
(Youtube) NLP 논문 리뷰📎 ELMo(2018) : Deep contextualized word repesentations 를 참고해주세요!!!!
Title
- ELMO: Deep contextualized word representations

1. Introduction
1.1. 논문이 다루는 Task

- ELMO(Embeddidngs from Language Model)는 2018년에 제안된
새로운 워드 임베딩 방법론
- Deep-Contextualized 임베딩을 통해 각 단어의 다양한 특징과 의미를 표현 가능
- 6개의 NLP Task에서 SOTA 달성
1.2. 기존 연구 한계점

- 기존의 Word Representation 방법에서는 각각의 단어는 하나의 벡터로 표현됨
- 복잡한 언어의 특성, 언어적 맥락 등 문제점
2. Related Work

Static Representation
- Word2Vec, GloVe
- 하나의 단어는 single vector로 존재함
- 단어를 나타내는 vector는 변하지 않음
Contextual Representation
-
ELMO, BERT, GPT
-
문맥에 따라 하나의 단어는 여러 개의 vector를 가질 수 있음
- 다의어의 경우 Static Representation보다 유연하게 Text 표현 가능
- Downstream Task에서 좋은 성능ㅇ을 보임
3. 제안 방법론
3.1. Main Idea
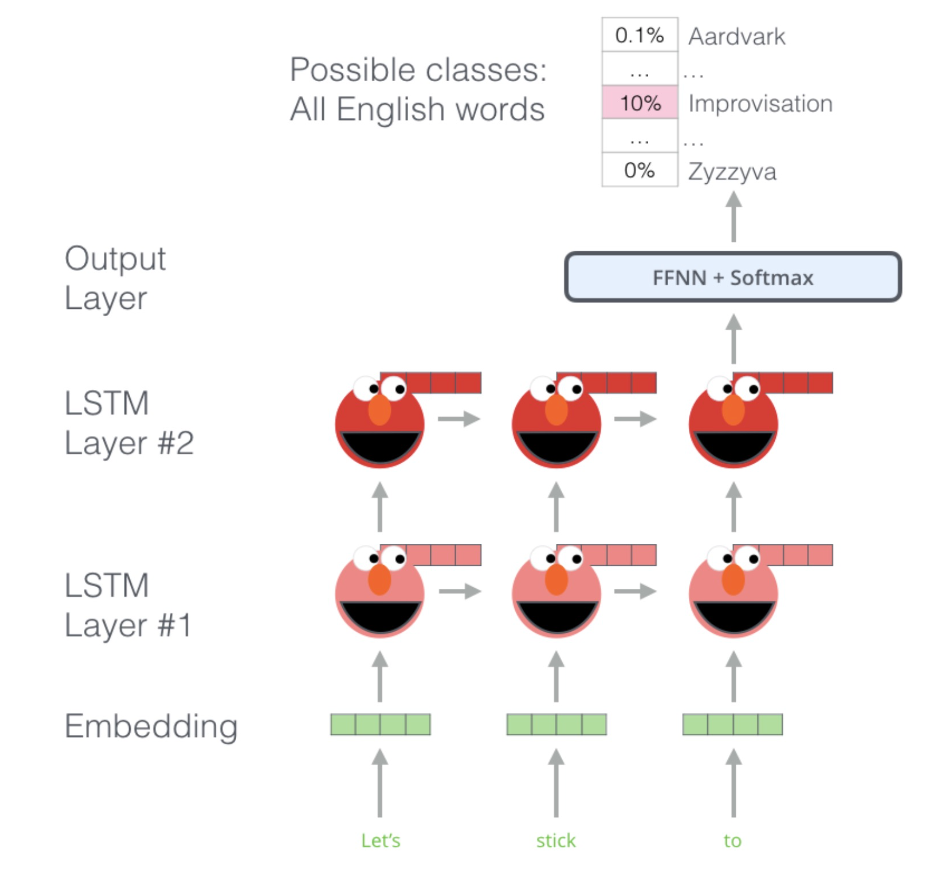
- Large Text Corpus로 BiLSTM 두 가지 LSTM의 벡터들을 결합하여 더 deep하게 문장 단위로 임베딩 진행
- 2가지 LSTM들이 앞뒤 문맥을 파악하고 같은 위치의 Layer끼리 결합
- BiLSTM Layer들의 representation을 선형결합하는 방법으로 각각의 단어를 표현
- LSTM의 Input과 가까운 Layer는 품사 등 문법 정보를, Output과 가까운 Layer는 문맥 정보를 학습하는 경향이 있고, Layer에 weight를 두어 각 task에 맞춰서 적절한 학습 가능
a. Forward LM
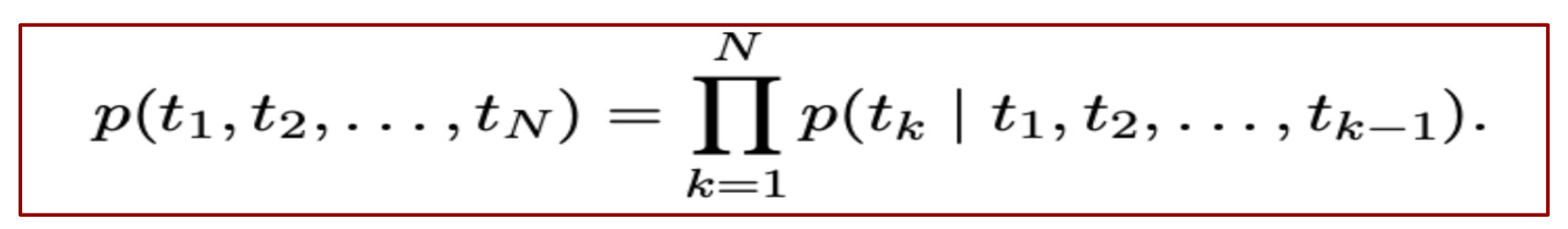
- 현재 Token을 기준으로 다음 Token이 나올 확률을 예측하는 모델
b. Backward LM
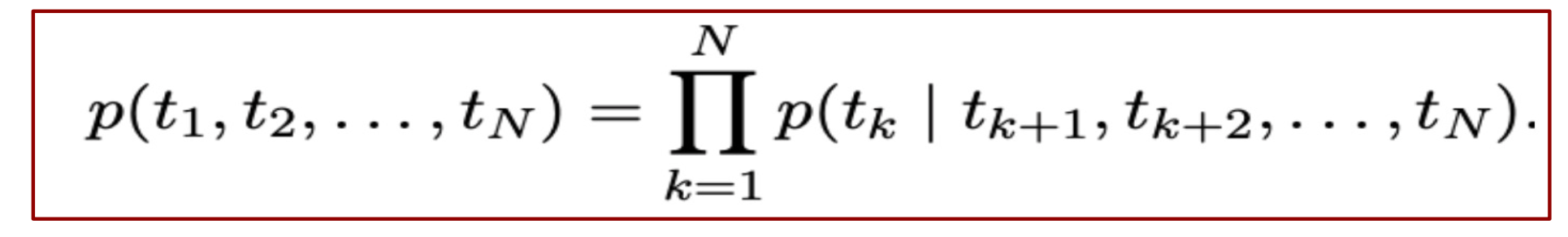
