boost course의 자연어처리의 모든 것을 보고 복습차원에서 작성하였습니다.
앞에서는 RNN과 RNN을 이용한 CHARACTER LEVEL language model에 대해서 살펴보았습니다.
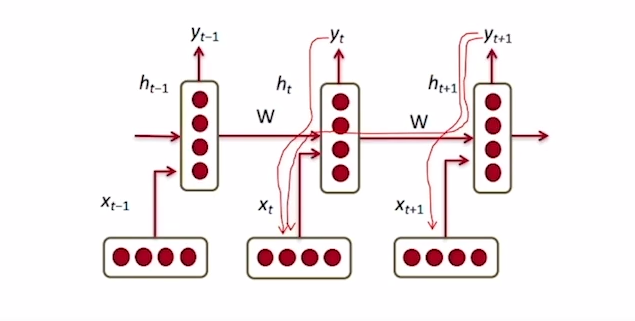
CHARACTER LEVEL language model은 위의 그림과 같이 학습이 진행됩니다. 각각의 input에 대하여 이전의 hidden state와 선형결합으로 현시점의 hidden state를 구하고 각각의 시점에서 해당하는 hidden state에 선형결합으로 output logits를 구하게 됩니다. 그 후 softmax함수를 통과시키고 예측된 label값에 loss를 계산하고 backpropagation를 통하여 각각의 가중치들을 update하며 학습을 하게 됩니다.
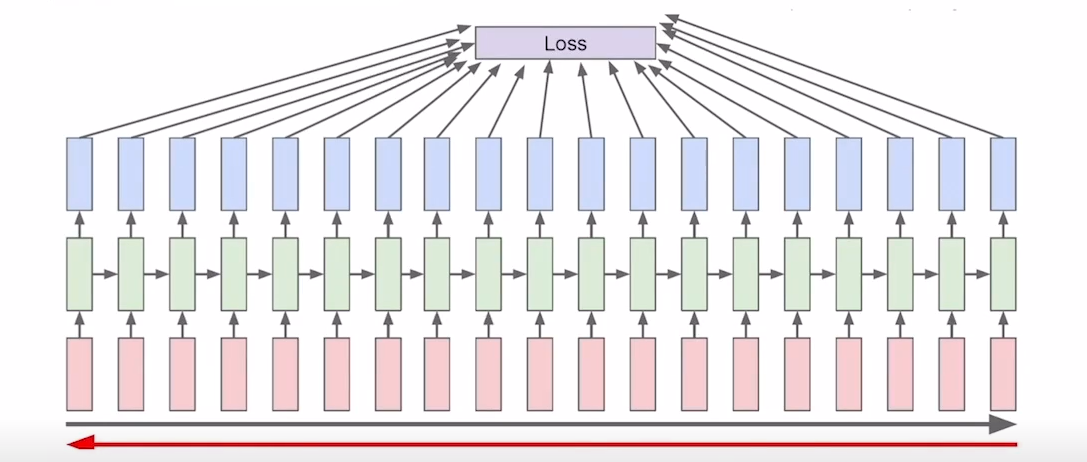
truncated backpropagation
RNN을 학습을 시킬 때에 마지막에 backpropagation을 통하여 hidden state를 update한다고 말씀 드렸습니다. 이 backpropagation을 하는 과정에서 입력 sequence의 길이가 너무 길다면 한번에 backpropagation을 하는것은 resource적인 측면에서 비효율적일 것입니다.
