링크 계층
호스트와 게이트웨이 라우터 사이에는 전용선이 존재하는 것이 아니라 모두 다 같이 사용하는 공용선 (Broadcast Medium)이라는 것을 통해서 패킷이 순서대로 전달이 된다. 따라서 동시에 패킷이 전달되려고 할 경우 충돌(collision)이 생긴다. 무선의 경우도 마찬가지이다. 공기는 모두가 사용하고 있고 두 명 이상이 동시에 얘기를 하면 잘 전달이 되지 않듯이 말이다.
패킷은 전자기파 시그널로 케이블에 실리기 때문에 공용선이기 때문에 연결된 다른 호스트에도 다 퍼져간다. 그렇기 때문에 2개 이상의 패킷이 동시에 나올 경우 충돌이 생겨서 제대로 전달되지 않는다.
애플리케이션 계층의 전송 단위인 메시지는 전송 계층의 전송 단위인 세그먼트의 데이터 부분에 담긴다.
세그먼트는 네트워크의 전송 단위인 패킷의 데이터 부분에 담긴다.
패킷은 링크 계층의 전송 단위인 프레임의 데이터 부분에 담긴다.
링크 계층에는 유선, 무선에 따라 다른 프로토콜이 존재한다. 유선의 경우 이더넷, 무선의 경우 와이파이 프로토콜을 따른다.
Mutiple Access protocols
브로드케스트미디엄을 컨트롤해서 충돌을 피하기 위한 프로토콜로 다른 말로 Medium Acess Control (MAC)이라고도 한다.
An ideal multiple acess protocol
Link bandwidth이 R이라고 했을 때
- 만약 노드 1개만 전송을 원한다면 그 노드가 R이라는 bandwidth을 다 사용할 수 있어야 한다.
- 만약 M개의 노드가 전송을 원한다면 각각 R/M씩 bandwidth을 사용할 수 있어야한다.
- 분산적으로 컴퓨팅이 되어야 한다.
- 동작이 단순해야한다.
Channel partitioning
TDMA : time division multiple access
여러 노드들이 시간을 나눠서 엑세스 하는 방식

전송을 원하는 노드가 적을 경우 시간이 낭비된다. 사용자가 많을 경우 효율적
FDMA : frequency division multiple access
주파수를 나눠서 전송하는 방식
마찬가지로 낭비가 될 수 있다.
Random Acess
전송을 원하는 노드들만 전송을 한다. 두 개 이상의 노드들이 전송을 원할 때 충돌이 발생한다. 사용자가 적으면 효율적, 사용자가 많으면 비효율적
CSMA (carrier sense multiple access)
- 내가 전송하고 싶은 프레임이 있을 때 전송하기 전에 carrier sense의 상태를 먼저 살펴본다.
- 다른 노드가 보내고 있지 않으면 전송을 시작한다.
- 전송 중 frame 전송을 완료하기 전에 충돌이 감지되면 전송을 멈추고 binary exponential back up 만큼 기다린 후에 재 전송을 시작한다.
그래도 충돌함. 먼저 전송을 시작한 노드가 있다해도 전자기파의 진행속도가 제한이 있기 때문에 어쩔 수 없는 딜레이가 발생하고 이로 인해 다른 노드들도 착각하고 전송을 시작하면 충돌이 생긴다. 충돌은 어쩔 수 없으므로 피해를 최소화하기 위한 노력이 필요하다.
