[DE kit] 4. Airflow로 데이터 파이프라인 만들기
멱등성
- 한 번 수행, 여러 번 수행한 결과가 같다. (ex:어떤 수에 1을 곱하는 연산은 여러 번 수행해도 처음 수행과 결과가 같으므로 멱등하다.)
- 데이터 파이프라인이 연속 실행되었을 때 소스에 있는 데이터가 그대로 DW로
저장되어야함을 이야기 (소스 데이터 = DW 데이터) - No duplicates, no missing data
- source의 데이터와 DW의 데이터가 같아야 한다는 것
full refresh를 하는 데이터 파이프라인이라면?
1. 먼저 Data Warehouse의 관련 테이블에서 모든 레코드를 삭제한다.
2. Data Source에서 읽어온 데이터를 Data Warehouse 테이블로 적재한다.
-> 이 과정을 SQL의 Transaction으로 묶어준다. (all or nothing)
1이 성공하고 2가 실패하는 경우, 1이 실행된 다음 누군가 이 테이블을 사용하는 경우 등 방지 가능
DELETE FROM / TRUNCATE
DELETE FROM
조건을 걸 수 있고, 없으면 모든 레코드 삭제
-> Transaction에 사용
TRUNCATE
조건 없이 테이블의 모든 레코드 삭제
Transaction 내부에서 쓰여도 Transaction을 무시하고 테이블의 레코드를 삭제한 후 바로 커밋하게 된다. 보통 Transaction 내부에서 쓰이면 커밋 전까지 결과를 명시적으로 Physical Table에 적용이 되면 안되나 TRUNCATE는 이런 것을 무시한다.
-> Transaction에 TRUNCATE 사용 금지
트랜잭션
- Atomic하게 실행되어야 하는 SQL들을 묶어서 하나의 작업처럼 처리하는 방법
- https://postgresql.kr/docs/9.2/tutorial-transactions.html
- BEGIN과 END 혹은 BEGIN과 COMMIT 사이에 해당 SQL들을 사용
- ROLLBACK : 이전 상태로 되돌아감, 명시적으로 해주는 것이 좋다.
- Transaction Isolation Level : 'Read Committed'가 디폴트 세팅이다. 즉, 다른 사용자가 테이블에 엑세스할 때 내가 트랜잭션을 열고 작업하고 있는 상태가 아니라 트랜잭션 작업 전의 상태를 볼 수 있게 한다. 커밋한 것만 볼 수 있고 작업 중인 것은 볼 수 없다.
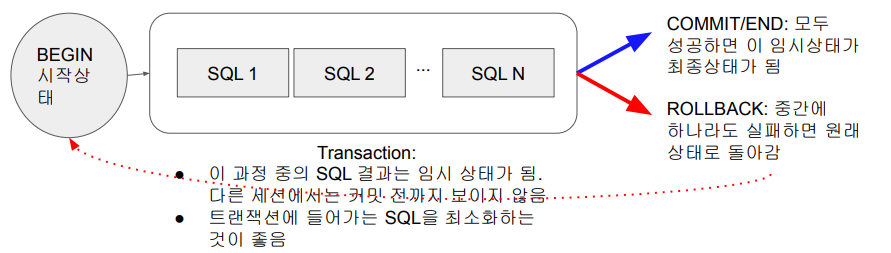 auto commit 이 True인 경우 BEGIN으로 시작해야 한다. auto commit 이 True인 경우 모든 쓰기 작업이 바로 커밋이 된다. 이것을 막으려면 BEGIN으로 시작하고, END 혹은 COMMIT을 명시하면 그때 커밋해라.
auto commit 이 True인 경우 BEGIN으로 시작해야 한다. auto commit 이 True인 경우 모든 쓰기 작업이 바로 커밋이 된다. 이것을 막으려면 BEGIN으로 시작하고, END 혹은 COMMIT을 명시하면 그때 커밋해라.
auto commit 이 False인 경우 모든 쓰기 작업이 바로 커밋되지 않는다. BEGIN을 부르면 아무것도 하지 않는다. 안써도 되고 써도 된다. 중간에 에러가 났을 때 ROLLBACK을 하면 깔끔하게 언커밋되었던 것들이 삭제되고 원래로 돌아간다.
트랜잭션 구현방법
두 가지 종류의 트랜잭션이 존재한다.
-> 레코드 변경을 바로 반영하는지 여부. autocommit이라는 파라미터로 조절가능
- autocommit=True
- 기본적으로 모든 SQL statement가 바로 커밋됨
- 바로 커밋되는 것을 방지하고 싶다면 BEGIN;END; 혹은 BEGIN;COMMIT을 사용 (혹은 ROLLBACK)
- autocommit=False
- 기본적으로 모든 SQL statement가 커밋되지 않음
- 커넥션 객체의 .commit()과 .rollback()함수로 커밋할지 말지 결정
무엇을 사용할지는 개인 취향에 따라 선택한다. Python의 경우 try/catch와 같이 사용하는 것이 일반적이다. try/catch로 에러가 나면 rollback을 명시적으로 실행. 에러가 안 나면 commit을 실행
끝에 raise를 붙여주는 것이 데이터 엔지니어링 관점에서 중요하다.
Try/Except 사용 시 주의사항
try:
cur.execute(create_sql)
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
raiseexcept에서 raise를 호출하면 발생한 원래 exception이 위로 전파됨
- ETL을 관리하는 입장에서 어떤 에러가 감춰지는 것보다는 명확하게 드러나는 것이 더 좋음
- 위의 경우 cur.execute 뒤에 raise를 호출하는 것이 좋음
raise가 없으면 try에서 에러가 발생해도 except에서 처리를 하기 때문에 Airflow에서는 문제가 없는 것으로 인식하게 된다. 에러가 있었고 이를 except에서 완벽하게 처리할 수 있는 것이 아니라면 raise를 불러주는 것이 좋다. 에러가 명확하게 드러나므로
Airflow 설치 방법
다수의 도커 컨테이너로 구성된 소프트웨어를 관리할 때 docker compose를 사용한다.
- EC2와 같은 리눅스 서버 사용

Airflow가 돌아갈 리눅스 서버를 Ubuntu로 구축한다. Ubuntu 무료라서 가장 많이 쓰이는 서버
Ubuntu에서 만든 방법은 Airflow의 모든 모듈이 하나의 서버에서 돌아간다. 도커로 만든 방법은 한 컴퓨터 위에서 돌아가지만 각각이 별개의 컴퓨터처럼 작동한다.
Docker 설치 에러
- No such file or directory: /opt/airflow/logs/scheduler/2023-06-18 -> opt/airflow는 도커 컨테이너 내에서 에어플로우가 설치되는 디렉토리이다. 그 밑에 Dags, plugins 등의 폴더가 존재한다.
- 해결방법 : docker-compose up을 실행하는 폴더에 logs 폴더를 먼저 만들고 실행한다. -> 윈도우에서는 logs 파일을 명시적으로 만들어주어야 하는 것으로 유추된다. 맥에서는 자동으로 생성해 실행됨
- Docker Volume: host volume, named volume, anonymous volume
- docker-compose.yml(=.yaml 야믈)이란?
