실 선택지가 너무 방대할수록 선택이 어렵고, 어떨 때는 누가 떠먹여줬으면 하는 마음도 괜히 생기니까요. 이 선택지를 줄여주고 떠먹여주는 일을 추천 시스템이 맡고 있습니다.
1.1 Goals
유튜브는 성공적인 추천시스템을 위해 아래 5가지의 목표를 가지고 있습니다. 한정된 자원 대비 사용자도 컨텐츠도 워낙 많기 때문에 당시에는 예측 시스템 보다는 상위 N개 추천 방식을 사용했다고 합니다. (predictor<Top-N Recommender)
- 정기적 업데이트
- 사용자 최신 활동 반영
- 방대한 컨텐츠 활용
- 사용자 프라이버시 보호
- 개인화된 사용자 데이터 통제(explicit control)
1.2 Challenges
하지만 유튜브가 추천시스템을 성공적으로 운영하기 위해서는 다음과 같은 도전과제들이 있습니다.
- 사용자 컨텐츠의 메타 데이터 부족(제목, 설명, 태그 등)
- 활성사용자 수 규모의 컨텐츠 Corpus(언어학적 분석을 위해 수집된 일군의 데이터)
- 컨텐츠 길이의 제한성(10분 이내)
- 사용자 상호작용의 한계 - 짧고 난잡함(short and noisy)
- Netflix, Amazon의 구매, 대여처럼 분명하지 않음
- 컨텐츠 생애주기의 단발성(ex: 인기 급상승 동영상)
2. SYSTEM DESIGN
그러니까 유튜브 추천시스템은 1.1의 목표를 가지고 1.2의 도전과제를 격파하고 아래의 가이드를 바탕으로 디자인 된다는 겁니다. 이 중 흥미로운 점은 당시의 UI가 추천 컨텐츠 목록에 이 동영상이 추천된 이유를 명시해줬기 때문에 “사용자이해범위 내의 추천”을 가이드 대상으로 꼽았다는 점입니다. 현재는 노출되지 않으므로 최신 버전에서는 이 가이드가 생략되었을 것으로 보입니다.
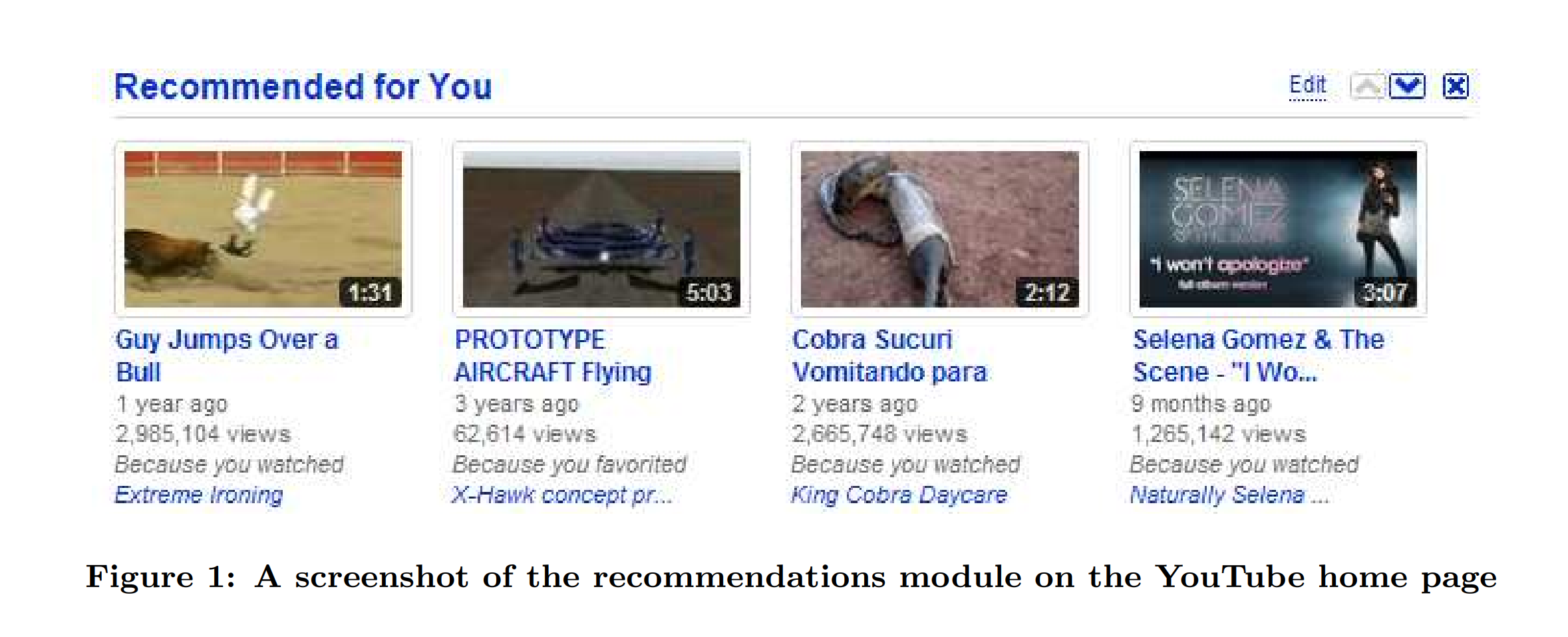
- 합리적인 최신성, 신선함
- 다양성
- 사용자 활동 기반
- 사용자이해범위 내의 추천
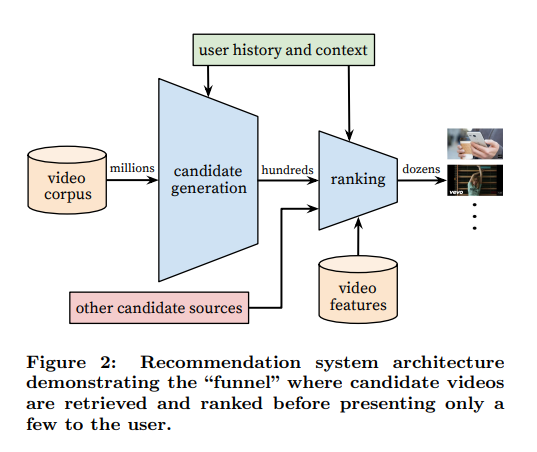
추천시스템의 기본 구조는 다음과 같습니다.
