해당 글은 강의 노트로 체계화된 글은 다음을 참고해 주시기 바랍니다.
DAG 개념, 실습 / Airflow로 DAG 관리하기
Docker / Airflow 설치
데이터 파이프라인 (=ETL, 크게 보면 ELT)
- 데이터 생성, 수집, 변환, 저장 등 데이터의 이동 통로
- 데이터 프로세싱을 위해 실행하는 코드
- 데이터 프로세싱은 보통 Extract, Transform and Load로 구성되며 ETL이라고 칭한다.
cf) 아래 용어는 모두 동일한 의미를 지닌다.
-
Data Pipeline
-
ETL (엄밀히 말하면, 데이터 파이프라인이 ETL을 섭셋으로 포함한다.)
-
Data Workflow
-
DAG (Directed Acyclic Graph)
-
Airflow에서 데이터 파이프라인을 특별히 DAG라고 칭한다. (계속 실행하려면 에어플로우 계속 실행해야 한다?)
데이터 파이프라인은 다수의 Task로 구성이 되어있고, Task들 간의 실행 순서가 그래프 같은 모양으로 나타나며, 양방향이 아닌 단방향 (에어플로우는 루프가 생기는 것을 허용하지 않는다. 계속해서 돌리고 싶다면 에어플로우를 짧은 주기로 실행해주면 된다.)
-
ETL vs ELT
- ETL: 데이터를 데이터 웨어하우스 외부에서 내부로 가져오는 프로세스- ELT: 데이터 웨어하우스 내부 데이터를 조작해서 (보통은 좀 더 추상화되고 요약된) 새로운 데이터를 만드는 프로세스 / 실제로는 개념이다. 구현은 ETL로 이루어진다.
-
이 경우 데이터 레이크를 쓰기도 함
-
이런 프로세스 전용 기술들이 있으며 dbt가 가장 유명: Analytics Engineering
데이터 레이크, 웨어하우스
서포트하는 데이터의 크기가 다르다는 점이 큰 차이점
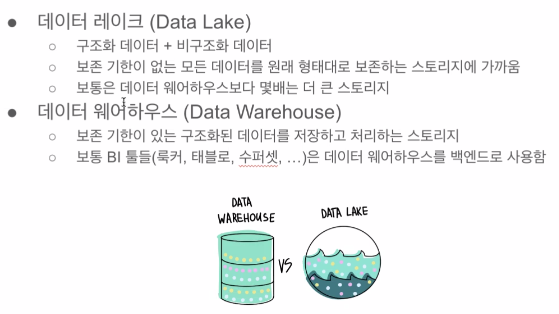
데이터 웨어하우스
- 상대적으로 작다.
- 스토리지 고비용.
- 처리 속도가 빠르다.
- 비구조화된 데이터 처리 불가.
데이터 레이크
- 스토리지
- 스케일러빌리티가 있다.
- 저비용
- 온갖 데이터를 던져 넣는다. 비구조화 데이터 예) 로그 데이터, 웹 서버 로그, 사용자 이벤트 로그 등 큰 데이터 <- 데이터 웨어하우스에 적재할 경우 고비용, 비구조화된 데이터이기에 데이터 웨어하우스에서 SQL로 처리하기 어렵다.
- 주기적으로 필요한 데이터를 프로세싱하여 웨어하우스에 로딩해서 쓴다.
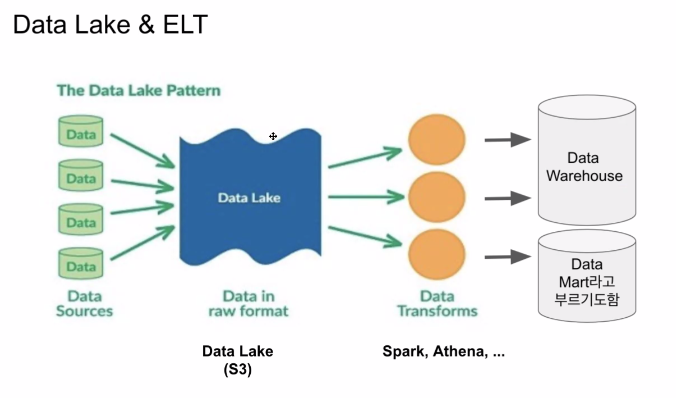
elt는 작게 보면 데이터 웨어하우스 내에서 재가공, 크게 보면 데이터 레이크(우리 시스템이므로)에서 재가공해서 데이터 레이크 혹은 마트에 저장하는 것도 elt로 볼 수 있다.
elt는 기본적으로 우리 시스템 안에 들어온 데이터를 재가공하는 것. 그 시스템의 범위를 데이터 웨어하우스로 제약을 할 것인가 OR 전체 데이터 시스템으로 확장할 것인가에 따라 그 의미가 달라진다.
대부분의 회사들은 AWS를 사용한다고 하면, S3를 데이터 레이크로 사용한다. 스케일하고, 저비용, 편하게 비구조화된 데이터 정의 용도, 비구조+구조 experation 걱정X, 백업 같은 느낌도
데이터 파이프라인 다시!
- 데이터를 소스로부터 목적지로 복사하는 작업
- 이 작업은 보통 코딩 (파이썬 혹은 스칼라) 혹은 SQL을 통해 이뤄짐
- 대부분의 경우 목적지는 데이터 웨어하우스가 됨
- 데이터 소스의 예:
Click stream, call data, ads performance data, transactions, sensor data, metadata, …
More concrete examples: production databases, log files, API, stream data (Kafka topic) - 데이터 목적지의 예:
데이터 웨어하우스, 캐시 시스템 (Redis, Memcache), 프로덕션 데이터베이스, NoSQL, S3
소스가 외부 데이터 시스템, ELT의 경우 데이터 웨어하우스 내부, 데이터 레이크 S3의 파일, 외부 등이 될 수 있다.
목적지의 경우 대부분 웨어하우스가 된다. 데이터 레이크 S3, 외부 시스템 등이 될 수도 있다. 로그 파일을 복사하는 데이터 파이프라인이라면/ETL이라면 데이터 레이크가 목적지가 될 것이다.
데이터 파이프라인 종류
Raw Data ETL Jobs
1. 외부와 내부 데이터 소스에서 데이터를 읽어다가 (많은 경우 API를 통하게 됨)
2. 적당한 데이터 포맷 변환 후 (데이터의 크기가 커지면 Spark등이 필요해짐)
3. 데이터 웨어하우스 로드
이 작업은 보통 데이터 엔지니어가 함
이런 job의 스케줄링에 Airflow 사용
Summary/Report Jobs (ELT)
1. DW(혹은 DL)로부터 데이터를 읽어 다시 DW or DL에 쓰는 ETL (이것을 ELT라고 많이 칭한다.)
2. Raw Data를 읽어서 일종의 리포트 형태나 써머리 형태의 테이블을 다시
만드는 용도
3. 특수한 형태로는 AB 테스트 결과를 분석하는 데이터 파이프라인도 존재
요약 테이블의 경우 SQL (CTAS를 통해) 만으로 만들고 이는 데이터 분석가가 하는 것이 맞음. 이때, CTAS에는 테스트 과정을 붙일 수 없다. 앞에 코딩을 해서 입력 테이블, 출력 테이블에 대해 우리가 원하는 상황인지 아닌지 체크해야 한다. 이런 것을 Built-in으로 사용할 수 있는 툴이 DBT
데이터 엔지니어 관점에서는 어떻게 데이터 분석가들이 편하게 할 수 있는 환경을 만들어 주느냐가 관건
-> Analytics Engineer (DBT)
Production Data Jobs : 새 정보를 데이터 시스템 바깥에
1. DW로부터 데이터를 읽어 다른 Storage(많은 경우 프로덕션 환경)로 쓰는 ETL
a. 써머리 정보가 프로덕션 환경에서 성능 이유로 필요한 경우
b. 혹은 머신러닝 모델에서 필요한 피쳐들을 미리 계산해두는 경우
2. 이 경우 흔한 타켓 스토리지:
a. Cassandra/HBase/DynamoDB와 같은 NoSQL
b. MySQL과 같은 관계형 데이터베이스 (OLTP)
c. Redis/Memcache와 같은 캐시
d. ElasticSearch와 같은 검색엔진
매 방문마다 실시간으로 별점을 계산하려고 하면 로드가 많이 걸린다.