- 다수의 docker container를 실행하는데 사용한다.
cf) Airflow의 host volume 관련
# yaml 파일 검색하기
vi docker-compose.test.yaml위와 같이 yaml 파일을 검색했을 때 volumes라는 키가 아래와 같이 나올 것이다.

현재 도커가 돌아가고 있는 파일 시스템의 특정 폴더 <-> 도커 컨테이너 안의 특정 폴더 매핑
-> 마운트한다.
즉, 현재 이 파일이 있는 폴더 밑의 Dags 폴더를 도커 컨테이너 안의 opt밑의 airflow 밑의 dags로 마운트해라. 이렇게 하면 에어플로우가 도커 안에서 돌 때 대그스 폴더 내의 내용을 등록하고 에어플로우 데이터 파이프라인으로 인지한다. 이것이 도커 볼륨 중 하나 host volume
도커가 돌아가는 호스트 시스템 즉 내 컴퓨터, 호스트 시스템 위에서 가상의 실행환경인 도커 컨테이너를 만들었다. 다수의 도커 컨테이너를 하나의 호스트에서 실행할 수 있다. 호스트 시스템의 특정 폴더를 도커 컨테이너 안의 특정 폴더와 매핑하면 여러 기능을 사용할 수 있다.
cf) command line
# 어떤 도커 컨테이너가 실행중인지 확인
docker ps
# 도커 프로세스에 로그인
docker exec -it "도커 컨테이너의 이름" sh
# 도커 프로세스에 로그인 후 어떤 파일 경로에 위치하는지 확인
pwd
ls -tl # 호스트 시스템에서 확인한 파일 경로와 유사하게 나올 것이다.
# logs 폴더에서 log 데이터 확인
cd logs # logs 폴더 진입
ls -tl # 로그 데이터 확인
# dag 목록 확인 -> dag id, 코드 위치, 주인, 실행여부 (True는 pause, false는 활성화)
airflow dags list
# dag에 어떤 task가 있는지 확인
airflow tasks list
# airflow task 실행
airflow tasks test 대그아이디 실행할 태스크아이디 2023-06-23
# airflow는 항상 날짜 정보가 필요하다. 정해둔 실행 시작 날짜보다 미래의 날짜이기만 하면 된다. 
앞으로 docker compose 와 관련된 명령어를 많이 사용할 것이다. 현업에서 매우 많이 사용한다.
DAG 소스코드
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
# DAG 오브젝트 생성 : 데이터 파이프라인
dag = DAG(
dag_id = 'HelloWorld', # Airflow 웹 UI에서 노출되는 이름
start_date = datetime(2022,6,14), # 명시하더라도 내가 실행하지 않으면 지정 날짜가 되더라도 실행되지 않는다.
catchup=False, # default=True, True는 대그의 시작날짜와 실제 실행날짜 사이 실행되지 않았던 만큼을 전부 실행 / full refresh를 하는 대그라면 True로 세팅할 이유X / DW경우 사용할 때마다 돈을 지불해야 하므로 주의 / catchup은 false로 설정 추천
tags=['example'], # 이름 밑에 붙는 태그, 다수의 태그를 동시에 지정할 수 있다. 태그를 통해 핕터링을 할 수 있다.
schedule = '0 2 * * *',# 매일 2시 0분 하루 한 번 실행되는 대그
default_args=default_args) # 위의 인자들은 대그에 지정되는 argument / 이 부분은 대그 밑의 태스크에 적용되는 파라미터
def print_hello():
print("hello!")
return "hello!"
def print_goodbye():
print("goodbye!")
return "goodbye!"
print_hello = PythonOperator(
task_id = 'print_hello',
#python_callable param points to the function you want to run
python_callable = print_hello,
#dag param points to the DAG that this task is a part of
dag = dag)
print_goodbye = PythonOperator(
task_id = 'print_goodbye',
python_callable = print_goodbye,
dag = dag)
#Assign the order of the tasks in our DAG
print_hello >> print_goodbye2개의 태스크로 구성된 데이터 파이프라인 (DAG : 에어플로우에서 데이터 파이프라인의 명칭, DAG는 Task의 집합, Task는 Operator로 구성된다.)
- print_hello: PythonOperator로 구성(구현)되어 있으며 먼저 실행
- print_goodbye: PythonOperator로 구성되어 있으며 두번째로 실행
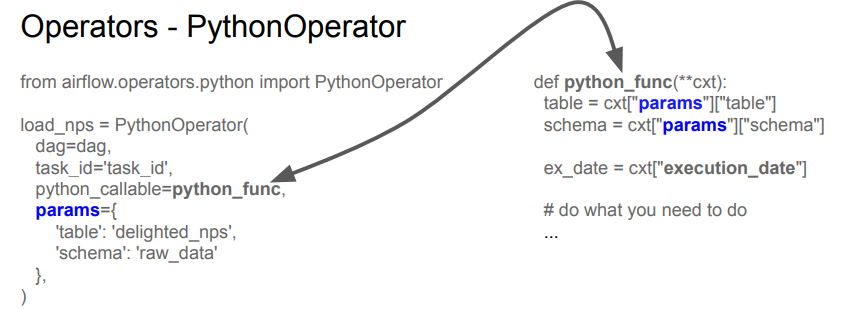
파이썬 오퍼레이터(파이썬 코드 실행기) 만들고,
- dag 태스크가 속한 대그를 지정
- task_id : 태스크 아이디 지정
- python_collable : 어떤 파이썬 코드를 실행할 것인지 함수 이름 지정
- params : 함수에 인자로 넘기고 싶은 값들을 전달
Airflow Decorators
위의 과정을 더 단순하게 작업하기 위한 도구
from airflow.decorators import task
@task # @task로 데코한다. 파이썬 오퍼레이터로 지정이 필요없다.
def print_hello():
print("hello!")
return "hello!"
@task
def print_goodbye():
print("goodbye!")
return "goodbye!"
with DAG(
dag_id = 'HelloWorld_v2',
start_date = datetime(2022,6,17),
catchup=False,
tags=['example'],
schedule = '0 2 * * *'
) as dag:
# Assign the tasks to the DAG in order
print_hello() >> print_goodbye()
더 깔끔한 패턴이다.
Task 파라미터
from datetime import datetime, timedelta
default_args = {
'owner': 'keeyong',
'email': ['keeyonghan@hotmail.com'], # Task 실패할 경우 이메일 알림 보낼 곳
'retries': 1, # 재시도 1번
'retry_delay': timedelta(minutes=3), # 재시도 사이에 3분 딜레이
}-
on_failure_callback : Task가 실패할 경우 호출할 함수, 보통 슬랙으로 메세지를 보내주는 함수로 설정하게 된다.
-
on_success_callback : Task가 성공할 경우 호출할 함수
-
여기서 지정되는 인자들은 모든 태스크에 공통으로 적용된다.
