졸업을 위해 캡스톤 디자인을 하면서 Contrastive learning쪽에 대해 공부하게 되었는데, 공부에 쓰인 TS-TCC 논문을 정리해서 남기고자 해당 포스팅을 씁니다.
코드 : https://github.com/emadeldeen24/TS-TCC
논문 : https://arxiv.org/abs/2106.14112
연구의 목표는 심전도 데이터를 기반으로 부정맥을 예측하는 주제였으나, 시계열 데이터에 대한 지식이 없었고, Contrastive learning에 대한 지식 또한 없어 해당 내용을 습득하는 것에 중점을 맞추게 되었습니다.
1. 들어가기 앞서
먼저 Contrastive learning의 등장 배경에 대해서 간략히 쓰겠습니다.
Contrastive learning은 Self supervised learning의 한 종류 입니다. 지도학습과 비지도학습의 중간 정도의 특성을 가지며, 데이터의 숫자가 적거나, 데이터의 질이 좋지 않아 지도 학습을 사용하기 힘들 때 사용할 수 있는 방법입니다.
Contrastive learning에 대해서 간단히 설명하자면, 하나의 데이터샘플 A를 데이터 증대기법으로 A' 로 만들고, 배치에 존재하는 다른 데이터와 증대된 데이터 B,B', C, C', D, D'.... 등에 대해 같은 출처에서 나온 데이터인 A와 A'사이의 유사도를 최대로, A와 B,B',C... 에 대한 유사도를 최소한으로 하는 방향으로 학습하는 방법입니다.
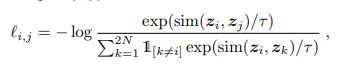
위는 SimCLR:A Simple Framework for Contrastive Learning of Visual Representations 논문(https://arxiv.org/abs/2002.05709)에서 발췌한 loss 함수의 식입니다.
해당논문의 sim(u,v)는 코사인 유사도로 , 텐서 u와 v의 내적을 u와 v의 크기를 곱한값으로 나누어준 값으로 사용했습니다.
τ은 temperature scailing 파라미터로, 이 또한 관련 논문이 있지만 모든 내용을 전부 논문에서 발췌하여 설명하기엔 길기 때문에 간략하게 설명만 하겠습니다.
τ 는 0 이상의 실수이며, 1을 기준으로 0<τ<1 일때, 확률 분포를 극대화하며 τ>1일때 확률 분포의 격차를 줄여줍니다.
로스 함수를 분석하면 - 1 *log안에 sim(Z, Z)/(sim(Z,Z) for 0 to )형태로 있는 것을 볼 수 있습니다.
이 때 분모는 해당 배치 내에 있는 각각의 샘플에 유사도의 합이 됩니다.
더 알기 쉽게 log를 풀어볼까요?
loss = -1 * (log(sim(Z,Z) - log((sim(Z,Z) for i 0 to k)))
= log((sim(Z,Z) for 0 to ))) - log(sim(Z,Z))
이 식에서 loss 값을 최소화하려면 어떻게 해야할까요? 앞의 항이 최소로 작아지고, 뒤의 항이 최대로 커지면 loss 값이 작아질 것입니다.
즉, 배치내의 i번째 샘플을 데이터 A라고 하고, j번째 샘플을 데이터 A', 나머지를 데이터 B,B',C...라고 한다면,
앞쪽 항에선 A와A'의 유사도를 제외한 나머지 샘플간의 유사도 합이 최소로, 뒤쪽 항에있는 A와A'의 유사도를 최대로 하게 되는 방향이 곧 loss를 최소화 하는 방향이 될 것입니다.
contrastive learning의 가장 중요한 개념을 loss함수 풀이로 정리했으니, 본격적으로 TS-TCC논문 번역 및 코드리뷰를 시작하겠습니다.
2. Abstract
레이블 되지 않은 데이터로 시계열 데이터를 학습시키는 것은 매우 도전적인 과제입니다.
이 논문에서는 레이블 되지 않은 시계열 데이터(Time Series data)를 Temporal and Contextual Contrasting을 이용한 비지도학습으로 학습시키는 프레임워크를 소개하고 있습니다.(TS-TCC)
먼저, 원본 시계열 데이터를 Weak과 Strong augmentation을 통해 두 가지로 변환합니다.
그 다음, Cross-view prediction을 통해 temporal contrasting을 진행합니다.
마지막으로, temporal contrasting 모듈을 통과한 데이터의 맥락을 극대화 하기 위해 contextual contrasting 모듈을 사용합니다.
마지막의 contextual contrasting에서 문맥이 다를 수 있으나, 같은 샘플에서 나온 데이터라면 그 유사도를 극대화하며, 동시에 다른 샘플에서 나온 데이터의 유사도를 최소화 합니다.