동영상을 보거나, 자주 보거나, 좋아요 등의 활동(watched, favorited, lilked videos)을 통해 사용자가 선호하는 컨텐츠 베이스(Seed)를 잡고, 이 컨텐츠와 유사한 컨텐츠 그룹(Candidates)을 찾은 뒤, 다양성과 관계도 기반으로 순위를 매겨 추천(Ranking)하는 것입니다. 여기서 favorited 기능을 현재 찾을 수 없어 위치 및 기능을 확인해 봤는데, 특별한 스크랩 기능이라기보다 자주 본 동영상 정도로 생각하면 될 것 같습니다.
물론 위 구조를 따르되, 아래의 이유에 따라 복잡도는 최소화해야합니다. 섬세하면서도 단순한, 합리적이면서도 신선하고 단순하면서도 다양한, 네 그런 추천시스템이네요.
- 실패에 대한 회복 탄력성 고려
- 독립적인 디버깅을 위해 구성요소 분리
2.1 Input Data
유튜브 추천시스템을 위해 활용되는 데이터 종류는 크게 두 가지 입니다. 협업 필터링(Collaborative Filtering)을 위한 재료로 보입니다. 관련 설명은 여기에서 볼 수 있습니다.
- 컨텐츠 데이터: 비디오 시청 기록, 비디오 메타데이터(제목, 설명 등)
- 사용자 활동 데이터(명시/암시)
- Explicit: Engagement(좋아요, 구독, 스크랩, 평가)
- Implicit: 사용자활동 결과 데이터(행동로그, 시청시작 사용자, 장시간 사용자)
각 데이터는 도전과제에서 언급했듯이 다음과 같은 한계를 가지고 있습니다. 하지만 우리의 구글러가 어떻게 문제를 푸는지 확인해봅시다.
- 메타 데이터 - 부재, 미완성, 구식, 부정확
- 사용자 활동 데이터
- 데이터 해석의 불명확성, 간접 측정만 가능(ex: 시청이 꼭 좋다는 뜻은 아님)
- 비동기적 데이터 생성, 불완전성
2.2 Related Videos
관련 컨텐츠 점수 측정
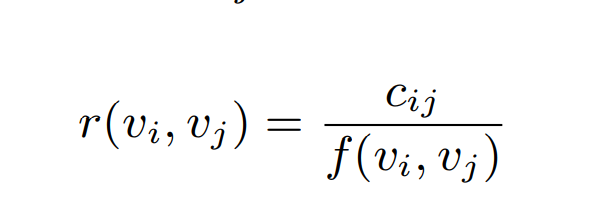
수식이 나와도 당황할 필요 없습니다. 우리의 활동 데이터를 기반으로 관련 동영상을 측정할 기반이되는 Seed가 Vi, 관련도 측정 대상이 Vj, 관련 점수가 r(Vi,Vj)입니다. 즉 내가 좋아하는 동영상 Vi를 기준으로 Vj와의 관련도를 구할 때, 관련도 점수는 Cij(=두 동영상을 동일 세션내에 시청한 횟수)를 f(Vi,Vj), 즉 ‘글로벌 인기도(global popularity)’로 나눈 값입니다.
- Cij = 연관 규칙 학습법(association rule mining) 기반, 일정 기간내에 동시 시청한 횟수(ex: 24시간)
- f(vi,vj)=글로벌인기도: 정규화(normalize)를 위해 도입, 각 비디오의 모든 세션 총 발생 횟수의 곱
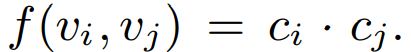
즉, 동시에 시청된 이유가 세계적으로 인기있어서라면 관련 컨텐츠 후보로는 적합하지 않기 때문에 점수를 낮게 준다는 것으로 보입니다. 예를 들어 서로 다른 2개의 인기 컨텐츠를 연속 재생으로 보는 사용자가 많다고 할때, 동시시청횟수는 높아서 두 컨텐츠의 관련도 점수가 높아질 수 있지만 글로벌 인기도로 이를 상쇄해서 관련 컨텐츠 후보에서 제외할 수 있는 것입니다.
그 외에도 일정 조회수 미만은 관련 점수가 높더라도 관련 컨텐츠 목록에서 제외하는 방식으로 품질을 관리합니다. 유튜브 추천 알고리즘에서 벗어나지 못하고 연속재생을 당하는게 점점 정상으로 보입니다. 추가로 논문에는 가장 단순화한 버전만 말하고 있기 때문에 이게 전부라고 생각하지 말라고 하네요. 실전에는 더욱 많은 난관들이 있다고 합니다.(a.k.a 도전 과제, 데이터 한계 등)

2.3 Generating Recommendation Candidates
사용자 활동 및 관계성 점수에 기반한 관련 추천 컨텐츠 세트 C1, Candidates라서 C입니다. S는 내가 좋아하는 컨텐츠 세트 Seeds의 약자라고 보면 됩니다.
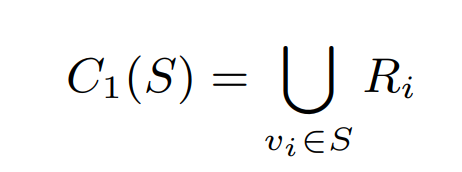
컨텐츠 후보는 관련점수가 높은 컨텐츠 세트 상위 N개의 집합으로 대부분 충분히 방대하고 다양한 추천을 해주지만, 일부 유사하기만 한 비디오를 추천하는 경우가 있다고 합니다.(narrow recommendation) 예를 들자면 똑같은 예능 방송 1화의 앞부분을 길이가 다르게 자른 컨텐츠들로 연상이 되네요. 유튜브는 이를 막기 위해 작은 양의 S로도 방대한 추천을 받을 수 있도록 추천 거리 N을 조절해서 final 값을 구합니다.
관련 컨텐츠는 높은 분기계수(high branching factor)를 갖고 있어 작은 Seed 사용자에게도 확장된 추천이 가능합니다. 유튜브는 순위 생성 목적 뿐만 아니라 추천 관련 설명을(2.SYSTEM DESIGN 참고) 위해 이런 케이스를 관리합니다.

