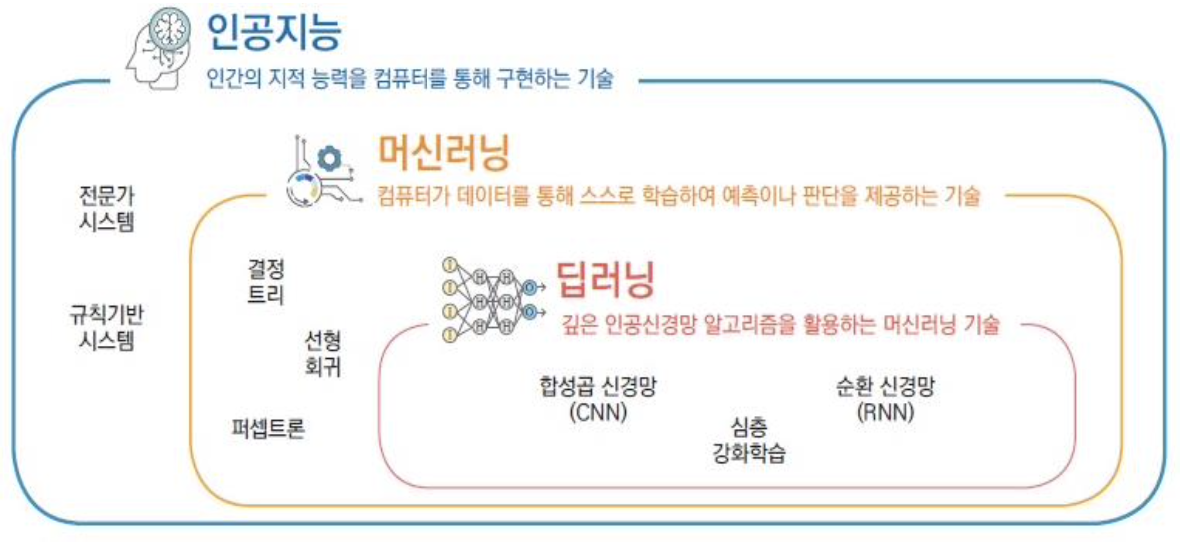
주제: 머신러닝 개요
1. 머신러닝 개요
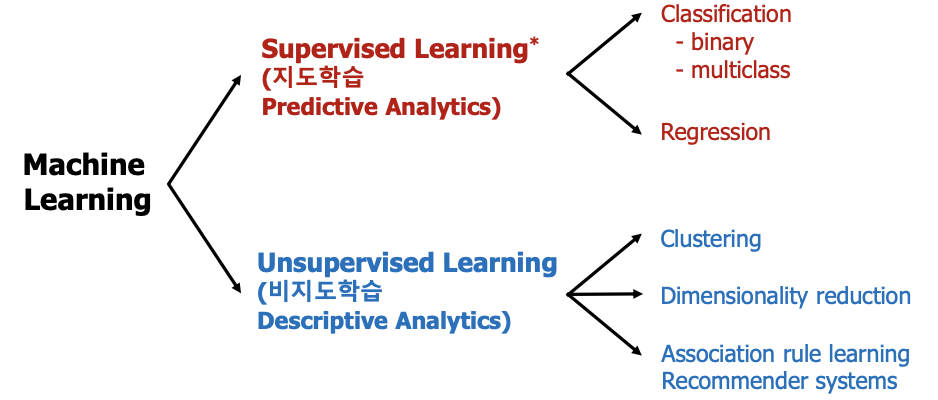
1.1. 머신러닝이란?
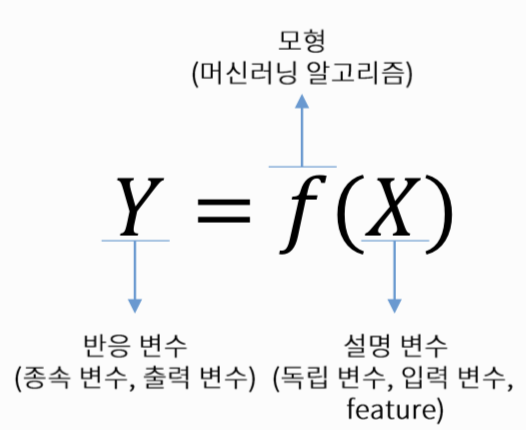
- 간단히 말해, "무엇(X)으로 무엇(Y)를 예측하고 싶다"
-> 주어진 데이터를 통해서 설명 변수와 반응 변수 간의 관계를 만드는 함수f를 만드는 것
- 기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 알고리즘을 개발하는 연구 분야 (Arthur Samuel, 1959)
- 컴퓨터가 데이터에서부터 규칙 또는 패턴을 찾아 학습하도록 하는 프로그래밍
1.1.1. 지도학습
- 라벨이 존재하는 학습 데이터를 학습하는 것
- 정답이라고 가정한 내용에 맞게 컴퓨터가 예측하여 분류, 회귀로 나뉨.
