simple : 'Page'Rank -> 'Text'Rank
심플하게 설명한다면, TextRank는 PageRank에서 사용하는 webpage를 text로 대체한 핵심 문장 추출(요약) 및 키워드 추출 알고리즘입니다.
TextRank를 이해하기 위해선, TextRank 알고리즘의 기반인 PageRank에 대해서 간단히 이해해 보겠습니다.
머신러닝 알고리즘에 Input이 되는 data는 벡터로 표현됩니다.
그래프도 데이터를 표한하는 한가지 방법이며, 흔히 그래프를 G = (V,E)로 표현하고, V는 Vertex, E는 Edge를 의미합니다.
PageRank의 알고리즘은 검색 엔진에서 webpage의 순위를 정하기 위해 사용하던 알고리즘입니다.
위 그래프처럼 vertex(node)와 edge를 기반으로 한 알고리즘이며, 여기서 vertex는 webpage입니다.
(여기서 TextRank는 vertex들이 각 문장들이며, edge는 문장들 간의 유사도를 의미합니다.)
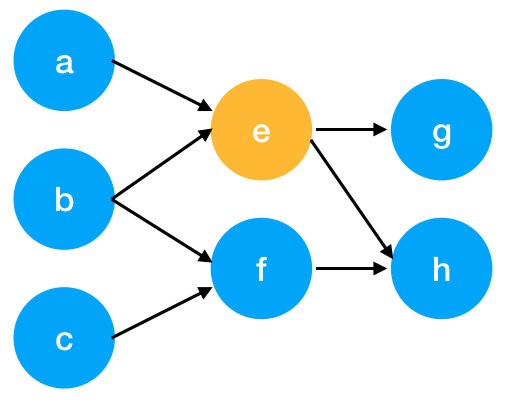
각 vertex(웹페이지)끼리 edge를 통해 방향과 가중치를 줄 수 있으며, 이를 matrix(행렬)화 시켜주고, 정규화를 해준뒤에 가중치를 행렬곱 합니다.
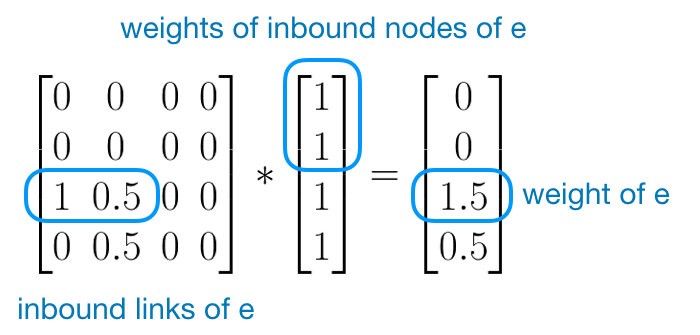
그래프 데이터에서 학습할 때 어떤 마디가 그래프 내에서 중요한 마디인가 입니다.
소셜 네트워크 분석에서는 영향력이 큰 사람을 찾는 문제일 수 있으며, 단어 그래프에서는 그래프를 대표하는 핵심 단어를 선택하는 문제일 수 있습니다.
이러한 문제를 graph ranking 이라 하고, PageRank 는 가장 대표적인 graph ranking 알고리즘입니다.
중요한 웹페이지를 찾기 위하여 PageRank 는 매우 직관적인 아이디어를 이용하였습니다.
많은 유입 링크 (backlinks)를 지니는 페이지가 중요한 페이지라 가정하고 이는 일종의 ‘투표’입니다.
각 웹페이지는 다른 웹페이지에게 자신의 점수 중 일부를 부여합니다.
즉 중요한 페이지로부터 많은 유입을 받는 페이지가 중요한 페이지이고 각 웹페이지의 중요도를 정의합니다.
여기에 한 가지 더, 한 페이지의 유입은 backlinks 외에도 검색, 혹은 알고 있는 휍주소의 의한 유입처럼 임의적인 유입이 있을 수 있습니다.
PageRank 는 웹페이지 유입의 c 만큼은 링크에 의한, 1−c 만큼은 임의적인 유입이라 가정하여 아래와 같은 식을 기술합니다.
이 임의 유입은 PageRank 계산의 안정성을 가져오는 역할도 합니다.
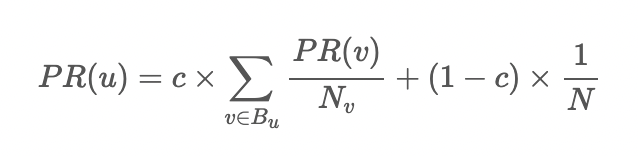
Bu 는 마디 u 로의 backlink 출발점들이며, Nv 는 각 마디 v 의 링크 개수 입니다. 한 마디 v 는 자신의 랭킹을 Nv 개로 나눠 링크로 연결된 페이지 u 에 전달합니다.
중요한 (랭킹이 높은 ) 마디로부터 backlinks 가 많은 마디는 랭킹이 높게 됩니다.
[출처 : https://lovit.github.io/nlp/2019/04/30/textrank/]
이를 파이썬 코드로 예시해 본다면,
import numpy as np
g = [[0, 0, 0, 0],
[0, 0, 0, 0],
[1, 0.5, 0, 0],
[0, 0.5, 0, 0]]
g = np.array(g)
pr = np.array([1, 1, 1, 1]) # initialization for a, b, e, f is 1
d = 0.85
for iter in range(10):
pr = 0.15 + 0.85 * np.dot(g, pr)
print(iter)
print(pr)Output,
0
[0.15 0.15 1.425 0.575]
1
[0.15 0.15 0.34125 0.21375]
2
[0.15 0.15 0.34125 0.21375]
3
[0.15 0.15 0.34125 0.21375]
4
[0.15 0.15 0.34125 0.21375]
5
[0.15 0.15 0.34125 0.21375]
6
[0.15 0.15 0.34125 0.21375]
7
[0.15 0.15 0.34125 0.21375]
8
[0.15 0.15 0.34125 0.21375]
9
[0.15 0.15 0.34125 0.21375]
10
[0.15 0.15 0.34125 0.21375]다시 한번 심플하게 설명한다면 PageRank는 WebPage Ranking이고, TextRank는 Text Ranking입니다.
[출처 : https://towardsdatascience.com/textrank-for-keyword-extraction-by-python-c0bae21bcec0]
[출처 : https://lovit.github.io/nlp/2019/04/30/textrank/]
- 이번 프로젝트를 진행하면서 word embedding을 직접 담당하진 않았지만 불용어 리스트, 키워드 등록 등 간접적으로 배울 수 있었으며 가장 중요한건, 데이터를 단순한 키워드가 아닌, vector로 봐야되는점을 배웠다.