A red–black tree with branching factor 2(출처: wikipedia)
2.4 Ranking
관련 컨텐츠 후보가 생성된 후에는 순위 생성을 통해 추천시스템을 고도화합니다. 아래 3가지 요소를 중점으로 보는데 특히, 다양성 측면에서 여러모로 공을 들이는 인상을 받았습니다. 사실 재미로 유튜브를 보는 사용자 입장에서는 아무리 관련 있고 인기 있다해도 동일한 컨텐츠를 보는 것보다 새로운 컨텐츠를 보는게 중요하긴 하니까요.(이런 신선함에 대한 중요도는 2016, 2019 논문에서도 강조됩니다)
1) video quality: 비디오 간의 유사성(조회수, 평점, 댓글, 좋아요, 공유, 업로드 시간 등)
2) user specificity: 사용자 취향 적합성(시청 길이, 조회수, 시청 기록 등)
3) diversification: 4~60개의 추천 세트 중, 카테고리 간 연관성과 다양성 최적화
- 유사도가 높은 컨텐츠 제외
- Seed video 당 추천 컨텐츠 수 제한
- 동일 채널 컨텐츠 수의 제한
- 그 외 topic clustering, content analysis 등
2.5 User Interface
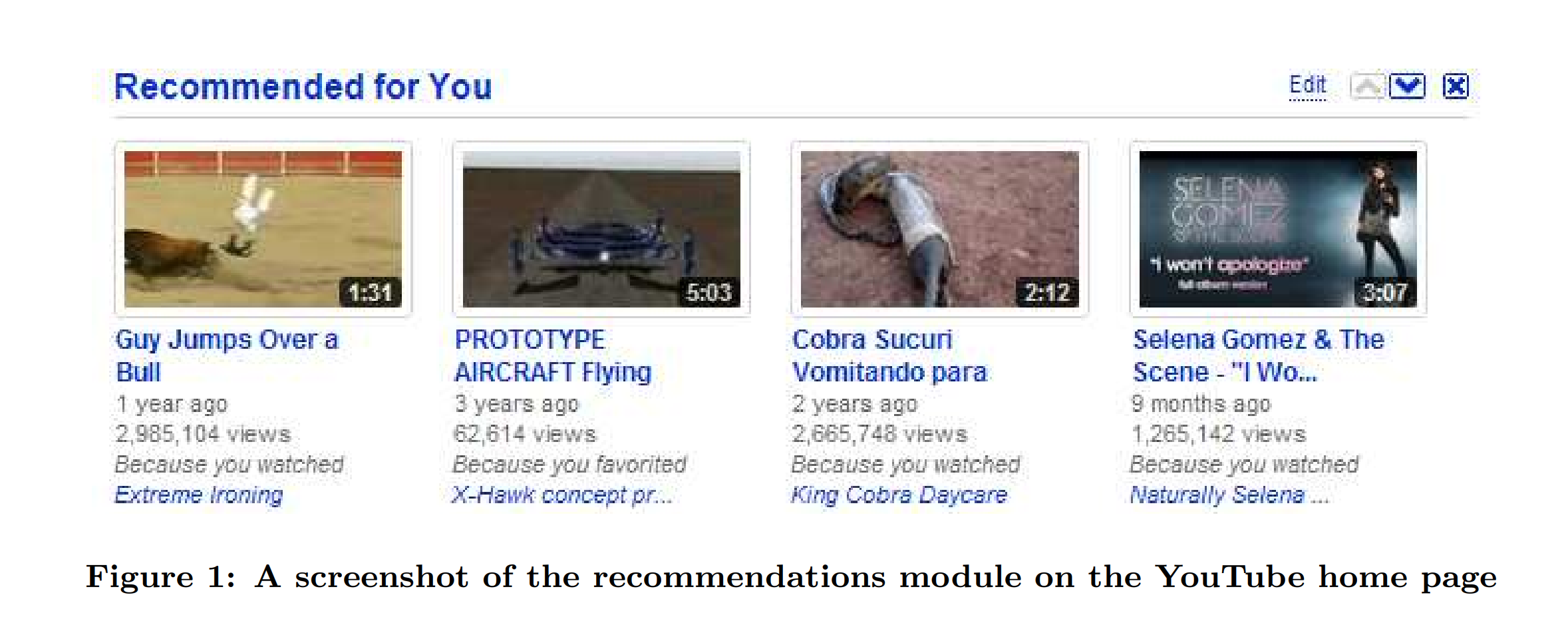
유튜브 프리미엄 구독자로서 위 이미지에서 보이는 현재와의 차이점은 이 정도 같습니다.
- 추천 사유 제공(Becaues you watched, favorited)
- 추천 리스트 조절 가능
- 정확한 조회수(현재: 1만 이상 trunc)
유튜브는 추천 시스템을 통해 기존에 마련된 세트 중 일부만 사용자 활동시간(Serving time)에 제한적으로 노출함으로서 최신성과 다양성을 반영(신규, 미시청 컨텐츠 등) 합니다. 2022 최신 버전 UI에서는 다양한 카테고리로 관련 컨텐츠를 제공하는 점도 흥미롭습니다.(모두, 관련 콘텐츠, [해당 채널] 제공, 실시간, 최근에 업로드된 동영상, 감상한 동영상)
2.6 System Implementation
당시에는 특히, 실시간 계산 추천 보다 배치 기반의 사전 처리를 선호했다고 합니다. CPU 자원을 최소로 사용하면서, 지연 없이 미리 배치된 추천 목록을 제공할 수 있고 추천 시스템이 최대한 많은 데이터를 사용할 수 있게하기 위함이죠. 추천 시스템의 작동과 제공 사이의 간극을 좁히는게 중요한 부분이라 1일 배치 빈도를 높이는 파이프라인 방법으로 그 간극을 완화했습니다.
추천시스템은 아래 3단계로 수행되는데 시각화를 위해 2016년 논문에서 사용된 이미지를 가져왔습니다. 기본적으로 후보 생성과 순위 측정 2단계는 동일하게 작용했다고 보시면 됩니다.