CSMA/CD
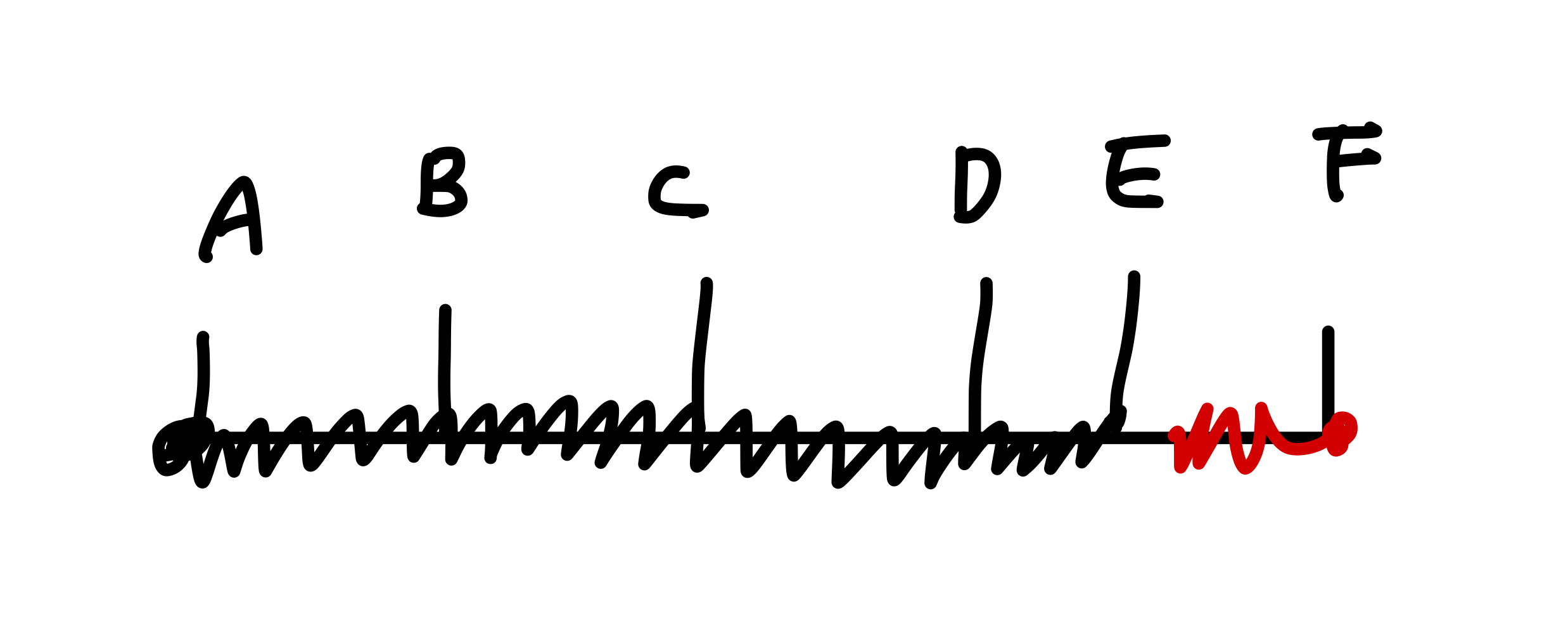
CSMA/CD는 충돌을 감지하고 바로 전송을 멈춘다. 그 후 랜덤 타임을 돌리고 재 전송을 한다. 이후 충돌이 일어나면 다시 반복한다. 재전송은 빠를수록 좋기 때문에 랜덤 타임의 폭이 좁을수록 좋다. 처음 충돌에 대해서는 짧게 랜덤 타임을 가지고 이후에는 2배씩 늘린다. 이를 binary exponential back up이라고 한다. 호스트가 많을수록 충돌이 발생할 확률도 늘어나기 때문에 인터넷 속도가 느리다고 체감하게 된다.
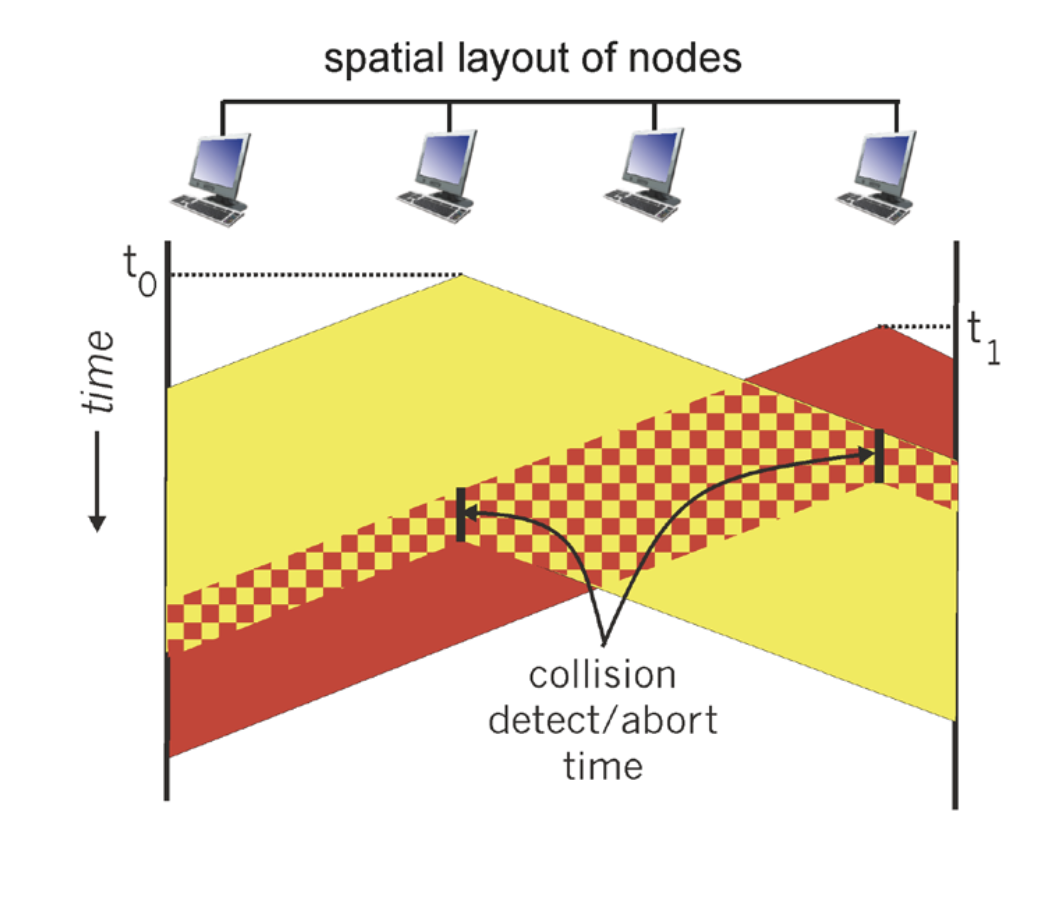
내가 보내는 전자기파의 세기와 다른 사람이 보내는 전자기파의 세기는 비슷하다. 그래서 바로 충돌을 감지할 수 있다.
Taking turns
Channel partitioning과 Random Acess의 장점을 합쳐본 방식
두가지 방식이 있다.
-
master노드가 slaves 노드를 관리하도록 한다.
Master 노드가 오작동하면 망함 -
토큰이 있는 노드만 전송할 수 있도록 하는 것
토큰 잃어버리면 망함
그래서 잘 안씀
실제로는 random access 많이 씀
Ethernet
유선 상황에서의 MAC 프로토콜
Ethernet frame structure
데이터 부분에 IP 패킷이 담긴다.

