기울기
함수 f를 x0과 x1에 대해 동시에 편미분을 계산하면 아래와 같다. 이처럼 모든 변수의 편미분을 벡터로 정리한 것을 기울기(gradient)라고 함
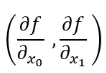
def numerical_gradient(f, x):
h = 1e-4
grad = np.zeros_like(x) # x와 형상이 같은 배열 생성
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h) 계산
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h) 계산
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val
return grad
numerical_gradient(function_2, np.array([3.0, 4.0]))
numerical_gradient(function_2, np.array([0.0, 2.0]))
numerical_gradient(function_2, np.array([3.0, 0.0]))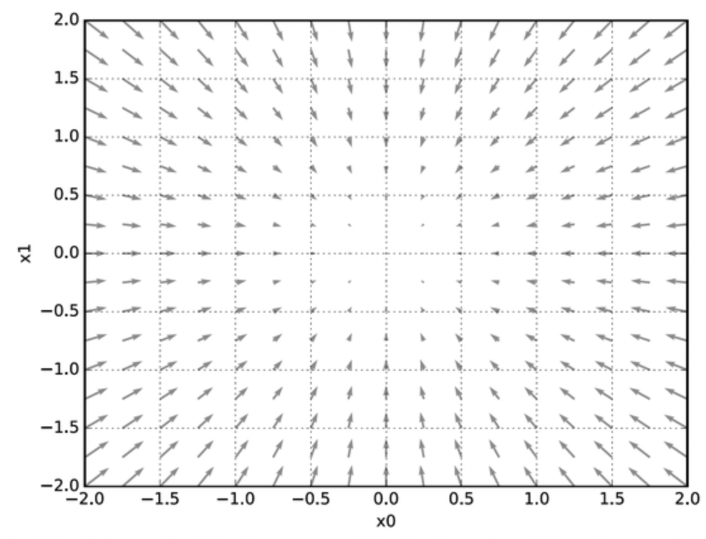
위 그림을 통해 아래의 내용을 알 수 있음
- 기울기는 함수의 '가장 낮은 장소(최솟값)'을 가리킨다고 볼 수 있음
- 또한, '가장 낮은 곳'에서 멀어질수록 화살표의 크기가 커짐
- 기울기는 각 지점에서 낮아지는 방향을 가리킴 (반드시 최솟값은 아님 - local minimum)
- 정확히는 기울기가 가리키는 쪽은 각 장소에서의 함수 출력 값을 가장 크게 줄이는 방향이라고 할 수 있다.
경사 하강법
기울기를 잘 이용해 함수의 최솟값(또는 가능한 작은 값)을 찾으려는 것을 경사 하강법이라고 한다.
1. 현 위치에서 기울어진 방향으로 일정 거리만큼 이동
2. 이동한 곳에서도 기울기를 구함
3. 다시 그 기울어진 방향으로 나아가기를 반복함
4. 위 과정을 통해 함수의 값을 점차 줄이는 것을 경사 하강법이라고 함
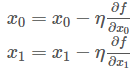
기호 η(eta)는 갱신하는 양을 나타냄. 이를 신경망에서는 학습률이라고 함.
위 식은 1회에 해당하는 갱신이며 이 단계를 반복함
또한 학습률 값은 0.01이나 0.001 등 미리 특정 값으로 정해 두어야 하며 일반적으로 이 값이 너무 크거나 작을 경우 ‘좋은 장소’를 찾아갈 수 없음
# 경사하강법 구현
def gradient_descent(f, init_x, lr=0.01, step_num=100): # f=최적화 함수 ini_x=초기값 lr=학습률 step_num=반복 횟수
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
init_x = np.array([-3.0, 4.0])
gradient_descent(function_2, init_x, lr=0.1, step_num=100)
>>> array([-6.11110793e-10, 8.14814391e-10])
# 학습률이 너무 큰 예
init_x = np.array([-3.0, 4.0])
gradient_descent(function_2, init_x, lr=10.0, step_num=100)
>>> array([-2.58983747e+13, -1.29524862e+12])
# 학습률이 너무 작은 예
init_x = np.array([-3.0, 4.0])
gradient_descent(function_2, init_x, lr=1e-10, step_num=100)
>>> array([-2.99999994, 3.99999992])
최솟값 탐색 결과 (0, 0)과 근접한 값을 얻음
학습률이 너무 크면 발산 / 너무 작으면 갱신 X
신경망에서의 기울기
신경망 학습에서도 기울기를 구해야 함. 여기서 말하는 기울기는 가중치 매개변수에 대한 손실 함수의 기울기.
예를 들어 2x3, 가중치가 W, 손실함수가 L인 신경망은 아래와 같이 표현할 수 있음
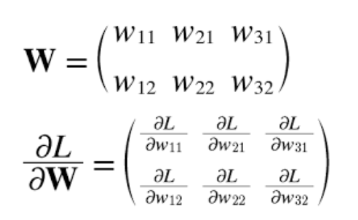
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 훈련 데이터가 원-핫 벡터라면 정답 레이블의 인덱스로 반환
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 오버플로 대책
return np.exp(x) / np.sum(np.exp(x))
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 값 복원
it.iternext()
return grad
class simpleNet:
def __init__(self):
self.W = np.random.randn(2,3) # 정규분포로 초기화
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss
x = np.array([0.6, 0.9])
t = np.array([0, 0, 1])
net = simpleNet()
f = lambda w: net.loss(x, t)
dW = numerical_gradient(f, net.W)
print(dW)학습 알고리즘 구현하기
- 전제
- 신경망에는 적응 가능한 가중치와 편향이 있고, 이 가중치와 편향을 훈련 데이터에 적응하도록 조정하는 과정을 '학습'이라 합니다.
- 미니배치
- 훈련 데이터중 일부를 무작위로 가져와서 미니배치를 만듭니다.
- 기울기 산출
- 미니배치의 가중치 매개변수의 기울기를 구합니다. 기울기는 손실함수의 값을 가장 작게 하는 방향을 가리킵니다.
- 매개변수 갱신
- 가중치 매개변수를 기울기 방향으로 아주 조금(LR에 비례해) 갱신합니다.
- 반복
- 1~3단계를 반복합니다.
위 단계들은 경사 하강법으로 매개변수를 갱신하는 방법입니다. 미니배치를 랜덤으로 선정하기에 확률적 경사 하강법(stochastic gradient descent, SGD) 이라 불립니다.

머신러닝 개발자