스프링을 이용해 개발한 웹 애플리케이션에서도 당연히 데이터베이스를 접근해야하는 경우가 있다.
당연하게도 트랜잭션을 사용해야하는 경우도 생긴다. 그러므로, 스프링은 어떻게 트랜잭션 기능을 제공하는지 알아야한다. 그전에, 스프링을 이용해서 개발한 웹 애플이케이션의 구조에 대해서 알 필요가 있다.
웹 애플리케이션의 구조는 크게 3가지 계층으로 나눌 수 있는데, 각각의 계층은 다음과 같다.
-
프레젠테이션 계층 : UI와 관련된 처리 담당
- 웹 요청과 응답, 사용자 요청 검증
- 스프링 MVC에서는 @Controller나 @RestController 를 사용하는 Controller가 이에 해당
-
서비스 계층 : 비즈니스 로직을 담당
- 특정 기술에 의존하지 않고, 순수한 자바 코드로 작성
- 스프링 MVC에서의 @Service에 해당
-
데이터 접근 계층 : 실제 데이터를 데이터베이스에 저장하는 담당
- JDBC, JPA, File, Redis,... 등의 기술로 실제 데이터 베이스에 접근하는 코드를 사용
- 스프링 MVC에서의 @Repository에 해당
참고.
서비스 계층은 가급적 비즈니스 로직만 순수한 자바코드로 구현하고, 특정 구현 기술에 의존하지 않는 것이 좋다.
특정 기술에 종속적인 부분은 프레젠테이션 계층(Spring MVC), 데이터 접근 계층(JDBC, JPA 등)이 가져 간다.
단순하게 보면 트랜잭션이 데이터 접근 계층에서 시작되겠구나라고 생각할 수 있다. 하지만, 트랜잭션은 DB의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산들을 의미한다.
즉, 트랜잭션에는 DB의 상태를 변화시키는 실제 연산 1개만이 아니라, 여러 개의 연산이 포함되어있을 수 있다. 이런 특징을 생각해보면 트랜잭션은 데이터 접근 계층이 아니라 서비스 계층에서 시작하는 것이 좋다. 데이터 접근 계층에서는 DB의 상태를 변화시키는 실제 연산들을 각각 1개씩 다루지만, 서비스 계층에서는 논리적인 기능 단위로 다루기 때문이다.
트랜잭션 사용 방법(스프링 트랜잭션 X)
스프링이 트랜잭션을 위해 제공하는 기능들 없이, JDBC만으로 트랜잭션을 사용하는 경우에 대해 알아보자.
DB상에서 트랜잭션을 사용하기 위해서는 수동커밋을 활성화시키고, 필요한 작업(쿼리)들을 수행한 뒤에 Commit 또는 Rollback을 호출하여 트랜잭션을 종료하면 된다고 이전 글에서 설명했었다. 자바에서 데이터베이스에 접근하기 위해서 사용되는 기술의 근간은 JDBC이므로, JDBC는 트랜잭션을 위한 기능들을 모두 제공한다. 아래의 코드를 보자.
public void exTransaction() throws SQLException {
Connection con = dataSource.getConnection();
try {
con.setAutoCommit(false); // ! 트랜잭션 시작
bizLogic(con); // * 비즈니스 로직(트랜잭션은 같은 커넥션을 사용해야하기 때문에 메서드 인자로 넘겨줌)
con.commit(); // * 성공시 commit
} catch (Exception e) {
con.rollback(); // ! 실패시 rollback
throw new IllegalStateException(e);
} finally {
release(con);
}
}메서드 내부에서 setAutoCommit(false), commit(), rollback()를 통해 트랜잭션을 사용함을 확인할 수 있다. 그러므로, 트랜잭션 내부의 비즈니스 로직은 트랜잭션에 의해 ACID를 보장받는다.
하지만 위의 코드에서 보이는 몇가지 문제점이 있다. 문제점들은 다음과 같다.
- 서비스 계층이 JDBC 기술에 의존한다. (Connection, DataSource, SQLException)
- 비즈니스 로직보다 JDBC로 트랜잭션을 처리하는 코드가 더 많다.
- 트랜잭션 내에서 같은 커넥션을 사용하기 위해 서비스 계층에서 얻은 커넥션을 데이터 접근 계층으로 매번 전달해야한다.
- 비즈니스 로직과 JDBC 코드가 섞여있어서 유지보수하기 어렵다.
- 향후 JDBC 대신 JPA 같은 다른 기술로 데이터 접근 방법을 변경하게 되면, 코드를 전부 수정해야한다.
- 동일한 JDBC 코드의 반복이 존재한다.
