주제: Data Handling-pandas
파이썬 머신러닝 완벽 가이드[개정2판] pp.62-83 참고해서 내용 작성하였습니다.
0. Pandas 주요 데이터 타입
| 공통 데이터 형식 | Numpy/Pandas 객체 | Pandas 이름 | 설명 |
|---|---|---|---|
Boolean | np.bool | bool | 단일 바이트 |
Integer | np.int | int | 64비트 정수 |
Float | np.float | float | 64비트 소수 |
Complex | np.complex | complex | 복소수 |
Object | np.object | Object | 대게 문자열 |
Datetime | np.datetime64, pd.Timestamp | datetime64 | 나노초의 정밀도를 가진 시각 |
Timedelta | np.timedelta64, pd.Timedelta | datetime64 | 일부터 나노초 단위의 시간 간격 |
Categorical | np.Categorical | category | pandas에만 존재하는 범주형변수 |
1. Data Selection & Filtering & Sort
- Numpy의 Data Handling도 Selection 및 Filtering을 할 수 있음.
예를 들어, '[]' 연산자 내 단일값 추출 / 불린 인덱싱 / 슬라이싱
- df[1:3]
- 하지만 데이터 분석용으로 사용하기에는 편의성이 많이 떨어짐.
- pandas의 iloc와 loc 연산자를 통해 간편하게 활용할 수 있음.
1.1. DataFrame의 [] 연산자
- Numpy는 '[]' 연산자를 활용하여 슬라이싱 범위, 행&열의 위치를 지정해서 Data Selection 가능했음.
- Pandas에서는 '[]' 연산자를 칼럼만 지정할 수 있는 '칼럼 지정 연산자'로 생각하면 쉬움.
-> 예를 들어, DataFrame['칼럼1', '칼럼2', '칼럼3'] 으로 지정해야 됨.
tr_df[tr_df['Job']=='개발자'].head(5)정리하면
- DataFrame 바로 뒤의 [] 연산자는 Numpy의 []와 쓰임이 다름.
- DataFrame 바로 뒤의 []연산자 내 입력값에는 칼럼 or 불린 인덱스 용도로만 사용 가능함.
1.1. DataFrame iloc[ ] 연산자
- 위치 기반 인덱싱 방식임.
- 행과 열 위치를 0을 출발점으로 하고 가로축, 세로축 좌표 정수값으로 지정하는 방식임.
-> .iloc[] 연산자는 행과 열의 위치에 해당하는 값으로 슬라이싱, 정수형 값을 입력해줘야 함.
tr_df.iloc[9,29]| iloc[]연산 유형 | 반환 값 |
|---|---|
| tr_df.iloc[:] | 전체 DataFrame 반환 |
| tr_df.iloc[0:2, 1:4] | 슬라이싱 범위의 첫번째에서 두번째 행의 1:4 슬라이싱 범위의 두번째부터 네번째 열 범위에 해당하는 DataFrame 반환 |
- 자주 사용되는 표현은 아래 형태임.
-> 처음부터 맨 마지막 피처를 제외한 모든 피처값들을 가져오게 됨.
tr_df.iloc[:,-1]1.2. DataFrame loc[] 연산자
- 명칭 기반 인덱싱 방식
- DataFrame의 인덱스 값으로 행 위치를 / 칼럼의 명칭으로 열 위치를 지정하는 방식임.
tr_df.loc['인덱스 값', '칼럼명']
- 명칭 기반이기 때문에 숫자형을 사용할 수 없음. 그러므로 [] 연산자의 종료값은 -1이 아니라 종료값까지 포함하는 것임
| loc[]연산 유형 | 반환 값 |
|---|---|
| tr_df.loc[:] | 모든 데이터 값 |
| tr_df.loc['one':'five', 'Job':'개발자'] | 인덱스 값 one부터 five까지 행의 Job부터 개발자 컬럼까지의 DataFrame 반환 값 |
| tr_df.loc[tr_df.salary >= 300] | loc[]는 인덱싱이 가능해서 salary 칼럼의 값이 300 이상인 모든 데이터를 불린 인덱싱으로 추출 |
1.3. iolc[], loc[] 정리
1. iloc[]는 위치 기반 인덱싱이며 행과 열 위치 값을 지정해 원하는 데이터를 반환함
- 시작을 0부터 시작하여 좌표에만 의존하는 것
2. loc[]는 명칭 기반 인덱싱이며 행 위치에는 DataFrame 인덱스가 오고, 열 위치에는 Feature값들이 와서 원하는 데이터를 반환함.