- 데이터 수집(data collection)
- 추천 시스템 가동(recommendation generation)
- 추천 컨텐츠 제공(recommendation serving)
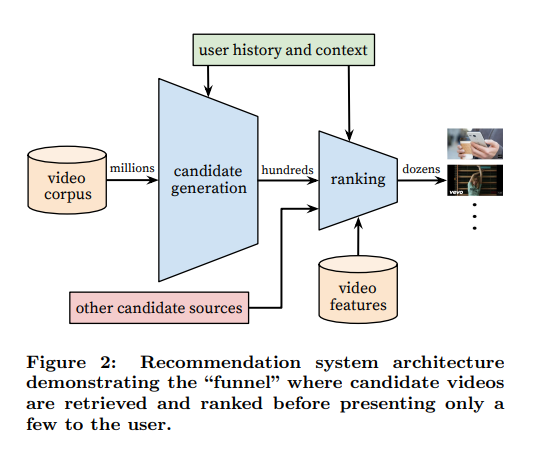
2p, <Deep Neural Networks for YouTube Recommendations(RecSys, 2016)>
데이터 수집 단계에서 RAW는 로그에서 전처리 되어 사용자 기반으로 Bigtable에 적재됩니다. MapReduce 방식을 통해 점수가 계산되고 적재되는데 결과물인 데이터는 상대적으로 크기가 작아서 단순화된 읽기 전용 Bigtable 서버와 유튜브 웹서버를 통해 제공될 수 있다고 합니다. MapReduce에서 Map이란 Input Data가 분산 파일 시스템에서 분할된 이후, 이를 병렬적으로 나눠서 분석을 수행하는 함수이고, Reduce는 처리된 데이터를 합쳐 새로운 작은 데이터셋으로 만드는 것입니다. 참고로 한 설명은 여기 입니다.
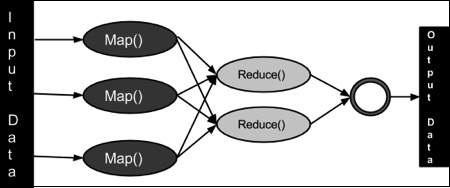
https://www.tutorialspoint.com/hadoop/hadoop_mapreduce.htm
3. Evaluation
이렇게 잘 만들어진 추천시스템은 주로 실시간 A/B 테스트를 통해 검증됩니다. 유튜브에서 말하는 A/B테스트를 통한 검증의 장단점은 다음과 같습니다.
장점
- 실제 웹사이트UI를 통해 평가가 실시됨
- 동시다발적 실험이 가능, 모든 경우에 해당하는 가장 빠른 피드백 습득.
단점
- 모든 경우에 비교를 위한 합리적인 통제가 어려움
- 통계적으로 의미있는 결과를 위해 충분한 트래픽이 필요함
- 사전에 정의된 소규모 Metrics 세트의 해석으로 제한됨.
아래는 주요 평가 지표입니다. 이 지표들을 토대로 추천 시스템 성능을 지속적으로 추적하고, 실시간 트래픽에 따른 시스템의 변화를 평가한다고 합니다. 당연할 수도 있지만 단순 CTR 뿐만 아니라 Long CTR을 함께 추적한다는 점이 흥미로웠습니다.
- CTR(노출대비 클릭률, Click Through Rate)
- 긴 CTR(컨텐츠 주요 부분을 시청하는 클릭만 포함)
- 세션 길이
- 첫 장기 시청까지 걸린 시간
- 추천 포함 범위(추천을 받은 로그인 사용자 비율)
4. RESULTS
결과적으로 우리도 잘 알고 있듯이, 유튜브의 추천시스템은 아주 효과적이었습니다. 수치적으로 보자면 홈페이지의 추천 컨텐츠 클릭이 전체의 60%를 차지할 정도로 성공적이라고 합니다.