-
뒤에서 DAG 객체를 만들 때 지정한다.
중요한 DAG 파라미터 (not task 파라미터)
with DAG(
dag_id = 'HelloWorld_v2',
start_date = datetime(2022,5,5),
catchup=False,
tags=['example'],
schedule = '0 2 * * *'
) as dag:- max_active_runs: # of DAGs instance / 동시에 대그가 돌아갈 수 있는 수, 보통은 한 번에 하나의 대그가 돌아간다. 만약 incremental update이고 지난 1년치 대그를 업데이트하고 싶을 때, 한 번에 하나의 대그만 돌아간다면, 365번 돌아가야 한다. 이런 경우에 동시에 30개씩 돌려서 12번으로 끝내도록 조절할 수 있는 값. / 크게 설정하더라도 worker의 CPU 수에 의해 upper limit이 생긴다.
- max_active_tasks: # of tasks that can run in parallel / 해당 대그의 태스크를 동시에 몇 개를 돌릴 수 있는지 설정한다. / 마찬가지로 CPU에 의해 상한값 존재
-> 두 파라미터로 병렬성 조절 - catchup: whether to backfill past runs
- DAG 파라미터 vs. Task 파라미터 차이점 이해가 중요
- 위의 파라미터들은 모두 DAG 파라미터로 DAG 객체를 만들 때 지정해주어야함
웹 UI에서 DAG 컨트롤
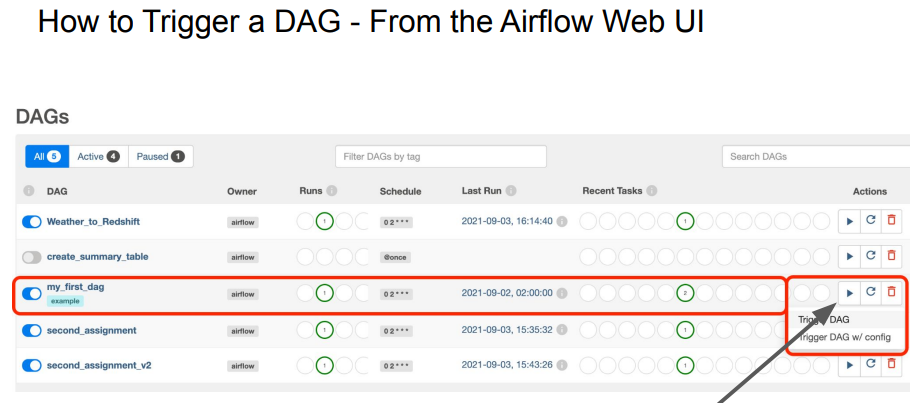
터미널에서 DAG 컨트롤
Airflow 컨테이너 중 하나로 로그인: “docker exec -it 컨테이너ID sh”
- airflow dags list
- airflow tasks list DAG이름
- airflow tasks test DAG이름 Task이름 날짜 # test vs. run
- 날짜는 YYYY-MM-DD
- start_date보다 과거인 경우는 실행이 되지만 오늘 날짜보다 미래인 경우 실행 안됨
- 이것이 execution_date의 값이 된다.
docker ps # 도커 아이디, 이름 찾기 위해
docker exec -it 컨테이너ID sh
airflow dags list
# my_first_dag 실행
airflow tasks list my_first_dag
#my_first_dag의 print_hello 태스크 실행
airflow tasks test my_first_dag print_hello 2020-08-09
# 태스크명 MySQL_to_Redshift_v3 -> 대그에 속한 모든 태스크들을 실행
airflow dags test MySQL_to_Redshift_v3 2019-12-08
# backfill할 기간
airflow dags backfill MySQL_to_Redshift_v3 -s 2019-01-01 -e 2019-12-31-it : interactive하게 실행하겠다.
어떤 날짜에 대해 대그가 성공했다면 똑같은 날짜에 다시 실행하면 성공으로 마킹되어 돌지 않는다.
Q. 도는 시간 주기에 따라서 시간단위나 timestamp로도 backfill 가능한가?
하루 단위로 돌아가는 대그라면 하루 단위로 백필이 가능하다. 그 외에는 불가하다.
Name Gender DAG 개선하기
Colab Python 코드를 Airflow로 Porting 하기
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import requests
import logging
import psycopg2
def get_Redshift_connection():
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
user = "keeyong" # 본인 ID 사용
password = "..." # 본인 Password 사용
port = 5439
dbname = "dev"
conn = psycopg2.connect(f"dbname={dbname} user={user} host={host} password={password} port={port}")
conn.set_session(autocommit=True)
return conn.cursor()
def extract(url):
logging.info("Extract started")
f = requests.get(url)
logging.info("Extract done")
return (f.text)
def transform(text):
logging.info("Transform started")
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
def load(records):
logging.info("load started")
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
schema = "keeyong"
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
logging.info("load done")
# ETL 각각의 함수를 연달아 부르는 함수
def etl():
link = "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"
data = extract(link)
lines = transform(data)
load(lines)
# 끝에 대그를 하나 생성했다.
dag_second_assignment = DAG(
dag_id = 'name_gender',
catchup = False,
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *') # 적당히 조절
task = PythonOperator( # etl 함수를 엔트리 포인트로 갖는 파이썬 오퍼레이터 생성
task_id = 'perform_etl',
python_callable = etl,
dag = dag_second_assignment)※ 문제점
1. CSV 링크가 하드코딩된 점
2. Redshift Connection 정보가 전부 노출된 것
3. host 이름이 바뀔 수 있는데 하드코딩 된 점
4. ETL도 각각을 Python Operator로 연달아 실행되도록 하는게 더 좋을 것이다.
5. ETL 함수의 패스된 태스크간의 데이터를 어떻게 전달할 수 있을까가 불분명
등등
NameGenderCSVtoRedshift.py 개선하기 #1
주의) git pull로 기존 git clone했던 폴더를 업데이트 한 후 실습 진행하기
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from datetime import datetime
from datetime import timedelta
import requests
import logging
import psycopg2
def get_Redshift_connection():
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
redshift_user = "keeyong" # 본인 ID 사용
redshift_pass = "..." # 본인 Password 사용
port = 5439
dbname = "dev"
conn = psycopg2.connect(f"dbname={dbname} user={redshift_user} host={host} password={redshift_pass} port={port}")
conn.set_session(autocommit=True)
return conn.cursor()
def extract(url):
logging.info("Extract started")
f = requests.get(url)
logging.info("Extract done")
return (f.text)
def transform(text):
logging.info("Transform started")
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
def load(records):
logging.info("load started")
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
schema = "keeyong"
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
logging.info("load done")
def etl(**context):
link = context["params"]["url"]
# task 자체에 대한 정보 (일부는 DAG의 정보가 되기도 함)를 읽고 싶다면 context['task_instance'] 혹은 context['ti']를 통해 가능
# https://airflow.readthedocs.io/en/latest/_api/airflow/models/taskinstance/index.html#airflow.models.TaskInstance
task_instance = context['task_instance']
execution_date = context['execution_date']
logging.info(execution_date)
data = extract(link)
lines = transform(data)
load(lines)
dag = DAG(
dag_id = 'name_gender_v2',
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
catchup = False,
max_active_runs = 1,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
task = PythonOperator(
task_id = 'perform_etl',
python_callable = etl,
params = {
'url': "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"
},
dag = dag)- context 이용하기
def etl(**context):- params를 통해 변수 넘기기 : ETL 함수 내부에서 하드코딩을 없앴다.
