(Youtube) NLP 논문 리뷰📎 RoBERTa(2019) : A Robustly Optimized BERT Pretraining Approach 를 참고해주세요!!!!
Title
- RoBERTa: A Robustly Optimized BERT Pretraining Approach

1. Introduction
1.1. 논문이 다루는 Task
- BERT 모델이 downstream task에서 더 나은 성능을 이끌어내는 pretraining 전략 제시
- 새로운 데이터 셋인 CC-News를 사용하고, 사전학습에 더 많은 데이터를 사용하는 것이 downstream task의 성능을 향상 시킴
- BERT의 Replication Study를 통해 하이퍼파라미터의 영향과 학습데이터셋의영향을 보여주는 논문임 -> BERT를 개선한 모델, RoBERTa
1.2. 기존 연구 한계점
- Self-training method의 어떤 측면이 좋은 성능을 내는지 특정하기 어려움
- 학습 비용이 높기 때문에 실제로 해볼 수 있는 튜닝 횟수는 제한적
- BERT 모델이 아직 undertrain 되었고, hyper parameter을 어떤 값을 선택하느냐에 따라 결과값에 매우 큰 차이가 있다는 것을 실험을 통해 알아냄
2. Related Work
BERT Model
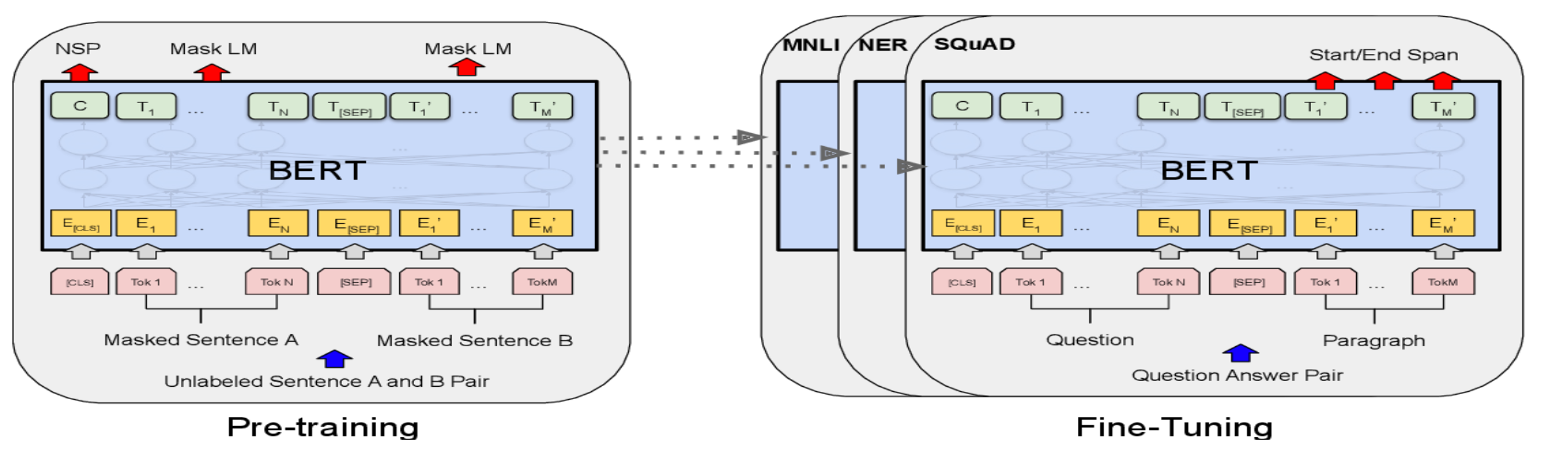
- 2개 Segment X,Y를 연결 -> [SEP] Token으로 구분한 Input을 받음
- [CLS], 𝑥(1, ) 𝑥(2, )… , 𝑥𝑁, … , [SEP], … , 𝑦_1, 𝑦_2, … , 𝑦𝑀, [EOS]
- BERT는 학습 속도 개선을 위해 초반 90% steps 길이 128로 제한
-> RoBERTa는 일정하게 T로 맞춤
Training Objectives
🎈 Masked Language Model (MLM)
- 목표: 마스킹 된 Token이 무엇인지 예측
🎈 Static Masking
- BERT는 Input Sequence Token의 15%를 pre-processing 단계에서 선택
- 선택된 Token 중 80% special Token [MASK]로 교체, 10% 그대로, 10% random Token
