[논문리뷰 | NLP] ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission (2020) Summary
[논문리뷰]
목록 보기
28/42
Title
- ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission

0. 논문 읽기 전에 알면 좋을 것
Clinical Note
- 의료 전문가가 환자의 진료 과정, 진단, 치료 계획, 그 외 관련된 정보를 기록한 문서 or 메모임.
-> 환자의 증상, 진단 이유, 방사선 결과, 일상 활동, 환자의 과거력 등을 포함하여 환자에 대한 더 풍부한 정보를 제공함.
- 보통 의사,간호사, 치료사, 그 외 다른 의료 전문가들이 환자의 건강 상태, 치료 과정, 의료 상담 내용 등을 기록하기 위해 사용함.
- 이는 환자의 의료 기록의 일부로 저장되며, 환자의 건강 상태를 모니터링하고 의료 서비스를 계획하고 제공하는 데 중요한 역할을 함.
Abstract
- ClinicalBERT는 Clinical Note를 대표하는 새로운 프레임워크임.
- Clinical Note에는 환자에 관한 깊은 정보가 포함되어 있지만, 높은 차원과 희소성 때문에 제대로 활용되지 못했음.
- 이 연구에서는 BERT를 Clinical Text에 적용하여, 환자의 30일 내 병원 재입원을 예측하는 모델을 개발함.
- 기존의 BERT는 Wikipedia나 BookCorpus와 같은 표준 말뭉치에서 훈련되었기 때문에, Clinical Note에 특화된 ClinicalBERT를 정의하기 위해 Clinical Note를 사용하여 BERT를 사전 훈련시킴.
- 결과적으로, ClinicalBERT는 의사들의 판단으로 볼 때 임상 개념 간의 고품질 관계를 발견하였고, 다양한 기준에서 병원 재입원 예측에서 다양한 기준선을 능가하였음.
- 모델의 예측을 해석하는 데 ClinicalBERT의 주의 가중치를 사용할 수 있음.
1. Introduction
- 전자 건강 기록(EHR)은 환자 정보를 저장하며, 이를 통해 비용과 시간을 절약하고 생명을 구할 수 있음.
-> EHR에는 매일 데이터가 추가되어 기계 학습을 통한 분석의 혜택을 얻을 수 있음.
- 구조화된 EHR data 특징을 활용해 패턴을 발견하고 예측을 개선할 수 있지만, Clinical Note와 같은 비구조화된 정보는 임상 기계 학습 모델에서 사용하기 매우 어려움.
- 이 연구의 목표는 임상적 통찰력을 발견하고 의학적 예측을 할 수 있는 Clinical Note Modeling Framework를 만드는 것임.
- 병원 재입원은 환자의 생활 질을 저하시키고 비용을 낭비하는 원인이 되므로 재입원을 정확하게 예측하는 것은 병원 효율성을 향상시키고 중환자실 의사의 부담을 줄일 수 있음.
ClinicalBERT라는 퇴원 지원 모델을 개발하여 환자 노트를 처리하고 환자가 30일 이내에 재입원될 위험 점수를 동적으로 할당함.
-> ClinicalBERT는 진단 예측, 사망 위험 평가, 또는 입원 기간 평가 등에도 적용될 수 있음.
ClinicalBERT는 Clinical Note를 기반으로 환자의 재입원 위험을 예측하는 모델로, 다양한 임상 예측 작업에 적용될 수 있음.
1.1. Background
- Clinical Text의 유용한 표현을 학습하는 모델을 구 축하는 것은 매우 도전적임.
- Clinical Note를 Modeling하려면 먼 거리의 단어 간의 상호 작용을 포착해야 함.
- 이러한 장거리 구조를 모델링하기 위해서는 BERT와 같은 문맥 표현에 적합함.
임상적 중요성을 가진 30일 병원 재입원 예측을 사례 연구로 사용함.
- 반면, ClinicalBERT는 환자의 입원 중에 재입원을 예측할 수 있음.
- 전자 건강 기록 내의 임상 노트는 복잡한 문법과 전문 용어를 사용하기 때문에 모델링이 어렵음.
-> 하지만BERT와 같은 기술을 활용하면 Clinical Note의 깊은 통찰력과 장거리 종속성을 포착할 수 있음.
1.2. Significance
- ClinicalBERT는 퇴원 요약을 중심으로 하는 기존 방법보다 재입원 예측을 향상시.
-> 퇴원 요약을 사용하여 입원 후 끝날 때 예측을 만드는 것은 재입원 가능성을 줄일 기회가 적음.