params = {'url': "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"},- execution_date 얻어내기
- “delete from” vs. “truncate”
- DELETE FROM raw_data.name_gender; -- WHERE 사용 가능
- TRUNCATE raw_data.name_gender;
NameGenderCSVtoRedshift.py 개선하기 #2
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from datetime import datetime
from datetime import timedelta
import requests
import logging
import psycopg2
def get_Redshift_connection():
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
redshift_user = "keeyong" # 본인 ID 사용
redshift_pass = "..." # 본인 Password 사용
port = 5439
dbname = "dev"
conn = psycopg2.connect(f"dbname={dbname} user={redshift_user} host={host} password={redshift_pass} port={port}")
conn.set_session(autocommit=True)
return conn.cursor()
def extract(**context):
link = context["params"]["url"]
task_instance = context['task_instance']
execution_date = context['execution_date']
logging.info(execution_date)
f = requests.get(link)
return (f.text)
def transform(**context):
logging.info("Transform started")
text = context["task_instance"].xcom_pull(key="return_value", task_ids="extract")
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
def load(**context):
logging.info("load started")
schema = context["params"]["schema"]
table = context["params"]["table"]
lines = context["task_instance"].xcom_pull(key="return_value", task_ids="transform")
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
logging.info("load done")
dag = DAG(
dag_id = 'name_gender_v3',
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
catchup = False,
max_active_runs = 1,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
# 파이썬 오퍼레이터를 이용한다.
extract = PythonOperator(
task_id = 'extract',
python_callable = extract,
params = {
'url': Variable.get("csv_url")
},
dag = dag)
transform = PythonOperator(
task_id = 'transform',
python_callable = transform,
params = {
},
dag = dag)
load = PythonOperator(
task_id = 'load',
python_callable = load,
params = {
'schema': 'keeyong', # load 함수의 경우 스키마와 테이블을 파라미터화했다.
'table': 'name_gender'
},
dag = dag)
extract >> transform >> load- Xcom 객체를 사용해서 etl 각각의 태스크를 세 개의 task로 나누기
- Redshift의 스키마와 테이블 이름을 params로 넘기기 <- 하드코딩했던 것을 개선
extract 함수의 결과가 transform 으로 넘어가고 transform 의 결과가 load로 넘어가야 한다. 이전에 하나의 태스크로 만들었을 때는 관계가 명확했다.
data = extract(link)
lines = transform(data)
load(lines)별도의 태스크로 만들 때는 xcom을 사용한다.
text = context["task_instance"].xcom_pull(key="return_value", task_ids="extract")extract 함수의 태스크 아이디 task_ids="extract"를 통해 extract 함수의 리턴값 return (f.text) 을 읽어온다.
같은 execution date 같은 날짜에 실행된 것을 읽어온다.
xcom pull로 읽어온 결과는 postgres 테이블로 저장된다. 그래서 xcom pull로 읽어오는 데이터는 작은 데이터만 가능하다. 큰 데이터는 S3에 올려놓고 그 링크(포인터, 위치)를 넘기는 형태로 진행한다.
NameGenderCSVtoRedshift.py 개선하기 #3
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from datetime import datetime
from datetime import timedelta
import requests
import logging
import psycopg2
def get_Redshift_connection():
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
redshift_user = "keeyong" # 본인 ID 사용
redshift_pass = "..." # 본인 Password 사용
port = 5439
dbname = "dev"
conn = psycopg2.connect(f"dbname={dbname} user={redshift_user} host={host} password={redshift_pass} port={port}")
conn.set_session(autocommit=True)
return conn.cursor()
def extract(**context):
link = context["params"]["url"]
task_instance = context['task_instance']
execution_date = context['execution_date']
logging.info(execution_date)
f = requests.get(link)
return (f.text)
def transform(**context):
logging.info("Transform started")
text = context["task_instance"].xcom_pull(key="return_value", task_ids="extract")
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
def load(**context):
logging.info("load started")
schema = context["params"]["schema"]
table = context["params"]["table"]
lines = context["task_instance"].xcom_pull(key="return_value", task_ids="transform")
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
logging.info("load done")
dag = DAG(
dag_id = 'name_gender_v3',
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
catchup = False,
max_active_runs = 1,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
extract = PythonOperator(
task_id = 'extract',
python_callable = extract,
params = {
'url': Variable.get("csv_url")
},
dag = dag)
transform = PythonOperator(
task_id = 'transform',
python_callable = transform,
params = {
},
dag = dag)
load = PythonOperator(
task_id = 'load',
python_callable = load,
params = {
'schema': 'keeyong',
'table': 'name_gender'
},
dag = dag)
extract >> transform >> loadtask = PythonOperator(
task_id = 'perform_etl',
python_callable = etl,
params = {
'url': "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"
},
dag = dag)url을 하드코딩으로 넘기는 것은 비효율적이다.
extract = PythonOperator(
task_id = 'extract',
python_callable = extract,
params = {
'url': Variable.get("csv_url")
},
dag = dag)csv_url에 https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv 를 담고 변수명을 전달한다.
at) Airflow
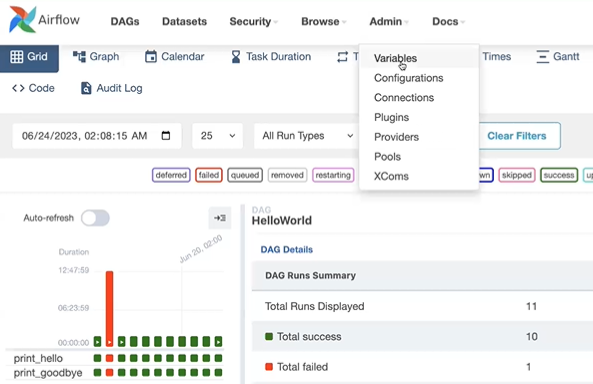
Admin -> Variables -> Add Variables
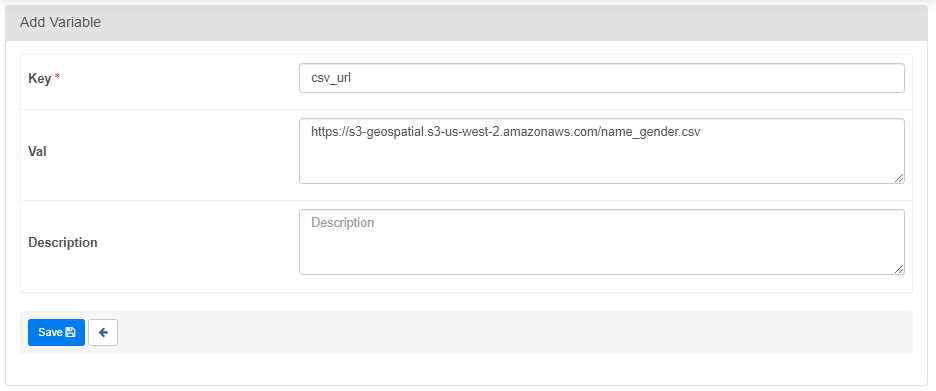
Airflow에서 추가한 변수를 활용하려면
from airflow.models import Variable모듈을 import 해야 한다.