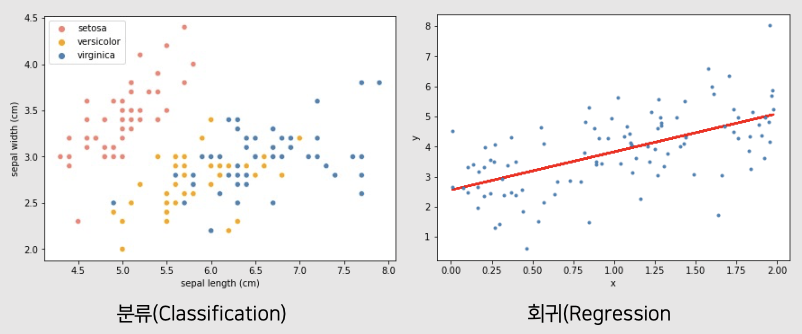
분류

- 데이터의 특성을 통한 범주형 데이터인 class 예측
- X에 대해서 이산형 변수 Y를 예측
회귀

- 연속형 데이터인 target 수치 예측
- X에 대해서 연속형 변수 Y를 예측
1.1.2. 비지도학습
- 라벨이 존재하지 않는 학습 데이터를 학습하는 것
ex. 군집화, 차원 축소, 연관 분석
1.1.3. 강화학습
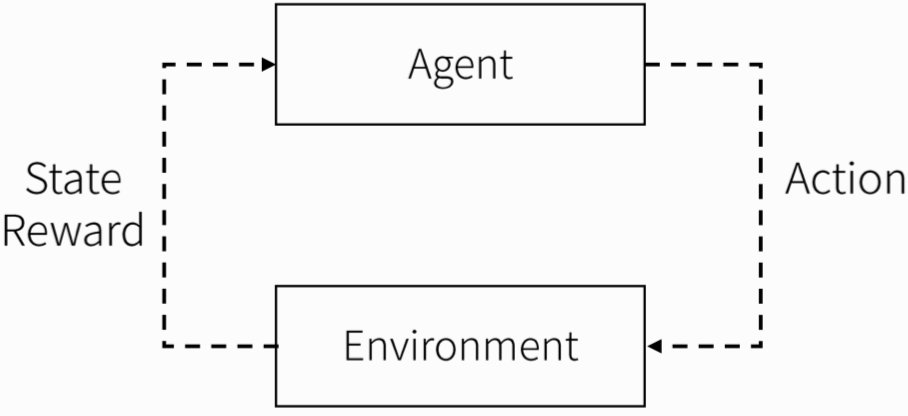
- 현재의 상태(State), 행동(Action), 보상(Reward), 다음 상태(Next state)가 있어야 학습 진행 가능
- 수 많은 시뮬레이션을 통해 컴퓨터가 현재 상태에서 어떠한 행동을 취해야 먼 미래의 보상을 최대로 할 것인가에 대해 학습하는 알고리즘임.
- 만약 벽돌게임으로 예를 든다고 하면
-state: 현재 이미지
-action: 바를 왼쪽 or 오른쪽으로 이동
-reward: 어떻게하면 점수를 올릴 수 있는가
1.2. 머신러닝 수행 과정

1.2.1. Domain Understanding & Data Collection
- 프로젝트를 진행할 때 데이터를 수집하고 도메인을 이해하는 단계
- EDA를 통해 데이터분석 진행
- 결측값, 이상치, 분포 등을 시각화를 통해 데이터분석
- 왜 어떠한 목적으로, 어떤 문제제기를 가지고 인사이트를 도출할 것인가에 따라 방향성이 따라짐
-> 매우 매우 매우 중요함
1.2.2. Data Preprocessing
- 데이터 전처리 과정으로 데이터분석에서 가장 많은 시간 및 노력을 투자해야 되는 단계
- Feature를 가공해서 만들고, 결측값 & 이상치를 어떻게 처리할지 고민하는 단계
- 유의미한 feature를 feature selection을 통해 골라서 사용
1.2.3. Modeling & Ensemble
- 데이터에 적합한 모델을 설계하는 과정
- 학습 모델에서 사용되는 하이퍼파라미터를 최적화함
1.2.4. Prediction
1.2.5. Evaluation
- 실제 정답과 모델의 예측값의 차이 정도를 통해 해당 모델이 잘 학습됐는지 평가하는 단계
-> 이때 과적합에 매우 매우 유의해야 함!!