이더넷은 CSMA/CD를 사용한다. 그렇기 때문에 피드백(ACKs)을 받지 못한다. 충돌만 없으면 프레임은 무사히 게이트웨이로 전달되기 때문에 피드백이 필요 없다. 하지만 충돌이 생기면 무조건 재전송되야하기 때문에 충돌 감지가 정확히 되는 것이 중요하다.
만약 충돌이 생겼음에도 불구하고 감지가 안되는 상황이 발생한다면?
A라는 노드가 먼저 프레임을 전송하고 있고 G라는 노드가 또 프레임을 전송해 충돌을 일으켰다고 해보자. 만약이 A의 프레임의 첫 비트부터 마지막 비트가 전송될 때까지 충돌이 A에 도달하지 못한다면 A는 충돌을 감지하지 못한 채 프레임이 제대로 전달 되었다고 판단해 전송을 끝낼 것이고, 재전송하지 않으므로 해당 프레임은 영원히 lost되게 된다. 이 상황의 원인은 A의 프레임의 길이가 충분히 길지 않았기 때문이다. 따라서 랜선의 최대 길이와 어쩔 수 없는 딜레이를 감안해서 프레임 사이즈의 최소 사이즈는 정해져있다. 만약 실제 데이터가 프레임의 최소 사이즈보단 적을 경우 뒤에 패딩을 붙여 최소 사이즈를 맞춰줘야한다.
MAC Address
Ethernet frame의 헤더 부분에 dest address와 source address는 MAC Address를 사용한다. 예를 들어 사람을 인덱싱하는 방법을 생각해볼 수 있다. 사람을 인덱싱 하는 데에는 여러가지 방식이 있다. 이름, 주소, 주민 번호.. 등. 각각 역할이 있기 때문이다.
-
이름 - 원하면 바꿀 수 있다.
=> 호스트 네임 -
주소 - 물리적 위치에 종속된 인덱싱으로 이사라는 조건이 만족되면 바꿀 수 있다.
=> IP 주소 -
주민번호 - 바꿀 수 없다.
