파이썬의 탄생
1989년 12월, 30대 중반의 네덜란드의 컴퓨터 과학자 귀도 반 로섬(Guido Van Rossum)은 여러 프로그래밍 언어들의 한계로 크리스마스 프로젝트로 새로운 언어를 직접 만들어보기로 결심했으며, 원칙은 간단했다.
1. 읽기 쉬워야 하고,
2. 사용자가 원하는 모듈 패키지를 만들 수 있어야 했으며,
3. 약간 독특하고 신비한 이름을 원했다.
그 후 30년이 지난 지금 어느덧 파이썬은 세상에서 가장 인기있는 프로그래밍 언어로 자리매김했다.
무엇보다도 문법이 매우 쉬워 입문자들에게 가장 먼저 추천하는 언어이면서 "실행 가능한 수도코드(Executable Pseudocode)"라는 별칭으로도 불린다.
원래 수도코드란 실행이 되지 않는, 알고리즘만을 기술하는 코드를 말하는데 파이썬은 알고리즘만을 기술할 정도로 간결하면서도 실행까지 가능하다
그렇다고 실무에서는 사용할 수 없는 교육용 언어에 불과하지 않고, 한쪽에서는 입문용으로 배우고, 다른 한쪽에서는 컴퓨터과학 박사들이 세계 최고 수준의 학회에 제출할 논문을 작성하는 데 사용할 정도로 다방면에서 활약하고 있는 프로그래밍 언어다.
다음은 PYPL지수(Popularity of Programming Language Index)는 구글의 튜토리얼 검색량에 따라 프로그래밍 언어의 인기도를 측정하는 지표이다.
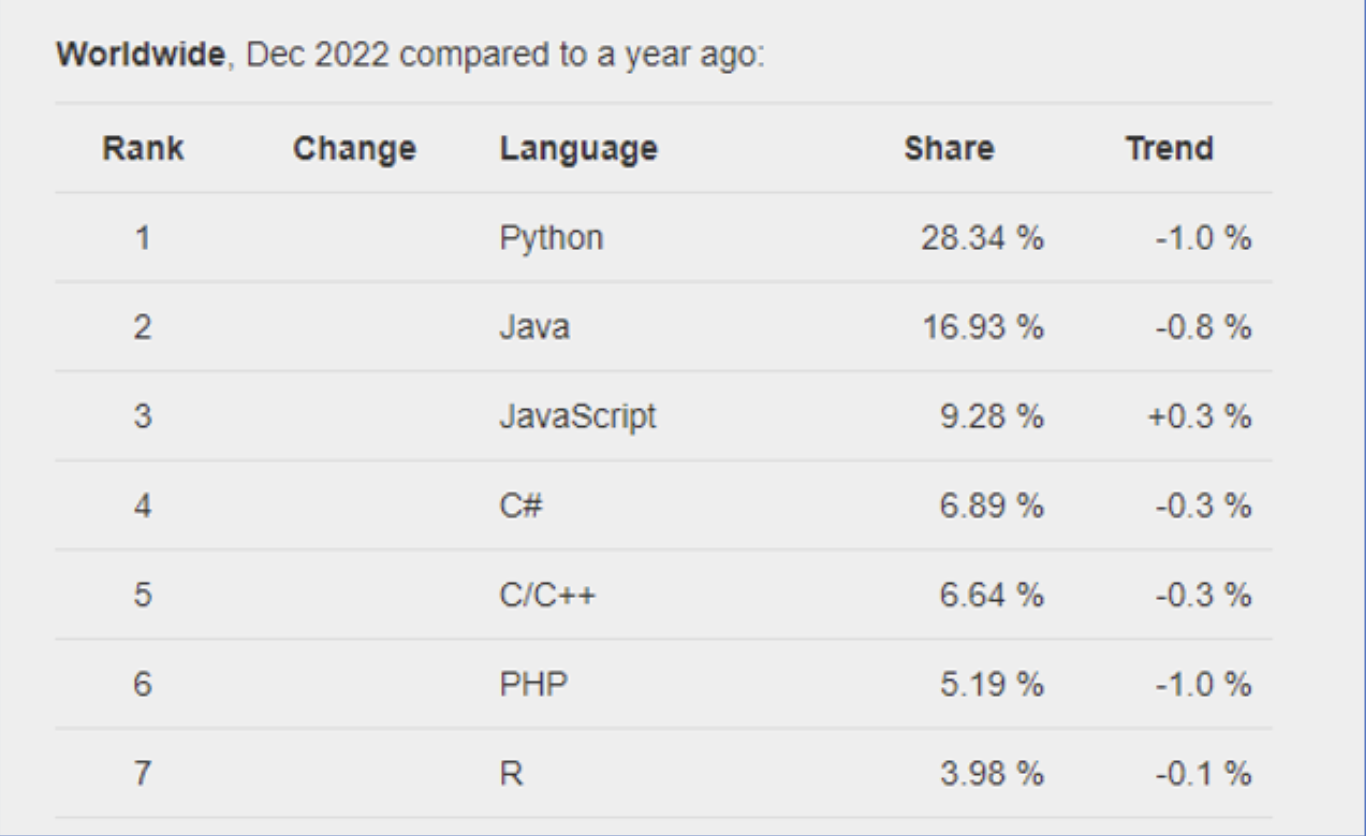
[출처-https://yozm.wishket.com/magazine/detail/1833/]
파이썬 문법
- PEP
파이썬의 개발은 파이썬 개선 제안서(PEP, Python Enhancement Proposals) 프로세스를 통해 진행된다.