Variable.get("csv_url")get 함수를 이용해 csv_url에 저장된 값을 읽어온다. set(키 이름, 새로운 값)을 사용하면 키에 저장된 Value값이 변경된다. 보안이 중요한 경우 이 기능을 활용한다.
키의 이름이 특정한 단어를 포함하면 Airflow에서 보여질 때도 *로 암호화하여 보여진다.
Connections and Variables
Connections
- This is used to store some connection related info such as hostname, port number, and access credential
- Postgres connection or Redshift connection info can be stored here
Variables
- Used to store API keys or some configuration info
- Use “access” or “secret” in the name if you want its value to be encrypted
- We will practice this
Redshift Connection 설정 (Data Warehouse)
def get_Redshift_connection():
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
redshift_user = "keeyong" # 본인 ID 사용
redshift_pass = "..." # 본인 Password 사용Redshift등과 연동하려면 Credential을 주고 인증을 해야 하는데 이런 정보가 connections다. Connection 정보를 숨겨야 한다.
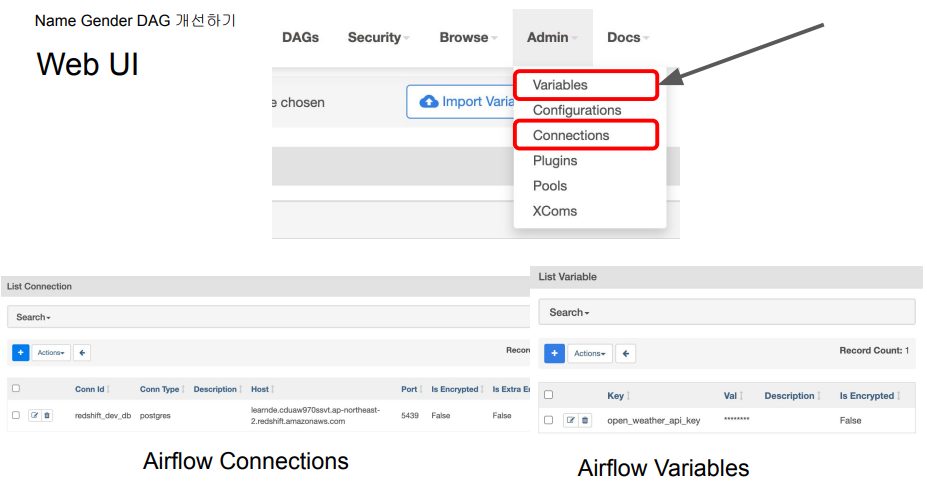
Airflow에서 Admin -> Connections
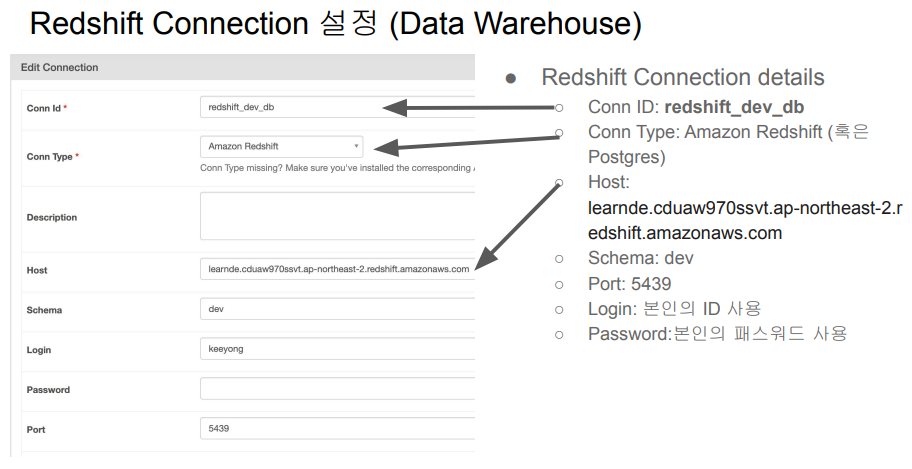
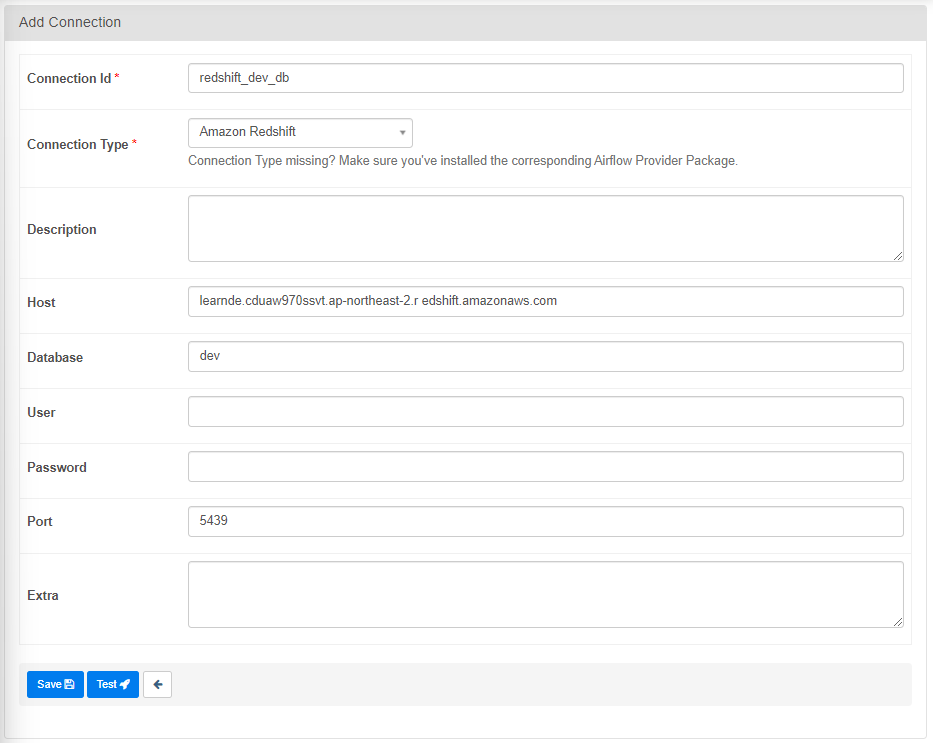
위의 항목들(connection 정보)이 Connections 밑에 감춰지게 된다.
