
(Youtube) NLP 논문 리뷰📎 GPT-3 : Language Models are Few-Shot Learners
를 참고해주세요!!!!
Title
- GPT3: Language Models are Few-Shot Learners (2020)

1. Introduction
1.1. 논문이 다루는 Task

1.2. 기존 연구 한계점

2. Related Work
2.a. Unsupervised Learning vs Supervised Learning

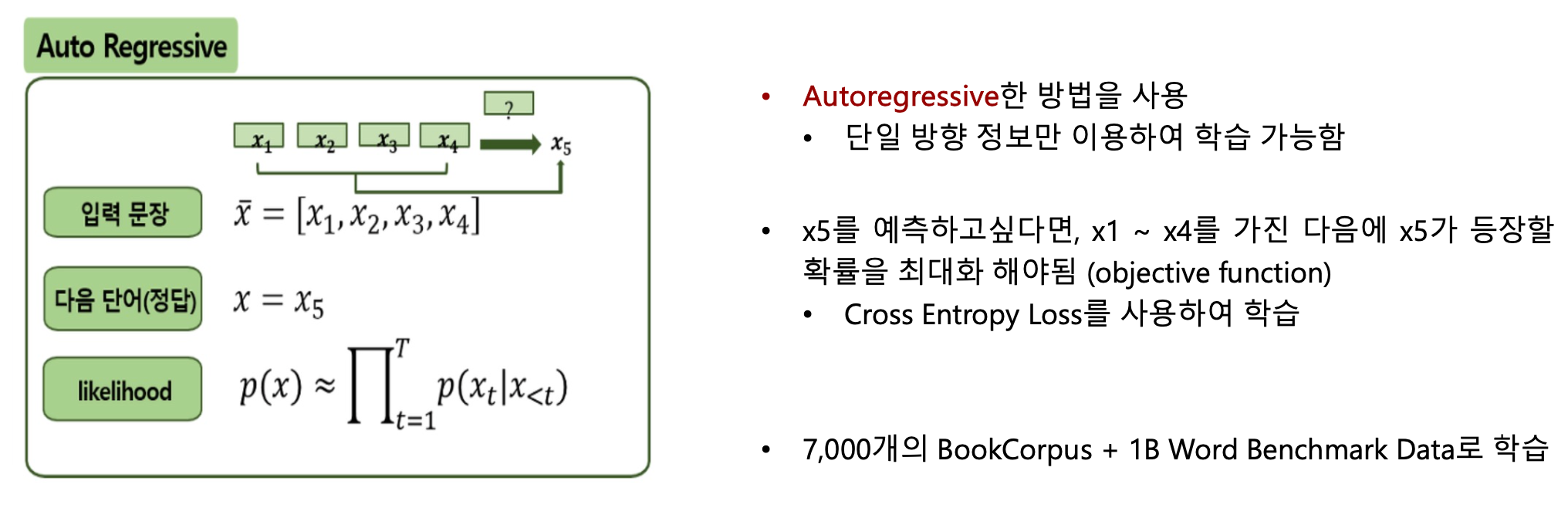
2.b. Auto Encoding vs Auto Regressive

