스프링 DB
1.데이터베이스와 JDBC

애플리케이션을 개발할 때 중요한 데이터는 대부분 데이터베이스에 보관한다.데이터베이스는 그 자체로도 하나의 시스템이기 때문에 보통 애플리케이션과 분리되어있는데, 만약 클라이언트가 애플리케이션을 통해 데이터를 저장하거나 조회하는 경우, 애플리케이션 서버는 다음 과정을 통해
2.커넥션 풀과 데이터 소스
이전 포스트에 JDBC를 이용해서 DB를 사용하고자 할 때, 가장 먼저 해야하는 일은 DB 커넥션을 얻는 일이었다. DB 커넥션을 얻을 때는 다음과 같은 과정을 거친다. 애플리케이션 로직은 DB 드라이버를 통해 커넥션을 조회한다. DB 드라이버는 DB와 TCP/IP
3.트랜잭션 (Transaction)
데이터를 저장할 때 단순히 파일에 저장해도 되는데, 굳이 데이터베이스에 저장하는 이유는 무엇일까? 다른 여러가지 이유들이 있겠지만, 가장 대표적인 이유는 DB는 트랜잭션이라는 개념을 지원하기 때문이다. DB에서 트랜잭션은 하나의 논리적 기능을 안전하게 처리하도록 보장
4.스프링 트랜잭션
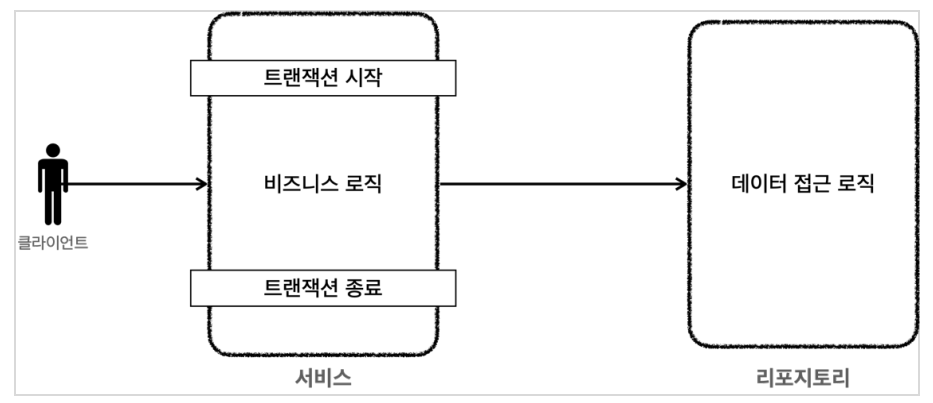
스프링을 이용해 개발한 웹 애플리케이션에서도 당연히 데이터베이스를 접근해야하는 경우가 있다. 당연하게도 트랜잭션을 사용해야하는 경우도 생긴다. 그러므로, 스프링은 어떻게 트랜잭션 기능을 제공하는지 알아야한다.
5.스프링 예외 추상화