=> MAC 주소
MAC 주소는 48비트로 어떤 머신의 인터페이스 카드에 새겨진 주소이며 바꿀 수 없다.
ARP(address resolution protocol)
A라는 호스트에서 구글로 아이피 패킷을 보낸다고 해보자.
(SRC = source , DST = destination, Next-Hop= 바로 다음으로 연결될 위치, IP PKT = 아이피 패킷)
-
A는 DNS를 통해서 구글의 아이피 주소를 알아내고 아이피 패킷의 헤더의 DST에 넣을 것이다.
-
A는 연결될 게이트웨이(Next-Hop)을 알기 위해서 자기 자신의 Forwarding Table을 참조한다. 이 안에는 DST와 Next-Hop으로 엔트리가 구성되어 있다.
(호스트는 최초 부팅될 때 DHCP 프로세스를 통해서 자기 자신의 IP주소, 게이트웨이의 IP주소, DNS 서버의 IP주소를 알아낸다. 그 작업을 통해서 자기 자신의 Forwarding Table을 만든다) -
Next-Hop을 알았으니 프레임을 만든다.
아이피 패킷을 데이터 부분에 넣는다. 헤더의 SRC는 A의 MAC 주소를 적는다. DST에는 게이트웨이의 MAC 주소를 넣어야한다. 하지만 아직 IP주소 밖에 모르기 때문에 모르기 때문에 해당 IP 주소에 맞는 MAC 주소의 매핑을 알아야한다.이를 위해 사용하는 프로토콜이 ARP(address resolution protocol)이다.
-
ARP
IP주소로 MAC주소를 알아오는 프로토콜이다. 누가 해당 IP 주소에 해당하는지 모르기 때문에 브로드캐스트로 MAC주소를 물어봐야한다. 이를 ARP query라고 한다.📢 : 이 IP 주소 가지신 분 MAC 주소 좀 알려주세요 ~ARP query를 위해서는 프레임에 src에는 A의 MAC 주소를 넣고 DST에는 FF-FF-FF-FF-FF-FF을 넣는다. (브로드캐스트라는 의미) 그리고 데이터 부분에 ARP query를 넣는다. 그렇기 때문에 데이터 부분에 담긴게 ARP query인지 IP 패킷인지를 구분하기 위해서 필요한 필드가 프레임 헤더의
type필드이다.ARP query에는 내가 궁금해하는 인터페이스의 아이피 주소가 담긴다. 그에 대한 응답은 호스트 A에게 직접적으로 프레임으로 오게 된다. A는 알아낸 정보를 자기의 ARP TABLE에 적어 놓는다. IP ADDR, MAC ADDR , TTL로 엔트리가 이뤄진다.
-
이제 프레임의 모든 정보를 채웠으니 CSMA/CD 방식으로 프레임을 전송한다.
-
게이트웨이는 프레임을 받아서 FRAME을 뜯어서 IP PKT을 확인한다. 그리고 그 아이피 패킷을 라우터 안에 있는 포워딩 테이블을 참조해서 어느 방향으로 포워딩 해야할지를 판단한 후 아이피 패킷을 담은 새로운 프레임을 만들어 보내야한다. 마찬가지로 Next-Hop는 해당하는 IP주소가 적혀 있기 때문에 MAC주소를 알기 위해서 ARP TABLE을 다시 참조한다.
도착할때까지 A에서 보낸 최초의 아이피 패킷의 데이터들은 변하지 않지만 포워딩 될 때마다 TTL이 1씩 감소된다. 그리고 아이피 패킷을 담은 프레임의 SRC, DST도 계속 바뀐다.