2.c. Zero-shot vs One-shot vs Few-shot

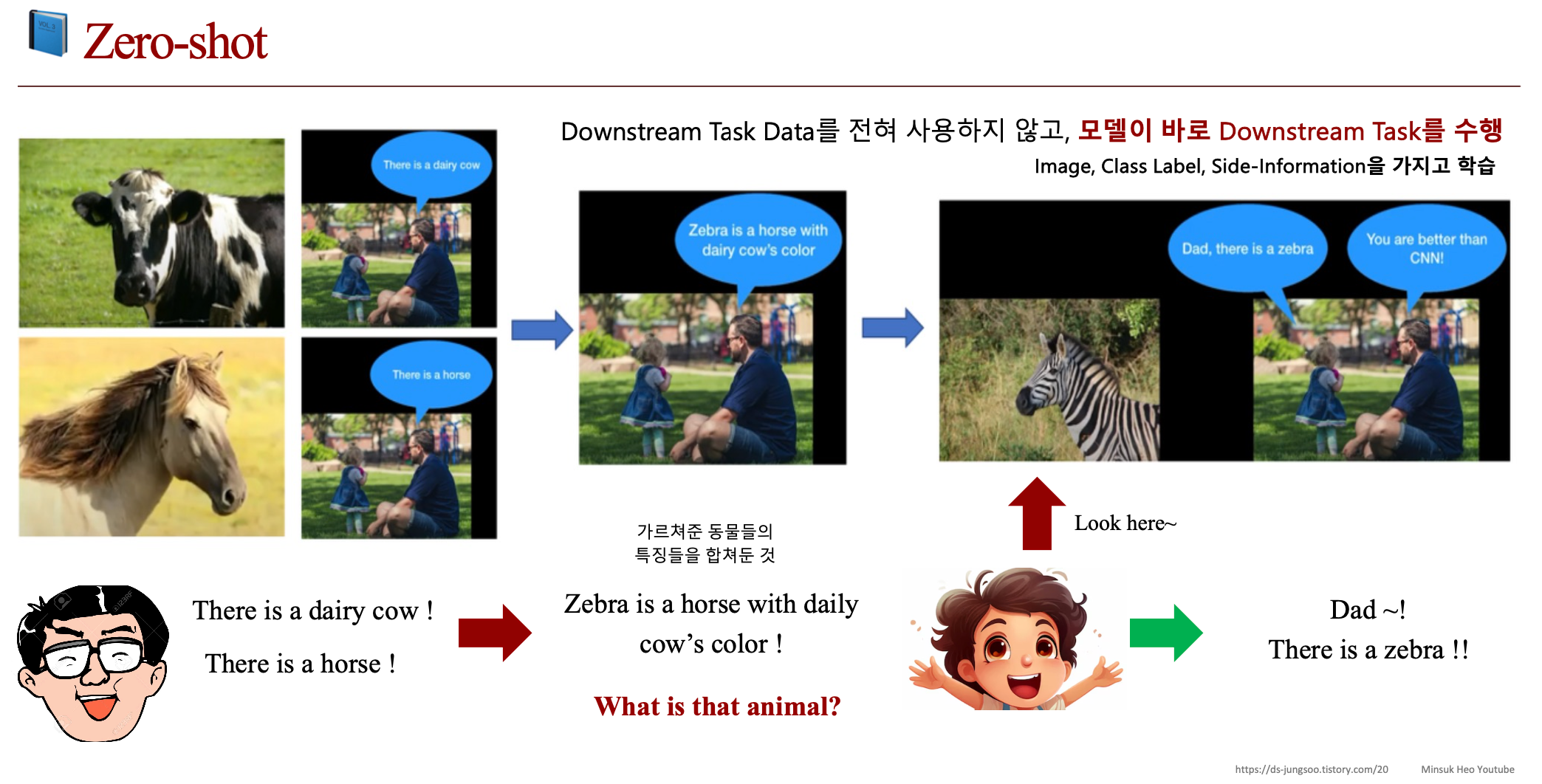
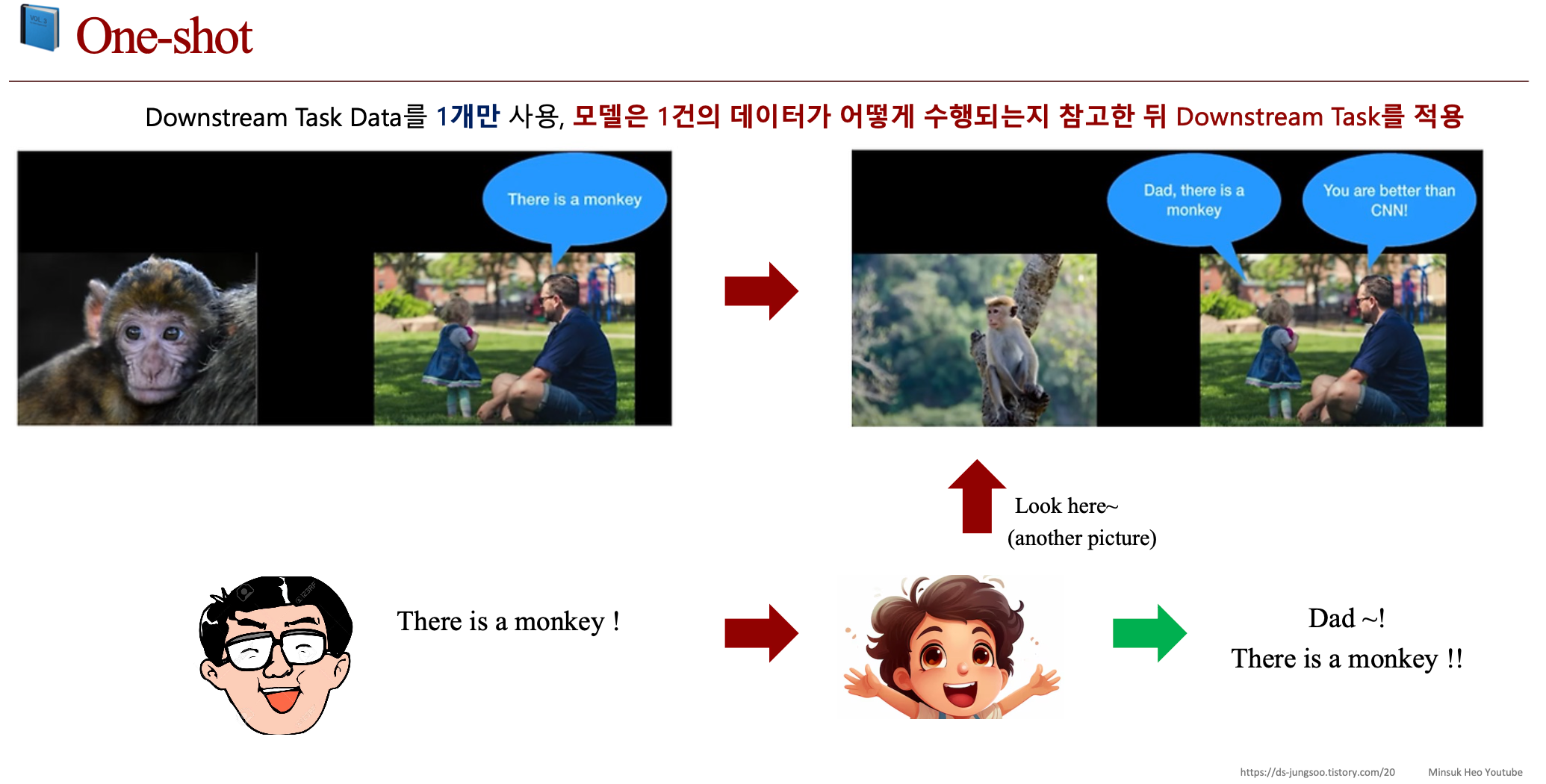
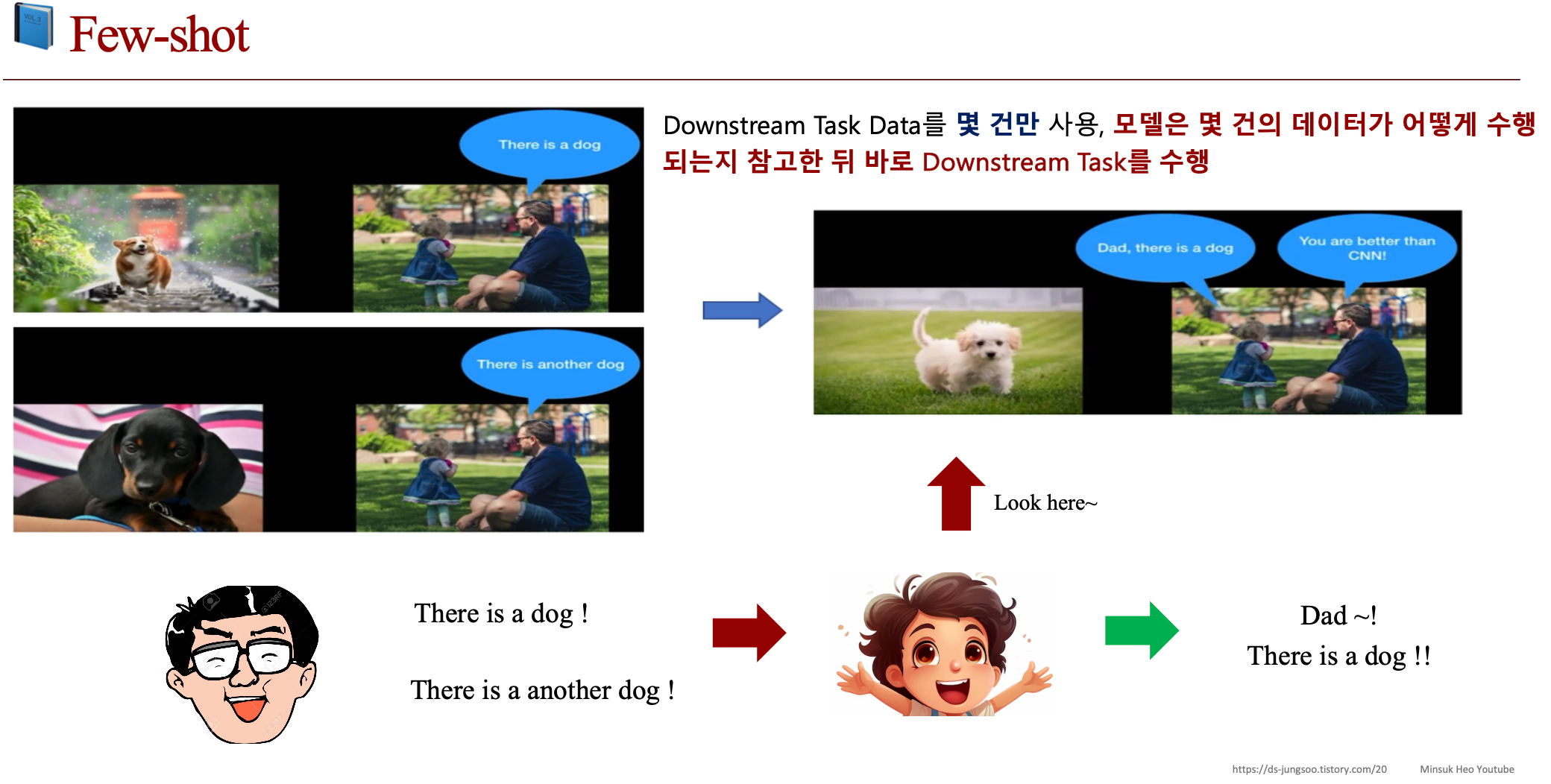
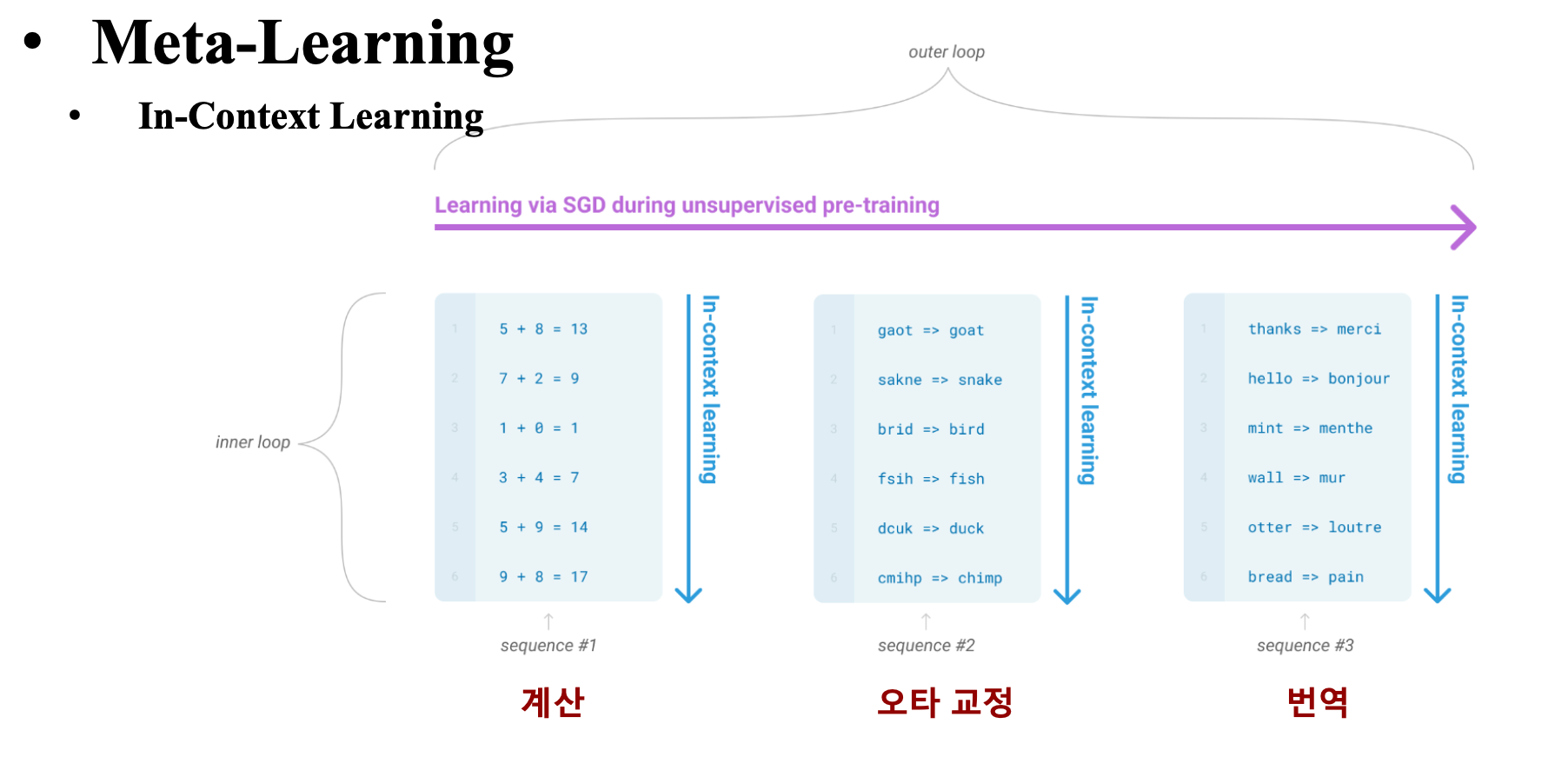
2.d. Meta-Learning
- 패턴의 차이 & 문맥을 파악할 수 있도록 학습하여 원하는 Task에 적용을 빠르게 할 수 있도록 하는 것
2.1. GPT 1
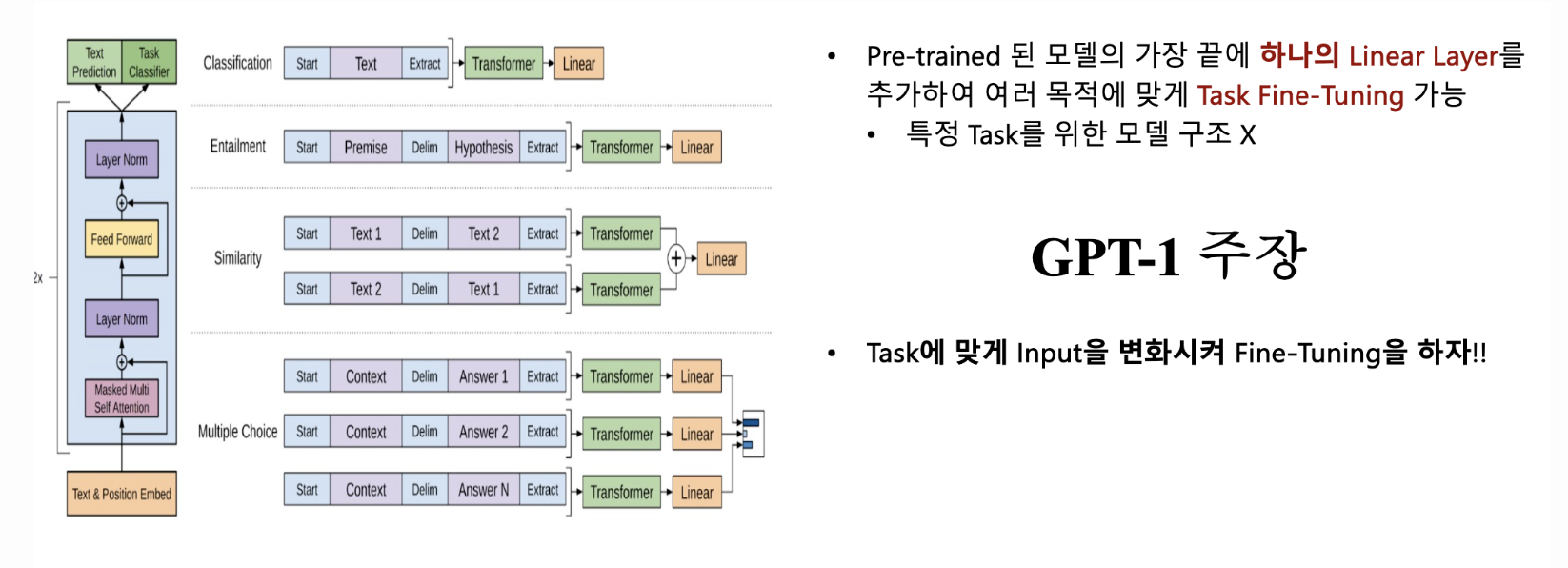