풀어서 설명하긴 했지만, 결국 모든 문제점은 서비스 계층에 JDBC라는 특정 구현 기술이 누수되었기 때문에 발생한다.
JDBC를 사용해서 자바 코드로 DB에 접근하기 위해 데이터 접근 계층으로 모든 JDBC 코드를 몰아두었는데, 트랜잭션을 적용하려고 보니, JDBC가 서비스 계층에서도 사용되는 결과가 초래된다. 하지만, 그렇다고 트랜잭션의 시작 위치를 서비스 계층이 아닌 곳으로 지정할 수도 없다.
위의 문제들을 해결하기 위해 스프링은 트랜잭션을 위한 여러 기능들을 제공한다.
트랜잭션 추상화
트랜잭션을 사용하는 코드는 데이터 접근 기술마다 다르다. 단적인 예시로 JDBC로 트랜잭션을 사용하는 코드와 JPA로 트랜잭션을 사용하는 코드는 전혀 다른 코드이다. 데이터 접근 계층에서 사용하는 기술이 변경될 때마다 서비스 계층에서 사용하는 트랜잭션 코드를 매번 변경하는 일은 매우 불편하기 때문에, 스프링은 추상화를 통해서 데이터 접근 계층에서 사용하는 기술이 변경되더라도 동일한 트랜잭션 코드를 사용할 수 있게 한다.
스프링 트랜잭션 추상화의 핵심은 PlatformTransactionManager 인터페이스이다. 아래의 코드를 보자.
public interface PlatformTransactionManager extends TransactionManager {
TransactionStatus getTransaction(@Nullable TransactionDefinition definition)
throws TransactionException;
void commit(TransactionStatus status) throws TransactionException;
void rollback(TransactionStatus status) throws TransactionException;
}스프링이 제공하는 PlatformTransactionManager 인터페이스를 사용하면 getTransaction() 메서드로 트랜잭션을 시작(메서드 내부에서 setAutoCommit(False) 수행된다)하고, commit() 과 rollback()로 결과에 따라 트랜잭션을 종료하면 된다. 데이터 접근 계층의 기술이 변경되더라도, 변경된 기술에 맞는 PlatformTransactionManager 구현체로만 바꿔주고, 나머지 코드는 수정하지 않아도 된다.
참고.
getTransaction() 메서드의 이름이 startTransaction() 같은 시작의 의미를 담지않고 있는 이유는 기존에 이미 진행중이 트랜잭션이 있는 경우 해당 트랜잭션에 참여를 할 수도 있기 때문이다.
스프링이 제공하는 트랜잭션 매니저는 크게 2가지 역할을 한다.
- 트랜잭션 추상화
- 리소스 동기화
1번의 경우 바로 위에서 설명했고, 2번의 리소스 동기화는 좀 더 자세히 알 필요가 있다.
리소스 동기화
트랜잭션을 유지하려면 트랜잭션의 시작부터 끝까지 같은 DB 커넥션을 유지해야한다. 그래서 JDBC만으로 트랜잭션을 사용하는 경우에는 동기화를 위해 서비스 계층에서 얻은 커넥션을 데이터 접근 계층으로 매번 전달했다. 이런 불편한 점을 스프링은 트랜잭션 동기화 매니저를 제공함으로써 해결한다.
트랜잭션 동기화 매니저는 쓰레드 로컬(ThreadLocal)이라는 특정 쓰레드에 종속되어 해당 쓰레드만 접근할 수 있는 저장소를 이용하여 커넥션을 동기화해준다. 트랜잭션 매니저는 내부에서 이 트랜잭션 동기화 매니저를 사용한다. 트랜잭션 동기화 매니저는 쓰레드 로컬을 사용하기 때문에 멀티쓰레드 상황에서도 안전하게 커넥션을 동기화 할 수 있다. 따라서 한 트랜잭션 내에서 커넥션이 필요하면 트랜잭션 동기화 매니저를 통해서 동일한 커넥션을 획득하면 된다.
스프링이 제공하는 트랜잭션 매니저와 트랜잭션 동기화 매니저를 사용한 트랜잭션 동작과정은 다음과 같다.
- 서비스 계층에서 트랜잭션 시작을 위해 transactionManager.getTransaction()을 호출하여 트랜잭션을 시작한다.
- 트랜잭션 매니저는 내부에서 데이터 소스를 사용해서 커넥션을 얻는다.
- 커넥션을 수동 커밋모드로 변경하여 실제 데이터베이스 트랜잭션을 시작한다.
- 커넥션을 트랜잭션 동기화 매니저가 쓰레드 로컬에 보관한다.
- 쓰레드 로컬에 커넥션을 보관하므로 멀티 쓰레드 환경에서도 안전하게 커넥션을 보관할 수 있다.