- DataFrame의 인덱스 또는 칼럼명으로 접근 하는 것
- 슬라이싱을 '시작점':'종료점' 지정할 때 종료점이 -1이 아니라 종료점을 포함시킴.
3. 개별 또는 여러 값 전체를 추출한다고 하면 tr_df['job']와 같이 DataFrame['칼럼명]만으로 사용하는게 훨씬 좋음.
- 행, 열을 전체적으로 추출하려면 iloc[] or loc[]을 사용하는 것이 간편함.
1.4. Boolean 인덱싱
- iloc[], loc[] 연산자보다 Boolean 인덱싱을 더 많이 사용함.
- []내에 자신이 가져오고 싶은 조건을 입력하면 자동으로 원하는 값을 필터링함.
- and 조건일 때는 &
- or 조건일 때는 |
- Not 조건일 때는 ~
tr_df[(tr_df['salary'] > 500) & (tr_df['address']=='서울 성북구')]1.5. DataFrame, Series의 정렬 - sort_values()
sort_values()
주요 파라미터는
by
: 특정 칼럼을 입력하면 해당 칼럼으로 정렬을 수행함
ascending
-ascending=True로 설정하면 오름차순으로 정렬
-ascending=False로 설정하면 내림차순으로 정렬
-> Default 값은 ascending=True
inplace
-inplace=False로 설정하면 sort_values()를 호출한 DataFrame은 그대로 유지하며 정렬된 DataFrame으로 반환
-inplace=True로 설정하면 호출한 DataFrame의 정렬결과를 그대로 적용함
-> Default 값은 inplace=False
tr_df_sorted = tr_df.sort_values(by=['salary, 'Job'], ascending=False)2. 함수
| method | 인수 | return |
|---|---|---|
| map | Series | Series |
| apply | Series, DataFrame | Series, DataFrame |
| applymap | DataFrame | DataFrame |
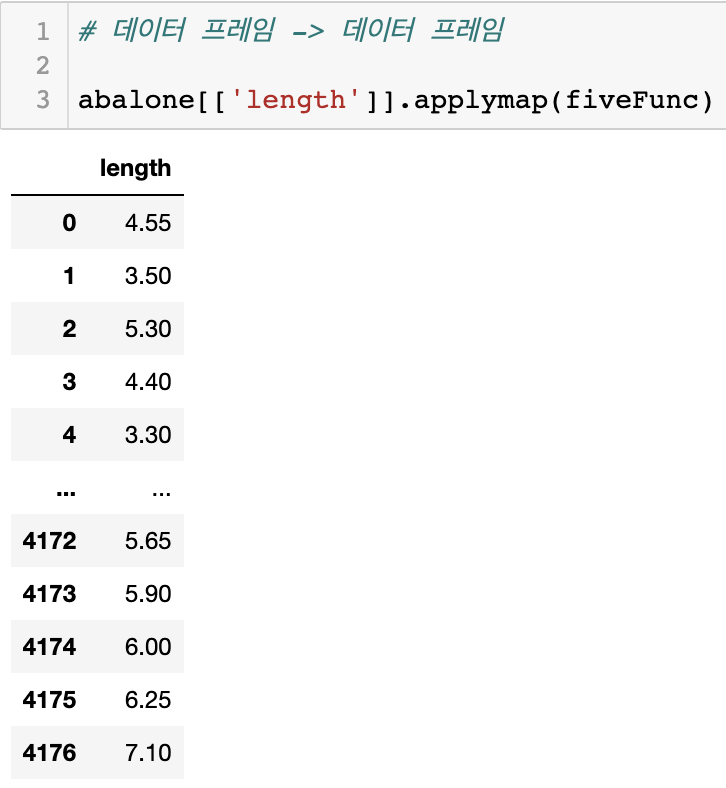
# 사용할 함수 정의
def fiveFunc(x):
return x*52.1. map
- DataFrame의 특정 열에만 적용 가능함 (Series)
-> DataFrame 적용시 에러 발생
- 1차원 배열값에 대해 자신이 만든 함수를 적용하여 1차원 배열로 출력할 수 있음

2.2. apply
- DataFrame
- 특정 열에 대해 적용
2.3. applymap
- 오직 DataFrame에만 적용 가능함
2.4. apply lambda
- apply함수에 lambda식을 결합하여 DataFrame / Series 형태로 제공 가능
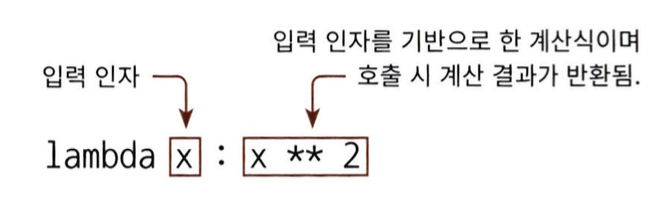
lambda x: x**2에서 ':'로 입력 인자와 반환될 입력 인자의 계산식을 분리함.
