
위 주제는 밑바닥부터 시작하는 딥러닝2 4강, CS224d를 바탕으로 작성한 글 입니다.
이전글에서 Embedding과 네거티브 샘플링을 통하여 CBOW 성능을 개선시켰다.
이전글 보러가기 word2vec 속도 개선(1)
PTB 학습👋
이제 개선된 CBOW 신경망 모델에 PTB 데이터셋을 사용해 학습 시키고, 단어의 분산 표현을 얻어보자.
1. 개선된 CBOW 모델
앞의 단순 CBOW 모델에서 Embedding 계층과 네거티브 샘플링 손실함수 계층을 적용했다.
class CBOW:
def __init__(self, vocab_size, hidden_size, window_size, corpus):
V, H = vocab_size, hidden_size
# 가중치 초기화
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(V, H).astype('f')
# 계층 생성
self.in_layers = []
for i in range(2 * window_size):
layer = Embedding(W_in) # Embedding 계층 사용
self.in_layers.append(layer)
self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size=5)
# 모든 가중치와 기울기를 배열에 모은다.
layers = self.in_layers + [self.ns_loss]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 인스턴스 변수에 단어의 분산 표현을 저장한다.
self.word_vecs = W_in
def forward(self, contexts, target):
h = 0
for i, layer in enumerate(self.in_layers):
h += layer.forward(contexts[:, i])
h *= 1 / len(self.in_layers)
loss = self.ns_loss.forward(h, target)
return loss
def backward(self, dout=1):
dout = self.ns_loss.backward(dout)
dout *= 1 / len(self.in_layers)
for layer in self.in_layers:
layer.backward(dout)
return None메서드는 4개의 인수를 받는다.
-
vocab_size 어휘수
-
hidden_size 은닉층의 뉴런 수
-
corpus 단어 ID 목록
-
window_size 맥락의 크기
이전 CBOW 모델에서는 입력 측의 가중치와 출력 측의 가중치의 형상이 달라 출력 측의 가중치에는 단어 벡터가 열방향으로 배치되었다. 한편 CBOW 클래스 출력 측 가중치는 입력 측 가중치와 같은 형상으로, 단어 벡터가 행 방향에 배치 된다. 그 이유는 NegativeSamplingLoss 클래스에서 Embedding을 사용하기 때문이다.
가중치 초기화가 끝나면, 이어서 계층 생성을 한다.
Embedding 계층 개수는 2 * window_size개 작성하여 in_layers에 배열로 보관 후 Negative Sampling Loss 계층을 생성한다.
(Negative Sampling Loss에 대한 설명과 코드는 이전 글을 참고하면 된다.)
모든 매개변수와 기울기는 params, grads에 모은다.
후에 단어의 분산 표현에 접근 가능하도록 인스턴스 변수인 word_vecs에 가중치 W_in을 할당한다.
foward
h += layer.forward(contexts[:, i]) 맥락을 h에 저장한다.
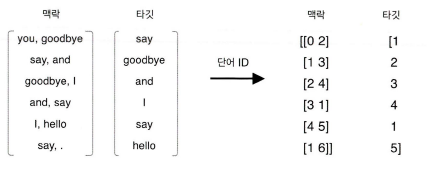
CBOW 학습
신경망 학습을 시켜보자
# 하이퍼파라미터 설정
window_size = 5
hidden_size = 100
batch_size = 100
max_epoch = 10
# 데이터 읽기
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
contexts, target = create_contexts_target(corpus, window_size)
if config.GPU:
contexts, target = to_gpu(contexts), to_gpu(target)
# 모델 등 생성
model = CBOW(vocab_size, hidden_size, window_size, corpus)
# model = SkipGram(vocab_size, hidden_size, window_size, corpus)
optimizer = Adam()
trainer = Trainer(model, optimizer)
# 학습 시작
trainer.fit(contexts, target, max_epoch, batch_size)
trainer.plot()은닉층의 개수는 100개
batch_size도 100개
optimizer은 Adam
10 epochs로 학습을 돌린다.
