텐서 구조체
딥러닝 프로세스는 입력을 부동소수점 수로 변환하는 것부터 시작한다. 이번 장에서는 텐서를 사용하여 파이토치가 부동소수점 수를 어떻게 다루는지를 알아본다.
부동소수점 수의 세계
신경망 안에서의 정보 처리는 실세계의 데이터를 신경망이 연산 가능하도록 인코딩해야 하고, 처리 후 나온 결괏값은 해석 가능하거나 사용할 수 있도록 디코딩해야 한다.
심층 신경망은 여러 단계를 거쳐 데이터 변환을 학습한다. 이미지 인식의 경우 앞 단계에서는 모서리를 검출하거나, 털 같은 질감을 잡아내고 깊이 들어갈수록 귀나 코 혹은 눈 같은 복잡한 구조를 파악한다.
신경망의 중간층에서의 표현값은 입력과 이전 층의 뉴런이 가진 가중치를 조합한 결과라는 점이다. 중간 단계의 개별 표현은 자신만의 방식으로 앞 단계에서 넘어온 입력을 변환한다.
Tensor
데이터 처리와 저장을 위해 파이토치에서는텐서(tensor)라는 기본 자료구조를 제공한다. 딥러닝에서의 텐서는 임의의 차원을 가진 벡터나 행렬의 일반화된 개념이다. 텐서는 또한 다차원 배열이라고도 부른다. 텐서의 차원 수는 텐서 안의 스칼라 값을 참조하기 위해 사용하는 인덱스 수와 동일하다.
또한 파이토치의 텐서는 넘파이와 깔끔하게 호환되므로 사이킷런이나 판다스와 같은 과학 라이브러리와 자연스럽게 통합된다.
텐서 : 다차원 배열
파이썬 리스트나 튜플 객체는 메모리에 따로따로 할당된다. 반면 텐서나 넘파이 배열은 파이썬 객체가 아닌 언박싱된 C언어의 숫자 타입을 포함한 연속적인 메모리가 할당된다.
텐서를 조작하기 위해 torch를 import하고 torch.tensor로 하여금 텐서를 만들어볼 수 있다. 텐서 안 데이터 값 조회가 리스트와 비슷하게 가능하였는데 책에서는 하나의 방법만 명시하였으나 다중리스트 조회와 같은 방법으로도 가능하였다.
텐서 인덱싱
파이토치 텐서도 넘파이를 비롯한 파이썬 과학 라이브러리와 동일한 표기법을 사용할 수 있다.
points[1:4] # 1번 인덱스부터 4번 인덱스 전까지
points[1:] # 1번 인덱스부터 마지막 인덱스까지
points[:4] # 처음 인덱스부터 4번 인덱스 전까지
points[:-1] # 처음 인덱스부터 마지막 인덱스 바로 앞까지
points[1:4:2] # 1번 인덱스부터 4번 인덱스 전까지 두 단계씩
points[1:, :] # 1번행 이후 모든 행, 모든 열
points[None] # 길이가 1인 차원 추가 unsqeeze와 동일이름이 있는 텐서
우리가 다루는 텐서는 차원이나 축이 있다. 텐서를 접근하려면 차원의 순서를 기억해서 인덱싱해야한다. 데이터가 여러 텐서 형태를 거치며 다양하게 변환되면, 어느 차원에 어떤 데이터가 들어있는지 헷갈리기 쉽다.
img_t 변수에 담긴 3차원 텐서(이미지)를 흑백으로 변환해야 한다고 가정해보자. 여러 색상별 가중치를 보고 하나의 밝기 값을 뽑아내야한다.
