실제 데이터를 텐서로 표현하기
신경망은 텐서를 입력받아 출력할 텐서를 만들며, 신경망에서 일어나는 모든 연산과 최적화는 텐서 연산이고 가중치나 바이어스 같은 신경망 내 모든 파라미터 또한 텐서이다. 텐서로 어떻게 연산을 수행하고 효과적으로 색인하는지를 이해하는 것이 파이토치 공부의 핵심이다.
이미지 다루기
이미지는 픽셀 단위의 높이와 너비를 가지는 표준적인 그리드에 나열된 복수 개의 스칼라값 모음으로 표현된다. 하나의 스칼라 값인 경우 흑백 이미지, 여러 색을 표현하기 위해서는 여러 개의 스칼라 값이 필요하다. 색상외에 추가적으로 다양한 피쳐를 포함하기도 한다.
컬러 채널 더하기
컬러를 숫자로 표현하는 가장 흔한 방법은 RGB로서, (빨강, 초록, 파랑)의 강도를 나타내는 세 개의 숫자로 컬러를 정의하는 방식이다.
이미지 파일 로딩
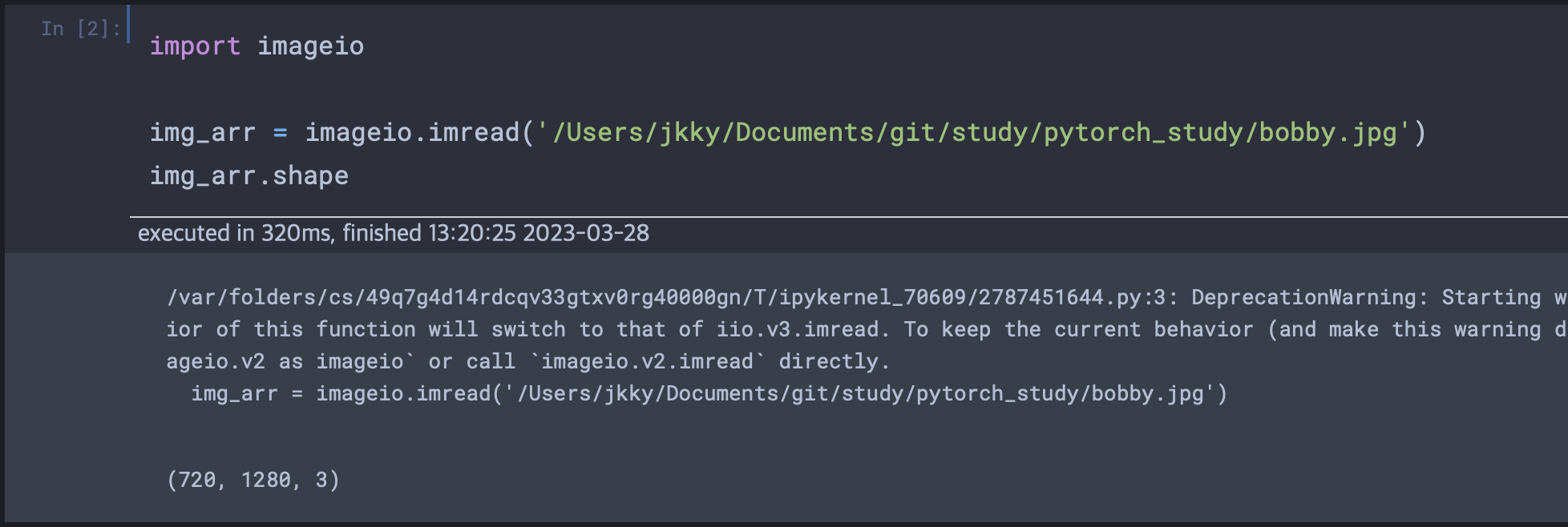
imageio 모듈을 사용한 PNG 이미지 로딩.
레이아웃 변경하기
현재 차원은 (H x W x C)로 되어 있는데 이것을 (C x H x W)로 바꿔야 한다.(레이아웃 변경)
import torch
img = torch.from_numpy(img_arr) # 텐서로 변경
out = img.permute(2, 0 , 1)
#레이아웃 변경, 복사본 만드는 것이 아님
#img가 참조하는 메모리는 같음 즉 out안의 데이터를 변경하면 img도 변경됨.지금까지는 하나의 이미지만 다뤘지만 보통 신경망에는 여러 이미지가 주입된다. 그러므로 그것을 구현하기 위해 첫번째 차원에 batch를 만들어 NxCxHxW 텐서로 저장한다. 지금 만든 batch는 빈 데이터를 가진 텐서 껍데기(zeros메서드로 구성했음)라고 생각하면 된다.