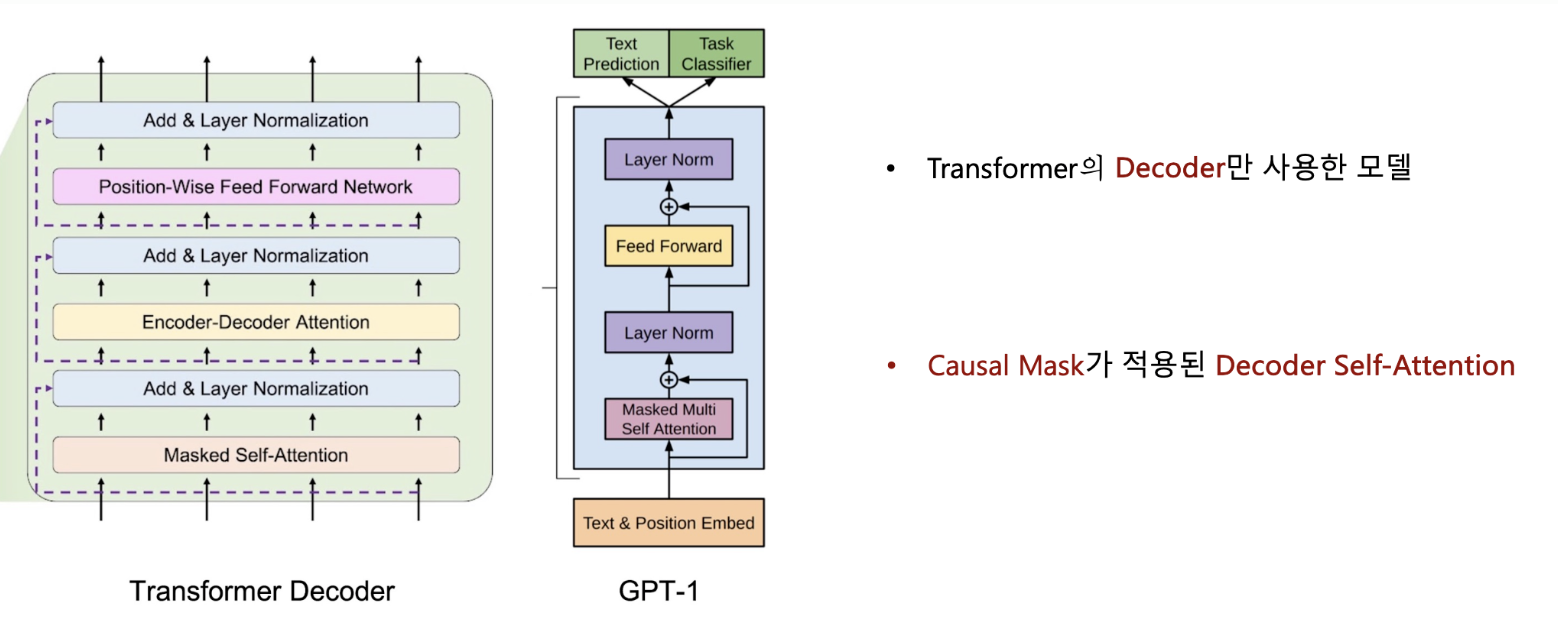
• Transformer의 Decoder만 사용한 모델
• 많은 데이터가 있지만 그중에서 특정학습을 위해 Label이 된 데이터는 많지 않음.
• Label이 없는 텍스트를 이용해서 Unsupervised Pre-training 후, Label된 데이터를 통해 목적에 맞게 Fine-tuning 할 수 있는 모델을 만들자!
• Pre-training 방식은 Causal Language Modeling(CLM)

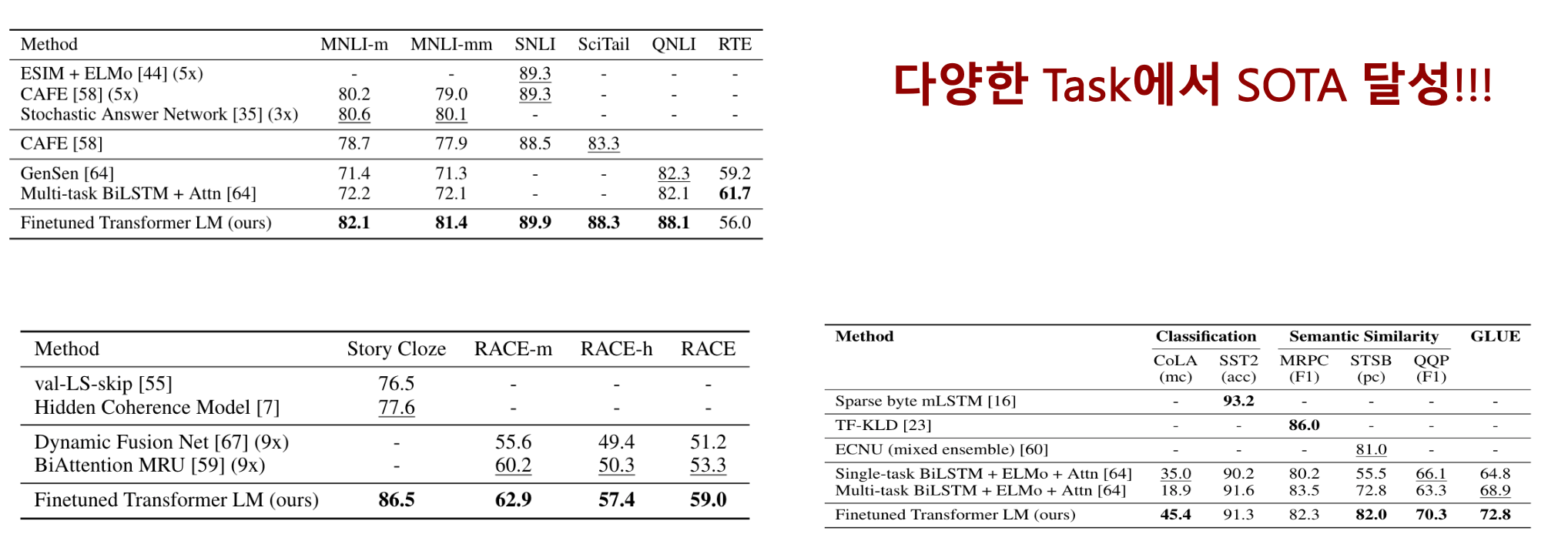
- 다양한 Task에서 SOTA 달성