- ClinicalBERT는 BERT를 임상 노트에 특화시킨 것이며, 이는 임상 노트가 길고 많기 때문에 BERT의 효율적인 아키텍처가 장기 종속성을 모델링할 수 있음.
- Word2Vec과 FastText와 비교하여, ClinicalBERT는 임상 단어 유사성을 더 정확하게 포착함.
- 요약하면, ClinicalBERT는 재입원 예측을 향상시키며, BERT의 효율적인 구조를 활용하여 임상 노트의 장기 종속성을 모델링 수 있음. 그리고 ClinicalBERT는 다양한 임상 예측 작업에 쉽게 적용될 수 있으며, 병원 재입원 예측에서 다른 모델들을 능가함.
2. Methods
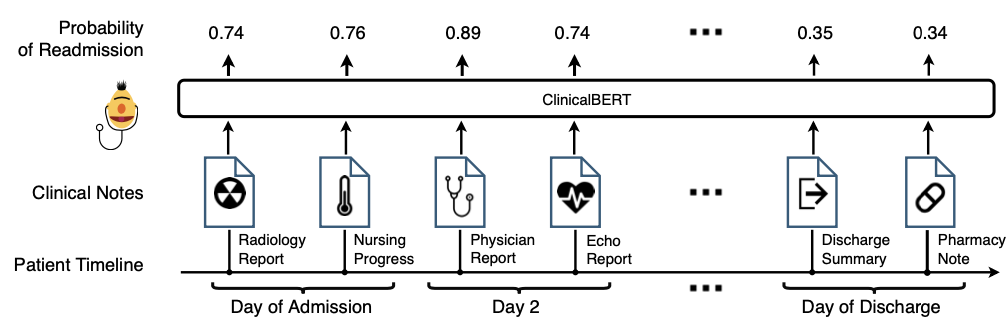
- ClinicalBERT는 임상 텍스트의 깊은 표현을 학습하여 임상적 통찰력과 병원 재입원 예측을 개선함.
- 위의 그림은 ClinicalBERT Architecture이며, Clinical Note의 깊은 표현을 학습하여 30일 이내에 재입원 위험을 예측하는 데 유용함.
- 예를 들어, 환자가 병원에 입원하는 동안 의료 제공자가 전자 건강 기록에 노트를 추가하면 모델을 환자의 재입원 위험을 실시간으로 업데이트함.
2.1. BERT Model
- BERT는 Transformer의 Encoder를 사용하여 Text Embedding을 학습하는 신경망이며, 비감독 학습 작업을 통해 사전 훈련됨.
- 임상 텍스트에 특화된 fine-tuning도 수행됨.
2.2. Clinical Text Embedding
- ClinicalBERT는 Clinical Note를 Token의 모음으로 표현함.
- 각 토큰은 token embedding, learned segment embedding, position emedding의 합으로 표현됨.
- 여러 토큰 sequence가 ClinicalBERT에 입력될 때, segment embedding은 토큰이 어떤 sequence와 연관되어 있는지를 식별함.
- position embedding은 입력 sequence 내의 토큰 위치에 해당하는 학습된 매개변수 집합
- 분류 작업을 위해 각 입력 토큰 sequence 앞에 분류 토큰 [CLS] 삽입

- ClinicalBERT는 2가지 비지도 학습 작업을 통해 Clincial Text의 깊은 표현을 학습함.
(1) MLM으로, 일부 입력 토큰이 예측을 위해 제외됨.
(2) NSP으로, ClinicalBERT는 두 입력 문장이 연속적인지를 예측함.
2.3. Self-Attention Mechanism

(1) Query 행렬과 Key 행렬 간의 내적을 계산하고 유사도 값을 산출
(2) , 를 루트 로 나눔
(3) score 행렬에 softmax 함수를 적용해 정규화 작업을 진행
(4) score 행렬에 Value 행렬을 곱해 Attention 행렬을 산출
2.4. Pre-training ClinicalBERT
- BooksCorpus, Wikipedia와 다르게 Clinical Note는 전문 용어와 줄임말이 많고, 문법과 구문이 다르기 때문에 전문 지식이 없으면 이해하기 어려움.
- ClinicalBERT는 Clinical Note에서 pre-training됨.
- 이 사전 훈련은 일부 입력 토큰을 마스킹하고 마스킹된 토큰을 예측하는 "마스크된 언어 모델링"과 두 문장이 연속적인지를 예측하는 "다음 문장 예측" 두 가지 작업을 포함함.
2.5. Fine-tuning ClinicalBERT
- Pre-training 이후 병원 재입원 예측이라는 임상 작업에 대한 fine-tuning을 함.