NameGenderCSVtoRedshift.py 개선하기 #4
- 위에서 만든 Connection 아이디를 이용해 개인정보 감추기
def get_Redshift_connection():
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
redshift_user = "keeyong" # 본인 ID 사용
redshift_pass = "..." # 본인 Password 사용에서 redshift_dev_db 이용
def get_Redshift_connection(autocommit=True):
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()Redshift는 PostgreSQL과 호환되므로 PostgresHook을 import해서 Connection 아이디를 전달한다. 이후 우리는 커넥션 정보를 얻고 autocommit을 어떻게 할 것인지 세팅하면 됨(default=autocommit false)
Python Operator를 쓰지 않고 Task를 사용한 버전
from airflow import DAG
from airflow.models import Variable
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.decorators import task
from datetime import datetime
from datetime import timedelta
import requests
import logging
def get_Redshift_connection(autocommit=True):
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()
@task
def extract(url):
logging.info(datetime.utcnow())
f = requests.get(url)
return f.text
@task
def transform(text):
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
@task
def load(schema, table, records):
logging.info("load started")
cur = get_Redshift_connection()
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
logging.info("load done")
with DAG(
dag_id='namegender_v5',
start_date=datetime(2022, 10, 6), # 날짜가 미래인 경우 실행이 안됨
schedule='0 2 * * *', # 적당히 조절
max_active_runs=1,
catchup=False,
default_args={
'retries': 1,
'retry_delay': timedelta(minutes=3),
# 'on_failure_callback': slack.on_failure_callback,
}
) as dag:
url = Variable.get("csv_url")
schema = 'keeyong' ## 자신의 스키마로 변경
table = 'name_gender'
lines = transform(extract(url))
load(schema, table, lines)Task Decorator를 사용하면 코드가 간단해진다. Python Operator를 3번 만들지 않고 @task (Decorator)를 사용한다. xcom을 사용하지 않아도 되게 된다.
lines = transform(extract(url))
load(schema, table, lines)-> 매우 직관적이 됨, Python Operator을 많이 써야 하는 경우 Task Decorator 추천
extract 함수의 결과를 transform 함수의 인자로 주고 transform 함수의 결과를 load 함수로 넘겨라.
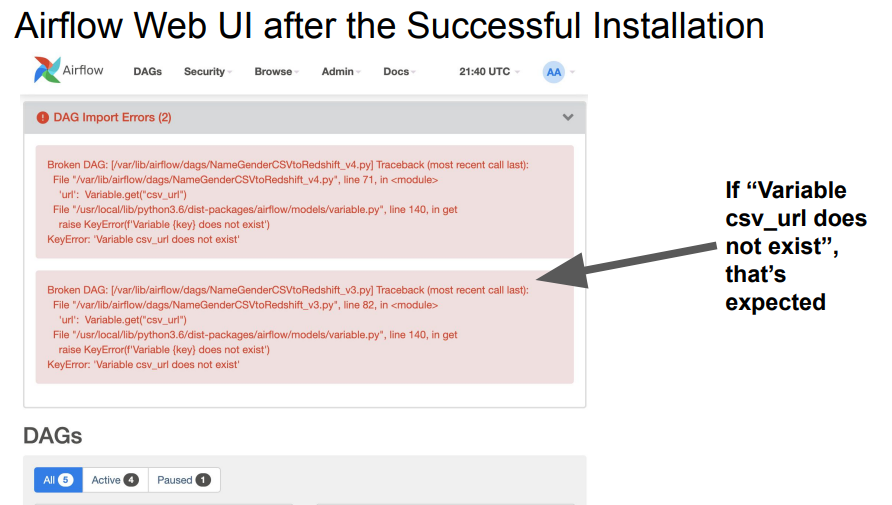
@Tetminal) github을 clone받은 폴더로 이동해서 git pull 받기 -> schema 이름 등 각종 정보 내 정보로 수정하기
정보 수정, Variable 세팅이 되지 않은 상태에서 발생하는 오류 내용
Yahoo Finance API DAG 작성 (1)
Yahoo Finance API를 호출해서 애플 주식을 읽어오는 Full Refresh로 읽어오는 DAG를 만들자
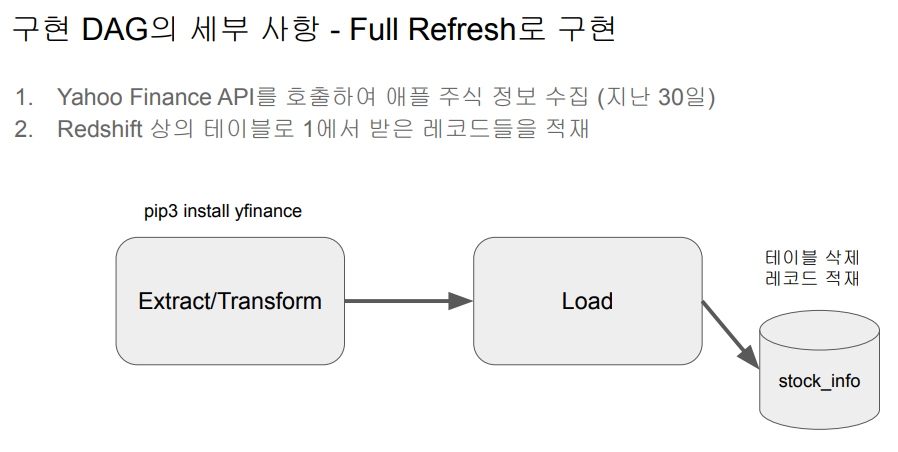
pip3 install yfinance # 설치Load: Redshift의 테이블을 업데이트
- full refresh로 구현 : 매번 테이블을 새로 만드는 형태
- 트랜잭션 형태로 구성 (NameGender DAG와 동일)
전체 코드
from airflow import DAG
from airflow.decorators import task
from airflow.providers.postgres.hooks.postgres import PostgresHook
from datetime import datetime
from pandas import Timestamp
import yfinance as yf # 임포트
import pandas as pd
import logging
def get_Redshift_connection(autocommit=True):
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()
@task
def get_historical_prices(symbol): #함수 생성, 주식의 symbol(애플은 APPL)
ticket = yf.Ticker(symbol)
data = ticket.history() # history가 리턴해주는 값은 판다스 데이터프레임
records = []
#지난 30일 정보를 불러와 저장한다. (주말 제외)
for index, row in data.iterrows():
date = index.strftime('%Y-%m-%d %H:%M:%S')
records.append([date, row["Open"], row["High"], row["Low"], row["Close"], row["Volume"]])
# 주식 정보의 날짜, 시작가, 최고가, 최저가, 종가, volume
return records
@task
def load(schema, table, records):
logging.info("load started")
cur = get_Redshift_connection() # 레드시프트 커넥션 정보 불러오기
try:
cur.execute("BEGIN;")
cur.execute(f"DROP TABLE IF EXISTS {schema}.{table};") #기존에 존재하던 테이블이 있으면 삭제하고 아니면 말기
cur.execute(f"""
CREATE TABLE {schema}.{table} (
date date,
"open" float,
high float,
low float,
close float,
volume bigint
);""") #테이블 새로 만들기 <- records로 받아온 데이터 순서 그대로 입력
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
sql = f"INSERT INTO {schema}.{table} VALUES ('{r[0]}', {r[1]}, {r[2]}, {r[3]}, {r[4]}, {r[5]});"
print(sql)
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;") #커밋하고
except Exception as error:
print(error)
cur.execute("ROLLBACK;") #에러가 나면 롤백하고 raise로 오류 발생을 알린다.