- 한 번 선택된 마스킹 구성으로 pre-training 내내 학습되지 않도록, 데이터를 복제해서 다르게 마스킹
- RoBERTa는 더 자주 마스킹을 다르게 해주면 유리하지 않을까??라는 가정 (Dynamic)
🎈 Next Sentence Prediction (NSP)
-
목표: Input으로 받은 2개 segment X, Y가 연속된 문장인지 여부 판단
-
두 문장 관계를 이해한 모델이 QA, NLI Task에서 더 나은 성능을 보였음
- RoBERTa는 충분히 잘 학습된 BERT 모델은 여전히 NSP를 필요로 할까?? 라는 가정 (삭제함)
3. 제안 방법론
3.1. Main Idea
- BERT 모델은 under-trained 되었으므로, 구조는 그대로 두고 downstream task에서 더 나은 성능을 이끌어 낼 parameter 설정 & pretraining 전략 제시
-
BERT 모델에 대한 수정사항
🎈 (1) 더 많은 데이터로 모델을 더 길고, 더 큰 batch size로 학습 🎈 (2) Next-Sentence Prediction Objective를 삭제 🎈 (3) 일정하게 긴 시퀀스의 데이터로 학습 🎈 (4) 학습 데이터에 동적 마스킹 패턴을 사용
3.2. Contribution
(1) 동적 마스킹 (Dynamic masking)
(2) Next-Sentence Prediction Loss를 사용하지 않는 FULL-SENTENCE: Only MLM Task
(3) 큰 미니 배치 (Mini-batches)
(4) Larger byte-level BPE 사용
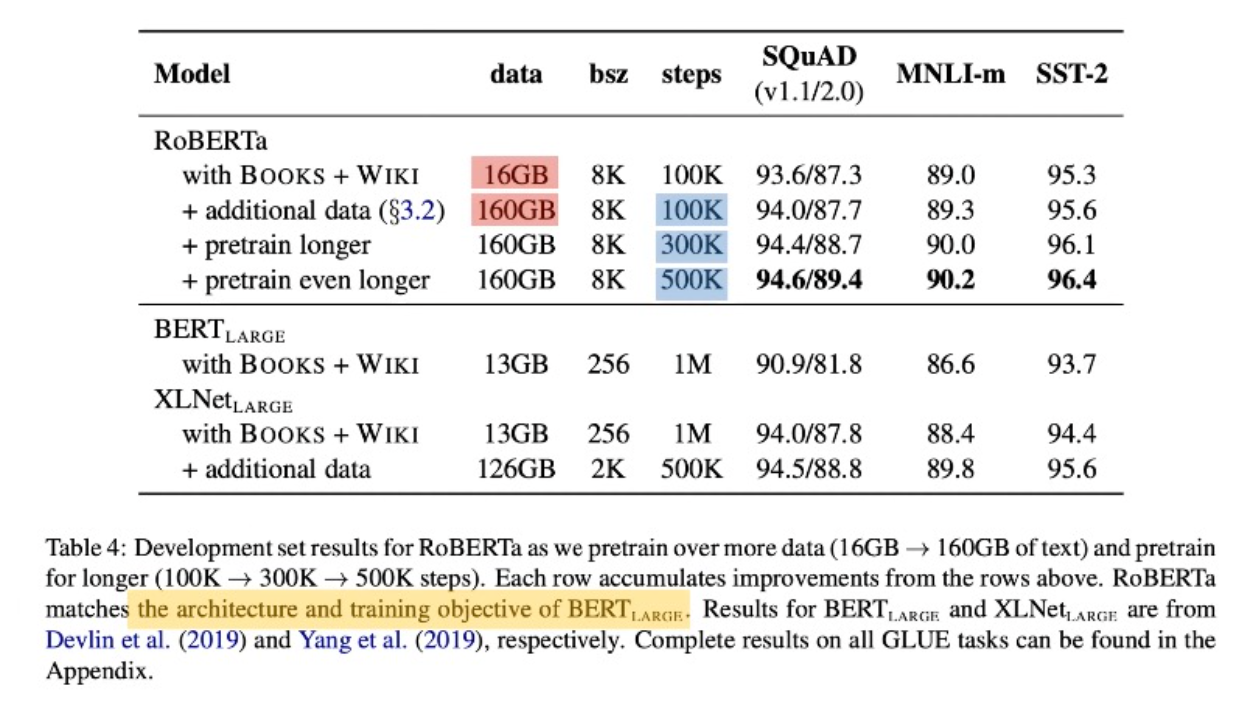
(5) Pretraining에 사용된 데이터: BERT(16GB) -> RoBERTa(160GB)
4. 실험 및 결과
4.1. Dataset
- Pretrain Data
🎈 BookCorpus + English WIKIPEDIA, 16GM
🎈 CC-NEWS (from CommonCrawl), 76GB
🎈 OPEN WEB TEXT, 38GB
🎈 STORIES, 31GB
- Data
🎈 GLUE (자연어 이해 성능 평가를 위한 9가지 데이터셋 조합)
🎈 SQuAD V1.1, V2.0 (지문과 질문쌍이 주어지고 질문에 답하는 문제)