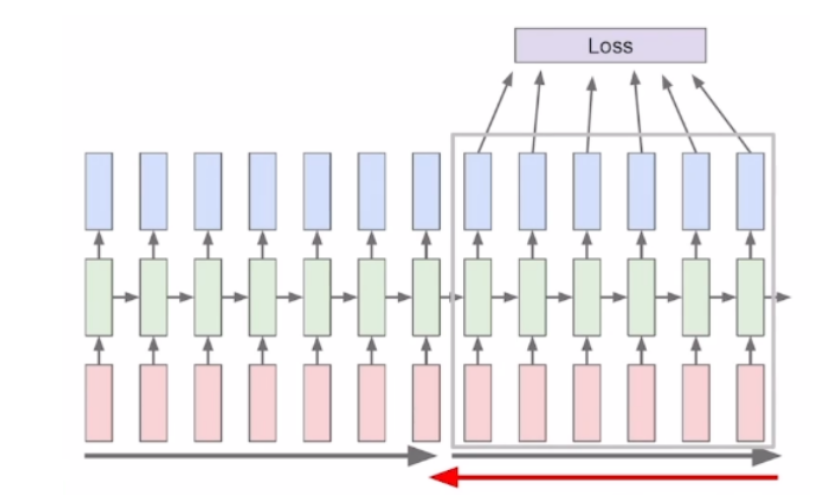
그래서 일정 sequence 길이로 잘라서 나눠서 backpropagation을 수행하게 됩니다.
Role of hidden state

RNN은 이전 step까지의 정보를 hidden state에 저장을 합니다. 위의 그림은 hidden state의 숫자를 음수면 빨간색 양수면 파란색으로 시각화 한 것인데 이 hidden state가 따옴표를 열고 닫았던 정보를 기억하고 있는 것을 볼 수 있습니다.
vanishing/exploding gradient
RNN은 위에서 말씀드린 형태로 학습이 진행되지만 몇가지 문제점이 있습니다. RNN의 경우 다음 step으로 넘어가는 데에 이전의 hidden state에 가중치 W(hh)를 곱하고 input값에 W(xh)를 곱하는 연산을 반복적으로 진행하게 되고 원하는 정보를 가진 hidden state를 얻기 위해 backpropagation을 수행하게 됩니다.
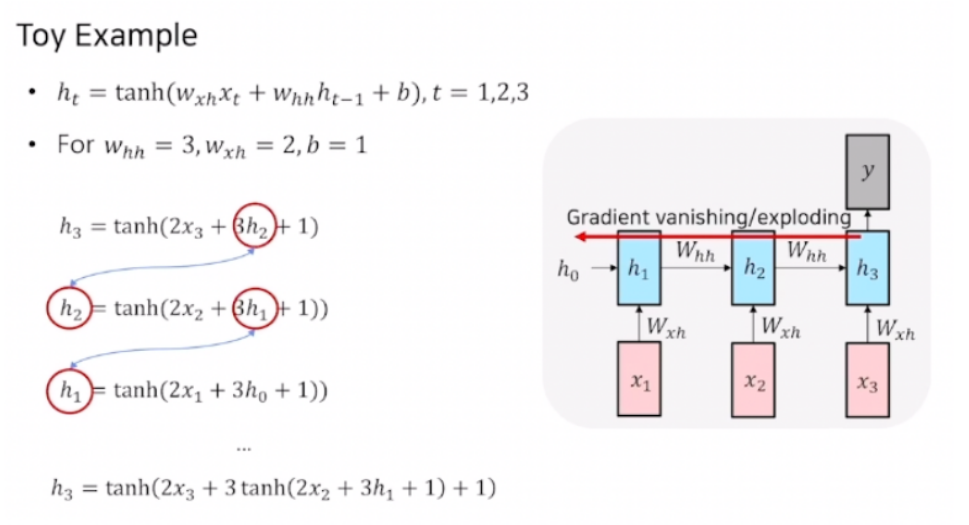
위 그림을 통해 time step이 3인 RNN의 backpropagation 과정을 살펴보겠습니다. 3번째 step에서 결과를 가지고 backpropagation을 통하여 오차를 1번째 step까지 전달 하기 때문에 h1에 대하여 h3를 미분하게 되면 chain rule에 의해서 아래와 같은 식이 작성되게 됩니다.(미분기호 생략)
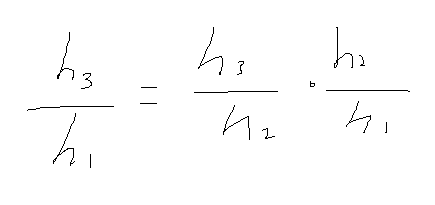
그래서 먼저 h3에 대해 h2의 미분을 먼저 해 보겠습니다.