- 출력은 재입원 확률을 예측하는 데 사용되고, 이 확률은 sigmoid 함수를 사용하여 계산됨.
h[CLS]는 분류 토큰에 해당하는 모델의 출력이고,W는 매개변수 행렬임.
- 이진 분류기의 likelihood를 최대화하기 위해 fine-tuning


- 모델은 환자의 Clinical Note를 입력으로 받고, ClinicalBERT에 의해 학습된 분류 표현 에 linear layer을 적용하여 30일 이내의 재입원 위험을 예측함.
3. Empirical Study
3.1. Data
- MIMIC-III dataset 사용
3.2. Language Modeling and Clinical Word Similarity
3.2.1. Clinical Language Modeling.

- ClinicalBERT는 의료 언어 모델링에서 BERT를 능가.
- BERT는 의료 텍스트로 훈련되지 않았기 때문에 성능이 떨어졌으며, 이로 인해 ClinicalBERT와 같은 의료 데이터에 맞춤화된 모델이 필요함이 강조됨.
3.2.2. Qualitative Analysis

- ClinicalBERT를 인기 있는 Word Embedding 모델과 의료 단어 유사성 작업을 사용하여 비교함.
- 의사들이 평가한 의학 용어 유사성을 평가하기 위해 데이터를 사용함.
- 각 의학 용어를 대표하는 벡터를 얻기 위해 ClinicalBERT에 의학 용어에 해당하는 토큰 시퀀스를 입력함.
- 마지막 4개의 hidden state 합은 각 의학 용어를 나타내는 데 사용됨.
- 결과적으로, ClinicalBERT는 심장 관련 개념과 같은 의료 의미론을 어느 정도 포착함.
- 이를 통해 ClinicalBERT는 의료 텍스트를 효과적으로 모델링하며, 특히 의학 용어의 유사성과 같은 의료 의미론을 캡처할 수 있음을 보여줌.
3.3. 30-Day Hospital Readmission Prediction
3.3.1. Cohort
- MIMIC-III 데이터베이스에서 환자 Cohort를 선택하여 사용함.
- 30일 이내에 재입원된 환자들은 'readmit=1'로 레이블링되었고, 그렇지 않은 환자들은 'readmit=0'으로 레이블링됨.
- 병원 내 사망한 환자와 신생아 환자는 해당 연구에서 제외됨.
- 최종적으로 34,560명의 환자 중 2,963명이 재입원 레이블을 양성으로, 42,358명이 음성으로 가지고 있음.
3.3.2. Evaluation
1. AUROC (Area Under the Receiver Operating Characteristic Curve)
- 진짜 양성 비율과 거짓 양성 비율 간의 곡선 아래 영역을 측정
2. AUPRC (Area Under the Precision-Recall Curve)
- 정밀도 대 재현율의 그래프 아래 영역을 측정
3. RP80 (Recall at Precision of 80%)
- 짓 양성이 중요하므로 80%의 정밀도에서 재현율을 계산하며, 거짓 양성 비율을 최소화하여 알람 피로의 위험을 줄이는 데 중점을 둠.
3.3.3. Models
- 여러 모델들이 재입원 예측을 위해 비교 및 평가됨.
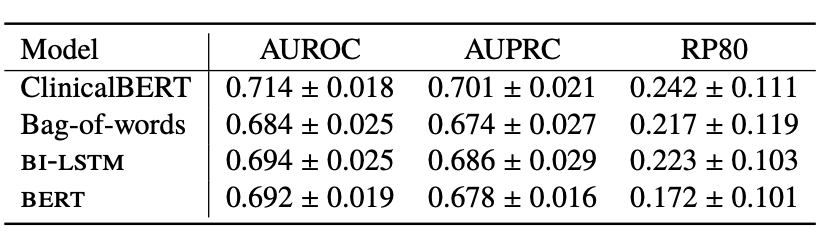
(1) ClinicalBERT
- 인코더 네트워크의 가중치와 학습된 분류기 가중치를 포함한 모델
(2) Bag-of-words
- 단어 빈도를 기반으로 노트를 표현하는 방법으로, 가장 흔한 5,000개의 단어를 특징으로 사용
- L2 정규화가 있는 로지스틱 회귀를 사용하여 재입원을 예측
(3) BI-LSTM 및 Word2Vec
- BI-LSTM은 단어 시퀀스를 모델링하는 데 사용됨.
- 최종 숨겨진 계층은 재입원을 예측하는 데 사용됨.