# 실제 데이터셋 읽어와서 텐서화 하기
import os
data_dir = '/Users/jkky/Downloads/pytorch-master/data/p1ch4/image-cats'
filenames = [name for name in os.listdir(data_dir) if os.path.splitext(name)[-1] == '.png']
# 경로안의 파일 .png로 된 파일만 리스트화
for i, filenames in enumerate(filenames):
img_arr = imageio.imread(os.path.join(data_dir, filenames)) #사진 넘파이 배열 가져오기
img_t = torch.from_numpy(img_arr) # 텐서로 변환
img_t = img_t.permute(2, 0, 1) #채널을 앞으로 땡겨오기
img_t = img_t[:3] #첫번째 차원에 대해 3개만 채택할 것 (rgb이니까)
batch[i] = img_t데이터 정규화
batch = batch.float()
batch /= 255.0
# 부동소수점으로 캐스팅 후 픽셀 값 정규화#다른 방법 : 입력 데이터의 평균과 표준 편차에 대해 평균이 0이고 각 채널값이
# 표준편차를 넘지 않게 만들기
n_channels = batch.shape[1]
for c in range(n_channels):
mean = torch.mean(batch[:, c])
std = torch.std(batch[:, c])
batch[:, c] = (batch[:, c] - mean) / std3차원 이미지: 용적 데이터
지금까지 우리는 카메라로 한번 찍은 2차원이미지를 어떻게 읽고 표시하는지를 배웠다. 의학분야에서의 CT 스캔은 밀도가 높아지는 차례대로 인간육체의 구성 물질들을 구별할 수 있도록 임상장비의 화면상에서 순서대로 어두운 쪽에서 밝은 쪽으로 매핑된다.
CT는 흑백 이미지처럼 하나의 밀도 채널만 있으며, 2차원 단면을 스택처럼 쌓아 3차원 텐서를 만들면 3차원 해부도를 표현한 용적 데이터를 만들 수 있다.
즉 우리는 NxCxD(깊이)xHxW의 5차원 텐서를 다루게 되는 것이다.
특수 포맷 로딩
샘플 CT 스캔 로딩을 위해 volread 함수를 사용.
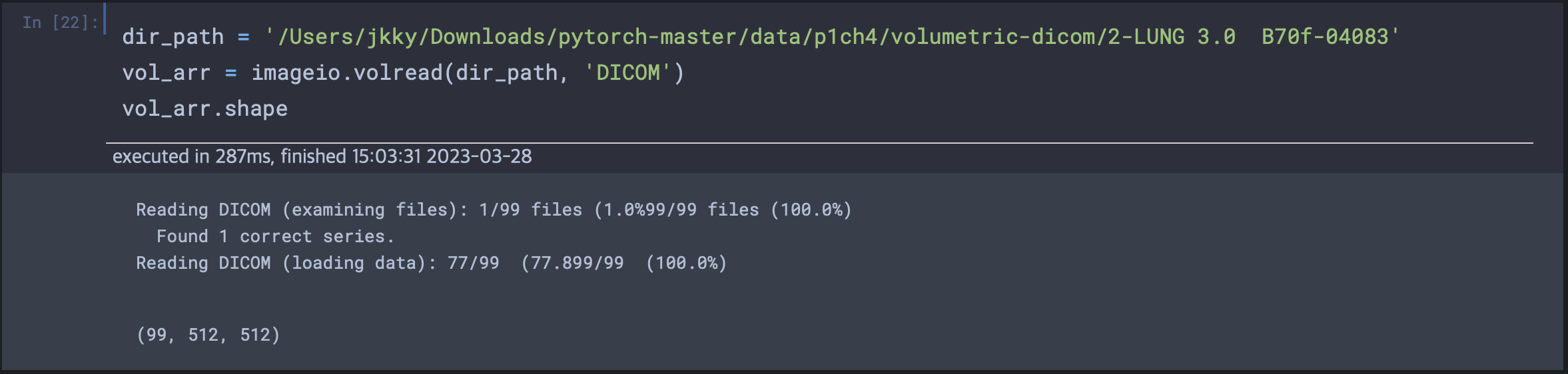
채널 정보가 사라진 것을 볼 수 있다. unsqeeze를 사용하여 channel 차원을 위한 공간을 공급한다.