스위치
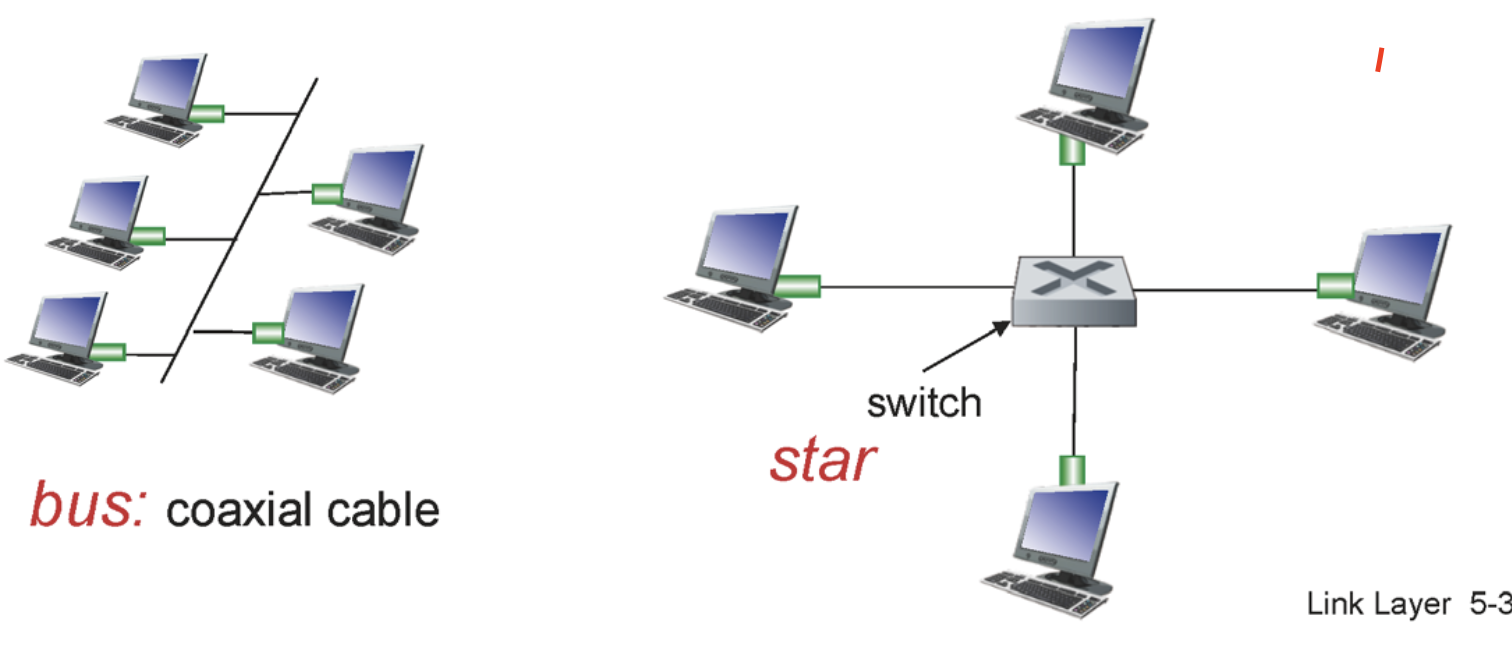
옛날에는 모든 노드들이 같은 충돌 도메인을 사용해서 동시에 노드들이 전송을 할 수 없었다. 하지만 요즘은 스위치라는 장비를 통해서 각 브로드캐스트 도메인을 분리한다. 각 노드들은 서로 충돌이 생기지 않고 각각 전송할 수 있다.
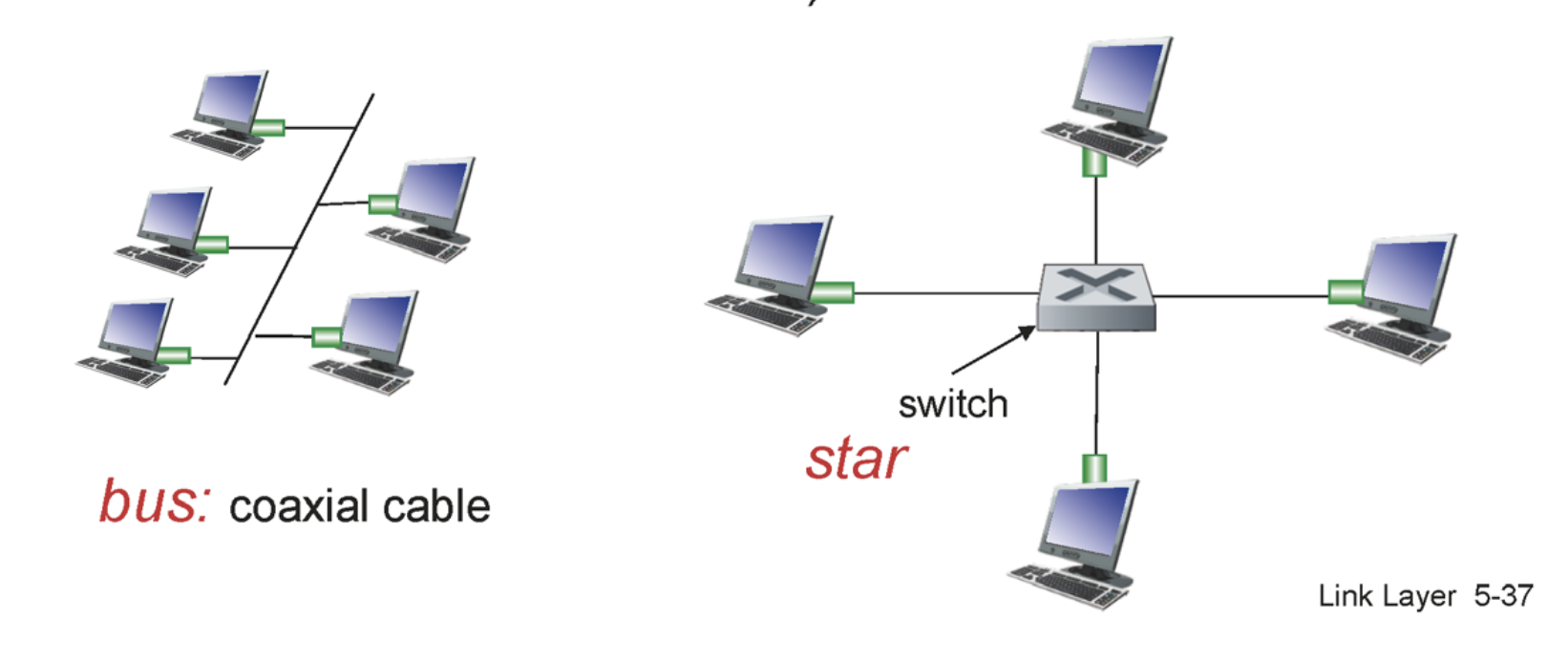
스위치 안에는 스위치 테이블이 존재하고 어떤 호스트가 어떤 인터페이스에 존재하는지 적혀있다. 