- : 왼쪽에 있는 x는 입력 인자를 가리킴.
- : 오른쪽은 입력 인자의 계산식을 의미하며 반환 값임.
- Pandas DataFrame의 lambda 식을 적용해보면
titanic_df['Child_Adult'] = titanic_df['Age].apply(lambda x: 'Child' if x <=15 else 'Adult')
titanic_df[['Age', 'Child_Adult']].head(8) 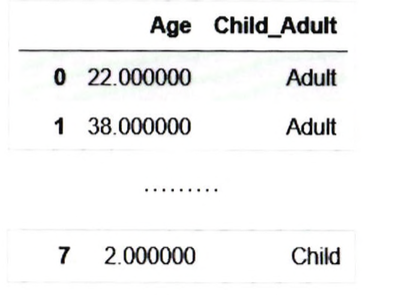
- 위의 식과 같이 lambda 식은 if & else을 지원함.
- 이때 주의할 점은 if식보다 반환 값을 먼저 기술해야 함.
-> lambda식 : 오른쪽에 반환 값이 있어야 하기 때문
- if,else만 지원하고 else if는 지원하지 않음.
- 이때 주의할 점은 if식보다 반환 값을 먼저 기술해야 함.
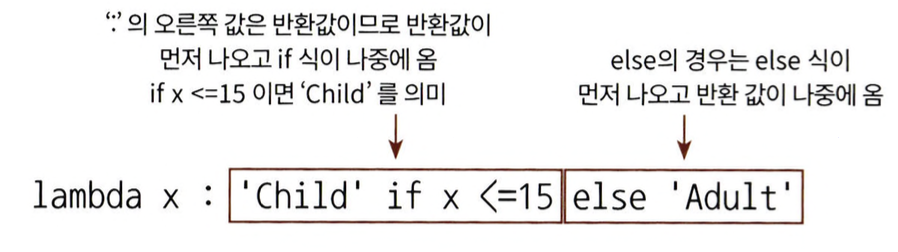
- 만약 else if를 사용하기 위해서는 else절을 ()로 내표해서 ()내에서 다시 if else를 적용해야 됨.
-> 나이가 15세 이하면, Child,
-> 15~60세 사이면, Adult,
-> 61세 이상은 Elderly
라는 Feature를 생성해보면?
titanic_df['Age_cat]
= titanic_df['Age'].apply(lambda x: 'child' if x<=15 else (