왜 이게 알고리즘에 뜨지? 하다가 구독하게 되는 경험을 많은 분들이 가져보셨을 것 같습니다. 저 같은 경우에는 아래 2가지 추천 컨텐츠 경험이 인상적이었습니다.
ex1: from 수빙수- to 승우아빠(요리 컨텐츠 콜라보한 채널, 지식+코믹)

ex2: from 발명 쓰레기걸- to 긱블(굿즈제작 컨텐츠 콜라보한 채널, 발명+코믹)
사실 추천 컨텐츠는 당시 다른 컨텐츠 보다 홈페이지에서 디폴트로 최상위에 위치하기 때문에 어느정도 편향된 결과(presentation bias)라고 할 수 있습니다. 그래서 논문에서는 이 편향을 피하기 위해, 3주(21일) 동안 검색페이지(browse)에서 결과를 측정했다고 합니다. 추천 컨텐츠 외에 아래 3가지 모듈의 평균 CTR을 비교한 결과입니다.
1) 1일 최다 조회수 컨텐츠
2) Favorited 목록에 가장 많이 기록된 컨텐츠
3) 1일 최다 좋아요 컨텐츠
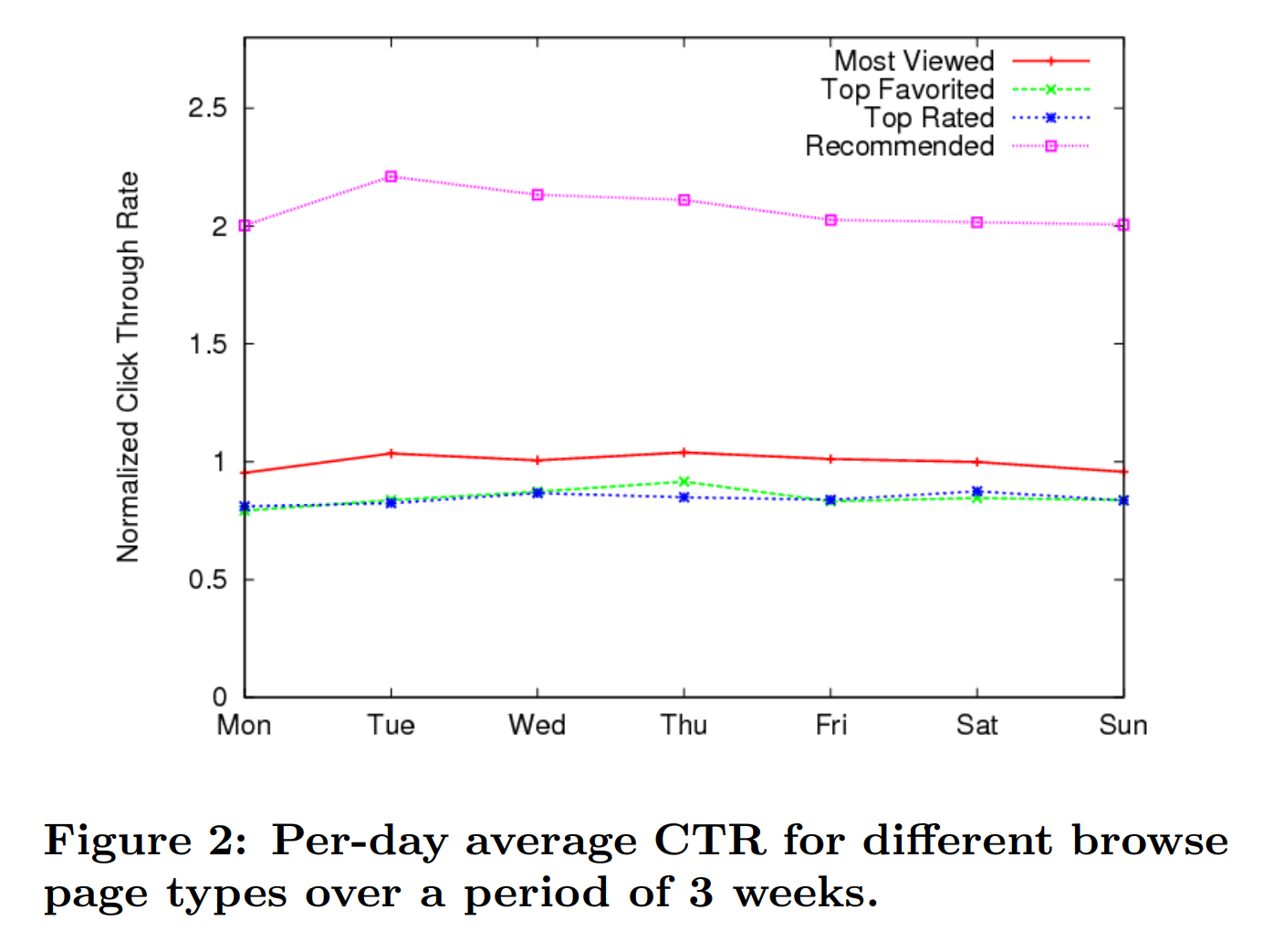
3개 모듈 중, 가장 높은 1일 최다 조회수를 기준으로 207% 상회하는 성능을 보여주는 것을 알 수 있습니다. 전체 기간동안 평균은 기본으로 넘고 다른 기준 보다 훨씬 높은 비율을 보이네요. 브라보 유튜브! 2010년 논문은 정확하거나 상세하기 보다 주로 기본 구조에 대한 내용을 다루고 있어 아쉽지만 이해는 어렵지 않았습니다. 다만 후보자 선정 뿐만 아니라 랭킹도 핵심인데 가중치 숫자 힌트 하나 보지 못해 아쉬울 따름입니다.
2. 관련 논문

긴 흐름에 지쳐있지만 후속 논문을 조금도 보지 않을 수는 없습니다.(봐야합니다) 빠른 이해를 위해 블로그 자료를 참고했으며 흥미로웠던 부분 위주로 리뷰합니다.
Deep Neural Networks for YouTube Recommendations(RecSys 2016)
Candidate Generation, Ranking이라는 추천 시스템의 기본 구조는 동일하지만 2016년에는 딥러닝을 통해 정확도(high-precision)를 고도화합니다. 주로 test를 위한 feature engineering을 심도있게 다뤘다고 합니다. 상세하고 친절한 내용은 여기를 통해 확인하실 수 있습니다.
2. SYSTEM OVERVIEW
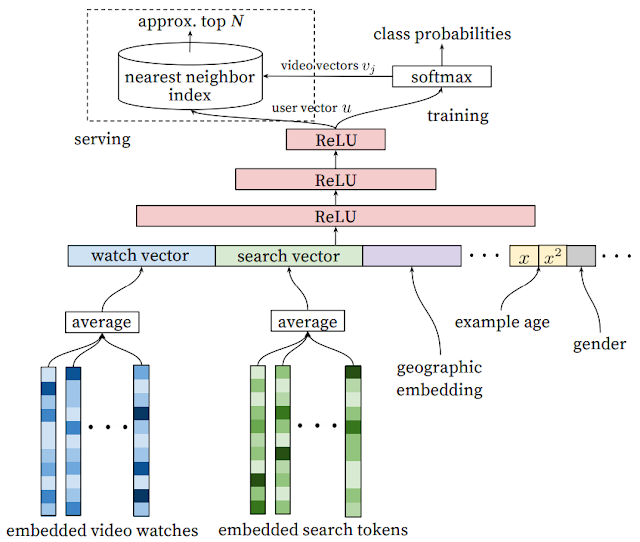
그 중, 재미있는 점은 새로운 컨텐츠를 추천하기 위해 검색어 기록과 시청 기록 vector을 평균화해서 얼버무린다는 부분이었습니다. 고도화를 위한 다운그레이드 느낌이라 신선했습니다. 여기서 watch vector, search vector가 얼마 없는 사용자의 경우 geographic, demographic vector가 유용하게 쓰인다는 점도 흥미로웠습니다.