별점 정보들은 여러 서버에 보통 나뉘어 있으므로
-> 실시간 계산이 아닌, 데이터 웨어하우스에서 매시간 계산해서 MYSQL의 특정 테이블로 푸시할테니 강의별 학생 수, 평점 등 계산하지 말고 푸시된 정보를 읽어와라.
계산을 할 경우 다음과 같은 쿼리가 돌아야 한다.
-- 강의별 수강생수, 리뷰수, 평점
SELECT c.courseid, COUNT(DISTINCT cr.studentid) “수강생수",
COUNT(DISTINCT cr.reviewid) “리뷰수",
AVG(cr.rating) “평점"
FROM course c
LEFT JOIN course_review cr ON c.courseid = cr.courseid
GROUP BY 1;-> 특정 course에 대해 사용자를 다 가져와서 group by 연산을 하는 것. 계산량이 많으므로 실시간으로 돌리지 않고 결과를 production DB에 넣는다면 백엔드 엔지니어들이 course id로 lookup(select where)로 불러온다. join, group by 등이 불필요
ETL 작성


Airflow
-
Airflow는 파이썬으로 작성된 데이터 파이프라인 (ETL) 프레임웍
- Airbnb에서 시작한 아파치 오픈소스 프로젝트
- 가장 많이 사용되는 데이터 파이프라인 관리/작성 프레임웍
-
데이터 파이프라인 스케줄링 지원
- 정해진 시간에 ETL 실행 혹은 한 ETL의 실행이 끝나면 다음 ETL 실행
- 웹 UI를 제공하기도 함
-
데이터 파이프라인(ETL)을 쉽게 만들 수 있도록 해줌
- 다양한 데이터 소스와 데이터 웨어하우스를 쉽게 통합해주는 모듈 제공 : https://airflow.apache.org/docs/
- 데이터 파이프라인 관리 관련 다양한 기능을 제공해줌: 특히 Backfill -
Airflow에서는 데이터 파이프라인을 DAG(Directed Acyclic Graph)라고 부름
- 하나의 DAG는 하나 이상의 태스크로 구성됨
- 2020년 12월에 Airflow 2.0이 릴리스됨 -
Airflow 버전 선택 방법: 큰 회사에서 사용하는 버전이 무엇인지 확인.
- https://cloud.google.com/composer/docs/concepts/versioning/composer-versions
코딩 관점에서 에어플로우가 가진 장점은 backfill을 쉽게 해준다는 것. 즉, incremental 중 에러 발생 시점을 기록하고 그 시점으로 돌아가서 그 당시의 날짜, 시간을 갖고 다시 실행할 수 있게 해준다.
airflow : etl 파이프라인 작성 - 관리 - 운영 프레임워크 / 에러 발생 시 슬랙과 연동해 바로 알고 incremental update를 하는 dag라면, 데이터 파이프라인이라면 에러 시점으로 돌아가 재실행을 해주는
-> 코딩을 잘 했을 때 가능한 기능
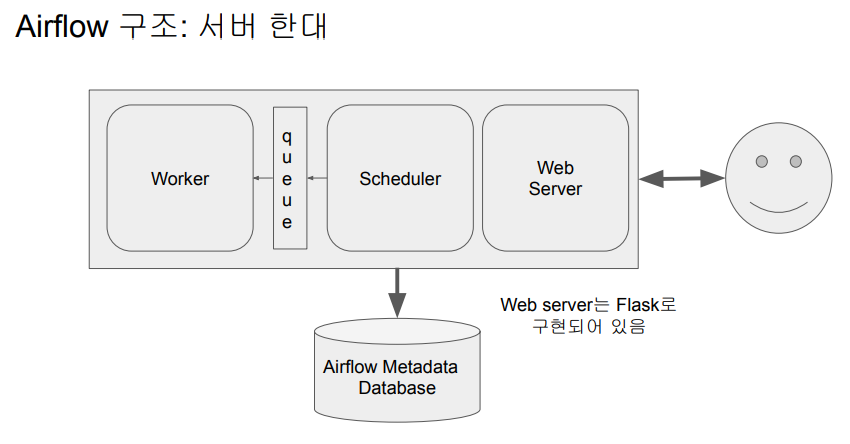
airflow 구성
- Web Server
- Scheduler
- Worker : 실제 데이터 파이프라인 코드를 실행해주는
- Database (Sqlite가 기본으로 설치됨) -> postgresql을 쓸 예정
- Queue (기본적으로는 멀티노드 구성인 경우에만 사용됨) : 워커가 다수의 서버로 구성되어 있을 때
a. 이 경우 Executor가 달라짐 (CeleryExecuter, KubernetesExecutor)
워커 수를 늘리는 형태로 스케일업을 하게 된다.
dag 즉, 데이터 파이프라인이 많을 경우 워커 수를 늘리거나, 에어 플로우 사양을 높이는 형태로 간다.
에어플로우는 python으로 작성되므로 웹 서버가 플라스크로 작성
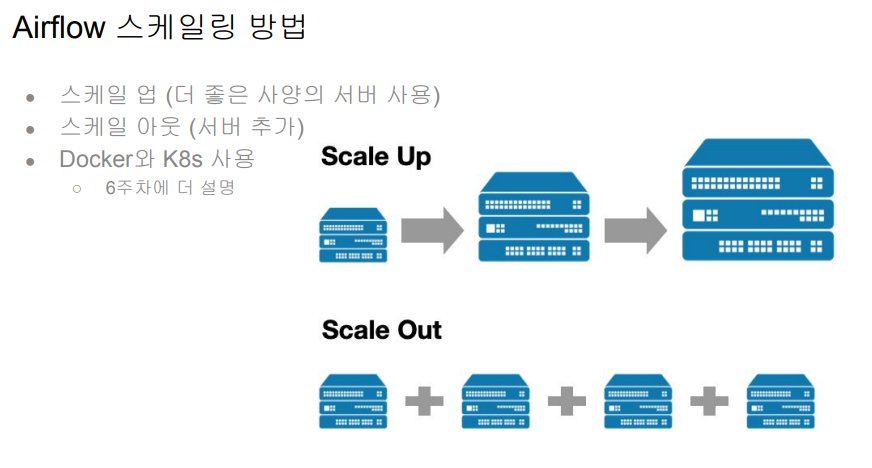
한 대로 최대한 버티는 것이 초반에는 가장 좋은 방법이다.