CBOW 모델 하이퍼파라미터 설정은 말뭉치에 따라 다르지만 보통 윈도우 크기는 2~10개, 은닉층의 뉴런 수는 50~500개 정도면 좋은 결과를 얻는다.
GPU를 사용하기 위한 Cupy 세팅
실제 학습을 돌리기 위해서 config.py 파일의 GPU변수를 True로 설정해주었다.
config.GPU = True참고로 GPU로 학습을 돌릴려면 Nvidia GPU를 장착한 컴퓨터이여야하고 Cupy도 미리 설치해 놓아야 한다.
CMD창이나 아나콘다(anaconda) 프롬포트에서
nvidia-smi나nvcc --version을 사용하면
본인 로컬에 해당하는 Cuda버젼이나, GPU정보를 알 수 있다.
그런데 문제는 "밑바닥부터 시작하는 딥러닝2" 책에서 Cupy 버전은 cupy < 8.0.0이다.
본인의 로컬 GPU환경은 Cuda 11.2버전에
GPU는 NVIDIA GeForce GTX 1050이다.
Cupy가 8버전 밑으로 지원하지 않는다. 가장 downgrade하였을 때 8.5.0 버전이였다. 이것 때문에 5시간 가량을 헤맸다.
-
error 1 : TypeError: Implicit conversion to a NumPy array is not allowed. Please use .get() to construct a NumPy array explicitly. (아직 해결 못함 뭐가 문제지..?)
-
error 2 : scatter_add 문제인데 밑의 코드에서 cupy에 scatter_add가 없는 것이다. Gpu로 실행하는 경우에
numpy의 add.at을 cupy형식으로 바꿔 주어야 하는데 이는 cupyx로 해결할 수있다.
if GPU:
import cupy as np
np.cuda.set_allocator(np.cuda.MemoryPool().malloc)
# np.add.at = np.scatter_add
print('\033[92m' + '-' * 60 + '\033[0m')
print(' ' * 23 + '\033[92mGPU Mode (cupy)\033[0m')
print('\033[92m' + '-' * 60 + '\033[0m\n')
else:
import numpy as npEmbedding 클래스의 backward 부분에 저 코드를 넣어 주면 된다. import cupyx는 해주어야 겠지..?
if GPU:
cupyx.scatter_add(dW, self.idx, dout)
else:
np.add.at(dW, self.idx, dout)
return NoneCupy 9.2.0 버전에 따른 Embedding 클래스 custom
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
if GPU:
cupyx.scatter_add(dW, self.idx, dout)
else:
np.add.at(dW, self.idx, dout)
return None
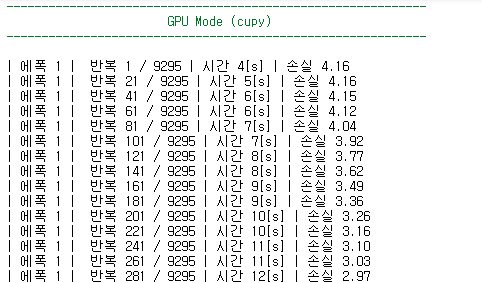
에폭 1에서 볼 수 있는 속도의 차이이다.
에폭 1의 반복 261 / 9265 에서 보면
CPU30[s]GPU11[s]
CPU로 돌리면 반나절이 걸리는 시간인데 GPU로 돌리면 30~40분내로 돌릴 수 있다.