1.2.6. Deployment
- 최종 모델을 선정한 뒤 실제로 사용될 수 있또록 상용화 체크 후 일정 간격으로 실시간 성능 체크 및 모니터링 진행하는 단계
1.3. 머신러닝 한계점
- 과적합 & 과도한 일반화로 인해 성능 향상 한계
- 도출 결과의 설명력 부족
- 대부분의 머신러닝 모델은 BlackBox모델이기 때문
- 기존 학습 모델의 재사용 어려움
- 법률 분야에서 학습된 모델을 다른 분야에서 적용 불가능
-
샘플링 잡음 및 편향 문제
-
모델 성능 악화
-
데이터 유출
2. 분류와 회귀
2.1. 분류
- 종속변수: 범주형 변수
- 예측결과가 이산값임. (종류 예측)
ex. 합격 여부, 메일 여부, 악성 종양 여부
2.2.회귀
- 종속변수: 양적 변수
- 예측결과가 연속성을 지님
ex. 시험점수 예측, 판매량 예측, 사망확률 예측
3. 과적합
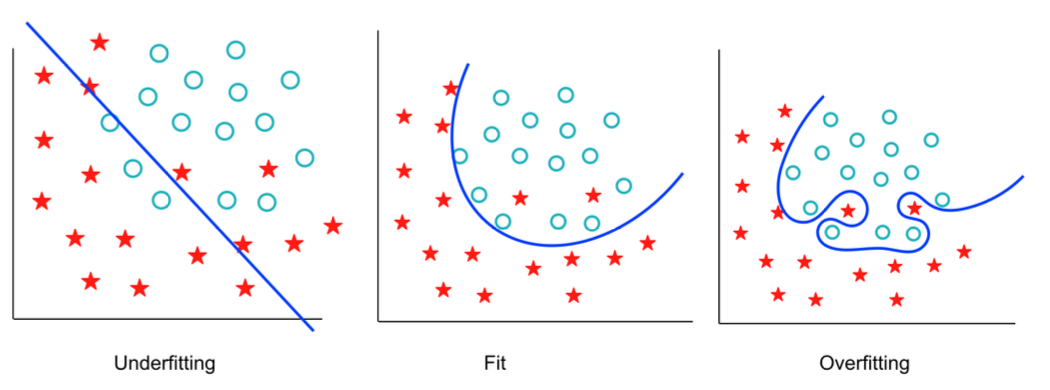
3.1. 과대적합
- 학습이 너무 잘 된 상태를 의미
- 학습 데이터를 너무 잘 학습하여 새로운 데이터에 대해서는 제대로 예측하지 못하는 것
원인
- 학습 할 샘플 데이터 수의 부족
- 풀고자 하는 문제에 대비 복잡한 모델을 사용
해결방법
- 데이터의 수를 늘려 모집단의 특성을 잘 반영한 데이터를 확보
- 풀고자 하는 문제에 대하여 적절한 모형을 선택
- 데이터 정규화, Dropout, 앙상블, 교차검증 등
3.2. 과소적합
- 모델이 너무 단순하여 학습 데이터조차 제대로 학습하지 못하는 것
- 데이터 내에 존재하는 규칙도 제대로 학습하지 못하는 상태
해결방법
- 모델 복잡도 증가
(과소적합은 데이터에 비해 모델이 가볍기 때문에 발생)
3.3. 편향-분산 Trade off
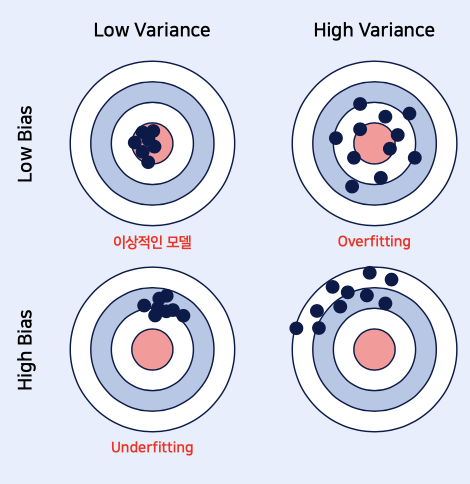
- Bias-Variance Trade off