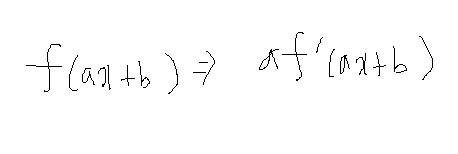
위와 같은 tanh의 속미분 공식으로 인해 3이 앞으로 튀어 나오게 되고 아래와 같은 결과가 나오게 됩니다.
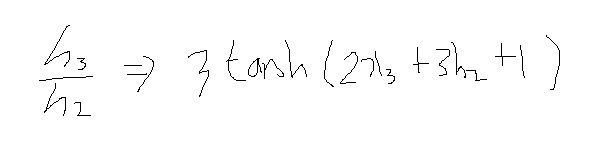
이 과정을 h2에 대해 h1의 미분에 또 적용을 시킨다면 속미분에 의해 3이라는 값이 나오게 될 것이고 만약 이게 3 step이 아니라 100 step이 었다면 3의 100승이라는 결과가 나오게 될 것이고 이러한 문제를 exploding gradient라고 합니다. 그리고 만약 3이 아니라 0.2와 같은 분수의 꼴이었다면 곱하면 곱할수록 0에 수렴할 것입니다. 이를 vanishing gradient라고 하고 이러한 상황들에서 학습이 잘 되지 않을 것입니다.
LSTM
LSTM은 기존의 RNN에 존재하던 vanishing/exploding gradient의 문제 해결하고 Time step이 멀더라도 효율적으로 정보를 전달하게 하는 모델입니다.
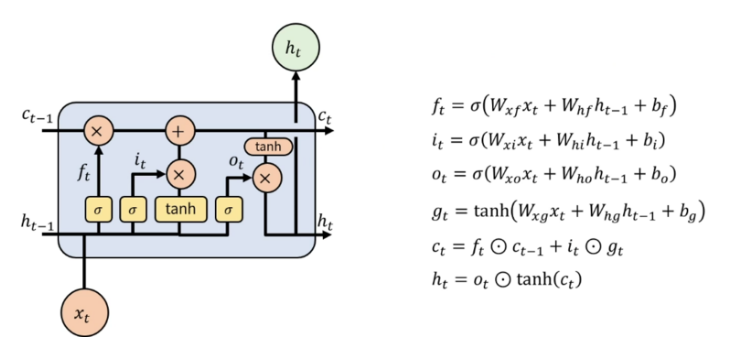
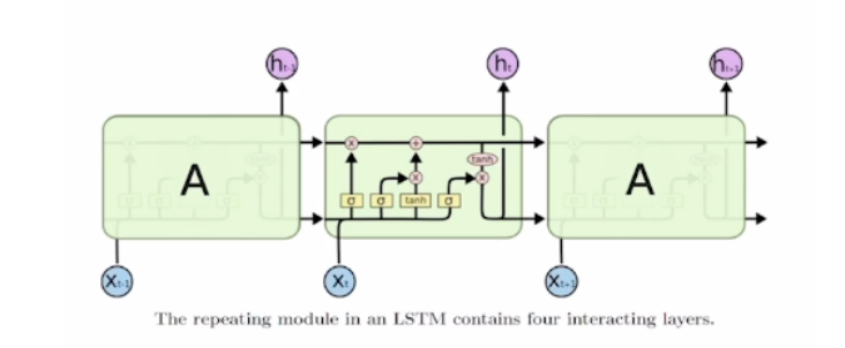
LSTM은 기존의 RNN과 달리 현시점의 input( x(t) )와 이전 시점의 hidden state( h(t-1) ), 이전 시점의 cell state( c(t-1) )를 입력으로 받습니다. cell state벡터는 무었일까요? cell state벡터는 hidden state에서 한번의 과정을 더 거쳐서 그 time step에서 필요한 정보만을 남기는 방식으로 만들어지게 됩니다. LSTM의 연산과정을 더 자세하게 살펴보겠습니다.