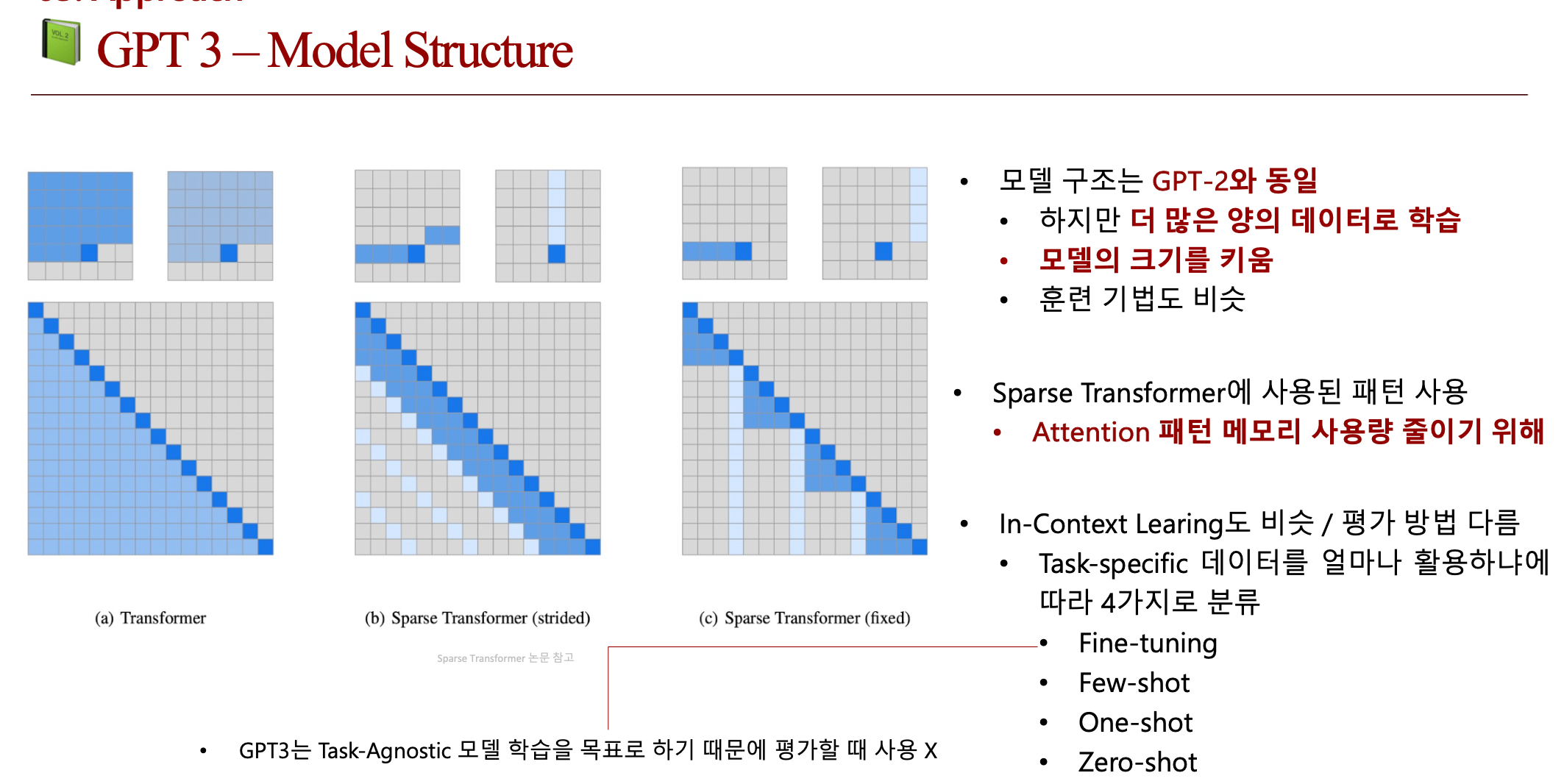
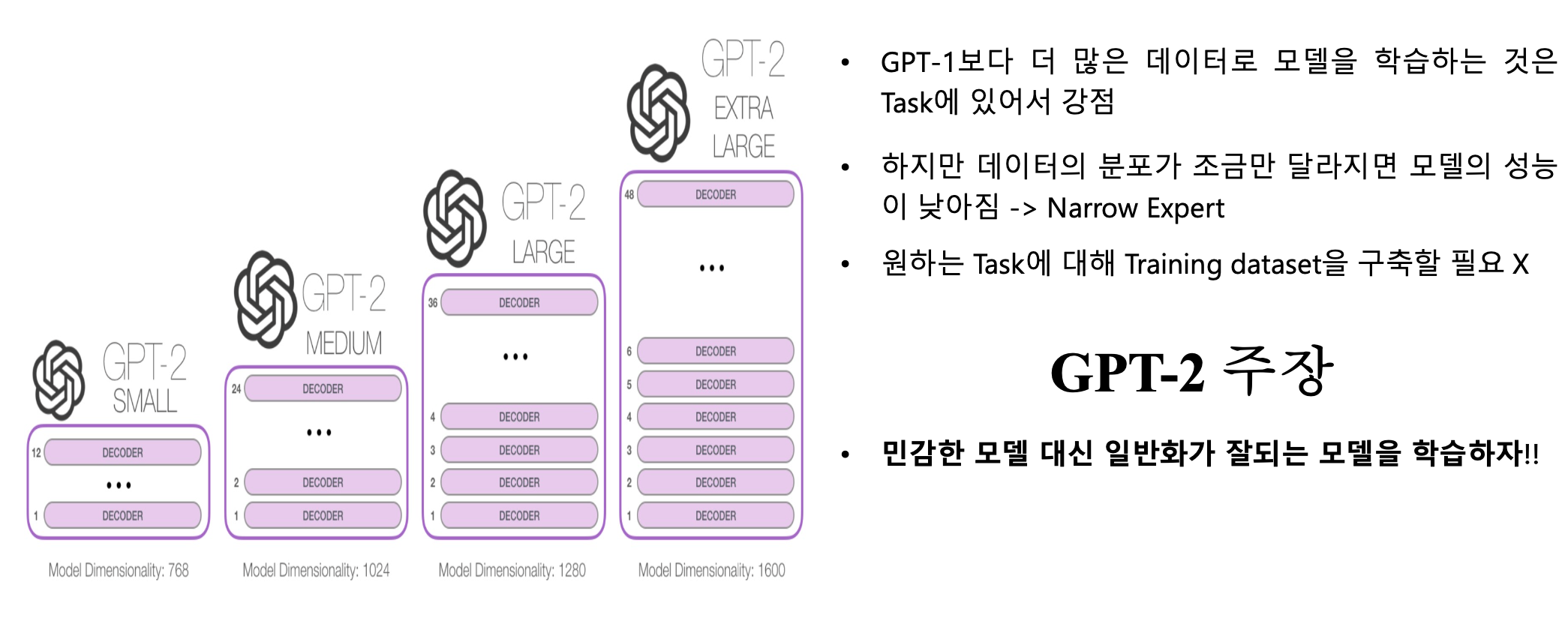
2.2. GPT 2
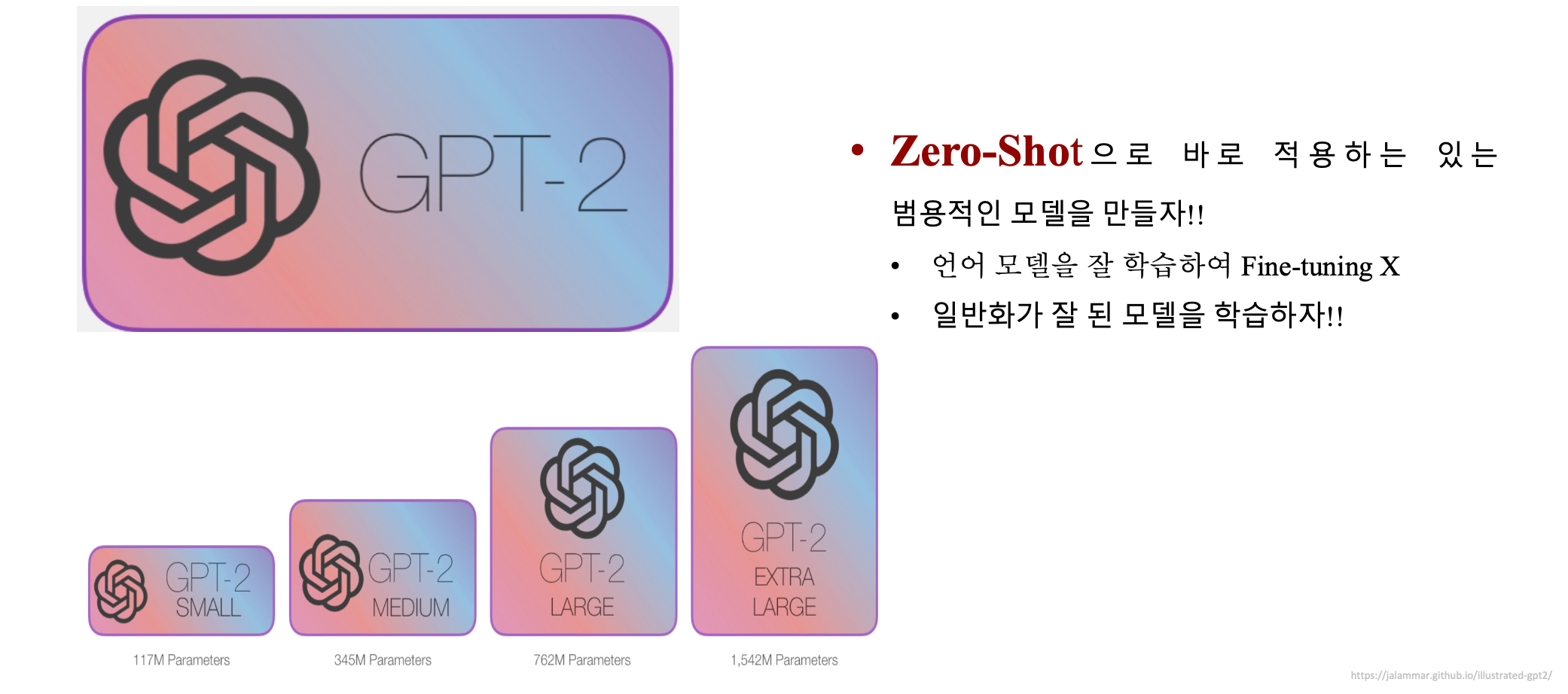
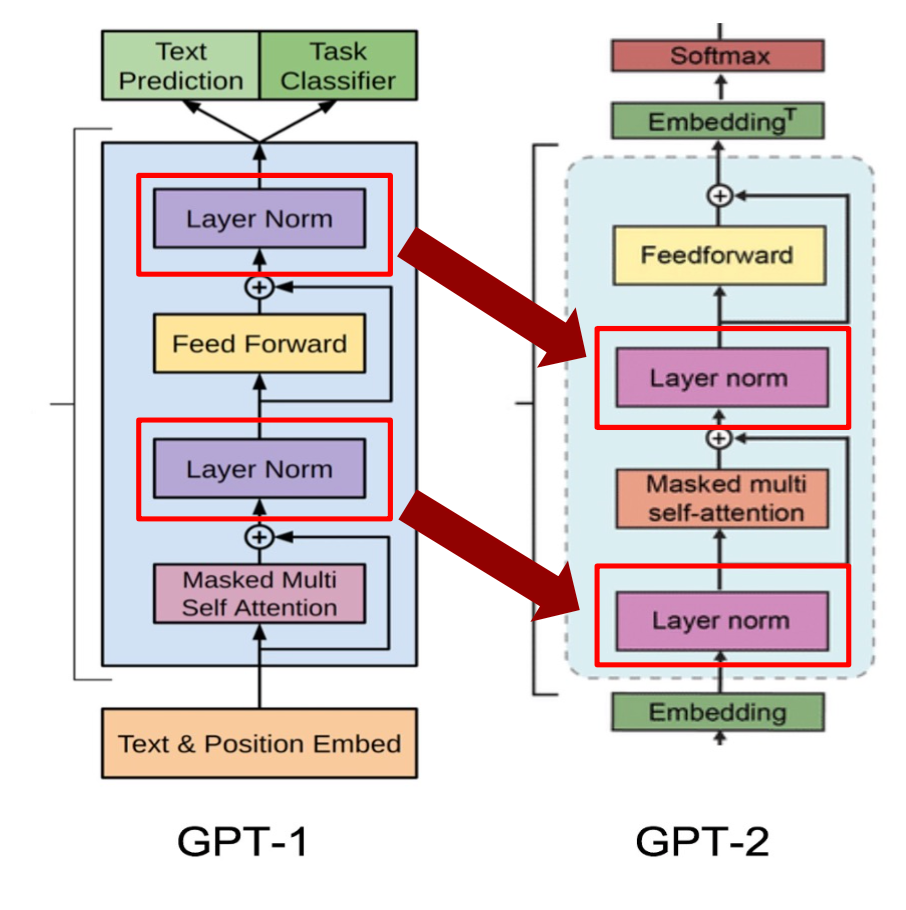
- 모델 구조는 GPT-1과 비슷하지만 Layer Normalization 위치가 다름

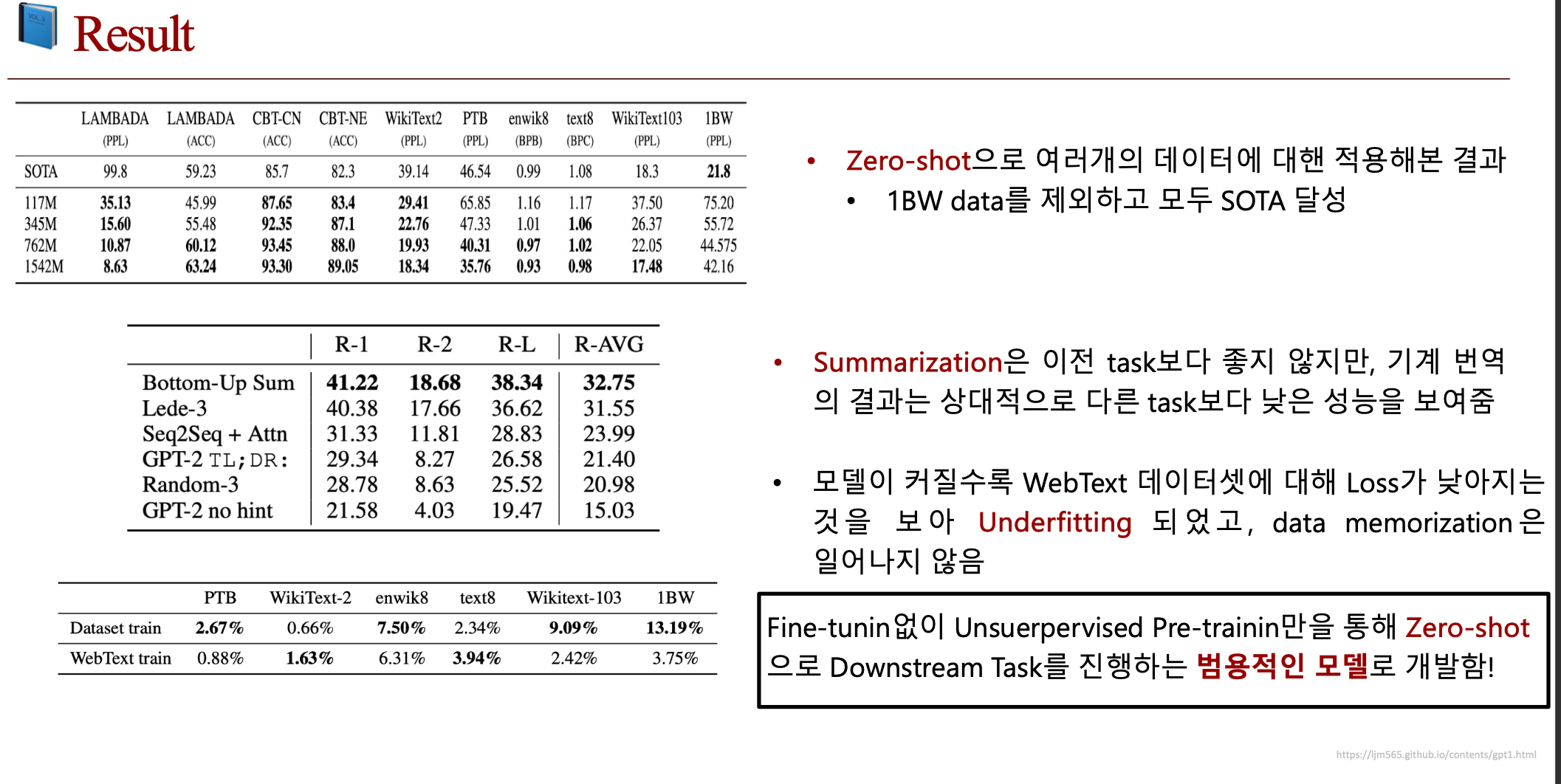
3. 제안 방법론
3.1. Main Idea
• 특정 Task를 수행하기 위해 Fine-tuning 없이 Pre-training만으로 동작하게 하자!!