Low Bias / Low Variance: 이상적인 모델
Low Bias / High Variance: Overfitting
High Bias / Low Variance: Underfitting
편향
- 예측값이 정답과 얼마나 멀리 떨어져 있는가
분산
- 예측값끼리의 차이
4. 교차검증
4.1. K-fold cross validation
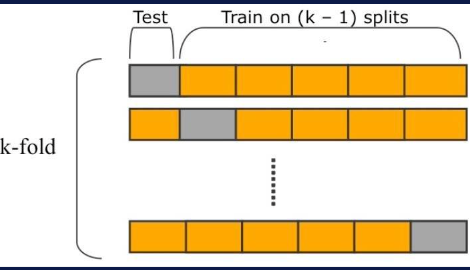
- 전체 데이터를 K개의 하나씩 test set으로 사용하고 나머지를 train set으로 사용하는 교차검증 방법
K-fold 단계
- 데이터 집합을 K개의 Fold로 나눔.
- 첫번째 Fold를 제외한 나머지 Fold 데이터를 합쳐서 학습 데이터로 사용하고, 첫번째 Fold를 검증 데이터로 사용
- 두번째 Fold를 검증 데이터로 사용하고, 두번째 Fold를 제외한 나머지 Fold 데이터를 학습 데이터로 활용
- 이를 K번 반복하면, 모든 데이터를 학습 데이터로서 사용하면서 검증 데이터로서 사용할 수 있음
-> 모든 Fold에서 가장 좋은 성능이 나오는 최적의 hyper-parameter 선정
장점
- 모든 데이터셋을 train set으로도, test set으로도 활용 가능함.
단점
- 여전히 데이터가 편향되어 있을 경우, 편향된 데이터가 분할되지 못하고 몰릴 수 있다는 단점이 있음.
-> 데이터를 일정한 간격으로 잘라 사용하기 때문에 target값이 편향되면 학습에 어려움.
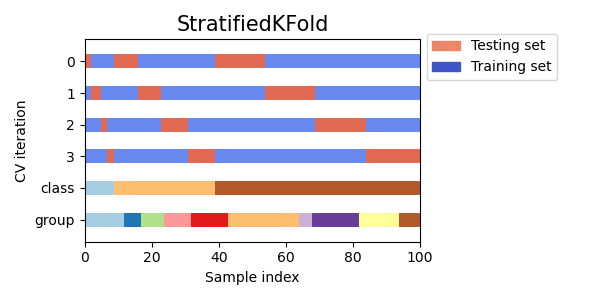
4.2. Stratified K-fold
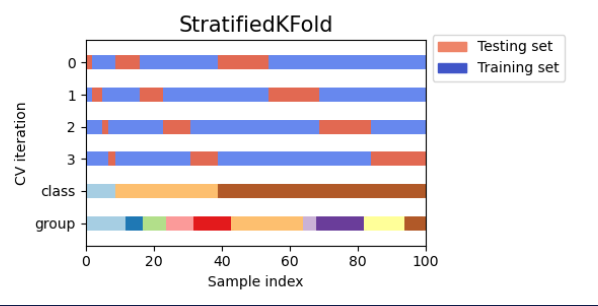
- K-fold의 단점을 보완하기 위해 target 속성값의 개수를 동일하게 하여 데이터가 한 곳으로 몰리는 것을 방지하는 교차검증 방법
-> 회귀의 경우 target값이 연속적이기 때문에 지원X