이 정보는 스위치가 스스로 터득해 나가는데 이를 self-learing이라고 한다.
self-learning은 스위치가 프레임을 받았을 때 그 프레임의 SRC 주소를 보고 이루어진다.
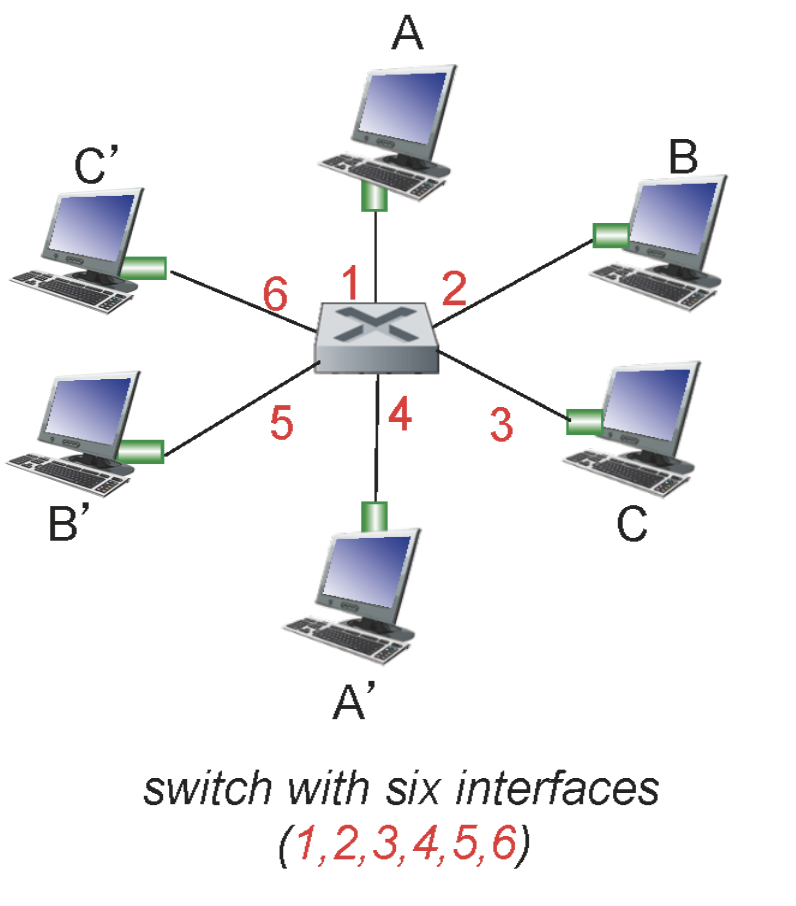
A에서 A'로 가는 프레임이 스위치에 들어왔다고 해보자
- 스위치 입장에서는 SRC인 A가 1번에서 들어왔기 때문에 최소한 A라는 MAC 주소는 interface 1에 존재한다는 것을 알 수 있고 이를 switch table에 기록한다.