'Adult' if x <= 60 else 'Elderly'))
titanic_df[/Age_cat].value_counts()
- 하지만 조건이 많아질수록 else if를 사용하는 것은 아무래도 부담스러움.
- 그래서 별도의 함수를 만들어서 lambda에 집어넣는 방법이 있음.
def get_category(age):
cat= ''
if age <=5: cat='baby'
elif age <=12: cat ='Child'
elif age <=18: cat = 'Teenager'
elif age <= 25: cat = 'Student'
elif age <= 35: cat = 'Ypimg Adult'
else: cat = 'Elderly'
return cat# lambda 식에 위에서 생성한 함수를 반환값으로 지정함
titanic_df['Age_cat] = titanic_df['Age].apply(lambda x: get_category(x))
titanic_df[['Age', 'Age_cat']].head()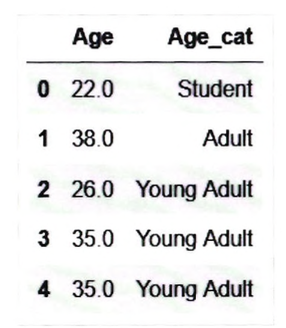
3. Groupby
- 집단, 그룹별로 데이터를 집계 및 요약하는 방법을 의미함
Split -> Apply Function -> Combine
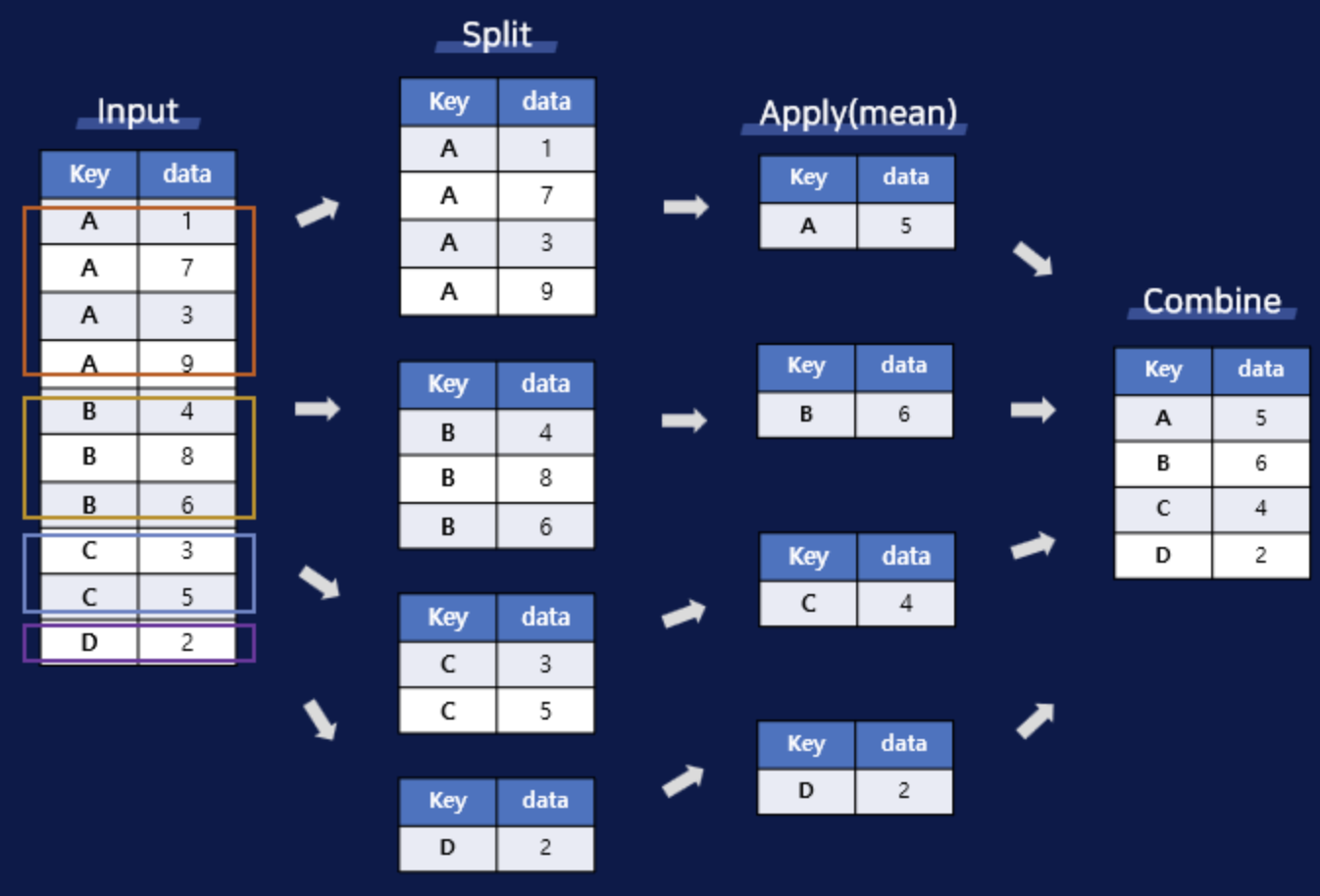