• 아주 적은 데이터로 Task를 풀게 할수 있는 모델을 만들자!!
3.2. Contribution
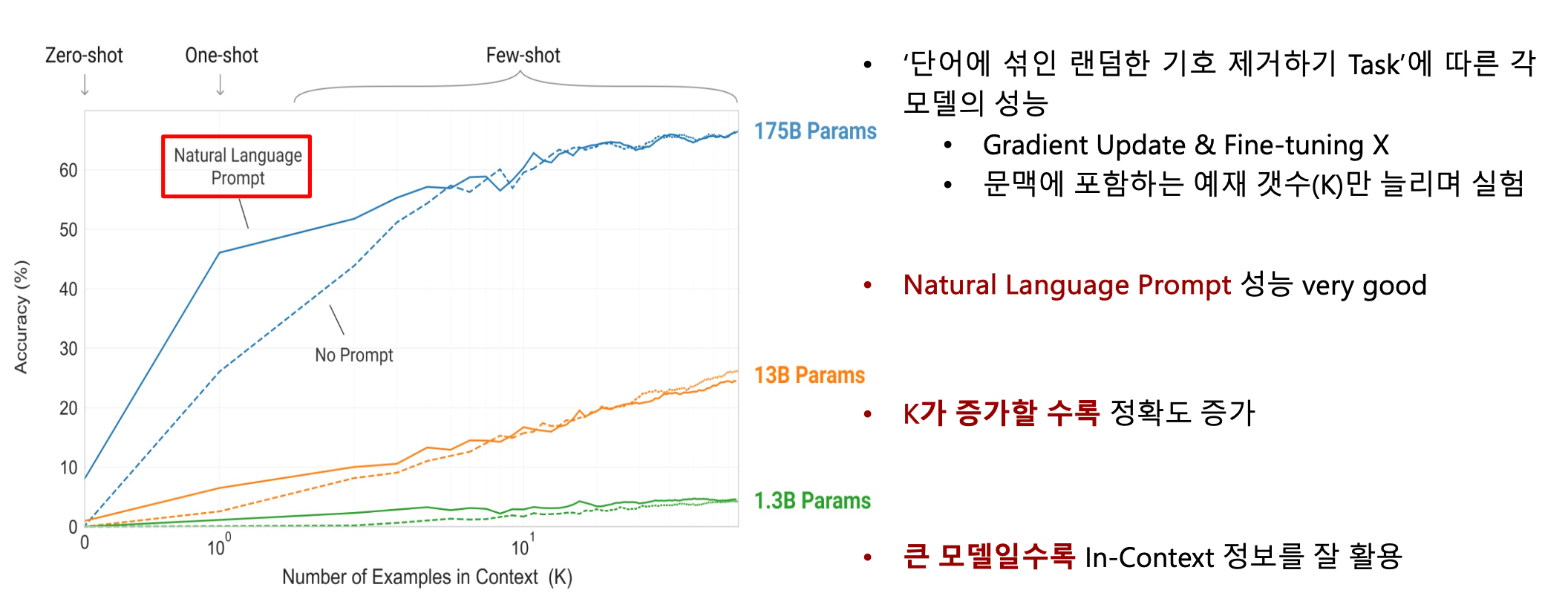
1. Meta Learning(In-Context Learning)을 통해 성능 향상
• Fine-tuning을 사용하지 않고도 이를 통해 높은 Few-shot 성능을 보임
• 일부 Task에서는 Zero-shot, One-shot setting에서도 기존 SOTA 모델들을 넘음
2. 모델의 크기를 키우고,전처리된 CommonCrawl Dataset을 학습시키면서 성능향상
4. 실험 및 결과