- 현재 Token을 기준으로 이전 Token을 예측하는 모델
c. BiLM 학습
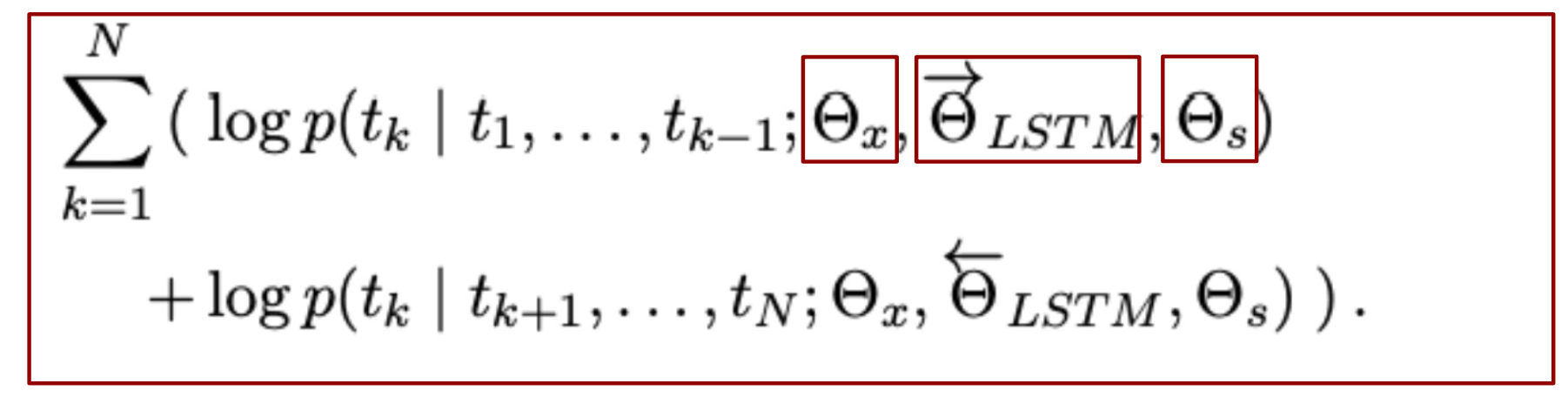
- 본 논문에 목적은 두 Forward, Backward의 각 파라미터를 별도로 유지하면서 두 방향의 Log Likelihood를
최대화시키는방법으로 학습
- 두 파라미터가 서로 완전히 독립적이지 않고 weights들을 공유함
d. ELMO
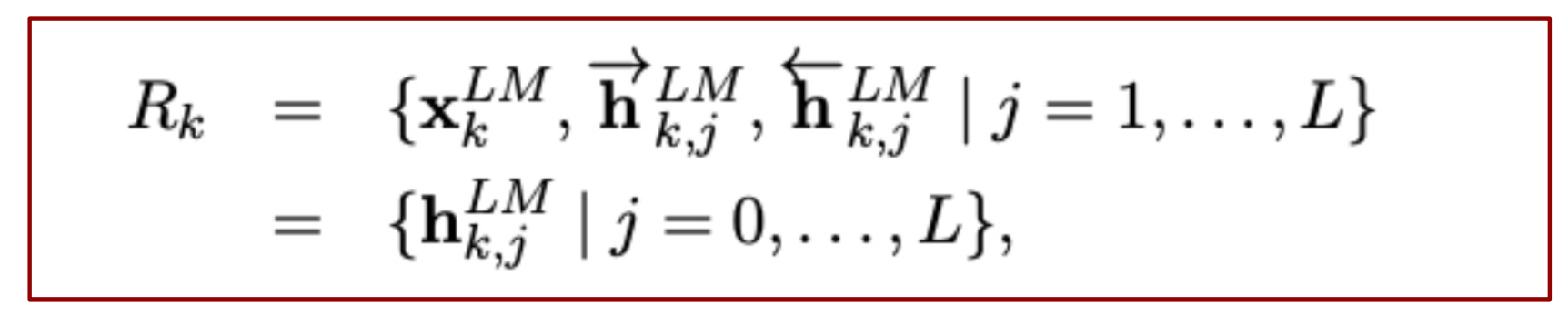
- BiLM의 중간 층들의 Representation들의 결합한 수식

- 최종적으로, 모든 층에서 생성한 Representation을 결합해서 하나의 벡터로 생성
e. ELMO가 임베딩 벡터를 얻는 과정
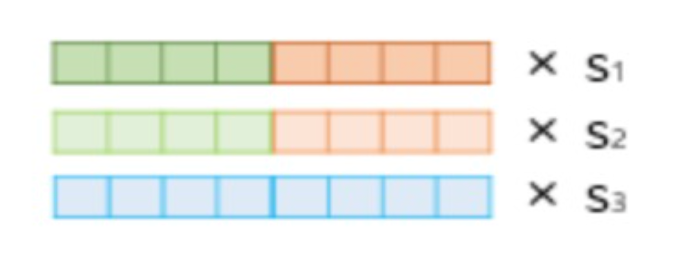
1) 각 층의 출력값을 연결 (concatenate)
2) 각 층의 출력값 별로 가중치를 줌
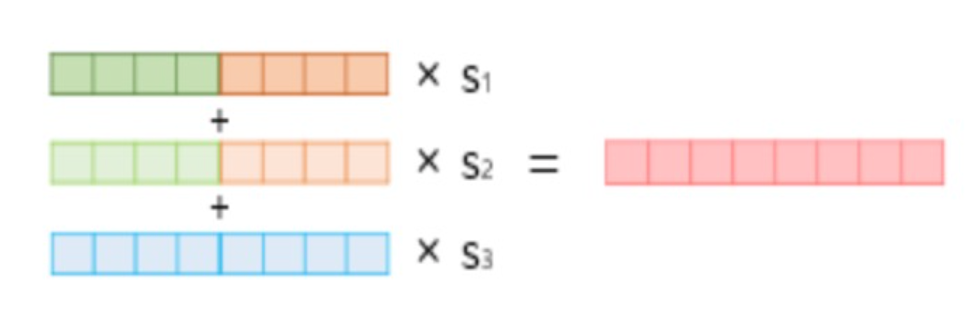
3) 각 층의 출력값을 모두 더하기 (2,3번 단계를 요약하여
Weighted Sum)
4) 벡터의 크기를 결정하는 스칼라 매개변수를 곱하기

3.2. Contribution