vol = torch.from_numpy(vol_arr).float()
vol = torch.unsqueeze(vol, 0) # 첫번째 차원으로 언스퀴즈
vol.shape
# 결과 = (1, 99, 512, 512)테이블 데이터 표현하기
머신러닝 작업시 접하는 가장 단순한 데이터 형태는 spreadsheet,csv,database에 들어있는 경우일 것이다. 모두 테이블 형식이다. 실습을 위해 첨부된 화이트 와인 데이터를 활용한다.
와인 데이터를 텐서로 읽어오기
import csv
import numpy as np
wine_path = '/Users/jkky/Downloads/pytorch-master/data/p1ch4/tabular-wine/winequality-white.csv'
wineq_numpy = np.loadtxt(wine_path, dtype=np.float32, delimiter=";", skiprows=1)
wineq_numpy.shape
# 결과 (4898, 12)
wineq = torch.from_numpy(wineq_numpy)넘파이에서 미리 np.float32로 설정했기에 torch부분에서 따로 부동소수점 데이터형식을 적용하지 않아도 됬다.
연속값, 순서값, 카데고리값
데이터를 처음 다룰 때 많이들 실수하는 지점이 피처의 특성을 무시하고 단순히 숫자처리를 하고 머신러닝을 돌린다는 것이다.
연속값: 값 사이에 순서가 있어서, 두 값의 차이가 독립적이지 않고 서로 영향을 준다.순서값: 연속값을 카테고리화 한 것이다. 대, 중, 소를 각각 3, 2, 1로 매핑되었다 했을 때 이를 그대로 입력으로 연속값처럼 주입하면 옳지 않다. 연속값으로 쓰일 수 있도록 매핑하거나 연속값에서만 가능한 연산을 수행하지 않도록 해야한다.카테고리값: 순서나 숫자적인 의미가 없는 값이다. 이 경우 숫자화 하여 인공지능 모델에 사용하기 위해서는 원핫인코딩, 멀티핫인코딩 등의 절차가 필요하다.
점수 표현하기
데이터에서 마지막 열에는 우리가 예측할 정답이 담겨있다. 이 부분을 따로 떼어내야하고, 우리는 나머지 열들로 하여금 떼어낸 열을 예측해야한다. 그리고 떼어낸 열(레이블 or target)과 predict결과를 반복적으로 피드백하여 예측성능을 올리는 것이다.
target = wineq[:, -1] # 단순하게 떼어내는 법
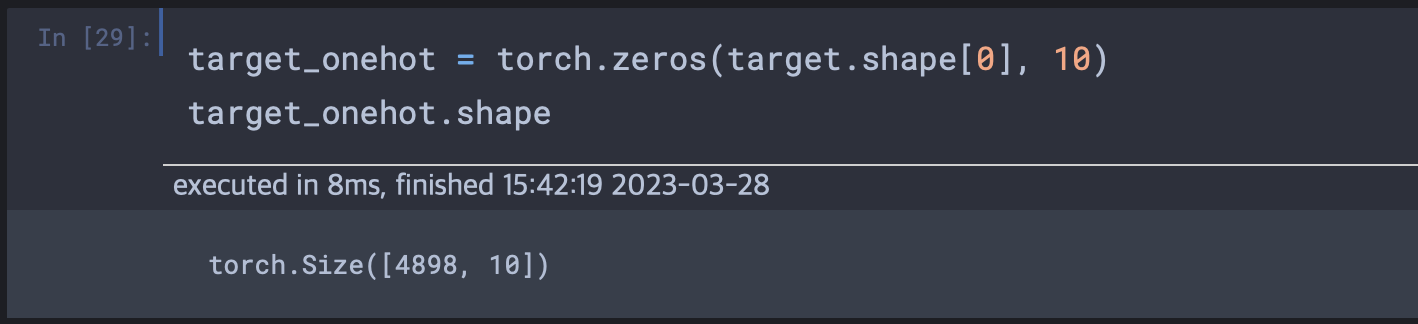
target = wineq[:, -1].long() # 정수화One-Hot-Encoding
현재 다루는 데이터의 경우 점수가 1점부터 10점까지 있다. 총 10개의 점수는 카테고리로 여겨진다. 포도와 딸기라는 관계보다는 1점과 2점과의 관계는 더 관계성이 있어보인다. 점수를 정수 벡터로 처리한다는 것은 점수상의 순서가 의미 있다고 가정하는 것이다. 즉 점수의 열로만 보았을 때 이전 점수와 이후 점수간의 관계성을 고려해서 연산되는 것이다. 하지만 실제로 앞 점수와 뒷 점수간의 관계성은 없다. 즉 점수는 이전 열들의 영향으로 생성되는 것이지 앞, 뒤간의 연속성이 고려되서는 안되는 것이다.