서버 수를 늘릴 때는 쿠버네티스를 사용하는 경우가 많다.
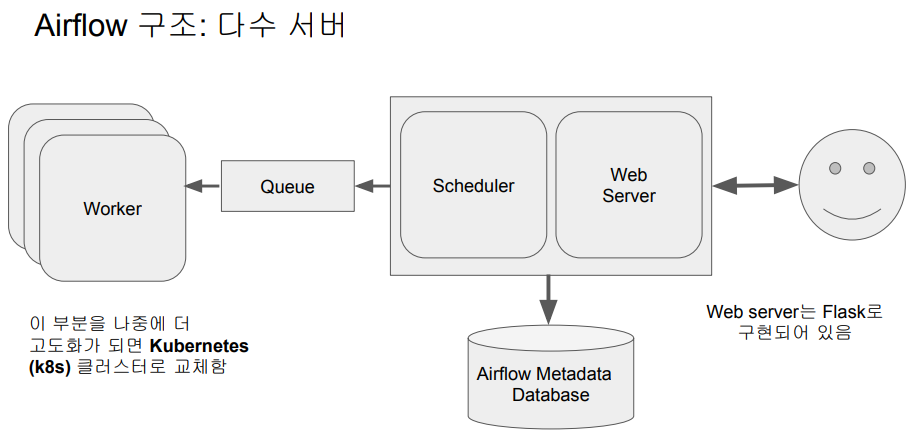
워커 전용 노드, 서버를 할당한다.
스케줄러, 웹서버, 디비는 마스터 노드에 남고,
워커들은 슬레이브가 되는 것
대그들을 스케줄러가 스케줄을 하면 큐에 쌓이고 워커들이 큐에서 할 일들을 받아와 실행하고 결과를 디비에 저장하고 다음 실행할 것이 있는지 본다.
워커들 즉 서버들 수가 증가하면 유지보수 비용이 증가한다.
서버를 전용으로 할당하면 항상 바쁘지는 않다. 즉 워커를 쿠버네티스 컨테이너 플랫폼으로 변환 -> 에어플로우 전용 서버를 할당하는 것이 아니라 공용 서버 플랫폼을 두고 빌려서 대그 하나를 실행할 리소스를 마련한다. -> 서비스별로 전용서버를 운영할 필요가 없어진다. 모든 서비스들이 쿠버네티스 내에서 필요한 자원 받아서 쓰고 리턴하고~ -> devops 팀의 업무가 줄어듦
데엔으로서 도커, 쿠버네티스가 무엇인지 아는 것이 중요하다. 쿠버네티스는 복잡한 기술이라서 언젠가는 알 필요가 있다. 그러나 취준생, 주니어라면 컨셉정도, 시니어가 사용하는 모습 보기 정도
Airflow
● 장점
○ 데이터 파이프라인을 세밀하게 제어 가능
○ 다양한 데이터 소스와 데이터 웨어하우스를 지원
○ 백필(Backfill)이 쉬움
● 단점
○ 배우기가 쉽지 않음
○ 상대적으로 개발환경을 구성하기가 쉽지 않음
○ 직접 운영이 쉽지 않음. 클라우드 버전 사용이 선호됨
■ GCP provides “Cloud Composer”
■ AWS provides “Managed Workflows for Apache Airflow”
■ Azure provides “Azure Data Factory Managed Airflow
오픈소스 커뮤니티이다보니 쉽게 쓸 수 있는 파이썬 모듈들이 있다. 로우 코딩으로 할 수 있는 기능이 많다.
DAG란?
Directed Acyclic Graph의 줄임말
● Airflow에서 ETL을 부르는 명칭
● DAG는 태스크로 구성됨
○ 예를 3개의 태스크로 구성된다면 Extract, Transform, Load로 구성
● 태스크란? - Airflow의 오퍼레이터(Operator)로 만들어짐
○ Airflow에서 이미 다양한 종류의 오퍼레이터를 제공함
○ 경우에 맞게 사용 오퍼레이터를 결정하거나 필요하다면 직접 개발
○ e.g., Redshift writing, Postgres query, S3 Read/Write, Hive query, Spark job, shell script
대그 프로그래밍은 하려는 일에 해당하는 오퍼레이터를 가져다 쓰거나, 오퍼레이터가 없다면 오퍼레이터 코드를 내가 짜는 것. 모든 일을 파이썬
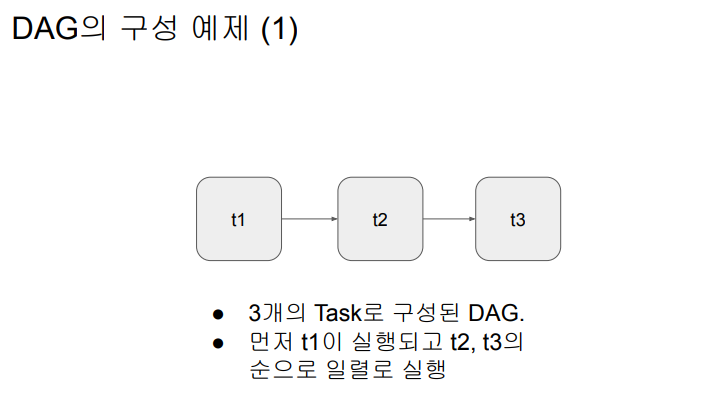
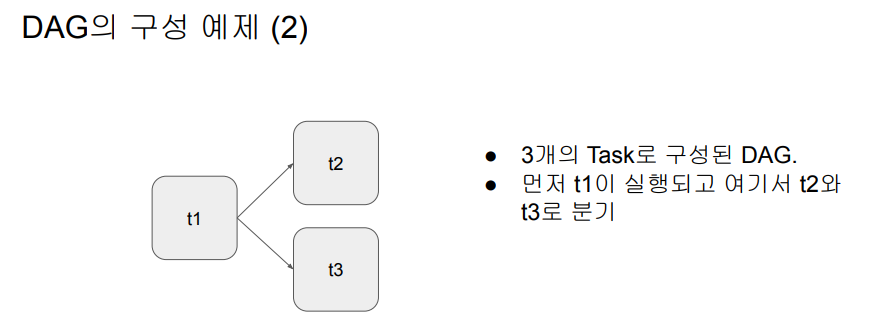
방향성이 있는 그래프, 루프 불가

email : 에러 발생 시 누구에게 이메일을 보낼지 결정하고
retries : 에러 발생 시 몇 번 리트라이
retry_delay : 리트라이 간 기다릴 시간
-> 파이썬 딕셔너리 형태로 세팅을 만든다.
대그 오브젝트 만들기 : 데이터 파이프라인 만들기

- 인자
dag 이름
스케줄 매일 9시 0분에 실행되는 대그 타임존은 UTC
속성 지정했던 것을 전달

- 0분 아무때나 -> 0분은 매 시간마다 1번만 생긴다. 따라서, hourly dag
- 12시 0분 -> 하루에 1번 daily dag
- 매주 일요일 6시 30분에 실행하는 weekly dag
모든 task는 operator이다.