- 기존의 Word 단위가 아닌 Context 단위로 임베딩을 진행
- 2가지 LSTM들의 벡터들의 Representation을 선형결합하고 Layer에 weight를 두어 각 task에 맞춰서 적절힌 학습 가능하게 함
4. 실험 및 결과
4.1. Dataset
- Setting
🎈 L = 2 / 각 층은 4096개 unit / dimension = 512
🎈 문맥을 고려하지 않은 임베딩은 2048 character n-gram convolution filter + 2개의 hightway layer 추가 사용
🎈 첫 번째 층과 두 번째 층의 Residual Connection으로 연결
🎈 최종적으로 512 차원의 출력 제공
- 총 6개의 NLP Dataset(Task)
🎈 SQuAD
🎈 SNLI
🎈 SRL
🎈 Coref
🎈 NER
🎈 SST-5
4.2. Baseline
Result 1

- 총 6개의 NLP Task에서 ELMO를 적용한 결과를 보여줌
- Task에 따라 다른 metric이 사용되었지만, 모든 분야에서 SOTA 달성
Result 2
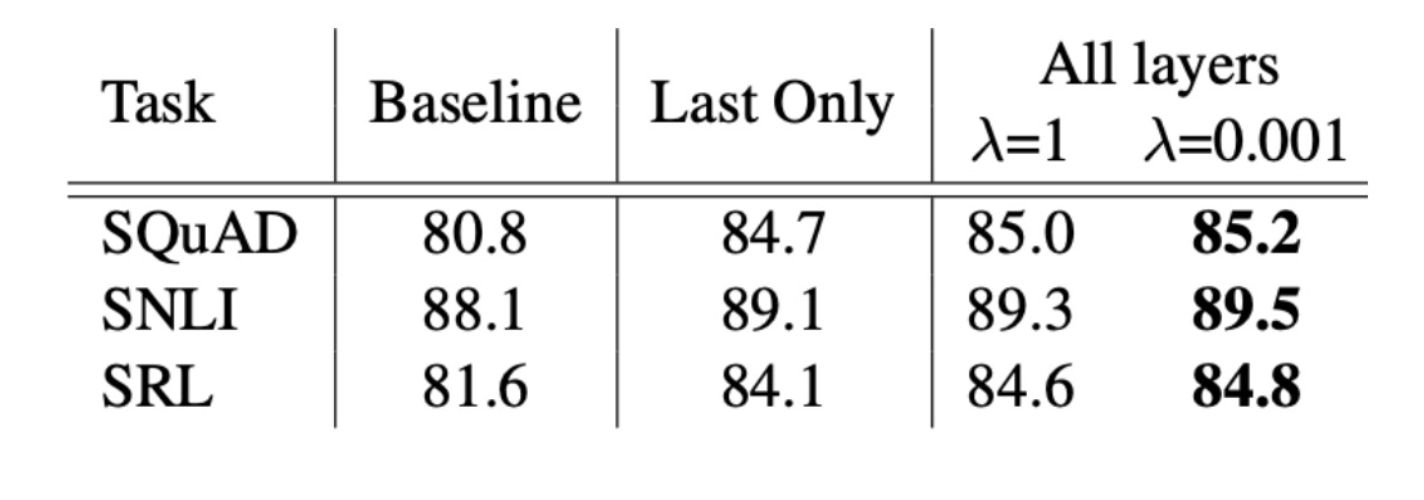
- Regularization Parameter Lambda에 성능 비교