실험은 세 가지의 시계열 데이터로 진행되었으며, TS TCC 모델의 맨 윗부분에 Linear Classifier(Fully connected layer)을 추가하여 지도학습과 정확도를 비교해 보았습니다.
TS-TCC는 적게 레이블된 데이터에서 자기 지도 학습 후 전이학습을 했을때 높은 성능을 보였습니다.
논문의 도입부인 요약(Abstract) 부분입니다.
3. Introduction
시계열 데이터는 IoT나 웨어러블 기기를 이용한 헬스케어나 제조업으로 부터 점점 많이 수집되고 있습니다. 하지만 시계열 데이터의 특성상 이러한 특징이나 레이블을 사람이 이해하기 쉽지 않습니다. 그래서 시계열 데이터는 이미지 데이터보다 더 레이블링 하기 힘듭니다. 또, 현실에 완전 레이블 된 시계열 데이터는 거의 없습니다.
딥러닝 방법은 매우 방대한 양의 레이블 된 훈련용 데이터가 필요합니다. 그래서 제한된 양의 레이블 된 시계열 데이터로 학습시키는 것은 도전적인 과제입니다.
자기 지도 학습은 레이블 되지 않은 데이터를 이용한 다운스트림 태스크를 하는데 있어 최근에 더 많은 주목을 받았습니다.
완전히 레이블된 데이터로 학습된 지도학습 모델과 비교했을 때, 제한된 양의 레이블 된 데이터를 이용한 자기 지도 학습 모델은 충분히 비교할만한 성능을 보였습니다.
자기 지도 학습은 레이블 되지 않은 데이터로부터 훈련을 하고 특징을 학습하는데 있어서 사전작업(pretext tasks)이 필요합니다.
그러나 사전작업은 특징을 학습하는데 있어 일반화 성능을 제한할 수 있습니다.
예를 들자면, 컬러에 관한 특징이나, 물체의 위치를 찾는데 학습한 모델은 영상이 각도 몇도로 회전되었는지 분류하는 문제를 빗맞출 수 있습니다. 컴퓨터 비전 분야에서 대조 학습은 자기지도 학습을 위한 방법으로 그 효과를 증명했습니다. 대조학습은 증대된 데이터에서 부터 변하지 않는 특징을 학습하는데 효과적입니다. 입력 영상으로부터 증대된 데이터에서 다른 시각을 학습합니다. 그리고 같은 출처에서 나온 데이터는 다른 모습을 가지더라도 그 유사도를 높게, 다른 출처에서 나온 데이터는 유사도를 낮게 하는 방향으로 학습을 진행합니다.
그러나, 영상 기반의 대조학습 모델은 다음 이유로 시계열 데이터에서는 잘 동작하지 않습니다.
첫 번째, 영상 데이터에는 시계열 데이터의 가장 중요한 특징인 시간적 의존성을 가지고 있지 않습니다. 두 번째, 몇몇 데이터 증대방법은 색 왜곡 같은 영상 데이터를 위한 방법입니다. 이런 방법은 일반적으로 시계열 데이터에는 적용되지 않습니다. 또한, 시계열 데이터에 대조학습을 적용하는 연구는 거의 없었습니다. 예를들어, Mohsenvand와 Cheng 2020년 연구는 EEG데이터나 ECG데이터같은 생체 신호에 대조학습을 적용하는 연구를 했습니다. 그러나, 위의 두 방법은 특정한 경우(생체 신호)에만 적용 가능했고 일반적인 시계열 데이터에 사용하기엔 무리가 있었습니다.
이런 문제가 있어 우리는 Time-Series representation learning frameworkd via Temporal and Contextual Contrasting(이하 TS-TCC)를 개발하기로 했습니다. 우리의 프레임워크는 간단하지만 효과적이고 어떤 시계열 데이터에도 사용 가능한 데이터 증대방법을 사용하여 두 가지 다르지만 연관성있는 데이터를 만들어냅니다. 다음, 우리는 힘든 크로스-뷰 예측을 통해 temporal contrasting 모듈이 데이터의 강렬한 특징을 일정 타입스텝만큼 학습하게 합니다. 이 방법으로 과거의 특징을 이용해 미래의 다른 증대된 데이터를 예측이 가능하게 됩니다. 이 새로운 절차는 모델에게 있어서 잠재력을 부여합니다. 서로 다른 데이터 증대기법으로 나온 데이터의 미래를 상호적으로 예측함으로써 강렬한 특징을 배웁니다. 게다가, 우리는 temporal contrasting 모듈에서 나온 강렬한 특징을 통해 구별할 수 있는 특징을 contextual contrasting을 통해 모델에 학습시킵니다. 이러한 contextual contrasting 모듈에서 우리는 같은 데이터에서 나온 다른 문맥의 유사도를 최대화 하는 동시에, 다른 데이터에서 나온 문맥의 유사도는 최소로 하도록 학습시킵니다.