학습 결과
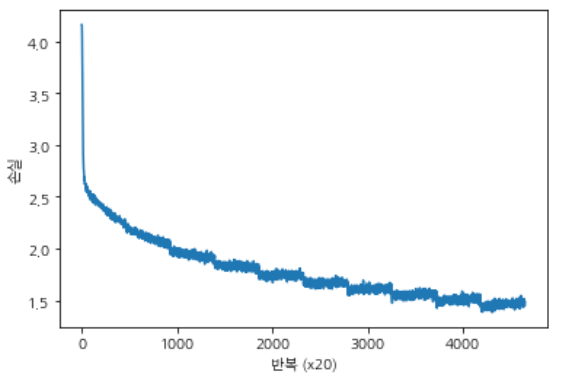
10 epochs를 돌린 결과 손실값은 1.4xx 언저리로 나온다. 그래프에서 볼 수 있듯 학습이 진행될 수록 loss값이 줄어드는데, 학습을 잘했다고 할 수있다.
train을 돌리고 나면 pkl파일이 생성된다. 이 파일로 test를 돌려보면 된다.
CBOW 모델 평가
학습된 pkl파일로 평가를 해보자 결과는 각각 다른 성격을 가진 단어들이 나왔다. toyota는 비슷한 자동차 메이커가 나왔다.
pkl_file = 'cbow_params.pkl'
# pkl_file = 'skipgram_params.pkl'
with open(pkl_file, 'rb') as f:
params = pickle.load(f)
word_vecs = params['word_vecs']
word_to_id = params['word_to_id']
id_to_word = params['id_to_word']
# 가장 비슷한(most similar) 단어 뽑기
querys = ['you', 'year', 'car', 'toyota']
for query in querys:
most_similar(query, word_to_id, id_to_word, word_vecs, top=5)Result
[query] you
we: 0.74609375
i: 0.6982421875
your: 0.62548828125
they: 0.61474609375
anything: 0.57373046875
[query] year
month: 0.85009765625
week: 0.7958984375
summer: 0.7724609375
spring: 0.73828125
decade: 0.685546875
[query] car
truck: 0.6240234375
window: 0.62255859375
luxury: 0.6044921875
auto: 0.57666015625
cars: 0.5703125
[query] toyota
engines: 0.64111328125
honda: 0.634765625
beretta: 0.62109375
seita: 0.62109375
mazda: 0.60107421875analogy('king', 'man', 'queen', word_to_id, id_to_word, word_vecs) analogy('take', 'took', 'go', word_to_id, id_to_word, word_vecs) analogy('car', 'cars', 'child', word_to_id, id_to_word, word_vecs) analogy('good', 'better', 'bad', word_to_id, id_to_word, word_vecs)>>[analogy] king:man = queen:? a.m: 5.45703125 woman: 5.22265625 toxin: 4.8984375 yard: 4.859375 gene: 4.80078125 [analogy] take:took = go:? eurodollars: 4.9140625 were: 4.7265625 're: 4.55078125 came: 4.3515625 went: 4.28125 [analogy] car:cars = child:? a.m: 6.828125 daffynition: 5.66015625 children: 5.40625 rape: 4.9921875 adults: 4.96875 [analogy] good:better = bad:? rather: 5.76171875 less: 5.453125 more: 5.359375 greater: 4.40234375 faster: 3.615234375king:man = queen:? 의 답은 "woman"인데 2등에 자리고 있고 a.m이 1등이다 왜그러지..?
take:took = go:? 의 답은 "went"이다 순위에는 있는데 5등이라는 처참한 등수이다.
car:cars = child:? 의 답은 "children" 3등
good:better = bad:? 의 답은 "worse" 순위 밖이다.
그래도 이전보다는 확실하게 성능이 향상된 것을 볼 수 있다.
이처럼 word2vec으로 얻은 단어의 분산 표현을 사용하면, 벡터의 덧셈과 뺄셈으로 유추 문제를 풀 수 있다. 단어의 단순 의미뿐 아니라 문법 패턴도 파악할 수 있다.
- "good"과 "best"사이에 "better"가 존재하다는 관계성 찾기
PTB 데이터셋의 정확도
사실 원하는 결과를 얻지 못하는 문제가 더 많다. 그 원인은 PTB 데이터셋이 작은 것이 원인인데, 아마 큰 말뭉치로 학습하면, 더 정확하고 더 견고한 단어의 분산 표현을 얻을 수 있으므로 유추 문제의 정확도도 크게 향상 될 것이다.
word2vec 단어의 분산표현의 장점
word2vec으로 얻은 단어의 분산 표현은 비슷한 단어를 찾는 용도로 쓰일 수 있다고 했다.