- 모든 BiLM Layer를 사용하여 ELMO를 표현하고 적절한 lambda를 적용하였을 때 가장 좋음
Result 3

- ELMO Representation이 추가되는 위치에 따른 성능 비교
-
Input Only, Input & Output, Output Only 3가지 비교
-
결과가 일치되지는 않았지만, 대체로 입출력에 모두 ELMO를 적용한 모델 성능이 좋았음
- Task별로 ELMO Representation이 필요한 위치가 다름을 직관적으로 알 수 있음
Result 4

- Play 단어에 대한 GloVe와 BiLM의 Representation Vector를 통하여 유사한 단어들을 확인 결과
- GloVe의 결과 -> 스포츠 관련된 단어들
- BiLM의 결과 -> 각각 다른 문맥에서 주어진 play와 의미가 일치하는 유사한 단어 추천
Result 5
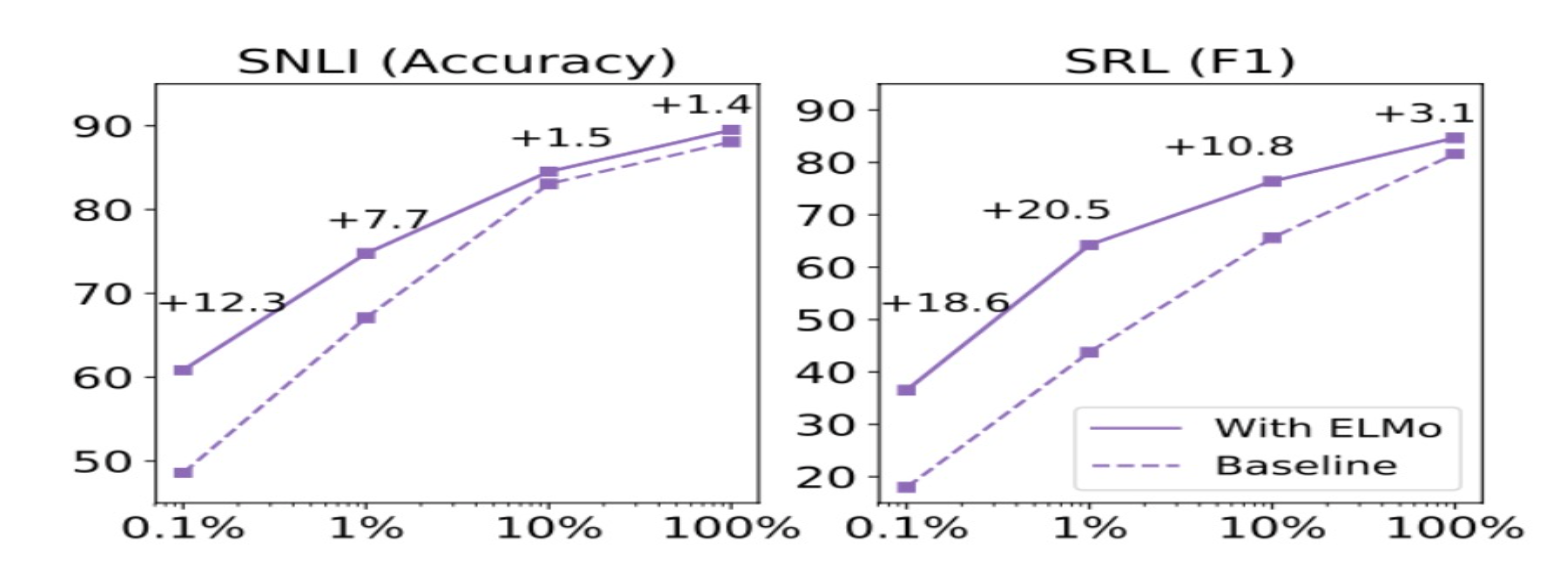
- Train set의 크기와 샘플링 효율성 따른 성능 비교
- ELMo 없이 기존 모델은 486 epochs 최고 성능 <-> ELMo 적용 모델 10 epochs 최고 성능