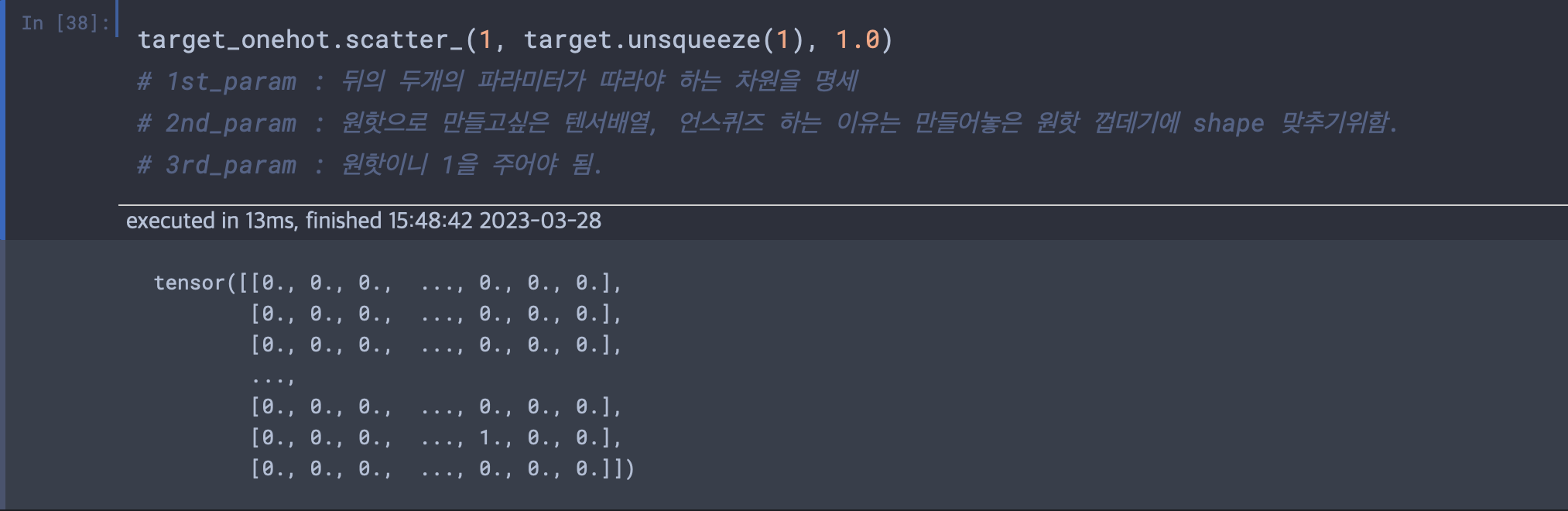
scatter, scatter_
메소드 뒤에 "_"가 붙는 것은 파이토치에서는 새로운 텐서를 반환하는 메소드가 아니라 텐서를 바꿔치기 하는 방법으로 변경하는 메소드라는 뜻이다.
언제 카테고리화 할 것인가
연속 데이터는 값을 바로 사용할 수 있고 카테고리 데이터는 원핫이나 임베딩을 사용하면 된다. 가장 애매한 부분은 순서데이터이다. 순서데이터는 "우선순위"가 있는 순서일 경우 값을 바로 사용하고, 없을 경우 카테고리로 취급하면 된다.