- 하지만 아직 A'의 정보를 모르기 때문에 포워딩할 수 없다. 그래서 1번을 제외한 모든 인터페이스로 프레임을 보내버린다. 이를
flood이라고 한다. - A'만 해당 프레임을 받을 것이다.
만약 A'이 다시 A에게 프레임을 보낸다면 어떨까?
- 스위치는 프레임을 받아
self-learing한다. - 이후 포워딩을 해야하는데 A의 정보는 이미 switch table에 있기 때문에 이를 참조해 flood 없이 A에게만 프레임을 보낸다.
Interconnecting switches
연결할 수 있는 이더넷을 늘리기 위해서 스위치와 스위치를 연결해서 확장한다.
이때도 self-learning을 한다.
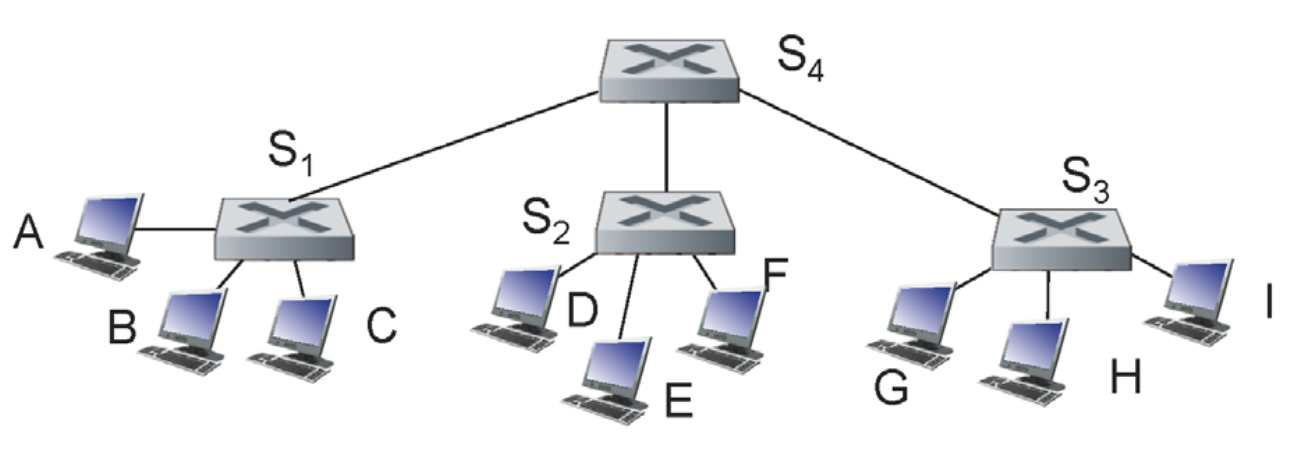
C에서 I로 간다고 생각해보자
C의 정보에 대해서 Self-learning이 일어나고 I의 정보는 모르기 때문에 모든 스위치로 flood이 퍼질 것이다.
-
S1
MAC INT# C 3 -
S2
MAC INT# C 0 -
S3
MAC INT# C 0 -
S4
MAC INT# C 0
다시 I에서 C로 돌아가는 경우를 생각해보자
지나가는 스위치에서는 I의 정보를 self-learning하고 C의 정보는 이미 알고 있으므로 flood 없이 바로 목적지로 포워딩할 것이다.
-
S1
MAC INT# C 3 I 0 -
S2
MAC INT# C 0 -
S3
MAC INT# C 0 I 3 -
S4
MAC INT# C 0 I 2
스위치가 하는 포워딩을 스위칭이라고 한다.
스위치는 Link layer 기반이고 MAC 주 레벨에서 포워딩을 하고 호스트에게는 존재가 안보이지만, 라우터는 네트워크 계층에서 IP 패킷을 보고 판단한다는 점에서 차이가 있다.
참고
http://www.kocw.net/home/search/kemView.do?kemId=1312397
http://www.kocw.net/home/cview.do?mty=p&kemId=1169634