img_t = torch.randn(3, 5, 5)
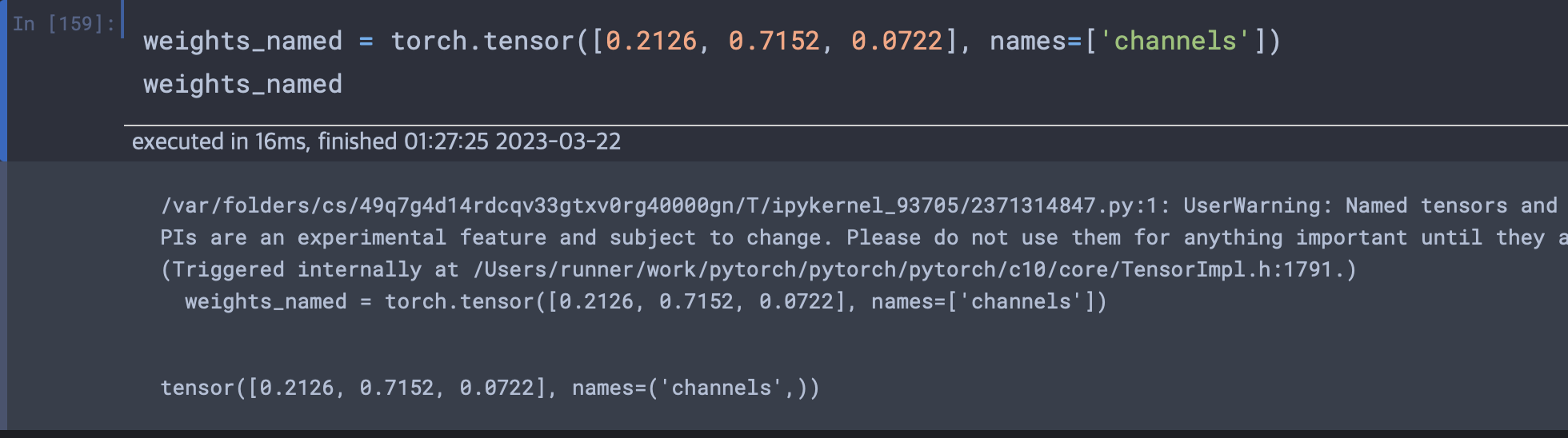
weights = torch.tensor([0.2126, 0.7152, 0.0722])
batch_t = torch.randn(2,3,5,5)
img_gray_naive = img_t.mean(-3)
batch_gray_naive = batch_t.mean(-3)
unsqueezed_weights = weights.unsqueeze(-1).unsqueeze(-1) # [3, 1 ,1]
img_weights = (img_t * unsqueezed_weights) # [3, 5, 5] * [3, 1 ,1] = [3, 5, 5] from broadcasting
batch_weights = (batch_t * unsqueezed_weights) # [2, 3, 5, 5] * [3, 1, 1] from broadcasting
img_gray_weighted = img_weights.sum(-3) # [3, 5, 5]를 첫번째 축 기준으로 sum (3개의 RGB 합침)
batch_gray_weighted = batch_weights.sum(-3) #[2, 3, 5, 5]를 두번째 축 기준으로 sum (3개의 RGB합침)squeeze() & unsqueeze()
squeeze함수는 차원이 1인 차원을 제거해준다. 따로 차원을 설정하지 않으면 1인 차원을 모두 제거한다. 그리고 차원을 설정해주면 그 차원만 제거한다. 반대로 unsqueeze의 경우는 차원이 1인 차원을 생성해준다. 지정하지 않을 경우 맨 뒤에 생성한다.
파이토치 버전 1.3에서는 이름 지정이 가능한 텐서가 등장했다.
텐서 요소 타입
파이썬 숫자 데이터 타입은 다음과 같은 이유로 최적이 아니다.
- Python에서 숫자는 객체다. 통상 부동소수점 수는 컴퓨터에서 32비트 공간을 사용한다. 하지만 파이썬은 부동소수점 수를 완전한 객체로 변환하여 박싱이라 부르는 연산을 수행한다. 이 연산은 많은 수의 수를 저장할 때 비효율적이다.
- Python의 List는 연속된 객체의 모음이다. 파이썬은 두 벡터의 내적을 효율적으로 수행해줄 연산이 없다. 벡터 합도 마찬가지이다. 리스트는 임의의 파이썬 객체에 대한 임의 접근이 가능한 포인터의 모음일 뿐이다.
- Python Interpreter는 최적화를 거치는 컴파일된 코드보다 느리다. 다량의 숫자 데이터 모음에 대한 수학적 연산의 경우 C와 같은 저수준 컴파일 언어로 최적화된 바이너리 코드가 훨씬 빠르다.
이 책 전반에서 알 수 있겠지만, 신경망 연산 대부분은 32비트 부동소수점 연산이다. 배정밀도64비트 타입을 사용해봤자 정확도 개선은 이루어지지 않으며 더 많은 메모리와 시간만 낭비된다.
텐서는 다른 텐서에 대한 인덱스로 사용할 수 있다. 인덱싱용 텐서의 경우 64비트 정수 데이터 타입으로 간주할 수 있고 텐서를 만들때 인자로 정수형을 할당하여 정수 텐서를 기본으로 만들 수 있다
- 앞으로의 대부분은 float32나 int64 값을 다루게 될 것이다.
코딩시 데이터 타입 고려
숫자 타입이 올바르게 지정된 텐서를 하나 할당할 때 생성자에 dtype 인자를 정확히 전달해야한다. 또한 .to()메소드를 사용하여 올바른 데이터타입으로 변환도 가능하다.
텐서 API
텐서끼리의 연산 대부분은 torch 모듈에 있고 텐서 객체에 대해 메소드처럼 호출할 수 있다.
(https://pytorch.org/docs 이곳에서 텐서 연산 함수들을 파악 가능)
텐서를 저장소 관점에서 머릿속에 그려보기
텐서 내부 값은 실제로는 torch.Storage 인스턴스로 관리하며 연속적인 메모리 조각으로 할당된 상태이다. 또한 서로 다른 방식으로 구성된 텐서가 동일한 메모리 공간을 가리키고 있을 수도 있다.