Operators Creation Example 1
from airflow.operators.bash import BashOperator
t1 = BashOperator(
task_id='print_date',
bash_command='date',
dag=test_dag)
t2 = BashOperator(
task_id='sleep',
bash_command='sleep 5',
retries=3,
dag=test_dag)
t3 = BashOperator(
task_id='ls',
bash_command='ls /tmp',
dag=test_dag)bash는 unix의 command line cell이다.
명령어를 command line에 입력해 실행하고 싶으면 airflow가 만들어준 bash operator를 불러오면 된다. bash operator를 통해 task를 만든다.
- 각 Task의 실행 순서
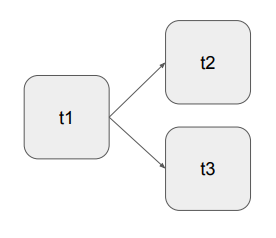
t1 >> t2
t1 >> t3
=> t1 >> [t2, t3]
# 일반적으로 사용하지는 않는 표현
t2.set_upstream(t1) # t2의 상류로 t1을 세팅
t3.set_upstream(t1) # t3의 상류로 t1을 세팅bash operator는 bash라는 cell script를 실행, 실행해주는 커멘드를 bash command라는 파라미터에 적어준다.
bash_command='date' : 날짜를 출력한다.
bash_command='sleep 5' : 5초 동안 아무 동작을 하지 않는다.
bash_command='ls /tmp' : tmp 디렉터리의 내용을 출력해라.
dag=test_dag : 이 Task가 속한 대그가 무엇인지 대그 이름을 적어라.
-> HelloWorld라는 Dag에는 3개의 Task(print_date, sleep, ls)가 속한다.
Operators Creation Example 2
from airflow.operators.bash_operator import BashOperator
from airflow.operators.dummy_operator import DummyOperator
start = DummyOperator(dag=dag, task_id="start", *args, **kwargs)
t1 = BashOperator(
task_id='ls1',
bash_command='ls /tmp/downloaded',
retries=3,
dag=dag)
t2 = BashOperator(
task_id='ls2',
bash_command='ls /tmp/downloaded',
dag=dag)
end = DummyOperator(dag=dag, task_id='end', *args, **kwargs)DummyOperator : 아무것도 하지 않는다. 뒤에 많은 수의 Task를 동시에 실행하면 가장 먼저 수행되는 Task가 무엇인지 알기 어렵기 때문에 시작시간과 마지막 시간을 마킹하는 의미 정도로 쓰인다.
start, end를 통해 dag의 시작, 마지막 시간을 정확히 알 수 있게 된다. 생략 가능
ls1, ls2 두 개의 Task 모두 tmp 밑에 downloaded 폴더의 내용을 찍어본다.
- 각 테스크의 실행 순서
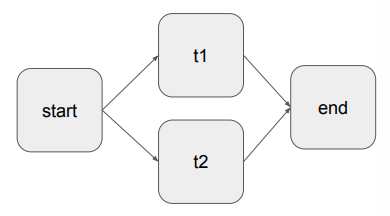
start >> t1 >> end
start >> t2 >> end
start >> [t1, t2] >> end
데이터 파이프라인 생성 시 고려할 점
이상과 현실간의 괴리
- 이상 혹은 환상
- 내가 만든 데이터 파이프라인은 문제 없이 동작할 것이다.
- 내가 만든 데이터 파이프라인을 관리하는 것은 어렵지 않을 것이다.
- 현실 혹은 실상
- 데이터 파이프라인은 많은 이유로 실패함
- 버그
- 데이터 소스상의 이슈 : What if data sources are not available or change its data format -> 내가 컨트롤할 수 없는 경우, ex) facebook 광고 api 고쳐질 때까지 기다려야 한다.
- 데이터 파이프라인들 간의 의존도 이해 부족 -> 데이터 파이프라인의 테이블명, 컬럼명 등을 임의로 바꾸는 것이 주니어 데엔의 많은 실수 중 하나 (이를 해결하기 위해 데이터 디스커버리, 데이터 카탈로그 등을 만들어낸다.)
- 데이터 파이프라인의 수가 늘어나면 유지보수 비용이 기하급수적으로 늘어남
- 데이터 소스간의 의존도가 생기면서 이는 더 복잡해짐. 만일 마케팅 채널 정보가 업데이트되지 않는다면 마케팅 관련 다른 모든 정보들이 갱신되지 않음.
- More tables needs to be managed (source of truth, search cost, …)
Best Practices (1)
- 가능하면 데이터가 작을 경우 매번 통채로 복사해서 테이블을 만들기 (Full
Refresh) - Incremental update만이 가능하다면, 대상 데이터소스가 갖춰야할 몇 가지
조건이 있음
- 데이터 소스가 프로덕션 데이터베이스 테이블이라면 다음 필드가 필요: created (데이터 업데이트 관점에서 필요하지는 않음) / modified / deleted
- 데이터 소스가 API라면 특정 날짜를 기준으로 새로 생성되거나 업데이트된 레코드들을
읽어올 수 있어야함
incremental update만 가능하다면, 업데이트를 매일 하고 싶은데 하루가 걸리는 경우... 그런데 이것도 바뀐 부분만 전달받을 수 있을 때 가능하다. 어떤 경우에는 incremental 을 소스에서 지원하지 못할 경우 불가능할 수 있다.
Best Practices (2)
- 멱등성(Idempotency)을 보장하는 것이 중요
- 멱등성은 무엇인가?
- 동일한 입력 데이터로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용이 달라지지
말아야함
- 예를 들면 중복 데이터가 생기지 말아야함, 데이터가 부족해도 안된다.
Best Practices (3)
- 실패한 데이터 파이프라인의 재실행이 쉬워야 한다.
- 과거 데이터를 다시 채우는 과정 (backfill) 이 쉬워야 한다. -> full refresh는 쉽다. incremental update일 때 문제
- Airflow는 이 부분(특히, backfill)에 강점을 갖고 있다.
- DAG의 catchup 파라미터가 True가 되어야하고 start_date, end_date가 적절하게 설정되어야 한다.
- 대상 테이블이 incremental update가 되는 경우에만 의미가 있다.
- execution_date 파랄미터를 사용해서 업데이트되는 날짜 혹은 시간을 알아내도록 코드를 작성해야 한다. - 현재 시간을 기준으로 업데이트 대상을 선택하는 것은 안티 패턴
Best Practices (4)
- 데이터 파이프라인의 입출력을 명확히 하고 문서화 (ex: 데이터를 누가 요청했는지) : 데이터 디스커버리 문제 -> 데이터 디스커버리, 카탈로그 등이 셋업되면 자동으로 검색할 수 있는 기능도 있다.
- 주기적으로 쓸모없는 데이터들을 삭제
- Kill unused tables and data pipelines proactively
- Retain only necessary data in DW and move past data to DL(or strage)
맥스는 바다보이는 곳에서 데이터 팀 전원이 안쓰는 테이블 정리하는 시간을 가졌다고 함.
테이블 관리 안할경우 새로 들어온 인력이 어떤 테이블을 사용해야 할지 몰라서 새 테이블을 만든다. 더 복잡해짐
Best Practices (5)
- 데이터 파이프라인 사고시 마다 사고 리포트(post-mortem) 쓰기
- 목적은 동일한 혹은 아주 비슷한 사고가 또 발생하는 것을 막기 위함
- 중요 데이터 파이프라인의 입력과 출력을 체크하기
- 아주 간단하게 입력 레코드의 수와 출력 레코드의 수가 몇개인지 체크하는 것부터 시작
- 써머리 테이블을 만들어내고 Primary key가 존재한다면 Primary key uniqueness가
보장되는지 체크하는 것이 필요함
- 중복 레코드 체크
DBT를 사용하면 ELT를 관한 한은 이런 류의 체크를 최소한의 코드로 확인할 수 있다.