Question. 우선순위란 무엇인가?(실제로 이해하기를 대, 중, 소의 경우 얼마나의 개념이 없지만 소가 중보다 작고, 중이 대보다 작다는 등의 관계가 존재한다. 근데 이것을 카테고리로 다룰지, 연속형으로 다룰지에 우선순위? )
시계열 데이터 다루기
와인 데이터셋으로 다시 돌아가서, 만일 매년 와인의 품질이 어떻게 발전해왔는지를 알 수 있는 year열이 있었다면 어떨까? 이러한 의문을 뒤로하고, 워싱턴 DC의 2011년도~2012년 사이의 캐피탈 바이크 쉐어 공유 자전거 시스템의 시간대별 자전거 대여 데이터에 날씨와 계절 정보까지 포함된 데이터셋을 3차원 데이터셋으로 바꾸어보자.
시간 차원 더하기
bikes_numpy = np.loadtxt('/Users/jkky/Downloads/pytorch-master/data/p1ch4/bike-sharing-dataset/hour-fixed.csv',
dtype=np.float32,
delimiter=',',
skiprows=1,
converters={1: lambda x: float(x[8:10])})
bikes = torch.from_numpy(bikes_numpy)
bikes먼저 신경망이 이 공유 자전거 데이터셋을 고정된 크기로 처리할 수 있도록 만드는 법을 생각해보자. 이 신경망 모델은 대여 수나 하루 중 시각, 혹은 기온이나 날씨 상태등의 각기 다른 값에 대해 연속으로 여러 개의 값을 볼 필요가 있다.
크기가 C인 N개의 병렬 시퀀스로 표현이 가능하다. C는 채널을 나타내고 N은 시간 축을 표현한다.
시간 단위로 데이터 만들기
2년치 데이터셋을 쪼개서 일 단위처럼 다소 넓은 관찰 주기로 나눌 필요가 있다. 시계열 데이터셋이 3차원 텐서가 되어 NxCxL로 만들어진다. C에는 17개의 채널이 들어가고 1을 한 시간으로 해서 L은 24가 된다. 즉 하루단위의 블럭으로 17개의 피처를 보는 것이다.
bikes의 shape를 찍어보면 (17520, 17)로 나타난다 즉 17,250시간에 17개의 열 테이블 데이터셋이다.
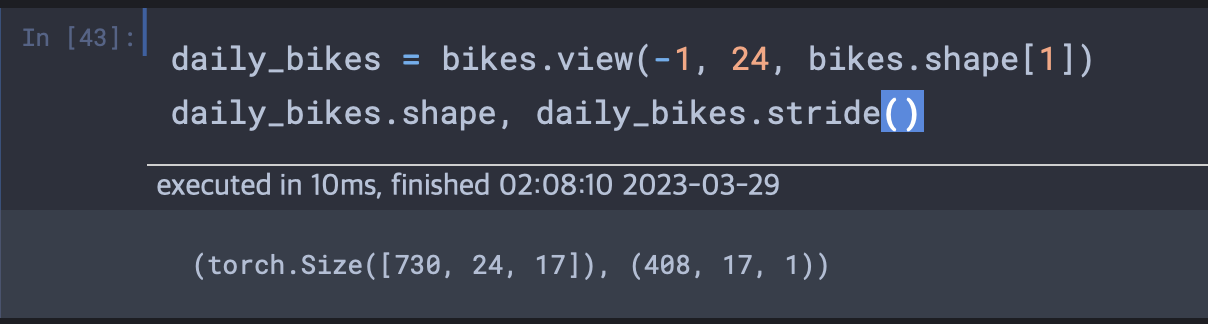
일별로 매 시간의 데이터셋을 구하기 위해 동일 텐서를 24시간 배치로 바라보는 뷰가 필요하다.
.view() 에서 -1의 의미
## Case 1 t = np.zeros((4,4,3)) #0으로 채워진 4x4x3 numpy array 생성 ft = torch.FloatTensor(t) #텐서로 변환 print(ft.view([-1, 3])) # ft라는 텐서를 (?, 3)의 크기로 변경 print(ft.view([-1, 3]).shape) #원소의 개수(4x4x3 = 48 개는) 유치한 채 3차원으로 #맞추다 보니까 결과적으론 16x3 이 됨.
bikes.shape[1]은 텐서의 열의 개수로 17이다. view는 shape의 구조를 바꾸는 역할을 한다. 텐서에 view를 호출하면 저장공간을 바꾸지 않고 차원 수나 스트라이드 정보를 바꾼 새 텐서를 넘겨준다.
daily_bikes에 대한 스트라이드를 보면, 두번째 차원인 시간을 한 칸 이동하기 위해서는 저장공간 상 열의 개수인 17칸만큼 이동해야 하고 첫번째 차원인 일자를 한 칸 이동하려면 한 행의 길이에 24를 곱한 수 즉 17x24 = 408칸 만큼을 이동해야한다. 그렇기에 스트라이드를 찍어보면
(408, 17, 1)이 된다.