PEP 프로세스는 새로운 기능을 제안하고, 커뮤니티의 의견을 수렴하여 파이썬의 디자인 결정을 문서화하는 파이썬의 주요 개발 프로세스를 일컫는다.
대표적으로 파이썬의 코딩 스타일 가이드는 PEP 8이다
- 인덴트(Indent)
파이썬의 대표적인 특징이기도한 인덴트는 공식 가이드인 PEP 8에따라 공백 4칸을 원칙으로 한다.
(한국어로는 "들여 쓰기"라고도 일컫는다)
강제하지 않고 2칸의 공백을 권장할 때도 있지만, PEP 8이후에는 이 기준을 준수한다.
또한, 가독성을 위해서 파라미터(Parameter)를 기준으로 인덴트를 맞춰주기도 한다.
# 파라미터가 시작되는 부분을 기준으로 인덴트를 맞췄을 때
foo = long_funtion_name(var_one, var_two,
val_three, val_four)
# 다른 행과 구분하여 인덴트를 맞췄을 때
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
foo = long_function_name(
var_one, var_two,
var_three, var_four)- 네이밍 컨벤션(Naming Convention)
파이썬은 변수명과 함수명을 각 단어를 밑줄(_)로 구분하는 스네이크 케이스(Snake Case)를 따른다.
일반적으로 모두 소문자로 표기하지만 경우에 따라 시작 문자는 대문자로 표기하기도 한다.
또한, 연구결과에 따르면 스네이크 케이스가 카멜 케이스보다 훨씬 더 인지하기 쉽다고도 하고, 파이썬은 PEP 8을 통해 스네이크 케이스 방식의 네이밍 컨벤션을 권장한다.
스네이크 케이스 외에도 대표적으로 단어별로 대소문자를 구분하여 표기하는 카멜 케이스(Camel case)가 있으며, 카멜 케이스는 첫 단어는 소문자로 작성하지만, 첫 단어부터 대소문자를 적용하는 파스칼 케이스(Pascal Case)가 있다.
# 스네이크 케이스(Snake Case)
snake_case = "Python"
# 카멜 케이스(Camel Case)
camelCase = "Java"
# 파스칼 케이스(Pascal Case)
PascalCase = "Upper Camel Case"- 타입 힌트( Type Hint)
파이썬은 대표적인 동적 타이핑 언어이기 때문에 함수를 정의해도 간결하게 정의해서 사용할 수 있다.
하지만 나중에 프로젝트의 규모가 커지게 된다면 파라미터로 들어가는 인자가 어떤 타입인지, 반환값은 무엇인지 인지하기 어렵기 때문에 가독성이 떨어지는건 물론 버그 유발의 주범이 된다.
# 타입 힌트를 사용하지 않을 경우
def fn(a):
...
# 타입 힌트를 사용할 경우, 인자값을 정수로 넘기면 Ture, False 중 한 개가 반환된다는 것을 인지할 수 있다.
def fn(a: int) -> bool:
...- 리스트 컴프리헨션(List Comprehension)
파이썬에서만 볼 수 있는 문법으로 기존 리스트를 응용해서 새로운 리스트를 간결하게 만드는 문법입니다.
기존 코드보다 짧고 간결하지만, 무리한 사용을 하면 오히려 가독성이 떨어질 수 있어 2개를 넘지 않도록 주의해야 합니다.
# 기존 리스트에 새로운 값을 넣을 경우
n_list = []
for i in range(10):
if i % 2 == 1:
n_list.append(i * 2)
# 리스트 컴프리헨션을 활용하여 위와 같은 코드를 작성할 경우
n_list = [i * 2 for i in range(10) if i % 2 == 1]
'''
리스트 컴프리헨션으로 다중 조건을 줄 수 있다.