Backfill
Full Refresh vs. Incremental Update
- Full Refresh: 매번 소스의 내용을 다 읽어오는 방식
- 효율성이 떨어질 수 있지만 간단하고 소스 데이터에 문제가 생겨도 다시 다 읽어오기에 유지보수가 쉽다.
- 데이터가 커지면 사용 불가
- Incremental Update : 변경된 부분만 읽어오는 방식
- 효율성이 좋지만 복잡, 유지보수가 힘들어진다. (실패한 부분으로 돌아가서 재실행해야 하는데 내가 작성한 코드가 아닐 경우, 내가 작성한 오랜 코드인 경우, 늦은 밤이나 주말같은 압박이 있는 상황에서 이런 실수가 발생하기 쉽다.)
- 보통 daily나 hourly로 동작해서 그 전 시간 혹은 그 전 날 데이터를 읽어오는 형태로 동작

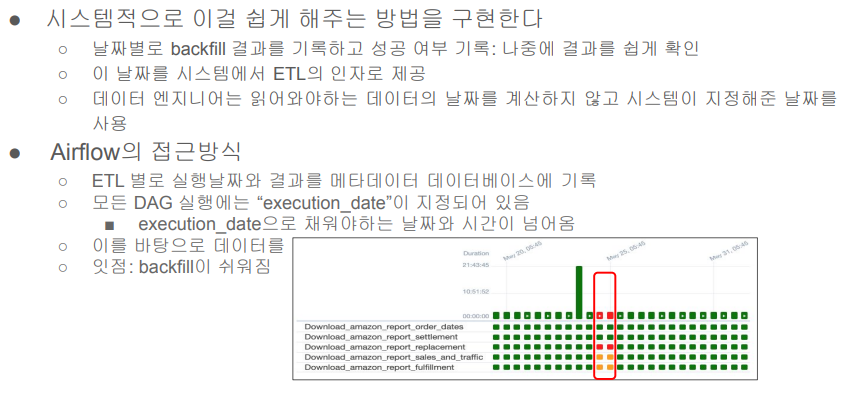
5개의 Task 존재, airflow는 실패한 테스크와 날짜를 확인할 수 있고 소스의 에러가 해결이 되고 실패한 부분 클릭해서 재실행 할 수도 있다.
airflow에서 backfill 쉽기 위한 전제
- incremental job인가, incremental update를 할 때만 backfill 이슈가 있다.
- airflow에서 언제 데이터를 읽어와야 하는지 정보를 읽어와서 업데이트를 하고 있는지, 그 정보를 이용하지 않는 경우 의미X
이제부터 할 이야기는 Incremental Update시에만 의미가 있음
- 다시 한번 가능하면 Full Refresh를 사용하는 것이 좋음 : 문제가 생겨도 다시 실행하면 됨
- Incremental Update는 효율성이 더 좋을 수 있지만 운영/유지보수의 난이도가
올라감
- 실수등으로 데이터가 빠지는 일이 생길 수 있음
- 과거 데이터를 다시 다 읽어와야하는 경우 다시 모두 재실행을 해주어야함
Backfill의 용이성 여부 -> 데이터 엔지니어 삶에 직접적인 영향!
- Backfill의 정의
: 실패한 데이터 파이프라인을 재실행 혹은 읽어온 데이터들의 문제로 다시 다 읽어와야하는
경우를 의미 - Backfill 해결은 Incremental Update에서 복잡해짐, Full Refresh에서는 간단. 그냥 다시 실행하면 됨
- 즉 실패한 데이터 파이프라인의 재실행이 얼마나 용이한 구조인가? -> 이게 잘 디자인된 것이 바로 Airflow
보통 Daily DAG를 작성한다고 하면 어떻게 할까?
지금 시간을 기준으로 어제 날짜를 계산하고 그 날짜에 해당하는 데이터를
읽어옴
# backfill을 고려하지 않은 코드
from datetime import datetime, timedelta
# 지금 시간 기준으로 어제 날짜를 계산
y = datetime.now() - timedelta(1)
yesterday = datetime.strftime(y, '%Y-%m-%d')
# yesterday에 해당하는 데이터를 소스에서 읽어옴
# 예를 들어 프로덕션 DB의 특정 테이블에서 읽어온다면
sql = f"SELECT * FROM table WHERE DATE(ts) = '{yesterday}'"예를 들어 Production DB에 있는 데이터를 incremental update 하는 데이터 파이프라인이라면, Production DB에 다음 SQL문을 보낸다. sql = f"SELECT * FROM table WHERE DATE(ts) = '{yesterday}'"
변경이나 추가된 레코드의 날짜가 ts라는 필드에 들어가 있다면, 그 날짜가 어제 날짜인 레코드들만 읽어오도록 한다.
-> 과거 데이터가 잘못 들어간 것이 확인된 경우
그런데 지난 1년치 데이터를 Backfill 해야한다면?
- 기존 ETL 코드를 조금 수정해서 지난 1년치 데이터에 대해 돌린다
- 실수하기 쉽고 수정하는데 시간이 걸림
from datetime import datetime, timedelta
# y = datetime.now() - timedelta(1)
# yesterday = datetime.strftime(y, '%Y-%m-%d')
yesterday = '2023-01-01'
# yesterday에 해당하는 데이터를 소스에서 읽어옴
# 예를 들어 프로덕션 DB의 특정 테이블에서 읽어온다면
sql = f"SELECT * FROM table WHERE DATE(ts) = '{yesterday}'"2023년 1월 데이터가 잘못 들어간 경우 -> yesterday 코드를 하드코딩으로 수정한 후 다시 돌려야 한다. 이렇게 수정해야 하는 코드가 여기저기 숨어있는 경우가 많다.
So, 운영하는 것만 생각하고 코드를 작성한다면, 나중에 Backfill 시 어려움, 어디를 고쳐야 할지, 실수 또 발생
-> airflow 만들어진 배경
어떻게 ETL을 구현해놓으면 이런 일이 편해질까?
어느 시간에 읽어와야 하는지 y = datetime.now() - timedelta(1)로 계산하는 것이 아니고, 하드코딩 yesterday = '2023-01-01' 하는 것도 아닌, 에어플로우가 넘겨주는 변수값을 읽어서 기계적으로 그 날짜, 시간을 읽어오게 코드를 짜면 운영, backfill에 문제가 없어진다. 이 정보를 execution date라고 한다. 에어플로우는 모든 DAG의 실행 시점을 기록해놓기 때문에 backfill이 가능하다.
Airflow 설치 - 도커 사용
- 도커 엔진 설치
- Airflow 설치
- Airflow 도커 이미지 다운로드- Airflow 도커 컨테이너 실행
- Airflow 웹 UI 접근
도커 : 소프트웨어를 하나의 분리된 패키지로 만들어주는 것, 소프트웨어를 다른 환경과 완전히 분리된 가상의 컴퓨터처럼 분리된 환경을 만들어주는 것.