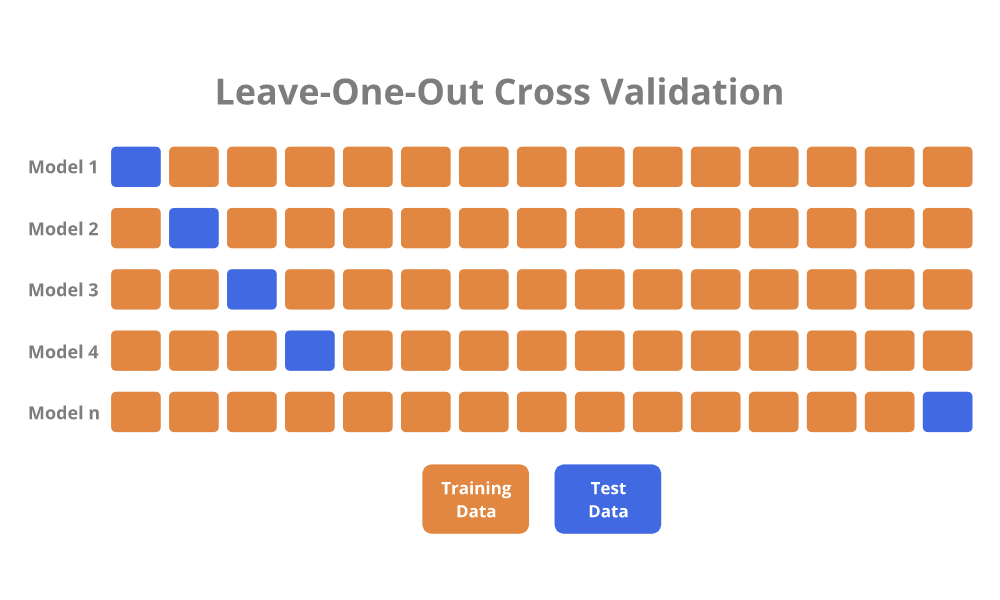
4.3. Leave-One-Out cross validation (LOOCV)
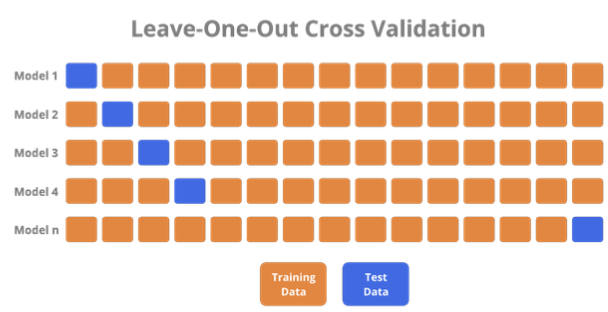
- 교차 검증을 극단적으로 사용한 것으로 n개의 데이터샘플에서 한 개의 데이터 샘플을 test set으로 함.
- 그 뒤 그 1개를 뺀 나머지를 train set으로 두고 모델을 검증하는 교차 검증 방법임
장점
- 훈련에 거의 데이터셋의 전부를 사용하기 때문에 모델 성능에 대해 신뢰 OK
- 편향되지 않은 추정치 제공
단점
- 계산 비용이 많이 듬.
4.4. Hold-Out cross validation
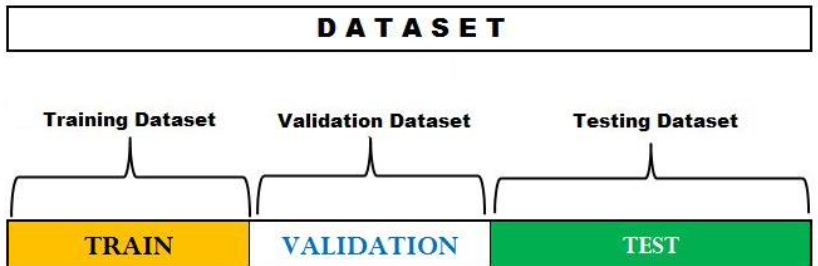
- 데이터셋을 train set / validation set / test set / 3개로 나눔
- train set으로 먼저 모델을 훈련시킨 뒤
- validation set으로 성능을 평가한 후
- test set을 이용하여 모델의 일반화 성능을 추정하는 교차 검증 방법
🎯 Summary
- 머신러닝 전체적인 과정 중 제일 중요한 부분은 Data Preprocessing과 문제 정의 부분이다.
이 두 부분을 중점으로 머신러닝 공부를 하면 좋을 것 같다!.
- 다양한 검증 방법을 공부할 수 있어서 Good
📚 References
{kind=link}
- Stratified K-fold: https://scikit-learn.org/stable/_images/sphx_glr_plot_cv_indices_009.png
{kind=link}
{kind=link}
- Hold Out: https://yandex.com/

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