- 학습 데이터가 작을수록 ELMo를 사용하면 더 효율적인 학습 가능함
Result 6
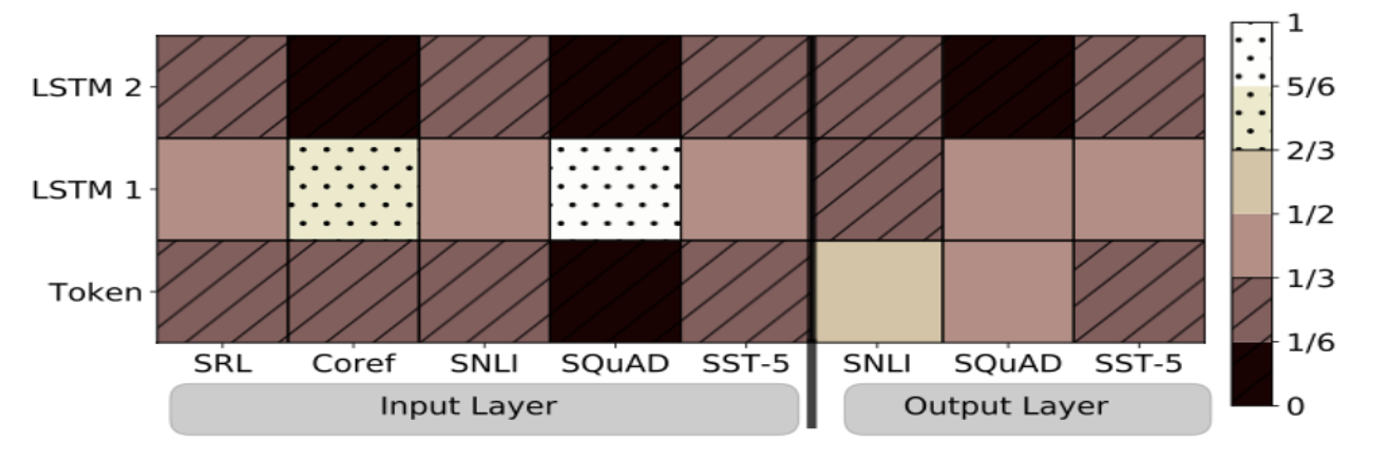
- Input Layer와 Output Layer가 더 높은 가중치를 두는 BiLM Layer를 확인하기 위한 시각화 결과
- Input Layer -> 첫번째 Layer에 높은 가중치를 둠
- Output Layer -> 모든 Layer에 균형적인 가중치를 둠
4.3. 결과
- 기존 word 단위가 아닌 context 단위로 임베딩을 한 ELMo를 적용한 것은 여러 가지 NLP Task에서 큰 향상을 보임
- BiLM의 hidden layer를 선형결합하고, 각 층은 서로 다른 문법/문맥 등의 특징들을 학습하기 때문에, 모든 층을 사용해서 Representation을 생성함으로써 Task 성능을 향상시킴
4.4. 결론 (배운점)
- Hidden Layer를 선형결합하고 모든 층을 사용해서 Representation 생성은 좋은 성능을 나타낸다는 것을 알 수 있음
- Context 단위의 임베딩은 very good
📚 References

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