도커 이미지 : 소프트웨어 패키지
도커 컨테이너 : 도커 이미지를 실행하는 환경
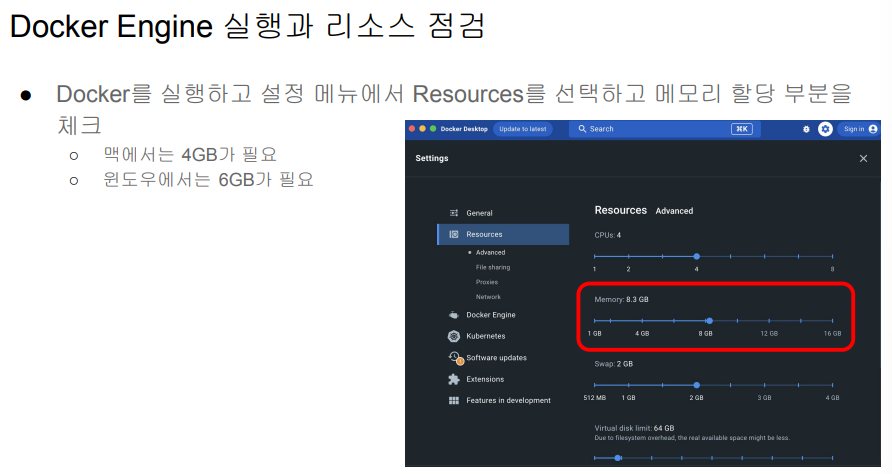
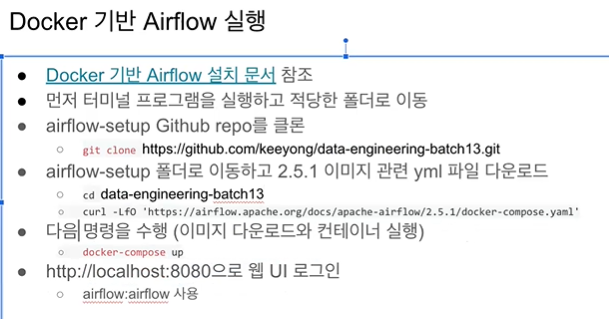
- Windows 터미널에서 원하는 폴더로 이동 (cd 원하는 폴더 경로)
- git clone https://github.com/keeyong/data-engineering-batch13.git 실행
- 폴더 확인해보면 github에 있던 폴더가 복사되어 있음을 확인할 수 있다.
- cd data-engineering-batch13 이동
5.curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.5.1/docker-compose.yaml' -> 특정 버전의 Airflow에서 Docker로 실행해주는 명령들 다운받기
※ windows의 경우 -LfO에서 에러가 발생한다. 아래의 방법으로 진행하자.
- 링크를 우클릭
- 다른 이름으로 링크 저장
- airflow-setup 폴더에 저장
컨테이너 생성
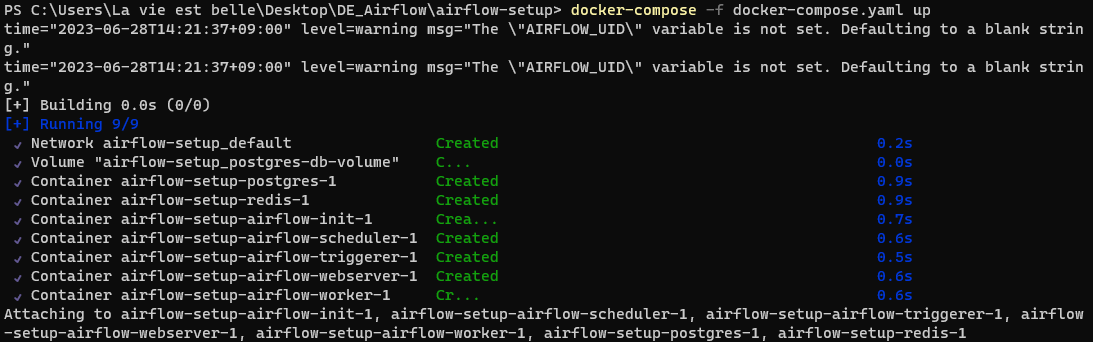
airflow-worker, airflow-webserver등의 이미지 설치, 그리고 이것들이 사용하는 큐로 redis, airflow 정보가 저장되는 postgres 등 설치
위와 같은 모듈들을 일일이 설치하지 않고 도커 컨테이너가 자동으로 설정해준다.
모듈들이 도커 엔진으로 실행된다. (도커 : 컴퓨터 위에 컴퓨터 <- 예전에 VM가상머신으로 이러한 기능을 사용했지만 굉장히 무겁다. 그에 반해 도커는 호스트 컴퓨터 위에 경량화된 형태로 프로그램들을 실행한다.)
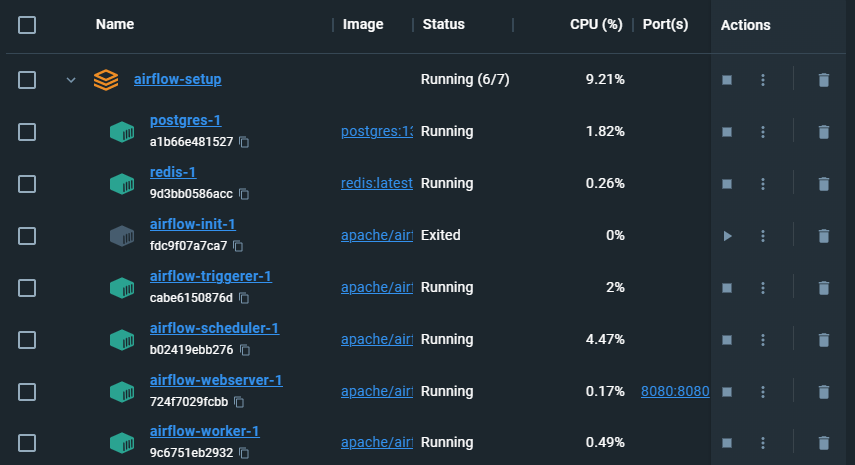
7개의 컨테이너가 돌고 있음을 볼 수 있다.
init은 초기화해주는 컨테이너로 한 번 실행 후 exit된 상태이다.
포트 번호 8080에 걸려있으므로 해당 주소로 접속하면 airflow를 웹 UI로 사용할 수 있다.
airflow docker 이미지는 자신이 실행된 폴더에 있는 dags 폴더를 찾아서 그 안에 dag들을 자동으로 웹 UI에 올려주는 형태로 동작한다.

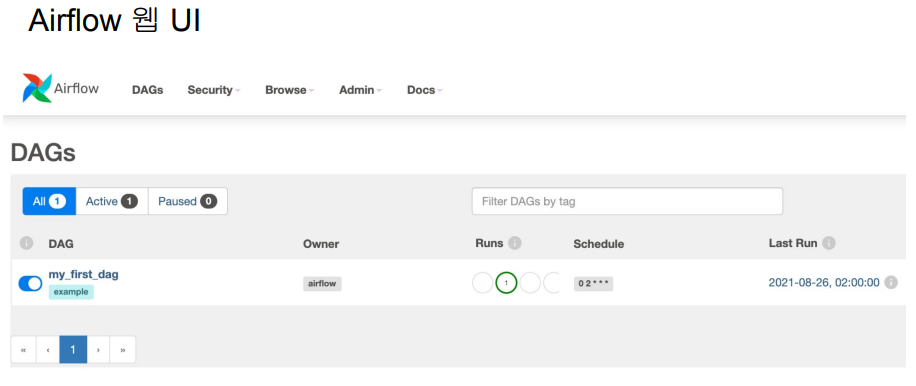
dags 폴더 내에 있던 HelloWorld, HelloWorld_v2 대그를 볼 수 있다.