groupby() - split
for k,v in abalone.iloc[:,:5].groupby(abalone['sex']):
print('key: ', k)
print('number: ', len(v))
print(v)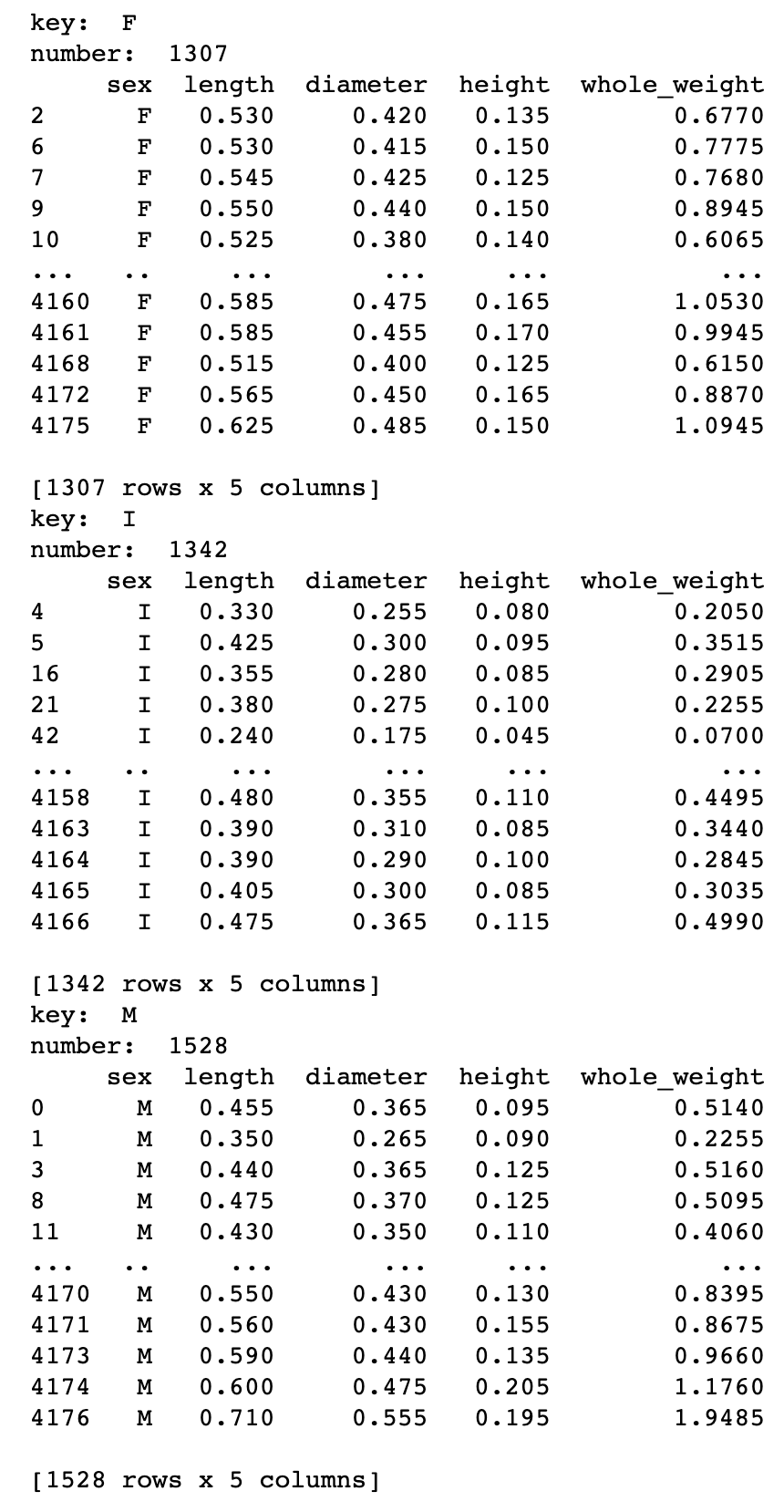
get_group()
- 그룹 안에 데이터를 확인하고 싶을 때 사용
abalone.iloc[:,:5].groupby('sex).get_group('M)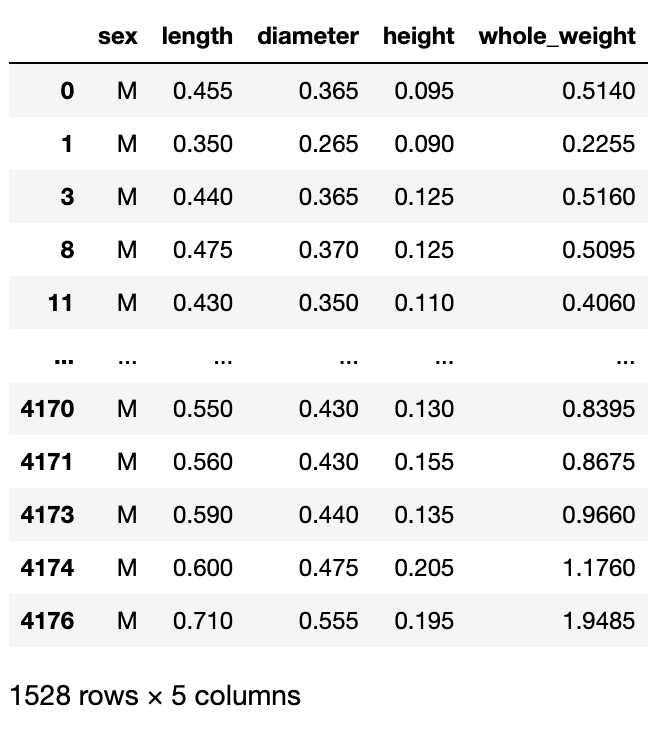
3.1. 집계함수
df.groupby('key')['column'].집계함수
- 여기서 집계함수란 sum, mean, max, min, size, count 등을 의미함
abalone.groupby('sex')[['length','rings']].sum()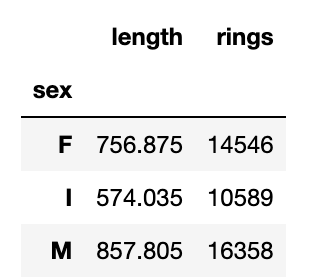
abalone.groupby('sex')[['height', 'diameter']].max()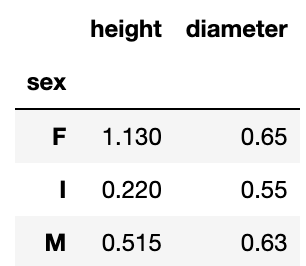
3.2. filter
df.groupby('key').filter(조건식함수)
- Group의 속성을 기준으로 Data를 Filtering할 때 사용
🤜 Input
abalone['rings'].mean()🖥️ Output