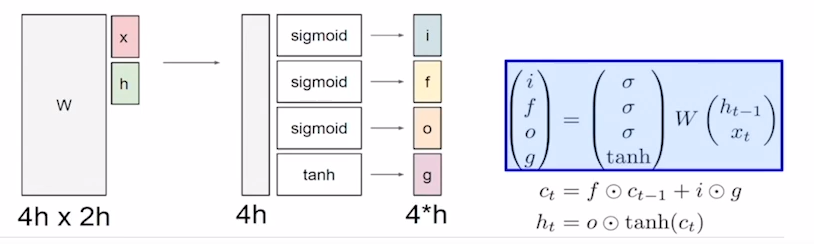
LSTM에는 총 4개의 gate가 존재합니다.
- f - forget gate(whether to erase cell)
- i - input gate(whether to write cell)
- o - output gate(how much to reveal cell)
- g - gate gate(how much to write cell)
input, forget, output, gate gate는 각각 입력으로 들어온 x(t)와 h(t-1)을 가지고 선형변환을 수행 후 활성화 함수를 거쳐 각각의 정보를 가지게 됩니다. 그 후 구해진 개별 gate값들을 가지고 c(t)와 h(t)를 구하게 됩니다.
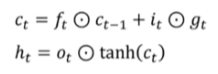
c(t)는 이전 시전의 c(t-1)과 앞에서 구해진 forget gate의 곱과 input gate와 gate gate의 곱의 합으로 구해지게 되고 h(t)는 이렇게 구해진 c(t)에 tanh함수를 거친 후 output gate와의 곱으로 구해지게 됩니다. 그래서 backpropagation 진행시 가중치(W)를 계속해서 곱해주는 연산이 아니라 forget gate를 거친 값에 대해 필요로하는 정보를 덧셈을 통해 연산하여 vanishing/exploding gradient 문제를 방지합니다.
GRU
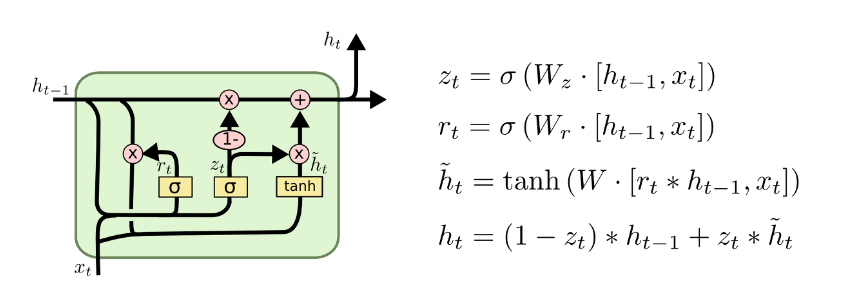
GRU는 LSTM을 간략화 해서 계산을 좀 편하게 해주는 모델입니다. 기존의 LSTM과의 차이점은 LSTM은 입력값으로 h(t-1), c(t-1), x(t)를 받지만 GRU는 h(t-1), x(t) 두개만 입력으로 주어진다는 점입니다. GRU의 구조는 위와 같으며 LSTM과는 달리 cell state가 완전히 사라졌으며(hidden state와 하나로 합쳐짐) gate도 forget, input 2개만 있는 것을 알 수 있습니다. 자세한 계산식은 LSTM과 비슷하니 이미지를 참고해주시면 감사하겠습니다.