여기서 주의할 점은 OR연산자는 직접 작성하여 해결할 수 있지만, AND 연산자는 직접 작성할 경우 SystaxError가 발생된다.
때문에 if 조건을 연속적으로 사용하면 AND연산을 할 수 있다.
'''
# SystaxError
n_list = [i for i in range(10) if i % 2 == 1 and if i % 3 == 0]
# AND 연산
n_list = [i for i in range(10) if i % 2 == 1 if i % 3 == 0]
# OR 연산
n_list = [i for i in range(10) if i % 2 == 1 or i % 3 == 0]리스트 컴프리헨션으로 리스트만을 다뤘지만, 컴프리헨션 식으로 리스트뿐만 아니라 셋(Set), 튜플(Tuple), 딕셔너리(Dictionary)도 가능하다.
- 제너레이터(Generator)
루프의 반복(Iteration) 동작을 제어할 수 있는 루틴 형태를 말합니다.
예를 들어 아주 큰 수를 만들어내고 계산할 때는 일부만 사용할 경우나 혹은, 단순히 제너레이터만 생성해 두고 필요할 때만 사용할 때 유용한 문법입니다.
보통 함수로 만들고 사용할 행을 yield 뒤에 적어주고, 메인 함수에서 호출할 때는 next()함수를 사용합니다.
# 간단한 예시 1
def three_generator():
yield 1
yield 2
yield 3
t_gen = three_generator() -> 1번째 출력 예시
next(t_gen) -> output 1
next(t_gen) -> output 2
next(t_gen) -> output 3
for i in three_generator(): -> 2번째 출력 예시
print(i)
-> output
1
2
3
# 간단한 예시 2
def infinite_generator():
count = 0
while True:
count += 1
yield count
infinite_g = infinite_generator() -> 출력 예시
for i in range(10):
print(next(infinite_g))
-> output
1
2
3
4
5
6
7
8
9
10
# 제너레이터 함수를 각각 2개의 변수에 선언하면 서로가 다른 객체이며, 각기 따로 동작합니다.
one = test_generator()
two = test_generator()
print(one == two)
-> False
print(one is two)
-> False- range
range() 함수는 파라미터(Parameter)를 1개부터 최대 3개까지 integer형만 전달할 수 있으며, 1개만 사용할 경우 0부터 함수에 전달된 인자까지의 수를 반환하고, 파라미터(Parameter) 2개를 전달할 경우 첫 번째 인자부터 두 번째 인자 - 1까지의 수를 반환하며, 3개를 전달하게 되면 두 번째 전달까지는 2개를 전달할 때와 동일하게 적용되며, 적용된 수 안에서 세 번째 인자값만큼 커진 수가 반환되거나 인자값으로 음수로 전달할 경우 수가 작아진다, 여기서 주의할 점은 세 번째 인자값을 음수로 전달할 경우, 당연히 첫 번째 인자가 두 번째 인자보다 커야되며, 동일하게 두 번째 인자 - 1까지 반환된다.
# 파라미터(Parameter)가 1개인 경우
print(list(range(3)))
-> [0, 1, 2]
# 파라미터(Parameter)가 2개인 경우
print(list(range(5, 8)))
-> [5, 6, 7] # 첫 번째 인자부터 두 번째 인자 - 1까지의 수를 반환
# 파라미터(Parameter)가 3개인 경우_1
print(list(range(1, 13, 3)))
-> [1, 4, 7, 10]
# 파라미터(Parameter)가 3개인 경우_2
print(list(range(13, 1, -3)))
-> [13, 10, 7, 4]range() 함수는 보통 for문에서 많이 사용합니다.
또한, 신기한 기능이 있는데 이전 Generator처럼 메모리를 절약하는 방법이 있다.
first_range = [n for n in range(1000000)]
second_range = range(1000000)
len(first_range)
-> 1000000
len(second_range)
-> 1000000
# 하지만 차이점은 first_range는 이미 생성된 값이 담겨 있고,
second_range는 생성햐야 한다는 조건만 존재합니다.
print(second_range)
-> rnage(0, 1000000)
print(type(second_range))
-> <class 'range'>
# 둘 사이의 메모리 점유율을 비교해보면 차이점이 있습니다.
sys.getsizeof(first_range)
-> 8448728
sys.getsizeof(second_range)
-> 48
# 여기서 굉장한 것은 미리 생성하지 않은 값은 인덱스에 접근이 안될 거라 생각되지만,
인덱스로 접근 시에는 바로 생성하도록 구현되어 있다.