- 서비스는 비즈니스 로직을 실행하면서 Repository의 메서드들을 호출한다. 이 때 커넥션을 따로 전달하지 않는다.
- Repository(데이터 접근 계층) 메서드들은 트랜잭션 동기화 매니저에 보관된 커넥션을 꺼내서 사용한다.
- 획득한 커넥션을 사용해서 Repository는 SQL을 DB에 전달해서 실행한다.
- 비즈니스 로직이 끝나고 트랜잭션을 종료한다. 트랜잭션은 commit 또는 rollback을 통해 종료된다.
- 트랜잭션을 종료하려면 동기화된 커넥션이 필요하다. 트랜잭션 동기화 매니저를 통해 동기화된 커넥션을 획득한다.
- 획득한 커넥션을 통해 데이터베이스에 트랜잭션을 커밋하거나 롤백한다.
- 전체 리소스를 정리한다. (트랜잭션 동기화 매니저/쓰레드 로컬 정리, 자동 커밋모드로 돌려놓기, 커넥션 종료 혹은 커넥션 풀에 커넥션 반환)
참고.
트랜잭션 매니저에서 사용하는 트랜잭션 동기화 매니저는 TransactionSynchronizationManager 이다.
스프링이 제공하는 트랜잭션 매니저를 사용하면, JDBC만을 이용해서 트랜잭션을 사용할 때보다 훨씬 편리하게 트랜잭션을 사용할 수 있음을 알 수 있다. 하지만, 여전히 서비스 계층의 코드에 getTransaction(), commit(), rollback()과 같은 트랜잭션 처리용 코드가 남아있고, SQLException 같은 JDBC에 종속적인 예외가 남아있다.
반복적인 트랜잭션 처리용 코드를 없애기 위해 스프링은 트랜잭션 템플릿이라는 기능을 제공하지만, 트랜잭션 템플릿을 사용하더라도 SQLException과 같은 JDBC 종속적인 예외가 남아있고, 트랜잭션 템플릿 사용을 위한 코드가 추가되기 때문에, 서비스 계층에 온전히 비즈니스 로직만 남기지 못한다.
스프링은 트랜잭션 템플릿보다 더 좋은 트랜잭션 AOP와 @Transactional annotation을 이용한 트랜잭션 사용 방법을 제공하기 때문에 트랜잭션 템플릿과 관련된 내용은 생략한다.
트랜잭션 AOP와 @Transactional
트랜잭션 AOP와 @Transactional annotation을 사용하면, 서비스 계층에 온전히 비즈니스 로직만 남길 수 있다.
AOP란 스프링 핵심 원리에서 짧게 설명했었지만, 프록시 객체를 이용하는 기술이다. 실제 주입될 객체 대신 공통 관심사를 처리할 수 있는 프록시 객체를 대신 주입하고, 대신 주입된 프록시 객체 내부에서 실제 주입되야할 객체를 호출하는 방식으로 AOP가 동작한다.
트랜잭션 AOP도 동일한 매커니즘을 갖고 있다. 트랜잭션 AOP(프록시)가 공통관심사인 트랜잭션을 처리하는 모든 로직을 가져가고, 실제 서비스 계층의 비즈니스 로직을 내부적으로 호출한다. 그림을 보면 더 이해하기 쉽다.
트랜잭션 AOP를 적용하기 전의 상태를 먼저 보자.
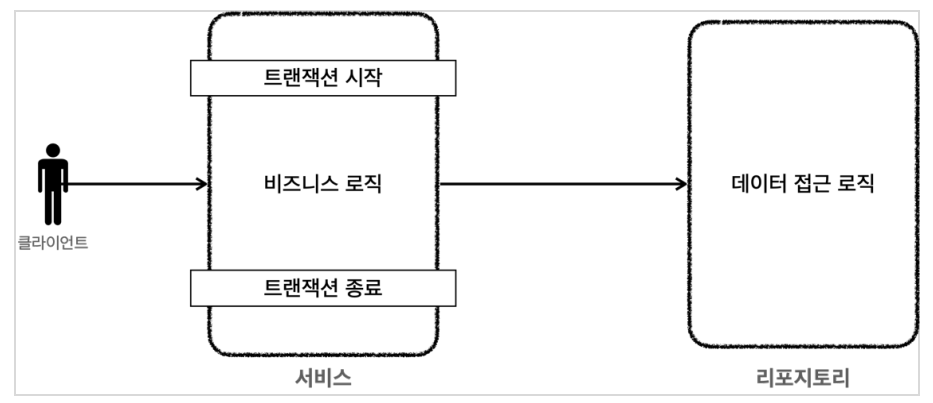
다음은 트랜잭션 AOP를 적용한 후의 상태이다.