(4) BERT
- ClinicalBERT의 기반이 되는 모델이지만, bert는 표준 언어 말뭉치가 아닌 임상 노트에 대해 사전 훈련되지 않았음.
- ELMo와의 비교도 이루어졌으나, 성능이 월등히 나쁘기 때문에 결과는 생략됨.
- ELMo의 가중치가 학습되지 않았기 때문에 장문의 복잡한 임상 텍스트에서 필요한 정보를 저장할 수 없음..
3.3.4. ETC
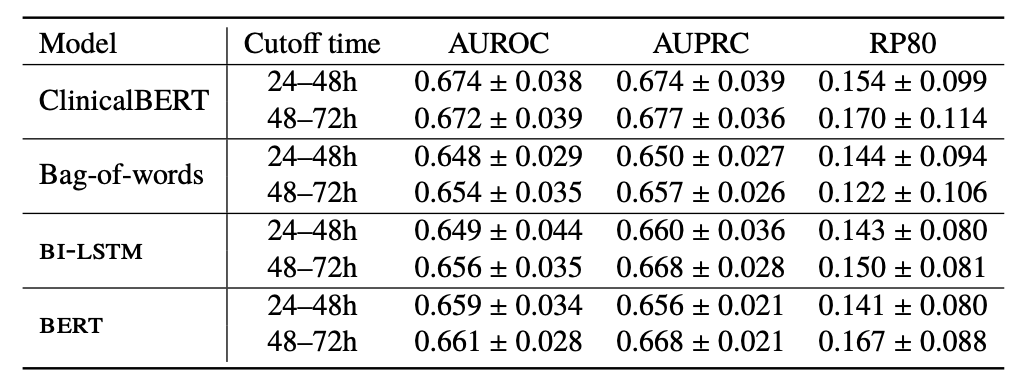
- ClinicalBERT는 환자 입원 초기의 임상 메모를 사용하여 재입원 예측에서 경쟁력 있는 기준선을 능가함.
- MIMIC-III Dataset에서는 입원 및 퇴원 시간이 제공되지만, 임상 메모에는 타임스탬프가 없음.
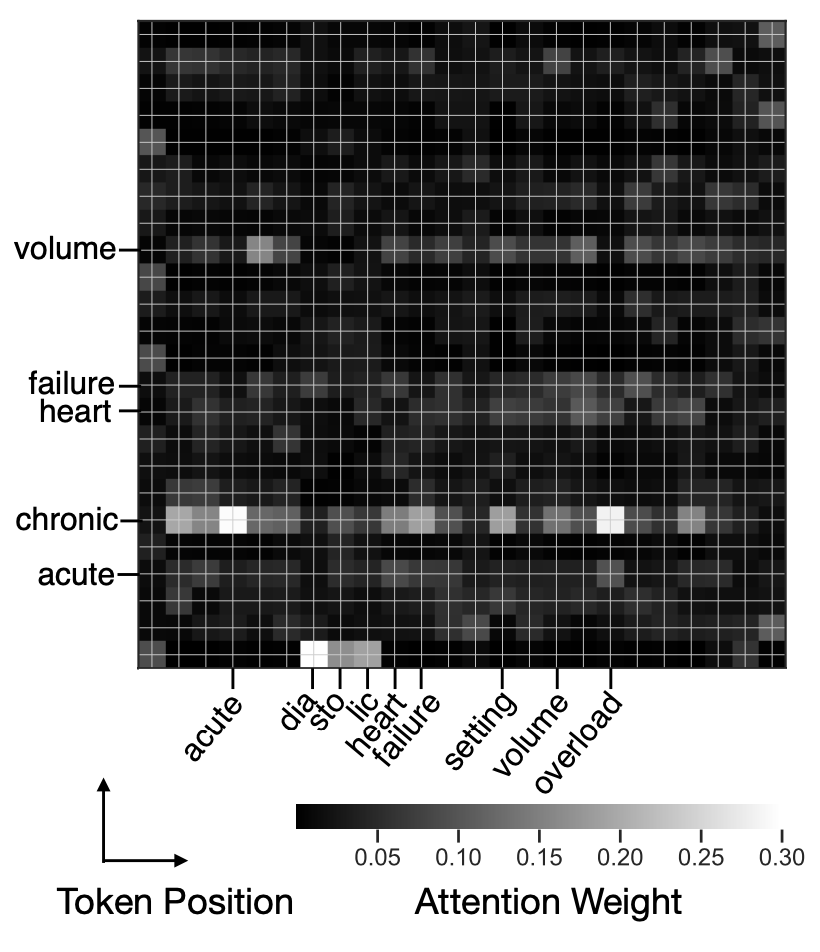
- ClinicalBERT는 임상 메모 내의 어떤 용어가 환자의 재입원을 예측하는지 밝혀내며, 해석 가능한 예측을 제공함.