second_range[999]
-> 999- enumerate
보통 list와 같은 자료형에서 정렬되지 않은 무작위 수(value) 와 순서(index) 를 같이 사용할 때 활용하는 함수이며, range() 함수와 마찬가지로 for문에서 많이 사용합니다.
n_list = [1, 2, 1, 3, 45, 3, 6]
print(n_list) -> [1, 2, 1, 3, 45, 3, 6]
list(enumerate(n_list)) -> [(0, 1), (1, 2), (2, 1), (3, 3), (4, 45), (5, 3), (6, 6)]
c_list = ['a4', 'a7', 'a1']
for idx, val in enumerate(c_list):
print(idx, val)
-> 0 a4
-> 1 a7
-> 2 a1- 나눗셈 연사자
파이썬 2이하 버전에서는 / 만 사용했지만, 파이썬 3이상에서는 /와 //의 차이가 있습니다.
# /를 사용할 경우 나눗셈
5 / 3
-> 1.6666666666666667
# //를 사용할 경우 몫
5 // 3
-> 1
# 추가로 나머지를 구할때는 %
5 % 3
-> 2
# 몫과 나머지를 동시에 구하려면 divmod() 함수를 사용
divmod(5, 3)
-> (1, 2)- print
출력하는 함수로 파라미터(Parameter)값을 어떻게 주느냐에 따라 여러가지 방법으로 출력이 가능합니다.
a = 'A1'
b = 'B2'
# 콤마(,) 를 사용할 경우 띄어쓰기로 값을 구분하여 출력해줍니다.
print(a, b)
-> A1 B2
# sep 파라미터로 구분자를 콤마(,)로 지정해줄 수도 있습니다.
print(a, b, sep=',')
-> A1,B2
# sep 파라미터로 줄바꿈을 생략할 수도 있습니다.
print(a, sep=' ')
print(b)
-> A1 B2
# 리스트를 출력할 때는 join() 으로 묶어서 출력이 가능합니다.
alphabet = ['A', 'B', 'C', 'D']
print(' '.join(alphabet))
-> A B C D
# 더하기(+) 연산자를 활용하면 붙혀서 사용할 수 있습니다.
print(a+b)
-> A1B2
# 여기서 주의할 점은 str 끼리 더하면 붙어서 출력되고 int 끼리 더하면 더한 값이 출력되지만,
str 과 int를 더하면 TypeError가 발생됩니다
# format 함수를 활용할수도 있고, f-string(formated string literal)도 가능합니다.
c = 3
print("{} : {}".format(c, a))
-> 3 : A1
print(f"{c} : {a}")
-> 3 : A1이 외에도 여러가지 출력 방법이 있습니다.
# 빈 자리는 빈공간으로 두고, 오른쪽 정렬을 하되, 총 10자리 공간을 확보
print("{0: >10}".format(500))
# 양수일 땐 앞에 + 표시, 음수일 땐 앞에 - 표시
print("{0: >+10}".format(500))
print("{0: >+10}".format(-500))
# 왼쪽 정렬하고, 나머지 빈 칸은 _으로 채움
print("{0:_<10}".format(500))
# 3자리수 마다 콤마를 찍어주기
print("{0:,}".format(10000000000))
# 3자리수 마다 콤마 & +,-부호도 붙이기
print("{0:+,}".format(10000000000))
print("{0:+,}".format(-10000000000))
# 3자리수 마다 콤마 & +,-부호 & 자릿수 확보한 후 빈 자리는 _로 채우기
print("{0:_<+30,}".format(10000000000))
# 소수점을 특정 자리수까지만 표시
print("{0:.6f}".format(5/3))output
500
+500
-500
500_______
10,000,000,000
+10,000,000,000
-10,000,000,000
+10,000,000,000_______________
1.666667[출처 : https://blackhippo.tistory.com/entry/Python-print%EB%AC%B8-%EC%98%A4%EB%A5%B8%EC%AA%BD%EC%99%BC%EC%AA%BD-%EC%A0%95%EB%A0%AC%ED%95%98%EA%B8%B0-%EC%9D%80%ED%96%89%EB%B2%88%ED%98%B8%ED%91%9C-%ED%91%9C%ED%98%84%ED%95%98%EA%B8%B0]
- pass
파이썬에서 pass는 널 연산(Null Operation)으로 목업(mockup)인터페이스부터 구현한 다음에 추후 구현을 할수 있습니다.