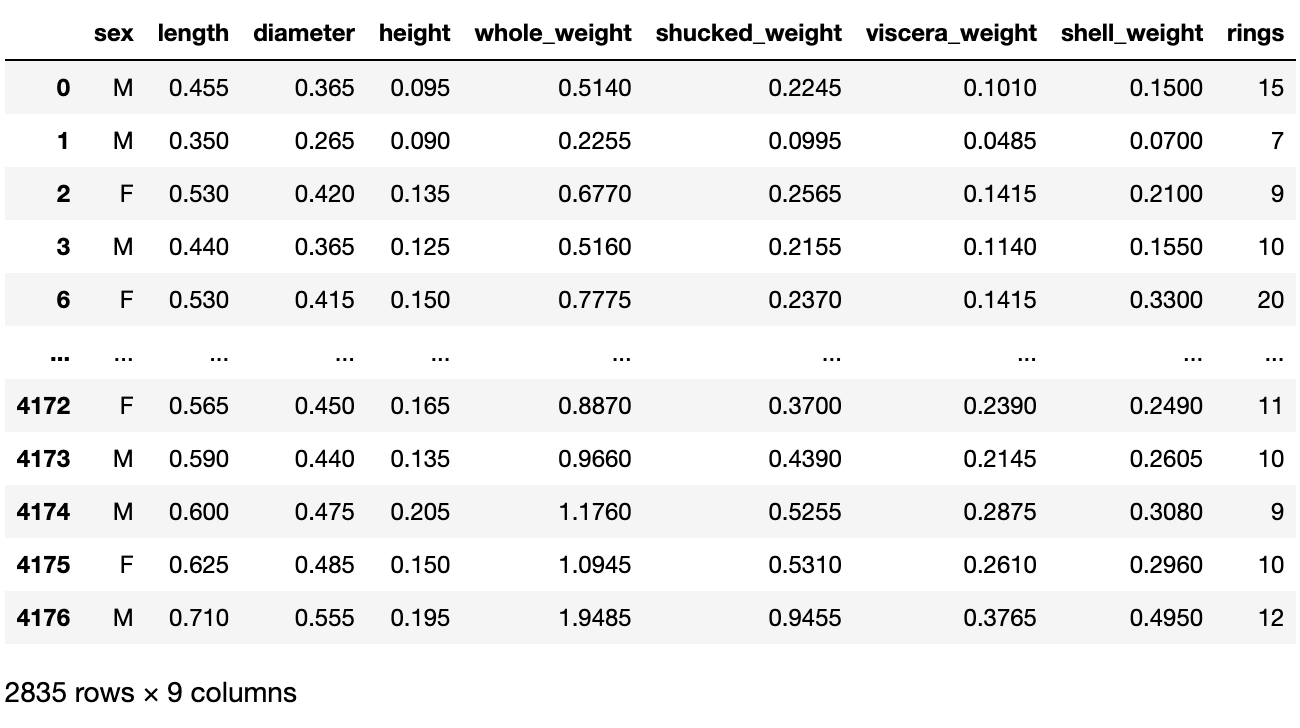
9.933684462532918🤜 Input
def filter_mean(x):
return x['rings'].mean() > 9.933684462532918🤜 Input
dabalone.groupby('sex').filter(filter_mean)🖥️ Output
3.3. agg
df.groupby('key')['column].agg(매핑함수)
df.gorupby('key')['column'].aggregate(매핑함수)
- 여러 개의 통계함수를 적용하고 싶을 때 사용
🤜 Input
abalone.groupby('sex')['whole_weight'].agg([('sex_총whole_weight', np.sum),
('sex_평균whole_weight', np.mean),
('sex_최소whole_weight', np.min),
('sex_최대whole_weight', np.max),
('sex_표준편차whoe_weight', np.std)]) 🖥️ Output

3.4. apply
df.groupby('key')['column'].apply(매핑함수)
- lambda 표현식을 사용할 수 있음
🤜 Input
abalone.groupby('sex')[['rings']].apply(lambda x: x.rings.min())🖥️ Output

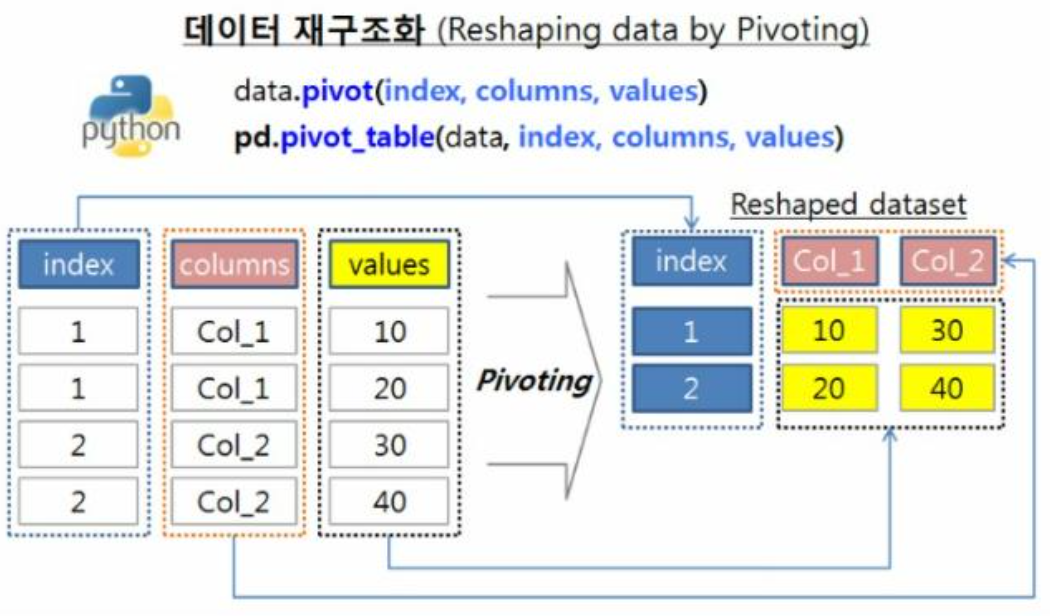