🎈 RACE (중국 중고등 학생의 4지선다형 영어 시험)
4.2. Baseline
a. Next-Sentence Prediction Loss를 사용하지 않는 FULL-SENTENCE: Only MLM Task
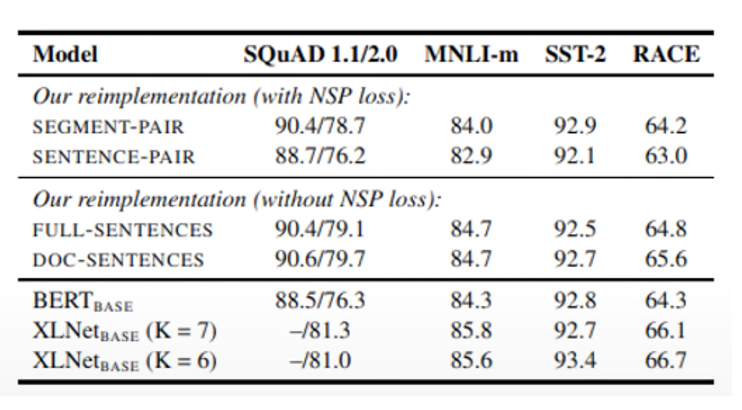
- Sentence-pair을 사용하는 경우 downstream task에서 성능이 안좋아짐
- 기존 BERT에서 NSP는 매우 중요했음. 하지만 NSP Loss를 제거하고 문장 길이를 채워서 input으로 넣는 것만으로도 NSP보다 더 높은 성능을 보임
- NSP를 제거한 경우 Doc-Sentence > Full-Sentence
🎈 Batch size를 다양하게 조절해야 하기 때문에 다른 모델과의 비교를 위해Full-Sentence사용
b. 큰 미니 배치 (Mini-batches)
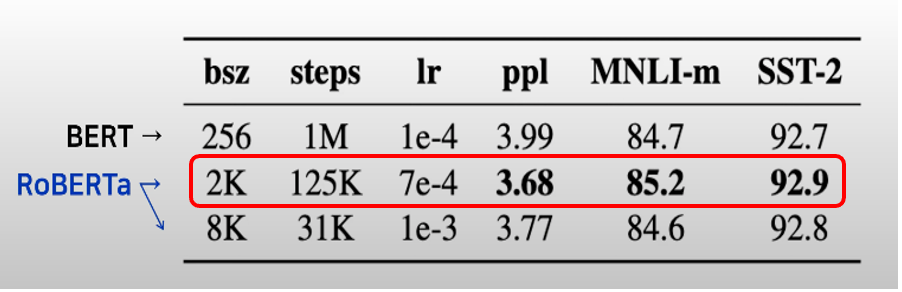
- Mini Batch Size를 크게 함으로 Perplexity & Accuracy 향상
- Bath Size를 2K로 했을 때 가장 좋은 성능을 보임
4.3. 결과
- BERT를 사전 학습할 때의 고려할 수 있는 design 요소에 대해서 평가함
- 모델 성능을 향상 시키는 방법으로
(1) 더 많은 데이터로 모델을 더 길고, 더 큰 batch size로 학습
(2) Next-Sentence Prediction Objective를 삭제
(3) 일정하게 긴 시퀀스의 데이터로 학습
(4) 학습 데이터에 동적 마스킹 패턴을 사용
4.4. 결론 (배운점)
- RoBERTa 모델은 parameter 설정 및 pretraining 전략만으로 성능이 좋아졌다. 간단하고 쉬운 방법이지만 이에 따른 컴퓨팅 환경이 뒷받침 해줘야 한다. 딥러닝을 하면 할수록 컴퓨팅 환경에 대한 중요성을 느끼게 된다. 서버 환경 및 Local 환경이 좋지 않게 되면 좋은 성능을 기대하기 어렵다. 이러한 한계점을 인정한다. 그렇다면, 내가 어떻게 하면 인공지능 시대에 살아남을 수 있을까..? 수학 공부를 함으로써 수식은 복잡하지만 코드를 단순화하는 작업을 하자!
📚 References

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