raise
logging.info("load done")
with DAG(
dag_id = 'UpdateSymbol',
start_date = datetime(2023,5,30),
catchup=False,
tags=['API'],
schedule = '0 10 * * *'
) as dag:
results = get_historical_prices("AAPL") #애플 주식의 심볼 전달하고 레코드 받아서
load("keeyong", "stock_info", results) #keeyong 스키마 밑에 stock_info 이름의 테이블로 만들어라위의 코드를 docker로 돌리기 위해 고려해야 할 점
- yfinance를 docker에 어떻게 설치할 것인가 : docker compose는 yfinance라는 모듈이 설치되어 있지 않다. pandas도 설치되어 있지 않을 가능성이 있다.
docker-compose.yaml 파일을 열어서 "없는 파이썬 모듈을 설치해주는 환경변수가 있다.
_PIP_ADDITIONAL_REQUIREMENTS - 현상태
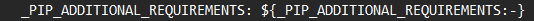
- 아래와 같이 수정한다

사용하려는 파이썬 모듈들을 적어주면 docker compose가 Airflow를 docker container로 실행할 때, Airflow가 다 설치된 후 뒤에 적어준 모듈들을 다시 또 설치해준다.
Airflow 개발 시 도커를 많이 사용하고 내가 필요한 모듈을 저 뒤에 적어준다.
:- 콜론 대쉬 -> 이런 이름의 환경 변수가 설정되어 있으면 거기에 있는 내용을 쓰고, 이 환경변수가 없으면 대쉬 뒤에 값을 써라. 조건문과 같은 yaml파일의 특수한 문법
yaml 파일 수정 후 docker를 docker compose down으로 꺼주고 docker compose up으로 재실행해야 한다.
docker ps 했을 때 postgres와 redis만 빼고 아무 곳에나 들어가도 된다. 모든 에어플로우 모듈에 동일한 에어플로우 환경이 세팅되어 있기 때문이다.
airflow tasks list UpdateSymbol
결과로 get_historical_prices, load 두 개가 나온다. 이것은 Task로 Decorate 했던 함수들의 이름이다.
Q. DAG를 airflow에 올리기전에 로컬환경에서 테스트 할 수 있나요?
A. 로컬 환경이 우분투인 경우를 제외하고 어렵다. 보통 터미널 두 개를 열어서 하나는 호스트 시스템의 dags에 들어가 코딩을 하고 하나는 에어플로우 스케줄러나 워커에 들어가 실행하는 방식으로 양쪽을 왔다갔다하며 테스트한다. 아니면 우분투 시스템을 개발 서버로 갖는게 제일 편함. 회사는 두 방법 사용
개발 시에는 왔다갔다 하며 코드로 하고 어느정도 완성이 되었다면, Airflow에서 DAG 활성화시키고 들어가보면 바로 실행이 되고 있다. 대그가 테이블에 레코드를 삽입하는 것이므로 테이블 이름 (keeyong)을 포스티코에 들어가서 확인

Yahoo Finance API DAG 작성 (2)
incremental update로 구현하는 방법
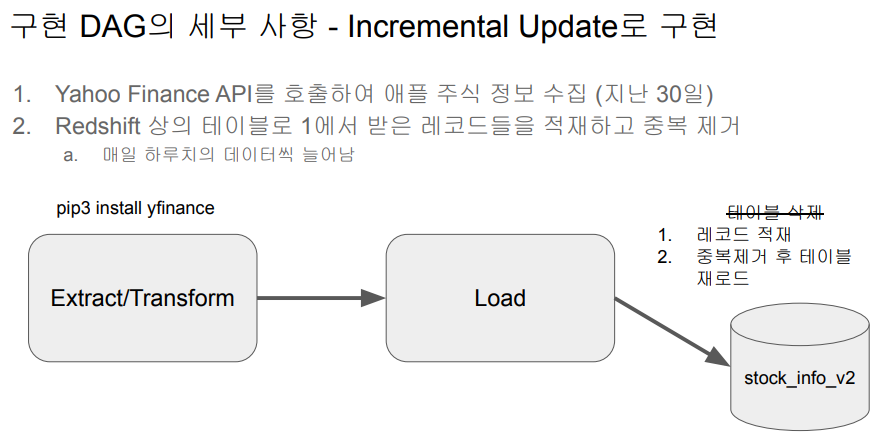
보통 incremental update는 하루에 한 번, 한 시간에 한 번 전날 전시간 것을 읽어오는 것인데, API는 시간을 기준으로 과거의 데이터를 읽어오는 것이 아니라 언제 API를 부르던 그 날로부터 지난 30일. 즉 과거로 돌아가서 과거 기준 지난 30일을 리턴해주는 함수가 아니다.
테이블에 로드할 때 테이블의 레코드를 삭제하고 들어가지 않고 중복만 제거하고 들어간다.
# load task
cur.execute(f"DROP TABLE IF EXISTS {schema}.{table};") #기존에 존재하던 테이블이 있으면 삭제하고 아니면 말기로드 시 테이블을 삭제하고 새로 만드는 과정으로 진행했었다. 그런데 테이블을 삭제하지 않고 insert를 할 것이다. 그러다보면 같은 날짜의 레코드가 두 번 반복되는 레코드가 발생할 것이다. 그런 경우 최근 날짜를 우선시하는 형태로 중복제거
Extract/Transform: Yahoo Finance API 호출
Yahoo Finance API를 호출하여 애플 주식 정보 수집하고 파싱
-> 기본적으로 지난 한달의 주식 가격을 리턴해준다.
load 부분. 즉, 업데이트 하는 부분이 달라진다.
Load: Redshift 테이블 업데이트 (1)
Incremental Update로 구현
- 임시 테이블 생성하면서 현재 테이블의 레코드를 복사 (CREATE TEMP TABLE … AS SELECT) : TEMP 테이블을 만들어 원본 데이터를 다 복제
- 임시 테이블 TEMP로 Yahoo Finance API로 읽어온 레코드를 적재
- 원본 테이블을 삭제하고 새로 생성
- 원본 테이블에 임시 테이블의 내용을 복사 (이 때 SELECT DISTINCT 를 사용하여 중복 제거)
-> 완벽하게 중복제거가 되지는 않는다. 대그가 시장이 끝난 뒤에 돌게 되면 SELECT DISTINCT 를 통해서 중복제거가 될텐데, API를 미국 주식 시장이 열려있는 동안 실행하면 종가가 그 시점의 가격이 종가로 나오게 된다.