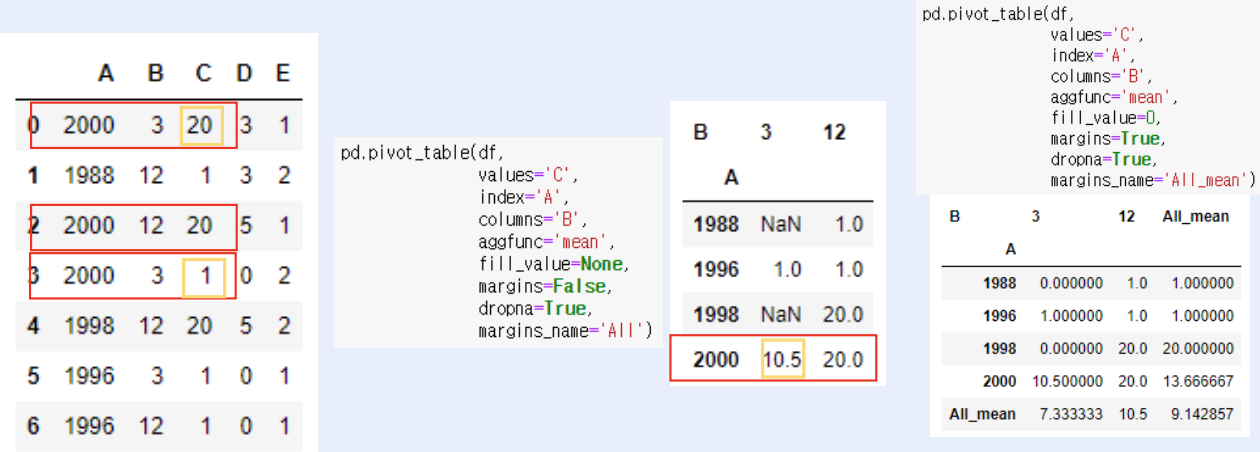
4. Pivot_table
4.1. pivot
- Pivot이란 데이터 테이블을 재비치하고 구조를 변경하는 것
- 엑셀의 Pivot table과 매우 유사하며 이는 그래프, 테이블 요약 그리고 Group 연산을 위해 사용됨

- index: index로 사용될 컬럼
- columns: column으로 사용될 컬럼
- values: value에 채우고자 하는 컬럼
4.2. pivot_table
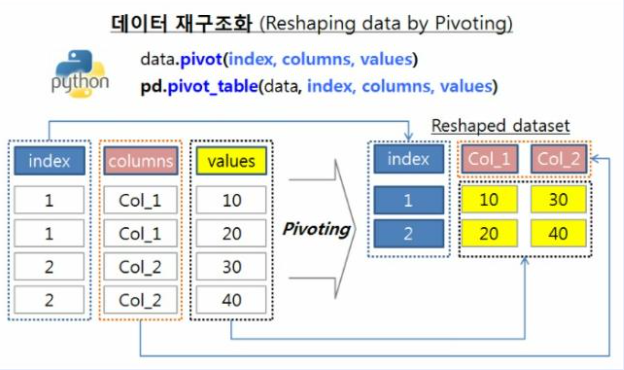
- pivot table이란 데이터의 요약된 정보를 출력해주는 것

🤜 Input
df.pivot_table(values='C',
index='A',
columns='B',
aggfunc='mean',
fill_value=None,
margins=False,
dropna=True,
margins_name='All')🖥️ Output
5. Crosstab
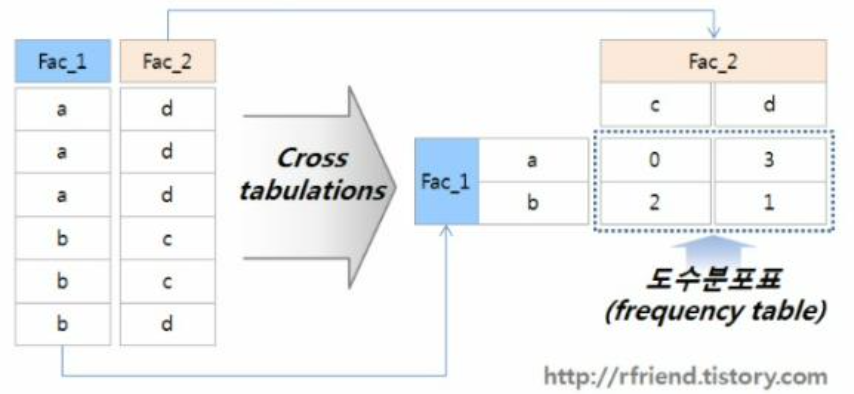
- Categorical Feature를 기준으로 개수 파악 또는 Numerical Feature를 넣어 계산할 때 사용
- pivot_table과 많이 유사하고, pivot_table의 특수한 형태임.
- 두 column의 교차 빈도, 덧셈, 비율 등을 구할 때 사용됨.