체크 예외와 언체크 예외 자바가 제공하는 예외처리 매커니즘에서 예외의 종류는 크게 체크 예외와 언체크 예외로 나눌 수 있다. 이 두 종류의 예외는 다음과 같은 특징과 차이점을 가진다. 체크 예외 : 컴파일러가 예외를 체크한다. 즉, 체크 예외는 예외가 발생했을 때 반
6.JDBC Template 간단 정리
자바 진영에서 DB에 접근하기 위해서는 JDBC를 사용한다. 그런데 실제 JDBC를 사용하여 DB에 접근할 때 필요한 코드를 보면, 실제 DB에 날리는 SQL 쿼리와 관련된 코드보다 그 외의 코드들이 양이 더 많다. 참고.커넥션 획득, statement 준비 및 실행,
7.스프링 트랜잭션의 이해
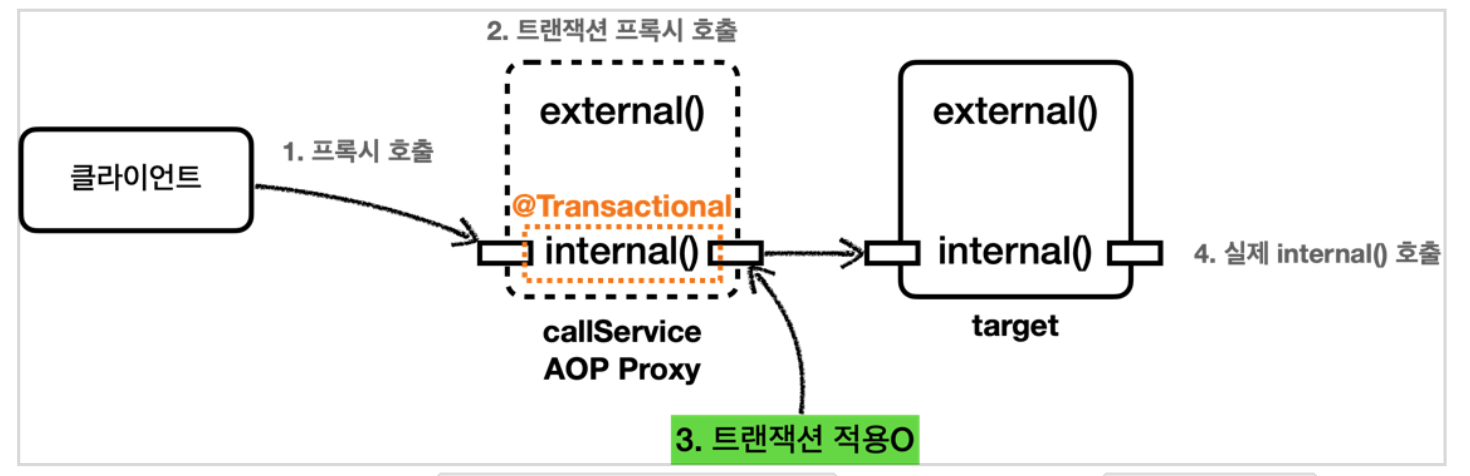
스프링 트랜잭션에 대한 이해
8.스프링 트랜잭션 전파
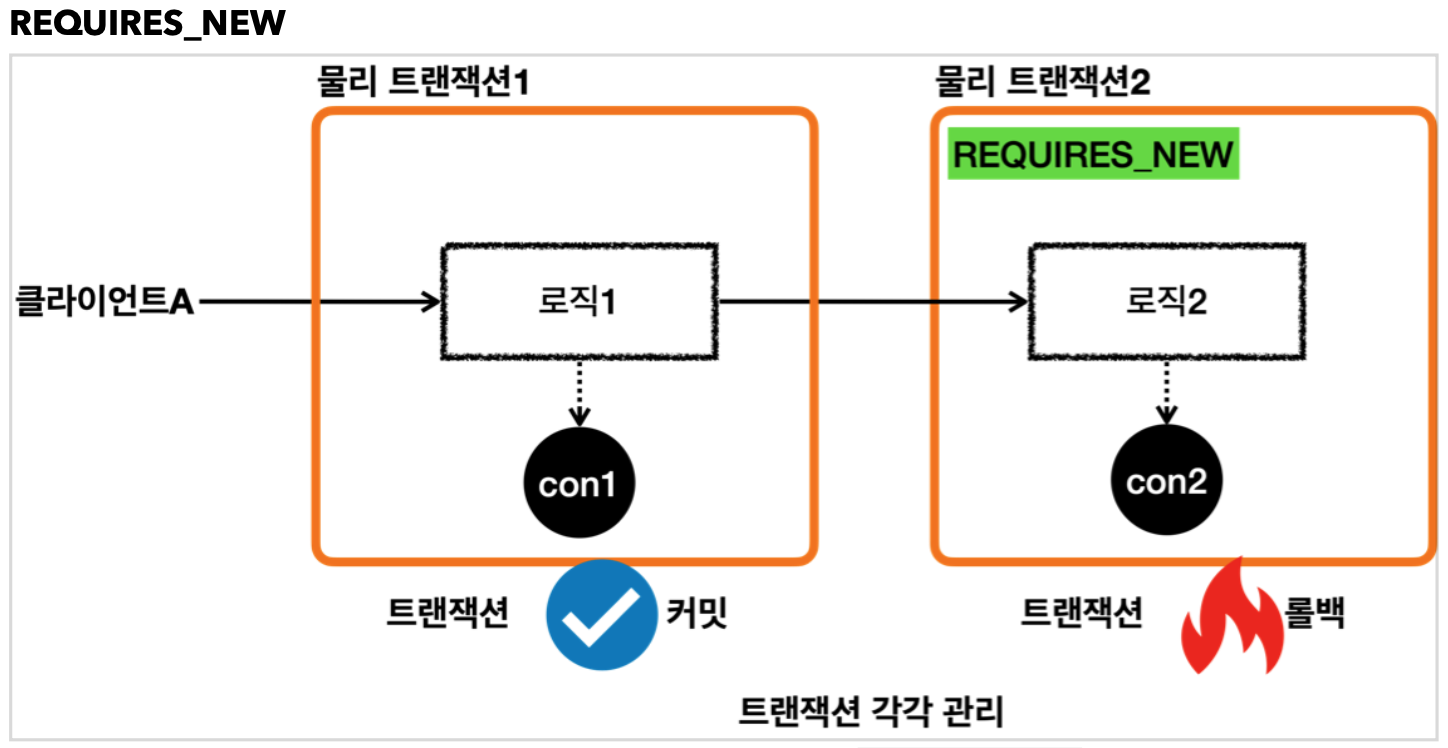
이전 글에서 스프링이 제공하는 스프링 트랜잭션이 어떻게 동작하는지에 대해 정리해보았다. 스프링 트랜잭션(이하 트랜잭션으로 통칭)을 독립적으로 각각 사용하면, 트랜잭션 별로 처리되어 트랜잭션 내의 동작에 따라 예외가 발생시에는 롤백하고, 문제가 없을시에는 커밋할 것이다
9.MyBatis 간단 정리
MyBatis는 이전 글의 주제였던 JDBC Template보다 더 많은 기능을 제공하는 SQL Mapper이다. 기본적으로 JDBC Template이 제공하는 대부분의 기능을 제공하지만, 특히 SQL을 XML에 편리하게 작성할 수 있고 JDBC Template이 해결