Open 을 제외하고 High, Low, Close, Volume 등에 해당하는 데이터가 다 정확하지 않을 수 있다. 더 완벽하게 중복을 제거하는 방법은 다음 시간에...
트랜잭션 형태로 구성 (NameGender DAG와 동일)
# 앞선 코드에서 Load 부분만 변경되었다.
from airflow import DAG
from airflow.decorators import task
from airflow.providers.postgres.hooks.postgres import PostgresHook
from datetime import datetime
from pandas import Timestamp
import yfinance as yf
import pandas as pd
import logging
def get_Redshift_connection(autocommit=True):
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()
@task
def get_historical_prices(symbol):
ticket = yf.Ticker(symbol)
data = ticket.history()
records = []
for index, row in data.iterrows():
date = index.strftime('%Y-%m-%d %H:%M:%S')
records.append([date, row["Open"], row["High"], row["Low"], row["Close"], row["Volume"]])
return records
def _create_table(cur, schema, table, drop_first):
if drop_first:
cur.execute(f"DROP TABLE IF EXISTS {schema}.{table};")
cur.execute(f"""
CREATE TABLE IF NOT EXISTS {schema}.{table} (
date date,
"open" float,
high float,
low float,
close float,
volume bigint
);""")
@task
def load(schema, table, records):
logging.info("load started")
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;") #트랜잭션 열기
# 원본 테이블이 없으면 생성 - 테이블이 처음 한번 만들어질 때 필요한 코드
_create_table(cur, schema, table, False) #함수 호출, False -> 테이블이 없는 경우 테이블을 만든다. 두 번째 실행 시 이미 테이블이 만들어져 있기 때문에 테이블이 생기지 않고 밑의 과정이 아무것도 안된다.(?)
# 임시 테이블로 원본 테이블을 복사
cur.execute(f"CREATE TEMP TABLE t AS SELECT * FROM {schema}.{table};") #TEMP 테이블 생성하기, 원본 테이블의 내용을 읽어서 복제하기
for r in records: #TEMP 테이블 t에 방금 읽어온 주식 정보를 insert
sql = f"INSERT INTO t VALUES ('{r[0]}', {r[1]}, {r[2]}, {r[3]}, {r[4]}, {r[5]});" #t라는 테이블이 모든 정보를 갖고 있는데 중복된 날짜들이 있을 것이다. 중복제거를 하면서 원본 테이블에 복사하고 싶다. -> 두 가지 방법. 1. 원본 테이블을 DELETE 2. 원본 테이블을 DROP
print(sql)
cur.execute(sql)
# 원본 테이블 생성
_create_table(cur, schema, table, True) #True를 통해 원본 테이블을 DROP
# 임시 테이블 내용을 원본 테이블로 복사
cur.execute(f"INSERT INTO {schema}.{table} SELECT DISTINCT * FROM t;") #원본 테이블에 insert into하는데 distinct한 결과를 넣는다. 주식 시장이 열려있으면 DISTINCT로 깔끔하게 중복제거가 되지 못한다. ROW_NUMBER로 날짜 기준 파티션을 만들고, 각 레코드가 언제 업데이트 되었는지 시간을 별도로 기록해두고 그 시간 기준으로 내림차수 일련번호 붙이고 번호가 1번인 것만 가져오면 깔끔하게 중복을 처리할 수 있다. 이것을 하려면 업데이트 시간도 별도로 테이블에 기록해야 한다. 업데이트 시간을 기준으로 order by해야 하므로... 이것이 일반적으로 빅데이터 기반 데이터 웨어하우스에서 primary key로 중복 제거를 하는 방법, upsert라는 방법도 있음. 다음 시간에 진행
cur.execute("COMMIT;") # cur.execute("END;")
except Exception as error:
print(error)
cur.execute("ROLLBACK;")
raise
logging.info("load done")
with DAG(
dag_id = 'UpdateSymbol_v2',
start_date = datetime(2023,5,30),
catchup=False,
tags=['API'],
schedule = '0 10 * * *'
) as dag:
results = get_historical_prices("AAPL")
load("keeyong", "stock_info_v2", results)_create_table 함수 설명
def _create_table(cur, schema, table, drop_first):
if drop_first:
cur.execute(f"DROP TABLE IF EXISTS {schema}.{table};")
cur.execute(f"""
CREATE TABLE IF NOT EXISTS {schema}.{table} (
date date,
"open" float,
high float,
low float,
close float,
volume bigint
);""")4번째 인자 drop_first를 False로 두면 if문 부분을 실행하지 않는다. 즉, 아래 테이블이 없는 경우 만드는 것이고 True라면, 테이블을 삭제하고 새로 만드는 것.
IF NOT EXISTS {schema}.{table} 만약에 테이블이 없으면 load("keeyong", "stock_info_v2", results) -> stock_info_v2라는 테이블을 만든다.
숙제
- transaction 실습 따라하기
- Name Gender 실습 따라하기
- airflow.cfg 파일 : 에어플로우 환경설정 파일을 탐색하기
- DAGs 폴더는 어디에 지정되는가?
- DAGs 폴더에 새로운 Dag를 만들면 언제 실제로 Airflow 시스템에서 이를 알게
되나? 이 스캔 주기를 결정해주는 키의 이름이 무엇인가? - 이 파일에서 Airflow를 API 형태로 외부에서 조작하고 싶다면 어느 섹션을
변경해야하는가? - Variable에서 변수의 값이 encrypted가 되려면 변수의 이름에 어떤 단어들이
들어가야 하는데 이 단어들은 무엇일까? :) - 이 환경 설정 파일이 수정되었다면 이를 실제로 반영하기 위해서 해야 하는
일은? - Metadata DB의 내용을 암호화하는데 사용되는 키는 무엇인가
- 세계 나라 정보 API 사용 DAG 작성 (1)
- https://restcountries.com/에 가면 세부 사항을 찾을 수 있음
- 별도의 API Key가 필요없음
- https://restcountries.com/v3/all (API Endpoint)를 호출하여 나라별로 다양한 정보를 얻을 수
있음
{"name": {"common": "South Korea", "official": "Republic of Korea", …
"area": 100210.0,
"population": 51780579, …} JSON 형태를 Parsing해서 저장
Full Refresh로 구현해서 매번 국가 정보를 읽어오게 할 것! - API 결과에서 아래 3개의 정보를 추출하여 Redshift에 각자 스키마 밑에
테이블 생성
country -> [“name”][“official”]
population -> [“population”]
area -> [“area”] - 단 이 DAG는 UTC로 매주 토요일 오전 6시 30분에 실행되게 만들어볼 것!
프로덕션 DB의 테이블을 Redshift로 적재하는 것이 데엔의 첫 임무