자연어 처리 분야에서 단어의 분산 표현이 중요한 이유는 전이 학습(transfer learning)에 있다.
전이학습은 한 분야에서 배운 지식을 다른 분야에도 적용하는 기법이다. 그래서 큰 말뭉치로 전반적인 학습을 끝낸 후, 각자 작업(분류, 클러스터링, 감정 분석 등)에 이용한다.
단어의 분산 표현은 단어를 고정 길이 벡터로 변환해준다는 장점도 있다. 더욱이 문장(단어의 흐름)도 단어의 분산 표현을 사용해 고정 길이 벡터로 변환할 수 있다. 현재 연구중인 방법이다.
- 가장 간단한 방법은 문장의 각 단어를 분산 표현으로 변환하고 그 합을 구하는 것이다.
- bag-of-words라고 하며, 단어의 순서를 고려하지 않는 모델이다.

그림 처럼 자연어로 쓰여진 질문을 고정 길이 벡터로 변환할 수 있다면, 그 벡터를 다른 머신러닝 시스템의 Input으로 사용할 수 있다.
자연어를 벡터로 변환함으로써 일반적인 머신러닝 시스템의 틀에서 원하는 답을 출력하는 것(학습하는 것도)이 가능해진다.
단어 벡터 평가 방법
word2vec을 통해 얻은 단어의 분산 표현이 좋은지는 어떻게 평가할까?
단어 분산 표현은 현실적으로는 특정한 애플리케이션에서 사용되는 것이 대부분이다. 우리가 원하는 것은 정확도가 높은 시스템일텐데, 여기서 생각 해야하는 것은 시스템이(예로 감정 분석 시스템) 여러 시스템으로 구성되어있다는 것이다.
여러 시스템은 단어의 분산표현을 만드는 word2vec과 분류를 수행하는 시스템(SVM 등)을 말한다.
단어의 분산 표현을 만드는 시스템과 분류하는 시스템의 학습은 따로 수행할 수도 있다.
이는 시간이 오래걸리기 때문에, 단어의 분산 표현의 우수성을 실제 애플리케이션과는 분리해 평가하는 것이 일반적이다. (자주 사용되는 평가 척도가 단어의 '유사성'이나 '유추 문제'를 활용한 평가다.)
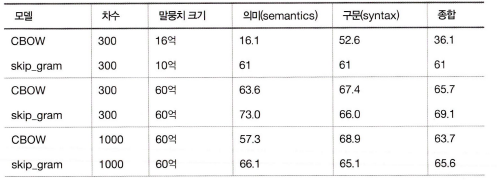
- 모델에 따라 정확도가 다르다 (말뭉치에 따라 적합한 모델 선택).
- 일반적으로 말뭉치가 클수록 결과가 좋다 (항상 데이터가 많은게 👍👍👍👍👍)
- 단어 벡터 차원 수는 적당한 크기가 좋다(너무 커도 정확도가 나빠진다.)
word2vec을 배우며
CBOW 모델을 만들고 Embedding 계층과 네거티브 샘플링이라는 새로운 기법을 배우고 개선까지 해보았다. 말뭉치의 어휘 수가 증가함에 따라 계산량이 증가하는 문제가 있었다.
이전에 '모든'데이터를 처리하는 것이 아니라 '일부'만을 처리하여 원하는 부분만 효율적으로 계산할 수있도록 하는 네거티브 샘플링기법이 정말 신기했다.
자연어 처리에 대한 기법을 하나 배우면서 후에 프로젝트나 어플리케이션 개발에 직접 사용해 보고 싶은 생각이 들었다.
다음은 RNN에 대한 포스팅이다!