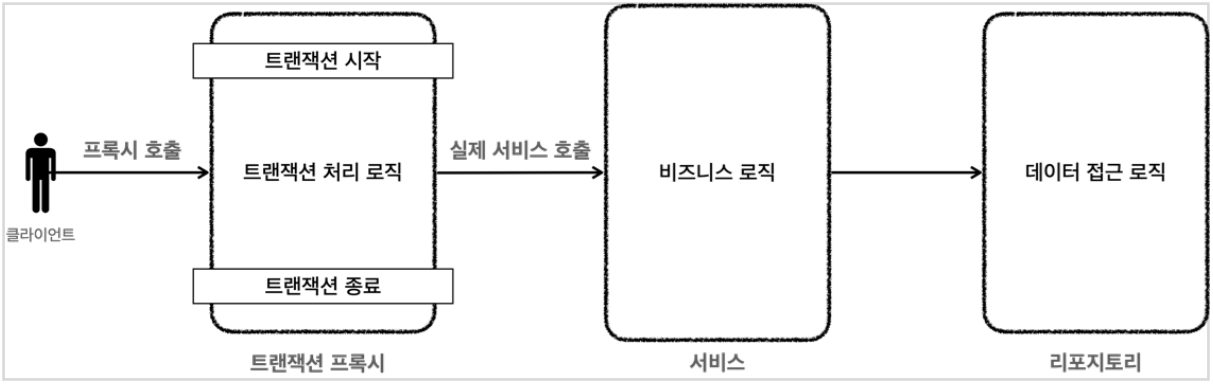
원래는 비즈니스 로직을 수행하는 서비스 계층에서 트랜잭션을 시작/종료 했기 때문에, 트랜잭션을 처리하는 코드가 서비스 계층에 있었지만, 트랜잭션 AOP를 사용하면 트랜잭션 프록시가 대신 트랜잭션 처리 코드를 가져가고 내부적으로 실제 서비스 계층의 비즈니스 로직을 수행해야할 때 실제 서비스 계층의 비즈니스 로직을 호출한다.
코드로 살펴보면 아래와 같은 구조라고 생각하면 된다.
public class TransactionProxy {
public void login() {
TransactionStatus status = transactionManager.getTransaction();
try {
target.logic(); // 실제 서비스의 비즈니스 로직 호출
transactionManager.commit();
} catch (Exception e) {
transactionManager.rollback();
}
}
}
public class ExService {
public void logic(){
// 비즈니스 로직
...
}
}트랜잭션 AOP를 이용하면 트랜잭션 프록시가 트랜잭션 처리 코드를 모두 가져가게되고, 프록시는 내부에서 서비스의 비즈니스 로직을 호출한다. 비로소 서비스 계층의 코드에는 비즈니스 로직만 남길 수 있게 되었다.
트랜잭션은 매우 중요한 기능이고, 누구나 다 사용하는 기능이기 때문에, 스프링은 트랜잭션 AOP를 처리하기 위한 모든 기능을 제공한다. 만약 스프링 부트를 사용한다면 트랜잭션 AOP를 처리하기 위해 필요한 스프링 빈들도 자동으로 모두 등록해준다.
개발자는 트랜잭션 처리가 필요한 곳에 @Transactional annotation만 붙여주면 된다. 스프링의 트랜잭션 AOP는 이 annotation을 인식해서 트랜잭션 프록시를 적용해준다.
@Transactional annotation은 주로 @Service가 붙은 클래스의 클래스 레벨 또는 메서드 레벨에 붙는다. 스프링 컨테이너를 초기화할 때, 만약 스프링 빈으로 등록되는 클래스의 클래스 레벨이나 메서드 레벨에 @Transactional annotation이 붙어 있다면, 자동으로 프록시 객체를 대신 스프링 빈으로 등록한다. 이 프록시 객체는 내부에서 원본 클래스의 객체를 호출하는 방식으로 동작한다.
@Transactional의 사용법은 추후 더 자세하게 설명한다.
참고.
@Transactional annotation 하나만 선언해서 편리하게 트랜잭션을 적용하는 것을 선억전 트랜잭션 관리라하고, 트랜잭션 매니저나 트랜잭션 템플릿을 통해서 트랜잭션 관련 코드를 직접 작성하는 것을 프로그래밍 방식의 트랜잭션 관리라고 한다. 선언적 트랜잭션 관리가 훨씬 간편하고 실용적이기 때문에 주로 이를 사용한다.
참고.
트랜잭션 AOP도 결국 내부에서는 트랜잭션 매니저를 사용하게 된다.