때문에 코드의 전체 골격을 잡을 때 반복문의 특정 조건 혹은, 클래스(class) 내에 매소드(method)에서 주로 사용됩니다.
class My_class(object):
def method_a(self):
pass
def method_b(self):
for i in range(10):
if i % 2 == 0:
pass- locals
로컬 심볼 테이블 딕셔너리를 가져오는 메소드로 업데이트 또한 가능합니다.
a = 'abc'
b = ['a', 'b', 'c']
c = 242
locals()
-> {..., 'a': 'abc', 'b': ['a', 'b', 'c'], 'c': 242}
# 가독성을 위해 pprint를 사용하면 좋습니다.
import pprint
pprint.pprint(locals())
# 메소드 업데이트
locals()['f'] = c + 5
locals()
-> {..., 'a': 'abc', 'b': ['a', 'b', 'c'], 'c': 242, 'f': 247}
locals()['c'] = 10
locals()
-> {..., 'a': 'abc', 'b': ['a', 'b', 'c'], 'c': 10, 'f': 247}클래스 메소드 내부의 모든 로컬 변수를 출력해 주기 때문에 디버깅에 많은 도움이 됩니다.
코딩 스타일
좋은 코드의 정답은 없지만 많은 사람이 선호하는 방식이거나 현업에서는 현업에서 사용되는 방식에 맞춰서 사용해야 된다고 합니다.
파이썬의 PEP 8(https://www.python.org/dev/peps/pep-0008/)과 구글의 파이썬 스타일 가이드(https://google.github.io/styleguide/pyguide.html)는 좀 더 실용적인 관점에서 좋은 파이썬 코드를 작성하는데 많은 도움이 됩니다.
특히 파이참(Pycharm) 같은 IDE를 사용하게 되면 PEP 8기준으로 자동으로 경고를 띄어주고 수정해주므로 많은 도움이 될 것입니다.
- 변수명과 주석
파이썬은 비교적 다른 언어보다 좀 더 직관적이고 인덴트를 필수로 하기 때문에 깔끔해 보일 수 있으나, 직관적이지 않은 변수명과 주석을 적지 않을 경우 본인이 적은 코드도 나중에는 이해하지 못하는 지경까지 올 수 있습니다.
때문에 a, b 변수명과 반복문인 for문에서 i, j, k를 사용하기 보다는 좀 더 직관적으로 작성할 수 있도록 습관들이는 것이 좋습니다.
또한 주석을 달아서 코드를 읽어내는데 도움이 될 수 있도록 적어주는 것이 좋고, 한글로 달아도 무방하지만 영어로 작성하는 것에도 부담이 없도록 익숙해지는 것이 좋습니다.
-
구글 파이썬 스타일 가이드
이미 파이썬의 공식 가이드인 PEP 8이 있지만, 구글 파이썬 스타일 가이드는 PEP 8에서는 설명하지 않는 좋은 코드를 위한 지침들이 여럿 있습니다.
특히 가독성을 높이기 위한 지침들이 많습니다.
몇가지만 살펴보자면-
먼저, 함수의 기본 값으로 "가변 객체(Mutable Object)"를 사용하지 않아야 됩니다.
함수가 객체를 수정하면 기본값이 변경되기 때문입니다.
그렇기 때문에 "불변 객체(Immutable Object)"를 사용해야 되고, None을 명시적으로 할당하는 것도 좋은 방법입니다.# 잘못된 예시 def My_function(a, b=[]): ... def My_function(a, b: Mapping = {}): ... # 좋은 예시 def My_fucntion(a, b=None): if b is None: b = [] def My_function(a, b: Optional[Sequence] = None): if b is None: b = []"가변 객체(mutable object)" - list, set, dict
"불변 객체(immutable object)" - int, float, bool, tuple, string, unicode -
True, False를 판별할 때는 암시적(Implicit)인 방법을 사용하는 편이 간결하고 가독성이 높습니다.
# 길이가 없다는 말은 값이 없다는 뜻으로 not user로 충분합니다. if len(users) == 0: -> if not users: print("no users") # 정수를 처리할 떄는 암시적으로 거짓 여부를 판별하기보다는 비교 대상이 되는 값을 직접 비교하는 편이 덜 위험합니다. if orders is not None and not orders: -> orders == 0 self.is_orders() # 모듈로 연산 결과가 0인 것을 정수로 처리하지 않고 암시적(Implicit) 거짓 여부로 판별하는 것은 위험하기 때문에, 명시적(Explicit)으로 값을 비교하는 편이 좋습니다. if not order % 10: -> order % 10 == 0 self.group_order() -
그 외에도 세미클론으로 줄을 끝내거나 세미클론을 사용하여 같은 줄에 두 문장을 써서도 안됩니다.
-
줄의 가로길이는 길어서는 안 된다는 암묵적인 약속이 있어 최대 줄 길이는 80자를 넘지 않도록 유의해야 합니다.
-