3.3 Heterogeneous Signals
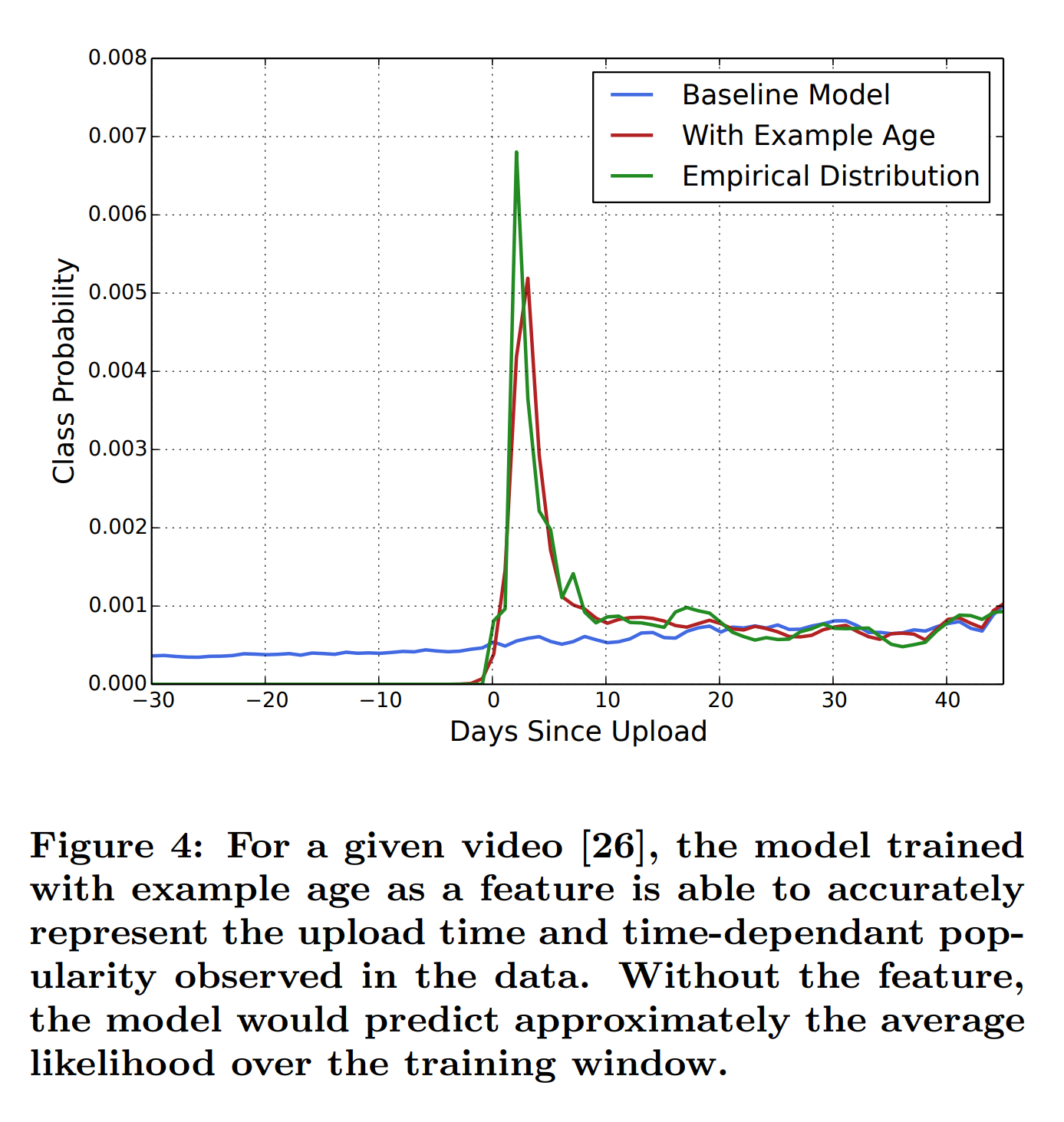
많은 사용자들이 새로운 컨텐츠를 선호하지만 머신러닝은 기본적으로 과거의 데이터를 기반으로 학습 하는 구조이기 때문에, 과거 컨텐츠 위주로 편향되는 경향이 있습니다. 특히 급상승 인기 컨텐츠(viral contents)의 경우 시청기록이 매우 비정상적(highly non-stationary)임에도 추천시스템은 평균적인 시청 가능성을 반영하기 때문에 문제가 있습니다. 유튜브는 이를 보완하기위해 모델 test에 해당 컨텐츠의 시청기록이 얼마나 오래되었는지 반영하는 Age facor를 도입합니다. 업로드 당시는 0 또는 음수를 기본으로 점점 나이를 먹이는 건데, 이를 통해 모델은 기본 예측(파란 선) 보다 실제 결과(초록 선)에 좀 더 가깝게 예측할 수 있게 됩니다(빨간 선)
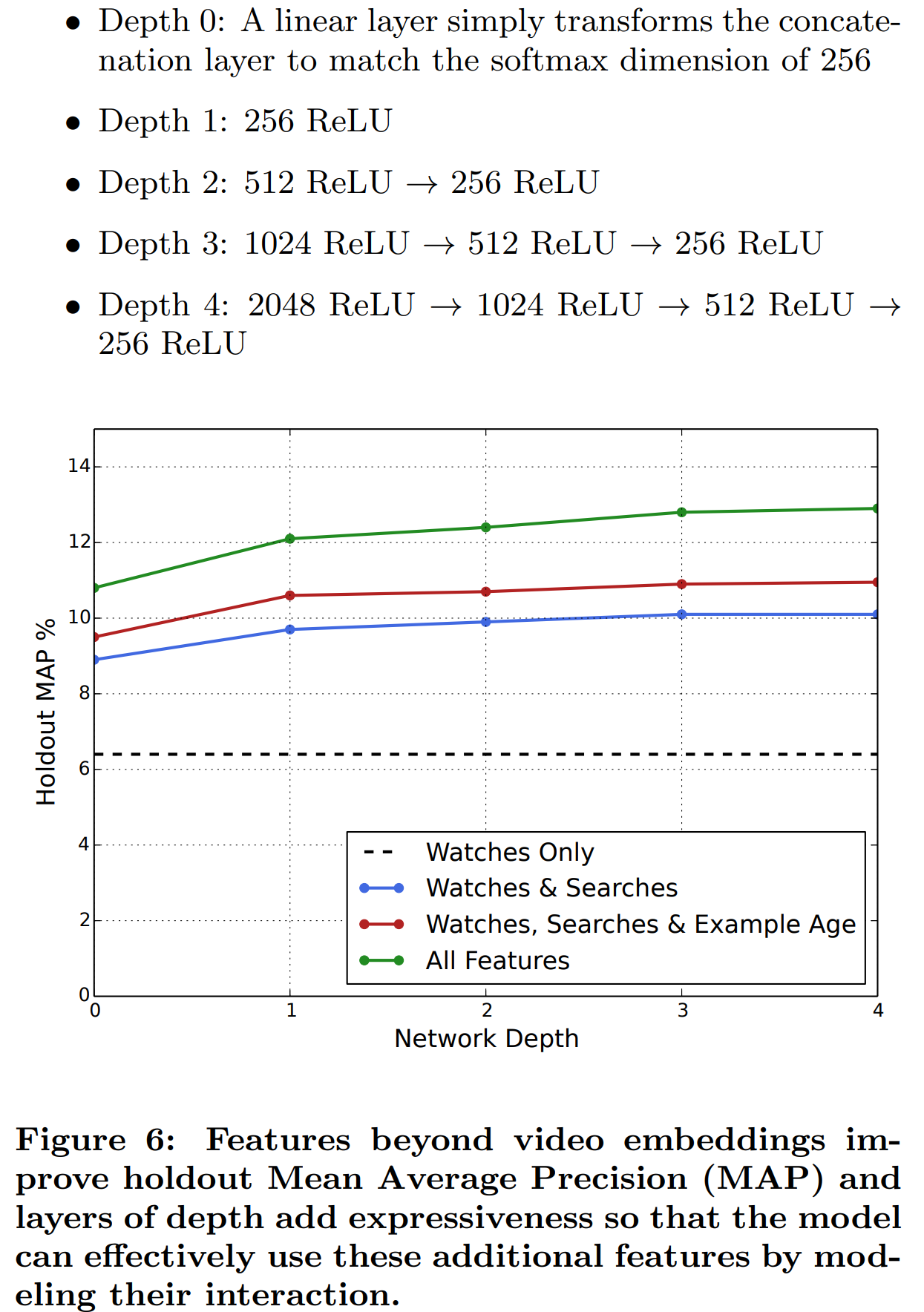
3.5 Experiments with Features and Depth
머신러닝을 위한 watch label은 과적합(overfitting)을 피하기 위해, 타채널 유입(Embeded Videos)을 포함하여 모든 기록을 사용합니다. 사용량이 많은 일부 사용자에게 편향되는걸 피하기 위해 동일량(ex: 최대 50개)의 시청 기록을 랜덤으로 샘플링한다는 점이 인상적이었습니다. 편향을 막는 방법이 더욱 효과적이라서 그랬겠지만 뭔가 정의로운 느낌입니다.