요약하자면, 본 연구의 주된 내용은 다음과 같습니다.
- 새로운 대조학습 프레임워크는 시계열 데이터의 비지도학습을 위해 개발되었다.
- 시계열 데이터에 있어 간단하지만 효과적인 데이터 증대 기법을 디자인하여 프레임워크에 적용시켰다.
- 우리는 새로운 temporal contrasting 모듈으로 힘든 크로스-뷰 예측을 통해 특징의 강렬한 부분을 모델이 학습하도록 한다. 게다가, 우리는 contextual contrasting 모듈을 통해 특징의 강렬한 부분으로 부터 데이터를 구분할 수 있는 부분을 학습시킨다.
- 우리는 우리의 목적인 TS-TCC 프레임 워크를 확장하기 위해 세 가지 데이터셋에 대하여 실험을 했다. 실혐 결과는, 자기 지도 학습을 시킨 후 전이 학습을 하는 다운스트림 태스크에 적용했을 때, 매우 효과적이었다.
논문의 첫 부분 Introduction에 관한 번역입니다.
4. Relative Works
여기선 TS-TCC에 관련된 연구에 대해 소개하고 있습니다.
2.1 self supervised learning
최근의 자기지도학습의 발전은 영상으로 부터 유용한 특징을 학습하는 pretext tasks 로부터 시작되었습니다.
이런 pretext task 들의 좋은 결과에도 불구하고, 그것들은 경험적 방법에 의존하고 있어 학습된 특징의 일반화에 있어 어려움을 가질 수 밖에 없었습니다. 반면, 대조를 사용하는 방법은 데이터를 증대하더라도 변하지 않는 특징을 학습하는 것에 두각을 나타내기 시작했습니다.
예를 들어, MoCo는 memory bank의 다른 데이터 쌍으로부터 특징을 학습하기 위해 모멘텀 인코더를 사용했습니다. SimCLR은 모멘텀 인코더 대신 더 많은 양의 다른 데이터를 배치에 넣음으로써 특징을 학습시켰습니다. 또한, BYOL은 다른 출처에서 온 데이터 쌍을 사용하지 않고 예측 값을 이용함으로써 특징을 학습시켰습니다. 마지막으로, SimSiam은 다른 출처에서 온 데이터 쌍을 무시하는 아이디어를 지지했습니다.. 그리고 Siamese 네트워크와 stop-gradient operation만을 통해 현재 선두를 달리는 성능을 보였습니다. 모든 접근방식이 성공적이며 영상 데이터의 특징학습에 있어서 발전을 보였습니다. 그러나 그것들은 시계열 데이터와는 다른 특성인 시간적 의존성 등에 의해 시계열 데이터에 잘 적용되지 않습니다.
2.2 Self-supervised Learning for Time-Series
시계열 데이터를 위한 특징 학습은 점점 유명해지고 있습니다. 몇몇 접근방법은 시계열 데이터를 위한 pretest task를 채택했습니다. 예를 들어, Saeed의 2019년 연구는 데이터에 여러 변형을 가한 인간의 행동 인지 이진 분류 pretext task를 설계했습니다. 그리고 원본과 변형된 버전을 분류했습니다. 비슷하게, SSL-ECG는 ECG의 특징을 여섯개의 변환을 통해 학습시켰습니다. 그리고 의사 레이블을 변환타입에 따라 할당했습니다. 게다가, Aggarwal의 2019년 연구에서는 로컬 및 글로벌한 패턴을 모델링하여 주제 의존적인 특징을 학습했습니다. 최근 대조학습의 성공에 영향을 받아 대조학습을 위한 연구가 진행되고 있습니다. 예를들어, CPC는 잠재된 공간에서 미래를 예측하는 것으로 특징을 학습했고 여러가지 대화 인지 태스크에서 발전을 보였습니다. 또한, Mohsenvand의 2020년 연구에서는 EEG에 관련된 데이터 증대를 하였고 SimCLR모델을 EEG 데이터에 맞게 확장시켰습니다. 기존 접근방식은 시간적 또는 전역적인 특징을 사용했습니다.
이와 다르게, 우리는 입력 데이터를 시계열 데이터에 맞는 특별한 데이터 증대 기법으로 다른 시각을 구성합니다. 게다가, 우리는 새로운 크로스-뷰 temporal 그리고 contextual contrasting 모듈을 통해 시계열 데이터로부터 특징을 배우는것의 성능 향상을 목표로 하고 있습니다.
이로서 논문의 앞부분이 끝났습니다. 이후의 내용은 코드 리뷰와 함께 진행할 것이고, 그러면 포스팅이 너무 길어질 테니 여기까지 하고 다음 포스팅에서 이어가겠습니다.