- ClinicalBERT의 Attention Mechanism을 사용하여 임상 메모에 대한 모델 예측을 해석할 수 있음.
- X축: Query Token
- Y축: Key Token
4. Guidelines on using ClinicalBERT in Practice
- ClinicalBERT는 보스턴 병원의 ICU 환자 데이터인 mimic-iii로 사전 학습됨.
- 병원과 임상 환경마다 메모의 내용이 다르므로, 실제로 ClinicalBERT를 사용하려면 의료 기관에서 사용 가능한 개인 ehr 데이터셋을 사용하여 ClinicalBERT를 교육하는 것이 좋을듯함.
5. Discussion
- ClinicalBERT는 정확한 언어 모델로서 임상 텍스트 내의 의사들의 의미적 관계를 잘 포착함.
- 30일 내 병원 재입원 예측 작업에서 ClinicalBERT는 깊은 언어 모델을 능가하며, 고정된 거짓 경보 비율에서의 회수에 큰 상대적 증가를 보여줌.
- 미래의 연구는 임상 메모의 긴 종속성을 포착하기 위해 ClinicalBERT를 확장하는 공학 연구를 포함하며, 장기 메모 내에서의 상관 관계를 포착하지 못할 수 있음.
- mimic-iii 데이터셋은 병원 내에서 사용 가능한 큰 양의 임상 메모에 비해 작으므로 ClinicalBERT를 병원에서 사용할 때 미리 학습된 mimic-iii ClinicalBERT 임베딩을 사용하는 대신 더 나은 성능을 위해 이 더 큰 메모 모음에 모델을 다시 교육하는 것이 좋을 듯함.
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
- 저자는 임상 텍스트의 깊은 표현을 학습하기 위한 모델인 ClinicalBERT를 개발하고 싶어함.
- 모델을 통해 임상 메모 내의 의미적 관계를 포착하고, 30일 내 병원 재입원을 예측하는 데 사용하려고 했음.
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
- ClinicalBERT 모델의 개발과 그것이 임상 텍스트의 언어 모델링 및 의사가 평가한 의미적 관계를 얼마나 잘 포착하는지에 대한 평가
- ClinicalBERT가 병원 재입원 예측에서 얼마나 잘 수행되는지도 중요한 포인트
- 어느 프로젝트에 적용할 수 있는가?
- 병원 또는 의료 기관에서 환자의 재입원 가능성을 예측하는 데 사용될 수 있음.
- ClinicalBERT는 다른 임상 관련 예측 작업, 예를 들면 사망 위험 예측 또는 체류 시간 예측 등에도 적용될 수 있음.
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- MIMIC-III Dataset
- BERT
- 느낀점은?
- 솔직히 읽으면서 내용이 뻔했다. 기존 BERT는 위키피디아 기반이라 의학 용어를 모른다. 그래서 의학 데이터(MIMIC-III)를 학습했고 의학분야 SOTA 달성했다. 이런 스토리여서 나중에 Medical 관련 논문을 작성할 때 특정 분야에 더 집중해서 어떻게 Contribution을 줄 수 있을지 생각해봐야겠다. 좀 더 특정 질병에 초점을 맞추는 게 좋을수도?!
- 나중에 이 모델은 모델 비교할 때 써봐야겠다.
- data는?
- MIMIC-III Dataset
- 의료 중 특화 도메인은?
- 병원의 재입원 예측
- 특히, 환자가 병원에 30일 이내에 재입원될 가능성을 예측하는 것에 중점을 둠.
- 임베딩 방식은?
- ClinicalBERT는 임상 메모를 토큰의 모음으로 나타냄.
- 토큰들은 전처리 단계에서 텍스트에서 추출된 서브워드 단위임.
- ClinicalBERT에서 임상 메모 내의 토큰은 토큰 임베딩, 학습된 세그먼트 임베딩, 그리고 위치 임베딩의 합으로 표현됨.
- 다양한 토큰 시퀀스들이 ClinicalBERT에 공급될 때, 세그먼트 임베딩은 토큰이 어떤 시퀀스와 연결되어 있는지를 식별함.
- 각 토큰의 위치 임베딩은 입력 시퀀스에서 토큰의 위치에 해당하는 학습된 매개변수 집합임.
- 분류 작업에 사용하기 위해 모든 입력 토큰 시퀀스 앞에 분류 토큰 [CLS]가 삽입
📚 References
논문

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