네트워크는 일반적인 타워 패턴이라 아래로 갈 수록 차원이 2배가 되는 구조를 가지고 있다고 합니다. 오는게 있어야 가는게 있다. 윗물이 맑아야 아랫물이 맑다 처럼 역시 Input Data도 많고 층 개수도 많을 때 성능이 잘 나옵니다.
Recommending What Video to Watch Next: A Multitask Ranking System(RecSys, 2019)
마지막 2019 발표도 간략히 살펴보자면 주로 2010년 버전에서부터 계속 유튜브가 마주해야했던 도전과제, 난관들을 말해주고 있습니다. 일반적인 추천 시스템으로서 가질 수 있는 문제와 유튜브가 가진 특유의 문제들이 공존하고 있습니다.
-
사용자 선호 기준의 모호함
: Like 하고 싶은 컨텐츠, 공유하고 싶은 컨텐츠, 자주 보고 싶어하는 컨텐츠가 다를 수 있다.
참여(engagment)와 만족(satisfaction) 두 가지 목표로 분류하여 기계학습 진행
(참여: 클릭, 시청시간 / 만족: 좋아요, 관심없음, 댓글 등)-
상위 노출에 따른 편향
: 상위에 추천된 컨텐츠를 사용자들이 계속 클릭하여 인기를 지속적으로 얻고 계속 상위노출 되는 피드백 루프가 생길 수 있다. the w
inners take it all
편향이 컨텐츠의 인기도에 미치는 영향을 계산하여 예측에 반영, 차감
그 외에도 유튜브는 서비스 내 데이터의 다양성(메타 정보, 사용자 활동 정보, 그래픽 정보 등)과 데이터 자체의 어마어마한 양 때문에 난관을 겪고 있습니다. 2010년 논문에서 주로 다뤘던 후보 생성과 랭킹 2단계 추천시스템은 유튜브의 특성상 가지는 난관 중 확장성(scalability)을 해결하기 위한 방안이었습니다.
흔히 온라인 플랫폼 서비스는 일반적으로 기업이 제품을 생산할 때 생기는 한계비용이 낮아 좋다고 하는데, 유튜브쯤의 규모가 되면 그렇지도 않네요. 데이터는 단순할 수록 예측 가능성이 높아진다고 하는데, 이런 점에서 유튜브의 다양한 데이터는 스스로가 해결해야하는 큰 숙제라고할 수 있습니다.
3. 마무리

첫번째 논문 리뷰를 마무리하려합니다. 사실 논문 리뷰는 학습의 시작이기도 하지만 데이터 분석/엔지니어링 실전 연습의 영감을 얻기 위한 공부이기도 합니다. 이를 위해 생각을 확장해보겠습니다. 이름하여 ‘컨텐츠 플랫폼의 추천시스템에서 배운점을 제품 판매 시장에 도입한다면?‘입니다. 두 상황의 차이점이나 유사한점을 살펴보겠습니다.
1) 사용자 선호의 모호함
유튜브는 사용자 선호의 모호함을 해결하기 위해, 만족과 참여 두 가지 목표를 기준으로 추천시스템을 만든다고 합니다. 여러분은 공유, 좋아요, 구독, 자주 재생하는 컨텐츠 별로 각각 차이가 있으신가요? 아래는 제 경험에서 분류해본 목적별 선호 영상컨텐츠 종류입니다.
- 공유: 단발성 코믹 컨텐츠, 지식 컨텐츠
- 좋아요: 감동, 귀여움, 따뜻한 컨텐츠, 음악 플레이 리스트, wow 컨텐츠(감탄이 나오는)
- 구독: 채널 자체가 마음에 드는 경우, 자주 보는 컨텐츠가 많은 경우
- 자주 보는: 음악 플레이 리스트, 레시피
하지만 이 모든 범위에 포함되지 않으면서도 무심코 클릭한 컨텐츠, 오랜 시간 멍 때리며 본 쇼츠들이 있을 것입니다. 즉, ‘만족’ 활동으로 추천받은 리스트들과, ‘참여’활동으로 추천받은 리스트의 간격이 어느 정도 있는 것이죠.
한편 일반적으로 제품을 판매하는 시장의 경우 어떻게 분류해볼 수 있을까요?