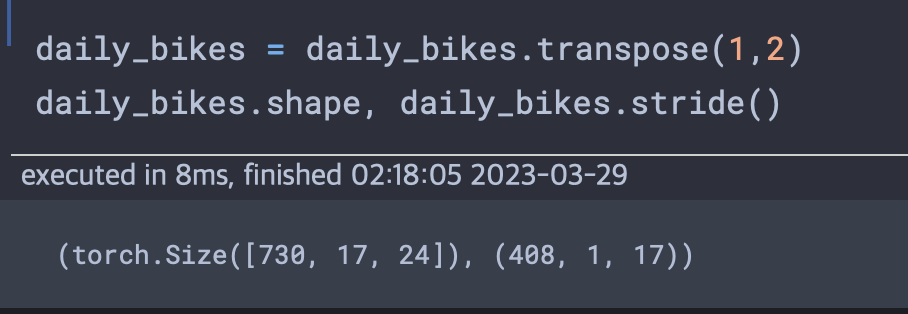
가장 오른쪽 차원은 원래 데이터셋에서 처럼 열의 수로 만들어야 한다 즉 NxCxL순서로 놓고 싶다면 텐서를 전치해야한다.
훈련 준비
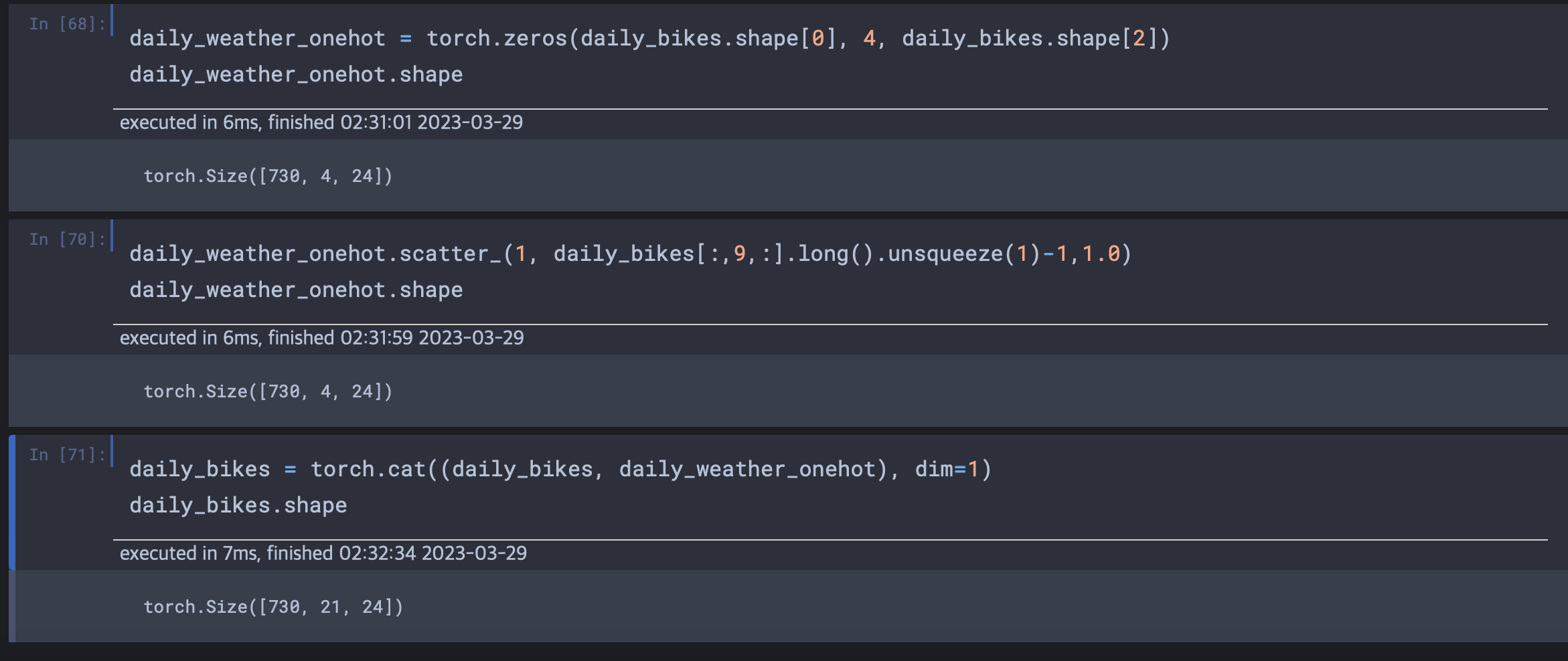
날씨 상태를 나타내는 데이터는 순서값이다. 총 4단계로 1은 좋은날씨 4는 정말 안 좋은 날씨이다. 첫 날의 데이터만 생각해보자. 하루 시간대 만큼의 행과 날씨 상태 가짓수 만큼의 열을 가진 0으로 채워진 행렬을 초기화 한다.