4.1. Dataset
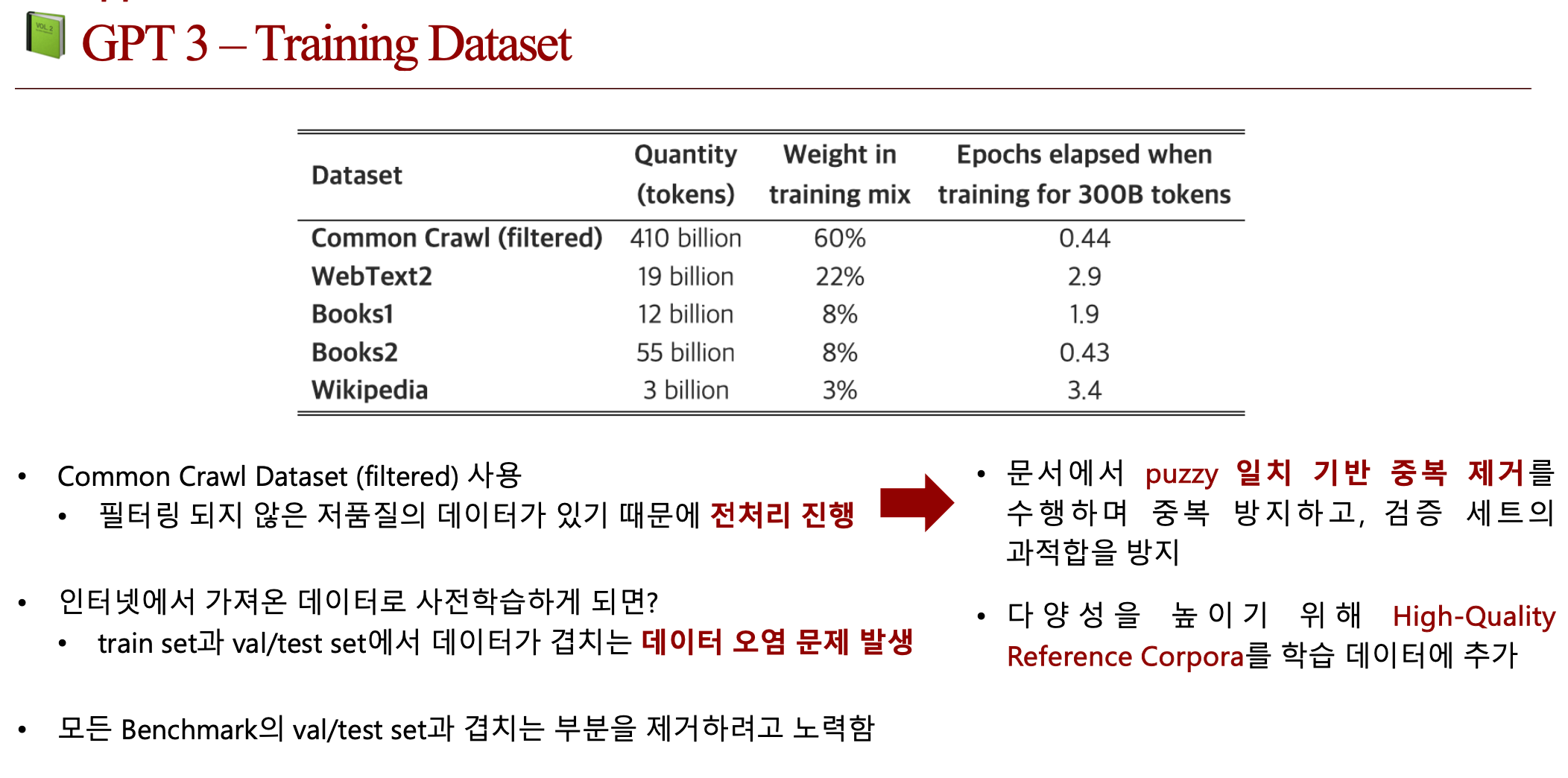
- Common Crawl Dataset

4.2. Baseline
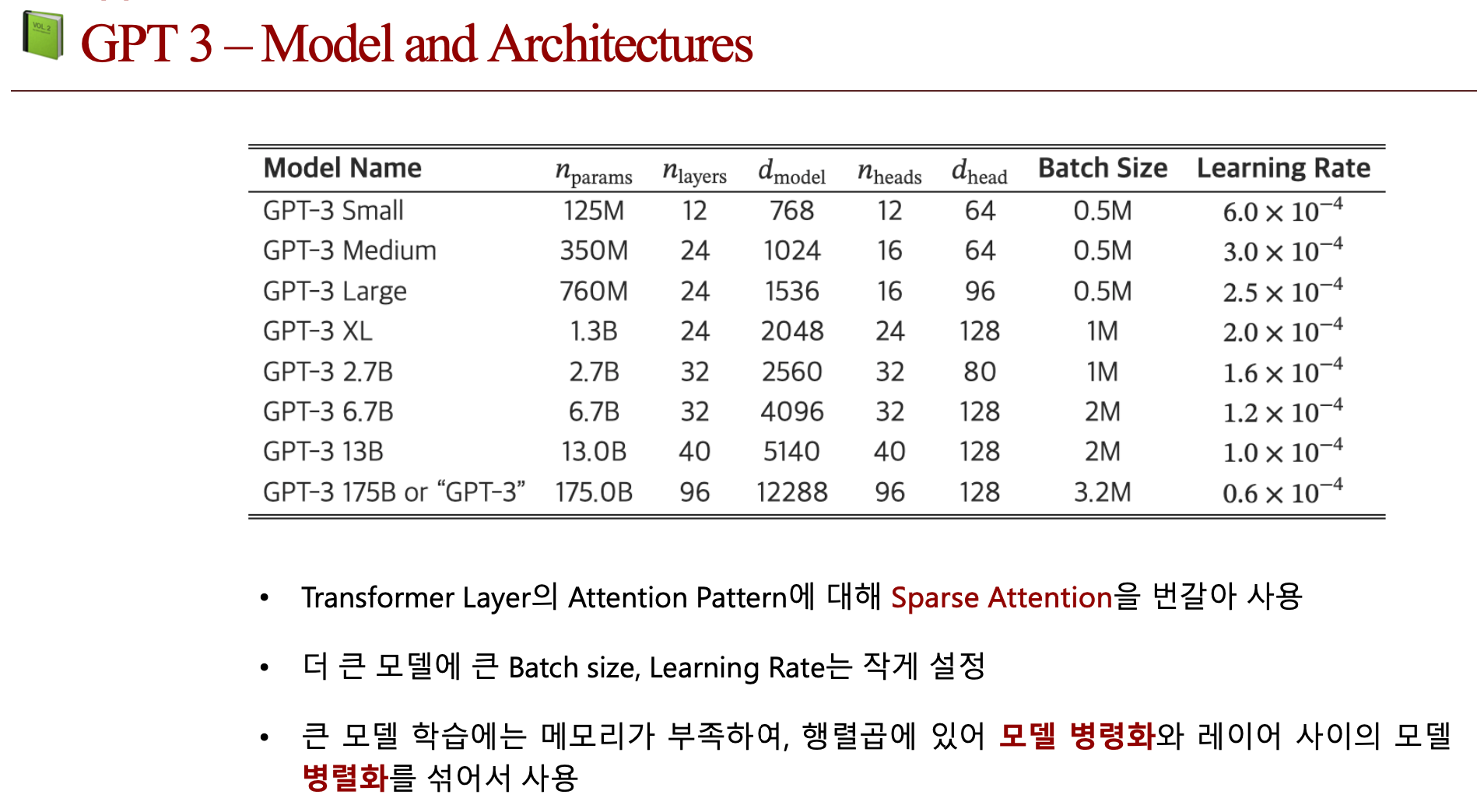
4.3. 결과
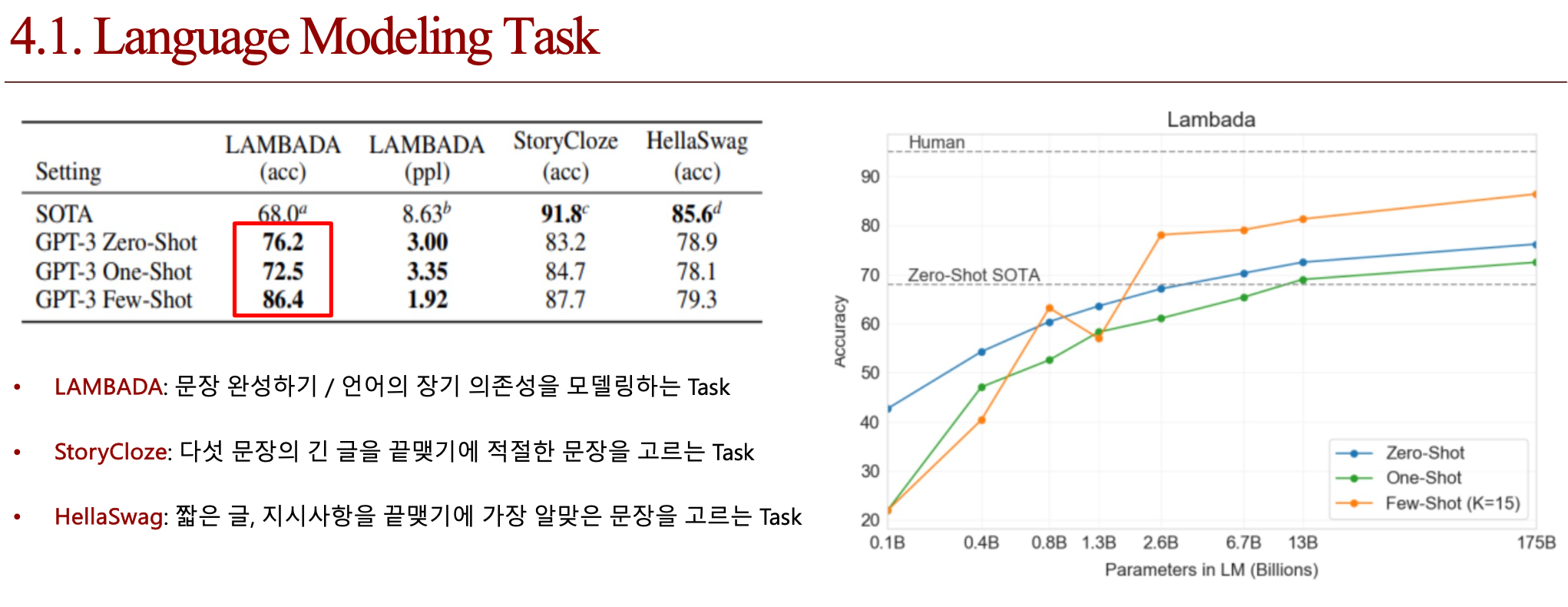
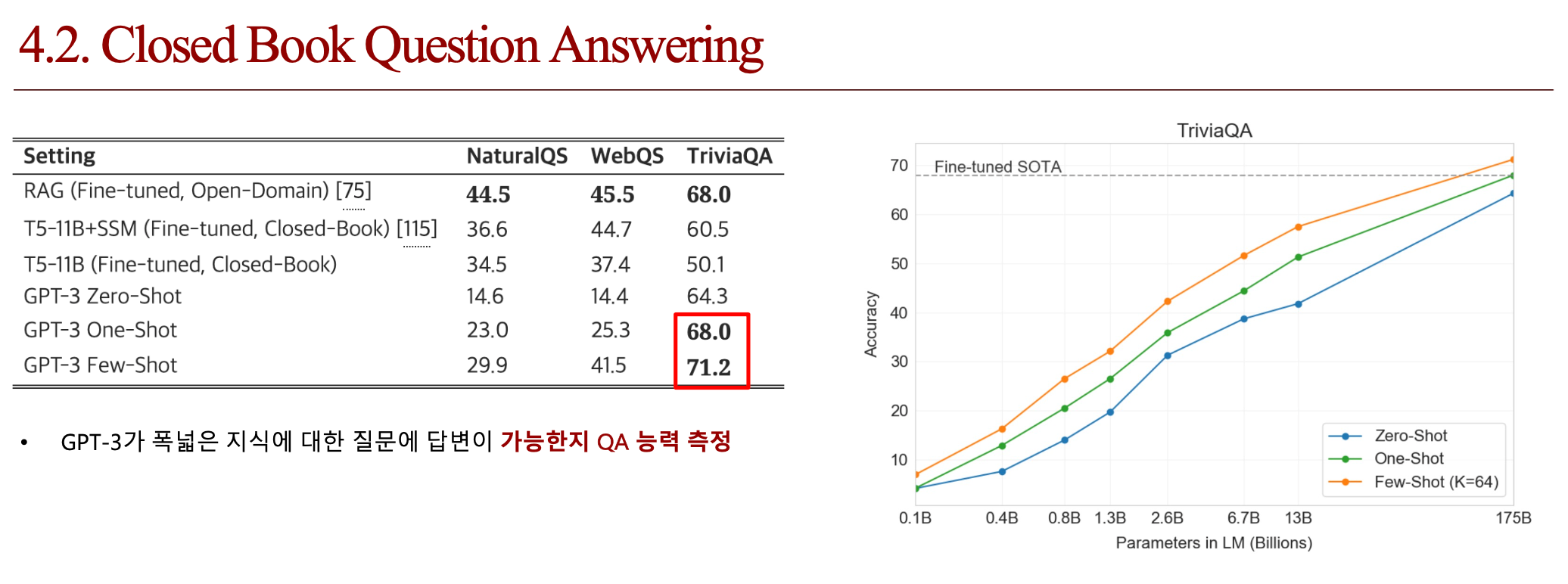
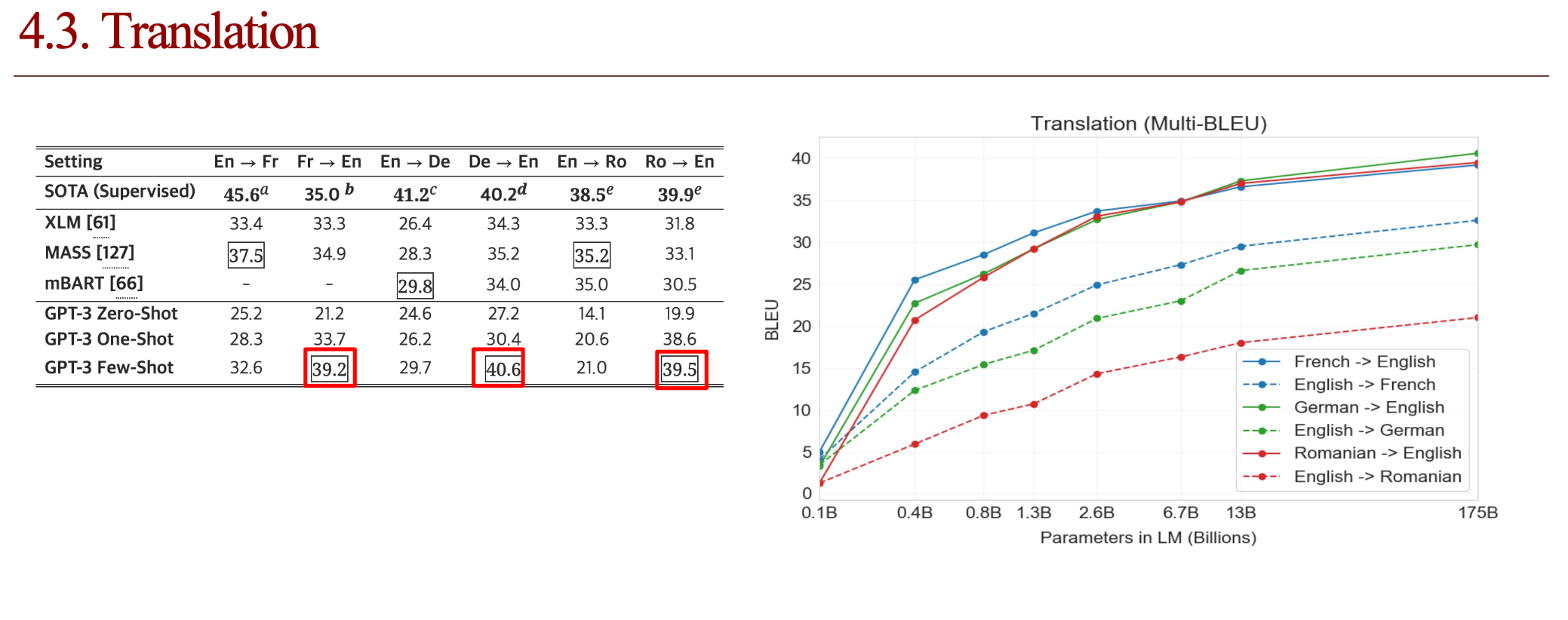

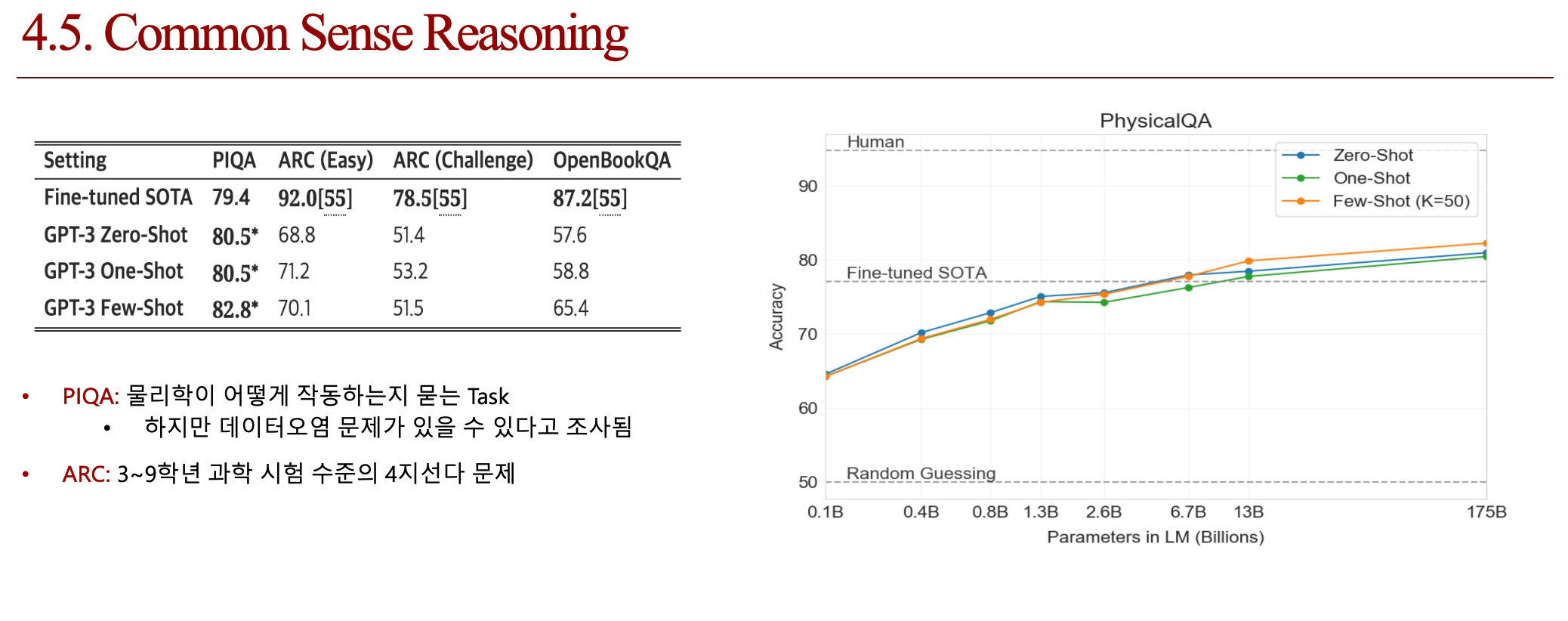
