기계 학습 - 모아진 데이터로부터 규칙을 찾아내는 역할은 ‘기계’가 담당 / 이미지를 벡터로 변환할 때 사용하는 특징은 여전히 ‘사람’이 담당
신경망 - 이미지를 있는 그대로 학습 > 종단간(end-to-end) 기계 학습
손실함수
일반적으로 오차제곱합과 교차 엔트로피 오차를 사용함
오차제곱합
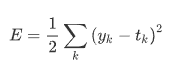 y_k = 신경망의 출력(신경망이 추정한 값)
y_k = 신경망의 출력(신경망이 추정한 값)
t_k = 정답 레이블
k = 데이터의 차원 수
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
def sum_squares_error(t, y):
return 0.5 * np.sum((y-t)**2)
# ex1 : 2일 확률이 가장 높다고 추정함 (0.6)
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
print(sum_squares_error(np.array(y), np.array(t)))
# ex2 : 7일 확률이 가장 높다고 추정함 (0.6)
y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
print(sum_squares_error(np.array(y), np.array(t)))교차 엔트로피 오차
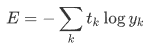 log = 밑이 e인 자연로그
log = 밑이 e인 자연로그
y_k = 신경망의 출력
t_k = 정답 레이블
식은 복잡해 보이나 사실상 -log(y_k)의 값과 같음
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
print(cross_entropy_error(np.array(y), np.array(t)))
y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
print(cross_entropy_error(np.array(y), np.array(t)))
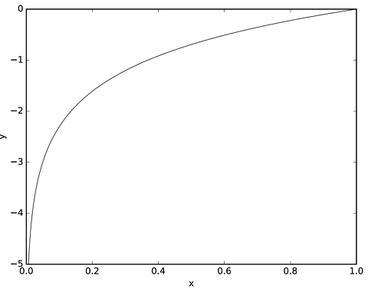
자연로그의 그래프
미니배치 학습
위에서는 데이터 하나에 대한 손실 함수만 계산
하지만 기계 학습에서는 훈련 데이터가 100개 라면 100개의 손실 함수 값이 있어야 함
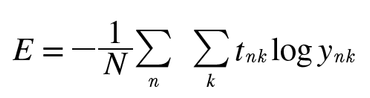
t_nk = n번째 데이터의 k값
y_nk = 신경망의 출력
t_nk = 정답 레이블
N으로 나누어 ‘평균 손실 함수’를 구함
- MNIST 데이터셋은 훈련데이터가 60,000개 존재
- 모든 데이터에 대한 손실 함수의 합을 구하려면 시간이 오래 걸림
- 빅데이터는 수백만에서 수천만까지도 되는데 이를 모두 계산 하는 것은 비효율적
- 일부를 추려 전체의 ‘근사치’로 이용 → 이를 미니배치라고 함
- 예를 들어 60,000장의 훈련 데이터 중 100장을 무작위로 뽑아 100장만을 이용해 학습 → 미니배치 학습
import sys
import os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
#load_minst()를 통한 데이터 불러오기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
# 각 데이터의 형상 출력
print(x_train.shape)
>> (60000, 784)
print(t_train.shape)
>> (60000, 10)
#총 훈련 이미지의 개수를 셉니다.
train_size = x_train.shape[0]
#손실 함수 계산에 몇개의 데이터를 이용할지 정합니다.
batch_size = 10
#몇번째 데이터로 손실 함수 계산을 할지 인덱스가 원소인 배열을 만듭니다.
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
np.random.choice(60000, 10)
>> array([ 8013, 14666, 58210, 23832, 52091, 10153, 8107, 19410, 27260, 21411 ])(배치용) 교차 엔트로피 오차 구현하기
데이터가 하나일때와 데이터가 배치로 묶여 입력될 경우 모두를 처리할 수 있게 교차 엔트로피 오차를 구현
데이터가 하나라면 신경망의 출력층 값들을 나타내는 y배열이 1차원이므로 조건을 y.ndim == 1: 처럼 설정
y = 신경망의 출력
t = 정답 레이블
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 훈련 데이터가 원-핫 벡터라면 정답 레이블의 인덱스로 반환
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
t = [[1, 0, 0], [0, 1, 0]]
y = [[0.9, 0.1, 0], [0.9, 0.1, 0]]
print(cross_entropy_error(np.array(y), np.array(t)))
t = [0, 1]
y = [[0.9, 0.1, 0], [0.9, 0.1, 0]]
print(cross_entropy_error(np.array(y), np.array(t)))위 구현에서 원-핫인코딩일 때 t가 0인 원소는 교차 엔트로피의 오차도 0이므로, 그 계산은 무시해도 좋다는 것이 핵심.
다시 말하면 정답에 해당하는 신경망의 출력만으로 교차 엔트로피 오차를 계산할 수 있음
손실함수를 설정하는 이유
정확도 대신 손실함수를 선택하는 이유
- 신경망 학습에서의 ‘미분’의 역할에 주목
- 신경망 학습에서는 최적의 매개변수(가중치와 편향) 값을 탐색할 때 손실 함수의 값을 가능한 작게 하는 매개변수 값을 찾음
- 이 때 매개변수의 미분을 계산하고, 그 미분 값을 단서로 매개변수의 값을 서서히 갱신하는 과정을 반복
- 손실함수는 매개변수의 변화에 연속적으로 변화하지만, 정확도는 매개변수의 변화에 둔감하고, 변화가 있더라도 불연속적으로 변화하기 때문에 미분이 불가능. 미분이 안되면 최적화를 할 수 없어서 정확도가 아닌 손실 함수를 지표를 삼아 학습을 하는 것

머신러닝 개발자