-> 개발할 때 dags 폴더 내에서 개발하면 airflow 인터페이스에서 바로 반영이 될 것이다.
Airflow에서 DAG 알아보기
-
HelloWorld 대그를 실행하고 싶을 경우 활성화한다.

-
DAG를 클릭해서 세부단계로 들어간다.
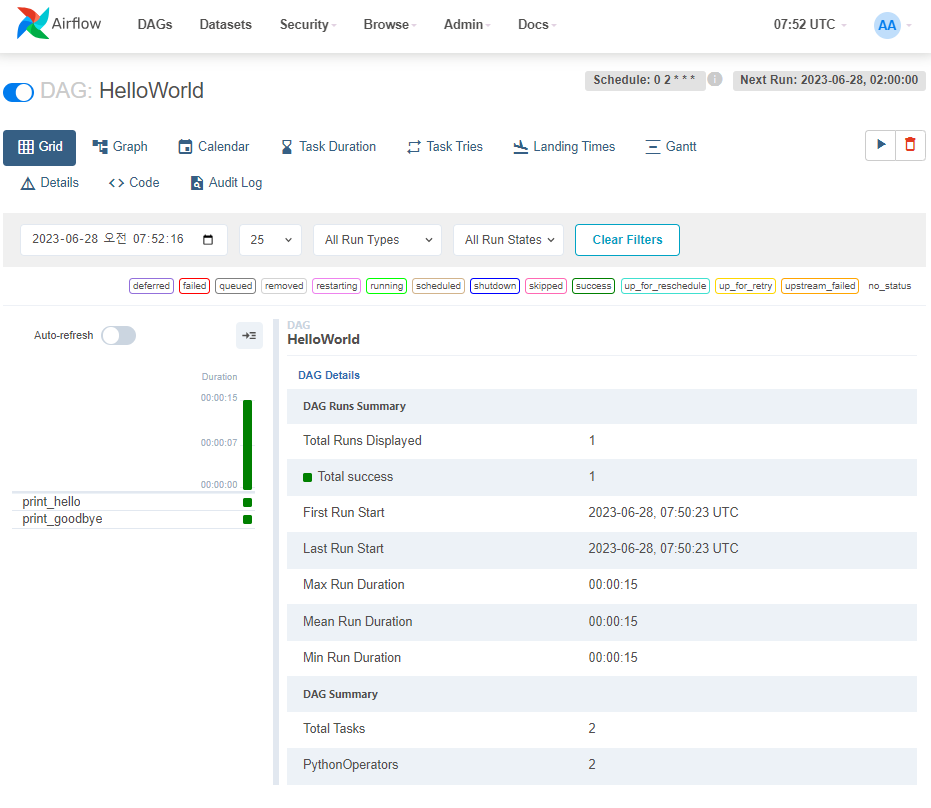 이 DAG는 2개의 Task (print_hello, print_goodbye)가 있다.
이 DAG는 2개의 Task (print_hello, print_goodbye)가 있다.
-
print_hello 구성 살펴보기
print_hello 클릭 -> Log 클릭
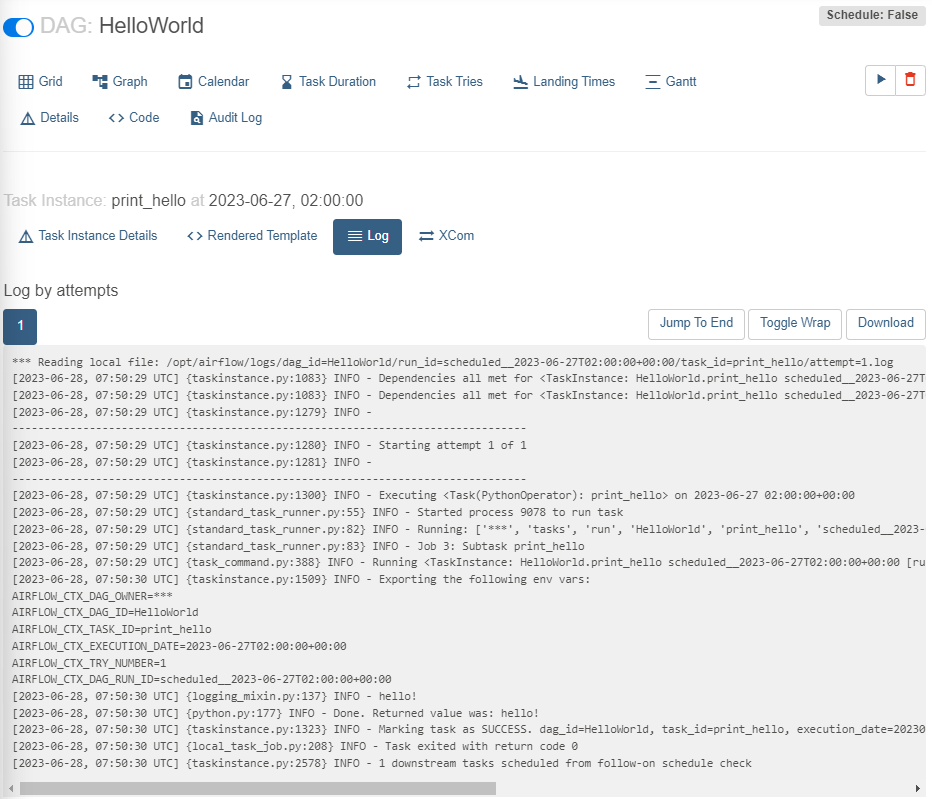 중간 INFO - hello! 부분 -> 해당 Task의 기능은 hello!를 print하는 것
중간 INFO - hello! 부분 -> 해당 Task의 기능은 hello!를 print하는 것
execution data가 incremental update시 읽어와야 할 데이터의 날짜 정보
-
DAG 내부의 실행관계를 알고싶다면 상단 Graph 클릭
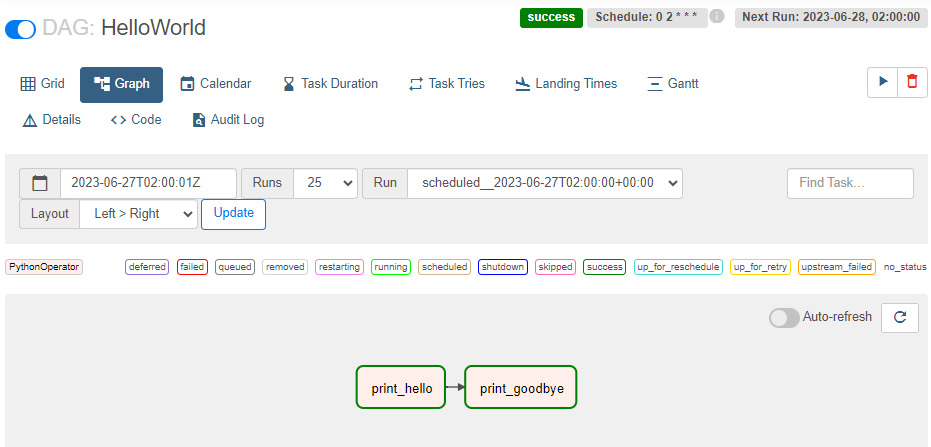 print_hello가 끝나면 print_goodbye를 실행하라.
print_hello가 끝나면 print_goodbye를 실행하라.