first_day = bikes[:24].long()
weather_onehot = torch.zeros(first_day.shape[0], 4)
weather_onehot.scatter_(
dim=1,
index=first_day[:,9].unsqueeze(1).long() - 1,
# 1~4이므로 0~3으로 수정
value=1.0)만들어진 행렬을 원래 데이터셋에 cat 함수를 사용해 병합한다.
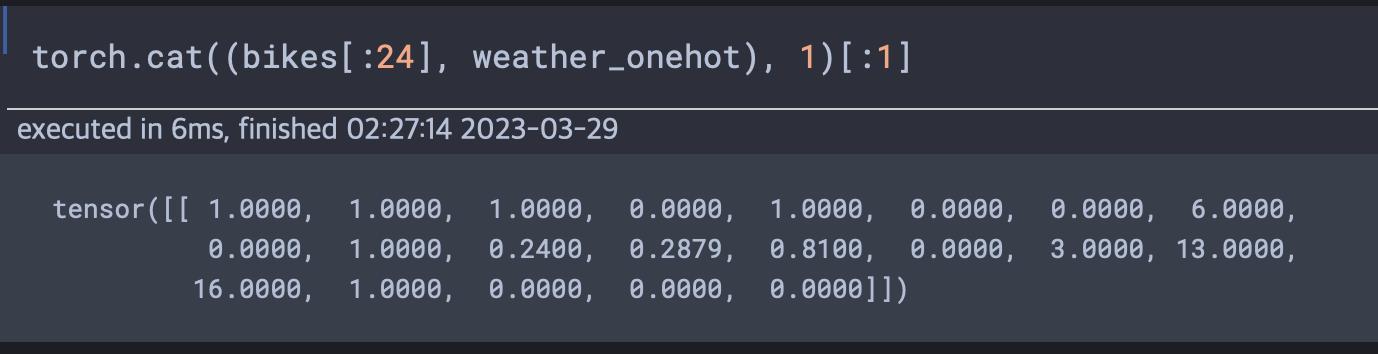
(24,17) 이 병합을 통해 (24, 17) + (24, 4)로 (24, 21)이 된다.
이제 원래의 bikes 데이터셋에 성공적으로 날씨 상태를 원핫 인코딩하여 데이터 열이 있는 차원인 1번 차원을 따라 병합했다. cat으로 붙이기 위해서는 텐서에 붙을 차원의 크기가 같아야 한다. daily_bikes 텐서에 대해서도 동일한 작업 수행이 가능하다.
Question
책에서 L을 24 즉 24시간으로 나누어 사용하는 것에 특별한 이유가 없어서 다르게 묶어도 상관없다는 말을 하였다. 하지만 3차원 텐서를 NxCxL로 구성하는 이유는 무엇일까?
텍스트 표현하기
신경망으로 텍스트를 다루는 직관적인 방법은 두 가지가 존재한다. 하나는 문자 단위로 한 번에 하나의 문자를 처리하는 것과 단어 단위로 신경망이 바라보는 세밀한 묶음으로 개별 단어를 처리하는 것이다.