🤜 Input
pd.crosstab(values=df['score'],
index=df['B'],
columns=df['C'],
aggfunc='mean')🖥️ Output

6. 정리
| 사용이유 | |
|---|---|
| groupby | 특정 컬럼을 기준으로 그룹화하여 테이블에 존재하는 행들을 그룹별로 구분하기 위해 |
| pivot_table | 다양한 요소들을 활용해 데이터를 빠르게 분석하기 위함 |
| crosstab | 두 컬럼의 교차 빈도, 덧셈, 비율 등을 구할 때 사용 |
🎯 Summary
- apply lambda 부분의 핵심은
lambda x**4:을 기준으로 오른쪽 값이 반환값이라는 것이다. If절에서도 먼저 반환 값이 나오고 그 다음에 if절이 시작된다는 점을 유의하자!
- 사실 지금까지 데이터분석하면서 제일 사용했던 것은
groupy('key')['column'].agg(매핑함수)였다. 이렇게 한번 정리를 하고나니 확실히 기억에 오래 남는거같다. 그리고 이제는 함수를 잘 만들어서 apply lambda에 적용함으로써 메모리 사용량도 신경쓰면서 하는 데이터분석가 되겠다! 오늘의 정리 끝!
📚 References
- 권철민(2019),'파이썬 머신러닝 완벽 가이드[개정2판]', 위키북스, pp.62-83.

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