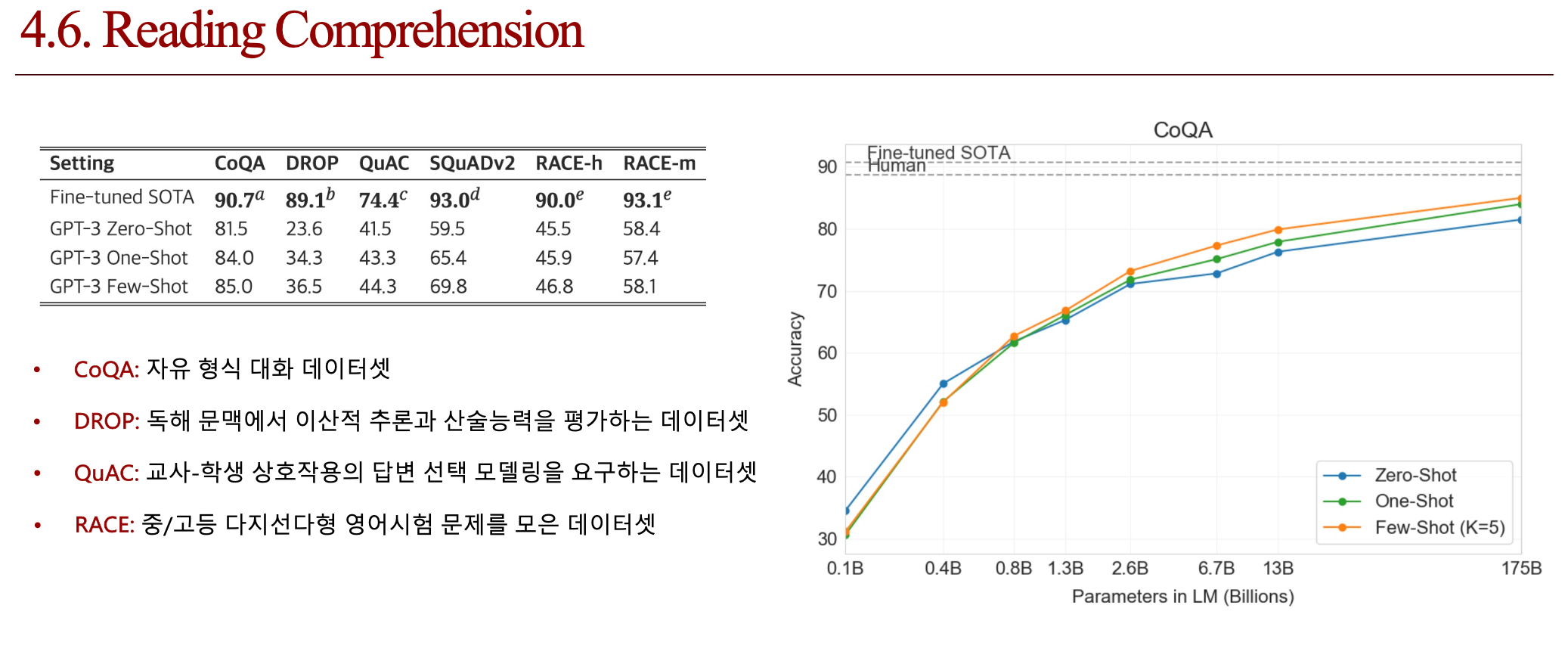
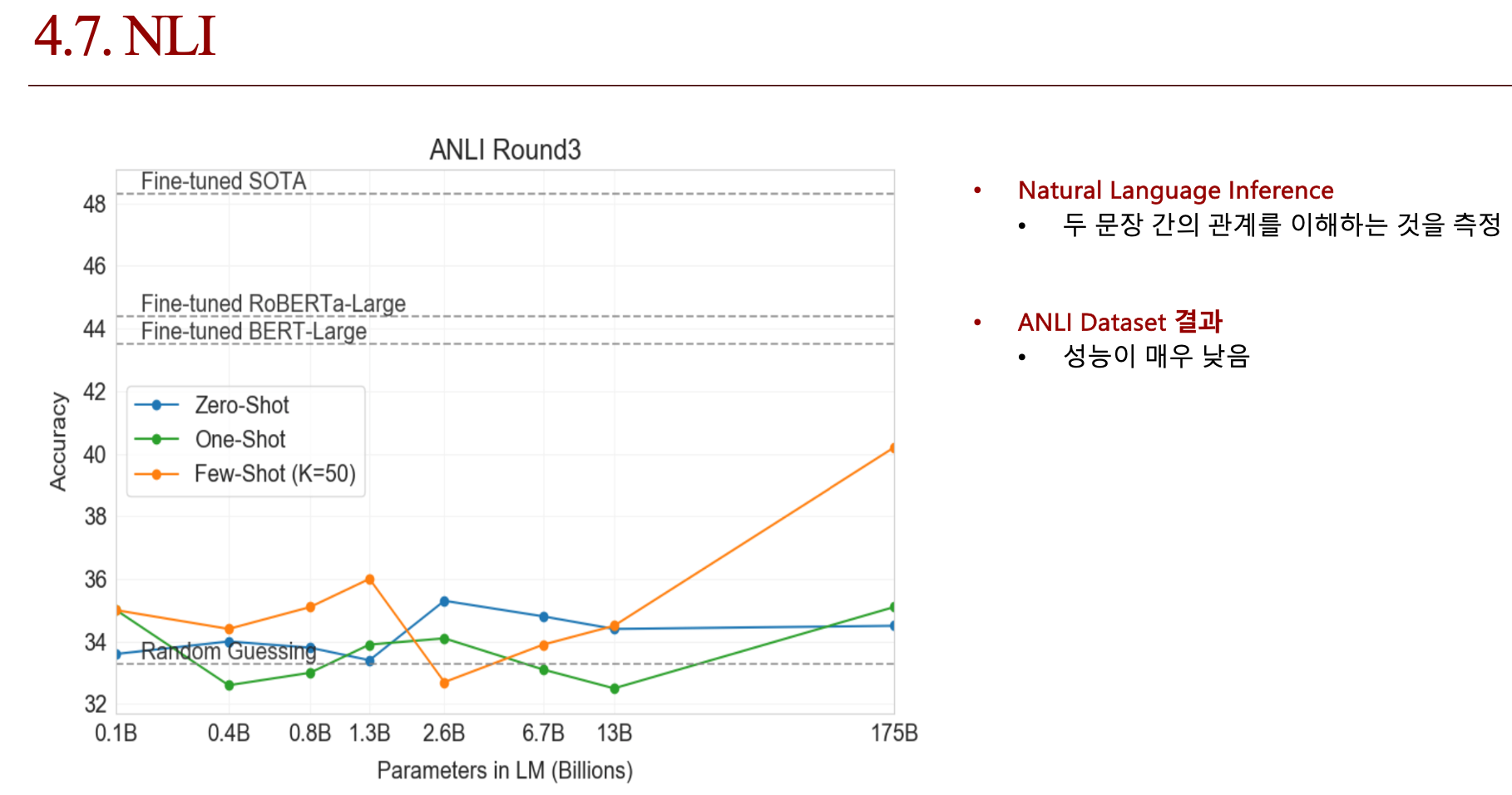
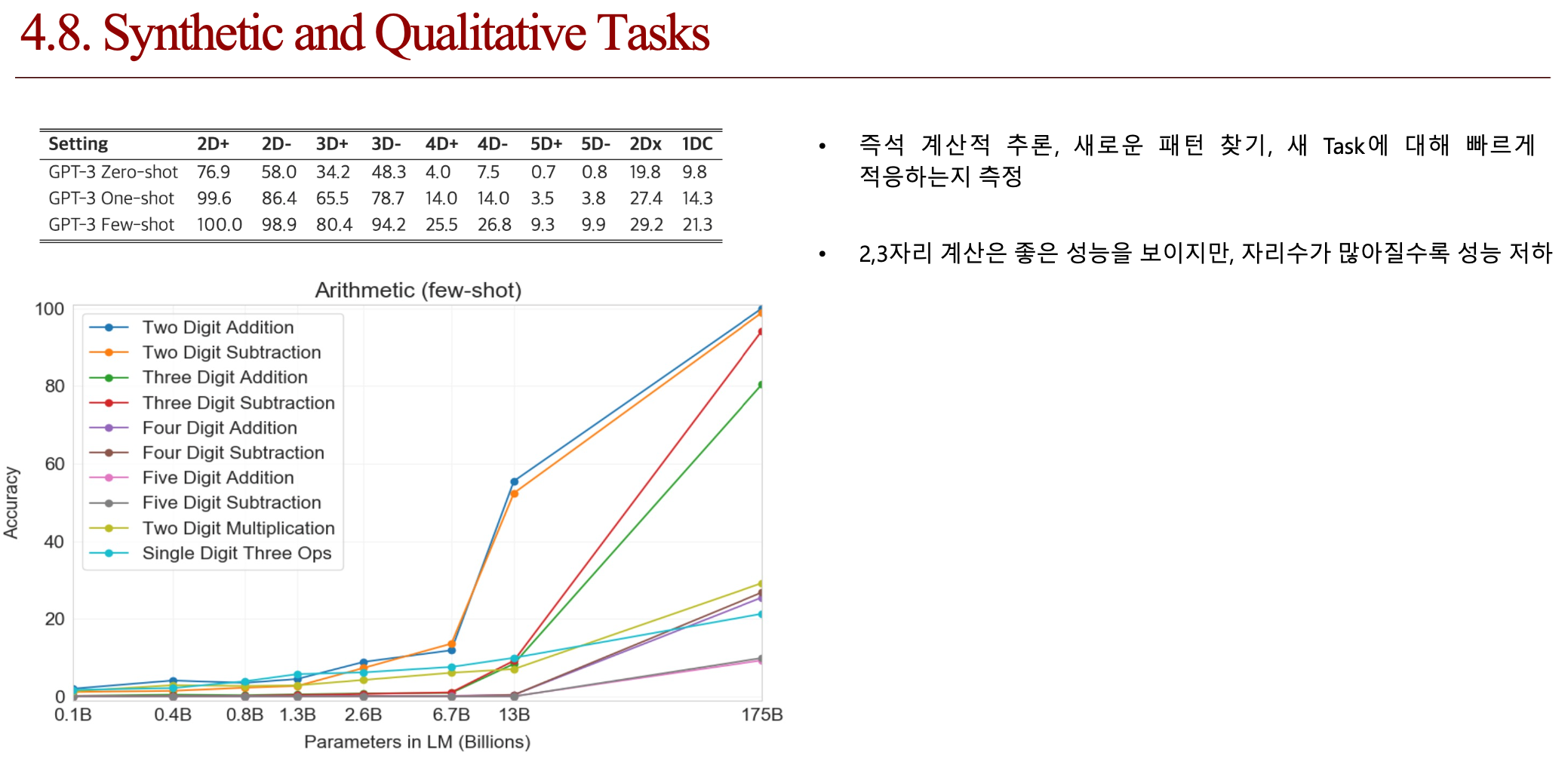
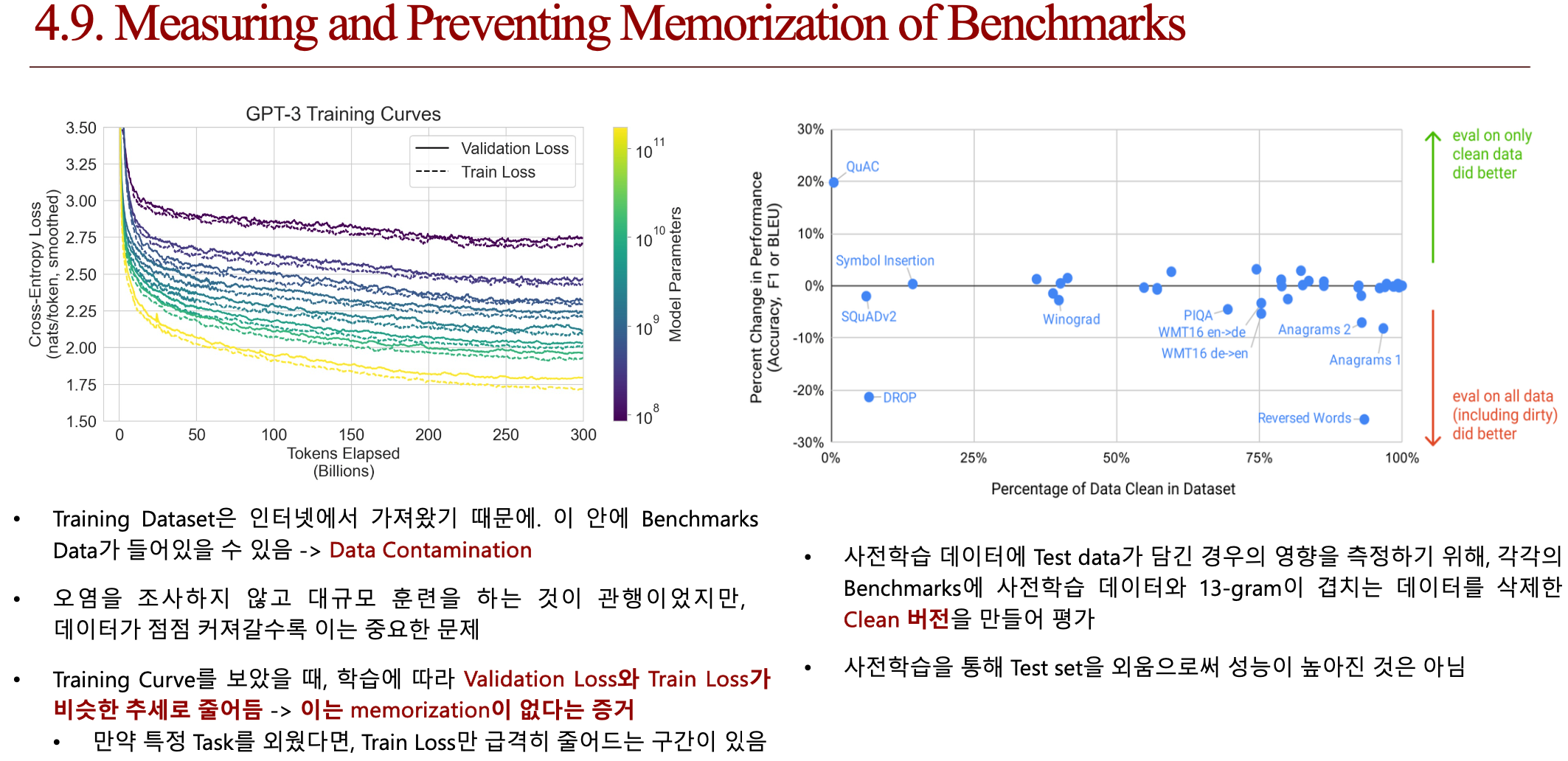
4.4. 결론 (배운점)

📚 References
• https://ar5iv.labs.arxiv.org/html/2005.14165v4
• https://ds-jungsoo.tistory.com/20
• https://ljm565.github.io/contents/gpt1.html
• https://forest62590.tistory.com/90
• https://jalammar.github.io/illustrated-gpt2/
• https://velog.io/@lee9843/GPT-3-Language-Models-are-Few-Shot-Learners-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
• https://devhwi.tistory.com/35
• https://ai4nlp.tistory.com/11
• https://youtu.be/xNdp3_Zrr8Q?si=-DjxrrA5jkENeDzv