-
상단 메뉴를 통해 Code를 볼 수도 있다.
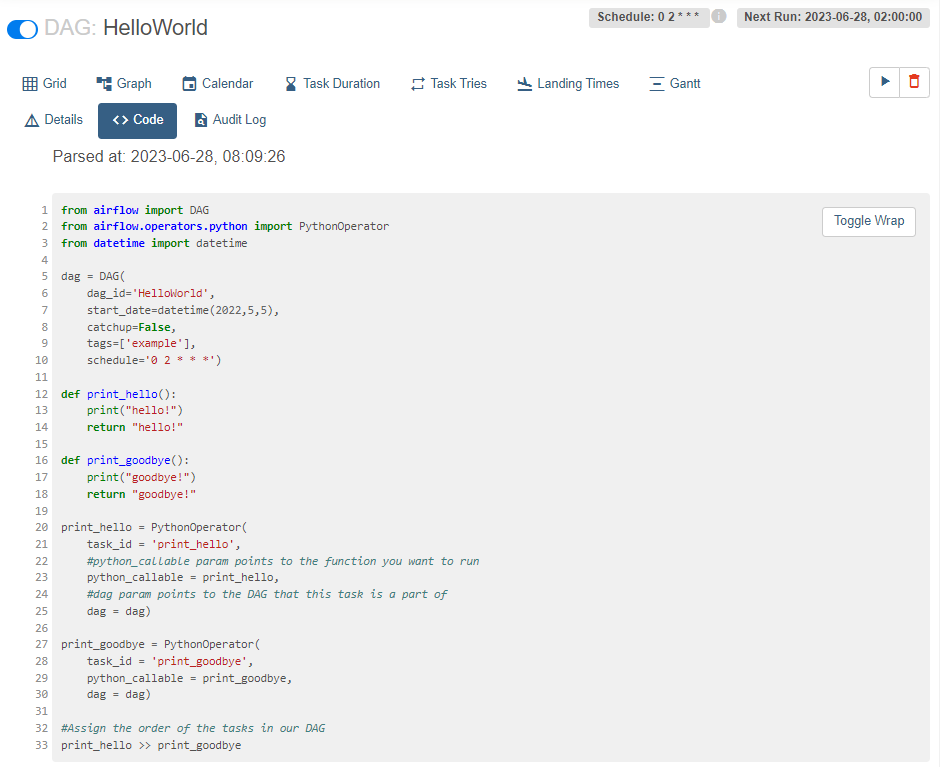
dag 코드의 schedule을 보면, 0 2 * * * 이다.
-> 매일 1번 UTC 기준 2시 0분에 실행된다.
2개의 PythonOperator로 만든 Task가 2개 있다.
Task가 실행될 때 python_collable 인자로 지정해준 함수인 print_hello, print_goodbye가 실행된다.
함수의 내용은 원하는 것을 넣어준다.
실행순서는 다음의 코드로 지정
#Assign the order of the tasks in our DAG
print_hello >> print_goodbye※ docker 컨테이너 실행 중지
- 아래 코드를 터미널에 입력
docker compose down- 터미널에서 ctrl + z 입력
- docker 엔진 프로그램에서 모두 선택 후 pause(잠깐 중단, 이후 지금 상황 그대로 실행할 수 있다.), stop(재실행 시 초기 상태로 시작된다.)

지금까지 현업에서 실제로 사용하는 방법을 실습했다.
숙제1) 파이썬 코드 개선하기

- 헤더가 레코드로 추가되는 이슈
- 멱등성이 깨지는 이슈
- 중간에 에러가 발생해서 중간에 데이터가 불완전하게 끊기는 경우 대처 transaction으로 해결하기
숙제2) Airflow HelloWorld, HelloWorld_v2 대그가 보이는 첫 화면 캡처해서 보내기
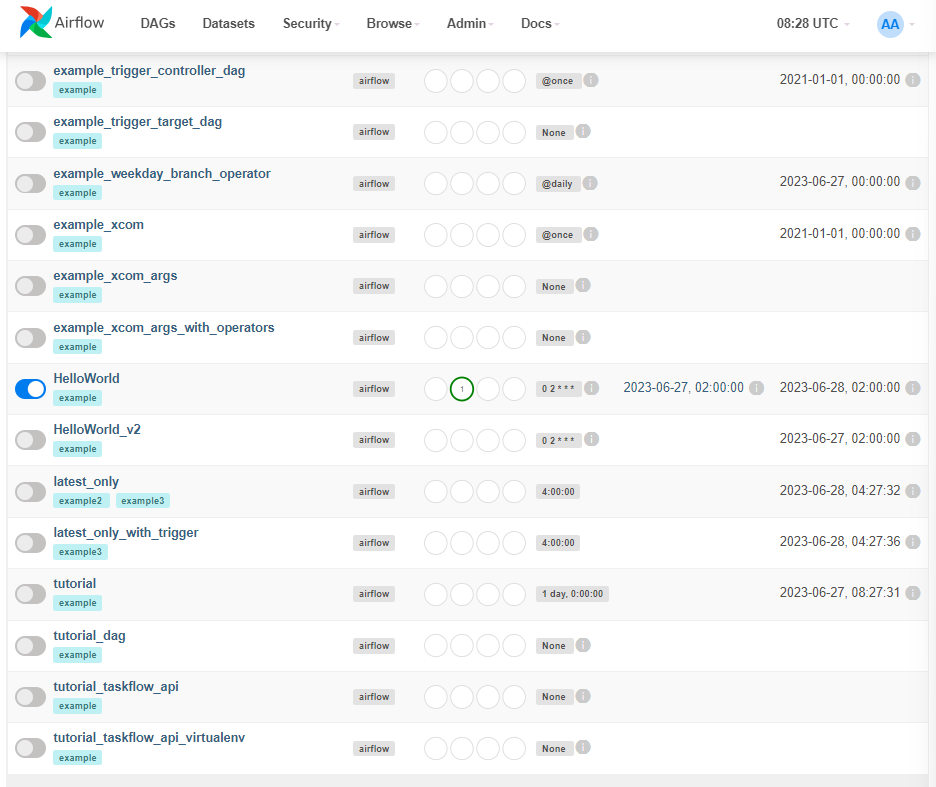
이때, 이전에 HelloWorld를 활성화했던 상태가 그대로 남아있는 것을 볼 수 있는데, docker의 volume 기능이다. 볼륨으로 특정 디렉토리 경로를 지정해놓으면 기록은 영원히 유지된다. 컨테이너 중단 삭제 등등 해도 유지되게 할 수 있다. airflow의 기록이 postgres에 남는데 postgres의 정보가 volume 이라는 것으로 세팅이 되어있기 때문에 여기의 기록을 명시적으로 reset하지 않는 한 계속 남게 된다.
도커는 데엔에게 중요한 기술, 쿠버네티스는 일단 컨셉만 알아두기