- 공유: 함께 사고 싶은, 추천하고 싶은, 선물하고 싶은
- 좋아요: 다음에 사고 싶은 (wish list)
- 구독: 신제품이 궁금한 브랜드, 할인혜택이 필요한 브랜드
- 자주 사는: 생필품
제품 판매 사이트 역시 위의 활동으로 만족을 표현하지 않았음에도 무심코 클릭하게된 상품이 있었을 것입니다. 제일 곤혹스러운건 무심코 클릭한 이 상품이 활동로그로 인식되어 다른 채널의 추천 광고에 연속해서 떴을 때 입니다. 요즘 제품 추천은 유튜브 연속재생 만큼 부드럽게 원클릭 한번으로 소개되기 때문에 큰 불편함을 느끼진 못한 것 같습니다. 유튜브가 시스템 디자인 가이드에서 심혈을 기울인 만큼 UI 역시 중요한 부분임을 알 수 있습니다.
쿠팡
네이버
2) 컨텐츠 추천과 상품 추천의 간극
한정적 구매 범위
동종업을 제외하고 유튜브처럼 사용자가 하루에도 몇 십개씩 소비할 수 있는 제품이 있을까요? 보통 제품을 판매하는 경우 하루에 사용자가 같은 규모로 제품을 반복 구매하지 않습니다. 따라서 한 번 살때는 최소한의 시간과 노력으로 편하게 살 수 있도록 설계해야하고, 명시적 데이터에 기반한 제품을 주로 추천하게 됩니다. 살 가능성이 낮은 제품을 추천해서 이탈하게하기 보다는 기존에 구매 경험이 있고 다시 구매할만한 제품을 추천하는게 합리적입니다. 그러다보니 아무래도 컨텐츠 플랫폼 보다는 추천을 한정적으로 할 수밖에 없습니다. 사용자의 선호 보다 밀어주는 제품(광고)이 많을 수도 있습니다.
구매주기
만약 제품 구매주기가 일주일, 한 달, 삼 개월, 육 개월을 넘어간다면 어떨까요? 예를 들어 떡볶이 밀키트, 기차 티켓, 옷, 비행기 티켓를 각 주기 별로 배치해봤을 때 추천시스템을 도입하면 일부 조금 어색한 경우가 생길 것 같습니다. 오늘 태국행 비행기 티켓을 구매한 사용자에게 내일 ‘태국행 비행기 티켓 구매자’가 많이 구매한 000행 티켓을 추천한다해도 구매로 이어질까요? 태국과 가장 유사한 속성을 가진 000행 티켓을 추천하는 건 어떨까요? 어느 쪽이든 사용자의 구매주기를 맞추지 않는 다면 추천이 효과적이기 어려울 것입니다. 게다가 대부분 비행기 티켓은 최저가를 선호하기 때문에 한 채널에서만 구매를 지속적으로 하지 않는다고 가정했을 때 추천시스템에 사용할만한 대량의 명시적 데이터를 수집하는 것도 어려울 수 있습니다. 유튜브에서 000영화 예고편을 봤다고 넷플릭스가 바로 000영화를 추천할 수 없듯이 채널간 데이터 상호공유가 안되기 때문에 더욱이 구매주기는 정확해지기 어려울 수 있습니다. 이 관점에서 추천은 구매 데이터가 많은 사용자에게 더욱 고도화 될 수밖에 없습니다. 편향을 주의해야겠지만요.
구매목적
위의 예시에서 떡볶이 밀키트, 옷의 경우 이 제품을 구매한 사람들이 자주 구매하는 제품, 이 제품의 속성에 따른 제품을 추천해도 크게 무리가 없어 보입니다. 유튜브 컨텐츠와 마찬가지로 신선함과 다양성이 어느정도 효과를 발휘할 수 있는 분야이기 때문입니다. 하지만 기차 티켓이나 비행기 티켓의 경우 사용자의 구매 목적(출장, 정기방문, 여행)에 따라 일시성과 반복구매 가능성이 좌우될 뿐만 아니라, 출발지와 도착지를 확정적으로 추천하기 조차 어려워 보입니다. 그렇다고 목적을 매번 사용자가 정확하게 기입하거나 설문조사를 제출해주진 않으므로 확보한 사용자 로그 데이터를 기반으로 구매유형별 목적을 가정하는 과정이 필요할 것입니다.
3) 실전 연습에 대한 아이디어
하나
논문의 기초 공식을 일반 제품군에 그대로 도입한다면 어떨까요? 두 제품의 한 세션내 동시 조회수를 각 제품 페이지 조회수의 곱으로 나눈 관련도 점수를 기반으로 제품을 그룹화하고 어떤 후보군이 나올지 보는 것도 재미있을것 같습니다. 물론 앞서 생각해본 차이점 처럼, 제품의 유형이나 구매주기 등에 따라 관련점수와 다양성과 신선함 지수는 밸런스 조절이 필요할 것 같네요.
구매가 아주 많은 사용자의 기록 위주로 관련도 점수가 편향되지 않도록 로그기록을 동일한 규모로 취합하는 가이드도 필요합니다. 공동 구매나 특가 구매로(go viral) 인기있는 제품이 모든 제품의 관련 제품이 되지 않도록 normalize 하는 방식을 좀 더 다양하게 생각해보는 과정도 필요합니다.
둘
사용자 구매 데이터를 기반으로 구매 수량, 주기를 통해 구매 목적을 가정하고 그 용도에 맞게 추천을 설계해 볼 수도 있을 것 같습니다. 같은 제품군에서의 추천 뿐만 아니라 경계를 넘어선 추천도 가능할 수 있습니다. 예를 들어 기차로 서울-제주 출장을 매달 가는 사용자에게 또 기차티켓을 추천하면 이상하지만(ex: 서울-강원 기차여행 어떠세요?) 제주 관련 체험 프로그램을 추천하거나, 좋은 식사 장소를 추천할 수 있는 것처럼 말입니다.
셋
한 제품의 구매주기가 길다면, 유튜브 연속재생처럼 ‘또 본다’라는 인식없이 구매할 수 있도록 관련 있으면서도 신선한, 새로운 제품군을 추천하는 발상도 재미있습니다. 선풍기를 검색한 사용자에게는 수박을 추천하거나, 떡볶이 밀키트를 구매한 사용자에게는 분식 스타일 그릇을 추천해보는 것입니다. 물론 그 제품까지 도달할 수 있도록 상위 랭킹을 손볼 수는 없으니 “이 제품은 어때요?”처럼 완전 관련제품이 아님을 명시하는 제목이라도 있어야 화를 면할 것 같습니다.
