CREATE TABLE
- 프라이머리 키, 외래키 지정방법
CREATE TABLE Employee ()
() 안에
PRIMARY KEY (DNUMBER,DLOCATION), -> 프라이머리 키 지정
FOREIGN KEY (DNUMBER) REFERENCES DEPARTMENT(DNUMBER) ->외래키 지정방법
ON DELETE SET NULL ->참조대상의 필드값이 삭제되면 참조하고있는 필드는 NULL값으로
ON DELETE SET CACADE ->참조대상의 필드값이 삭제되면 참조하고있는 필드도 삭제
ON UPDATE SET CASCADE ->참조대상의 필드값이 업데이트되면 참조하고있는 필드도 자동으로 업데이트
위의 ON DELETE SET~ 부분은 외래키 쓰는 부분인 REFERENCES ~ 바로뒤에 ,(COMMA) 없이 이어서 써주고 다 써준후에 괄호를 닫아주면 (CREATE TABLE EMPLOYEE 하고 열어준 괄호를 이때 닫아준것
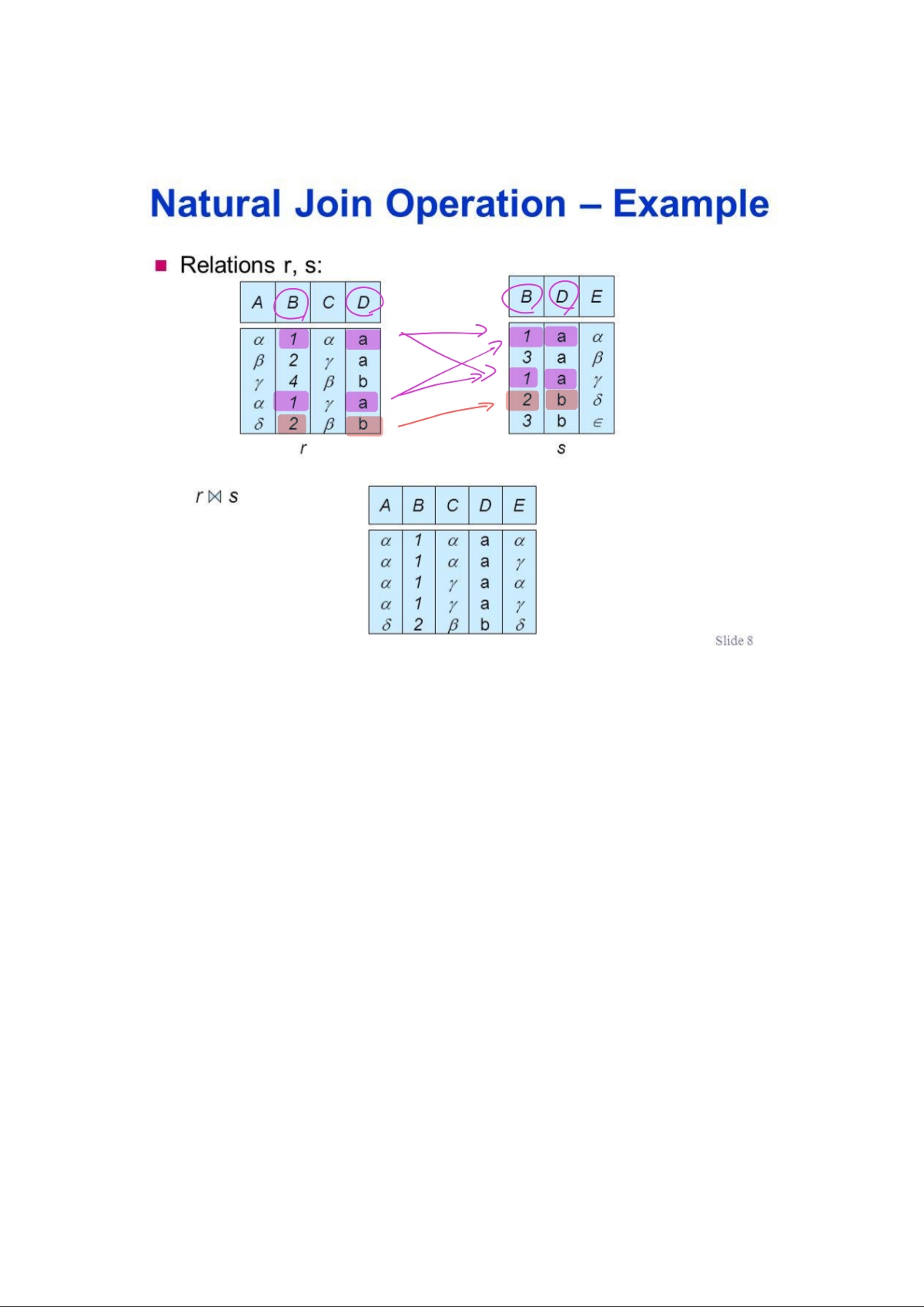
join (일단 흐름 이해하기)
join은 서로 다른 두개의 테이블을 결합하는 연산이다
더 자세히 말하면 카티션 프로덕트를 진행하고 그 결과에서 조건식을 만족하는 레코드만 선택하는 연산이다
카티션 프로덕트: 두 테이블에서 각각의 레코드들을 서로 결합하여 하나의 레코드로 구성함 즉, 가능한 모든 조합이 나옴 ->두 테이블 투플갯수의 곱만큼
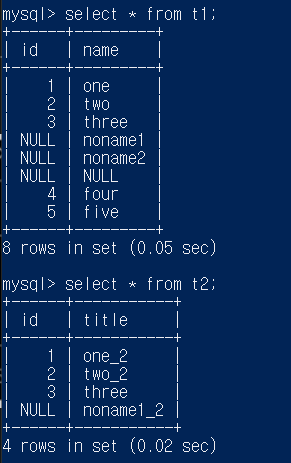
t1,t2가 위와 같이 있을 때
select * from t1 join t2 를 해보자
가능한 모든 조합이 나올 것으로 예상할 수 있다 (카티션 프로덕트)
결과는 아래와 같다

이때 select * from t1 join t2 where t1.id=t2.id라는 조건을 걸어주면 저 중에서 t1의 id와 t2의 id가 같은 것만 검색이 될 것이다
결과는 아래와 같다
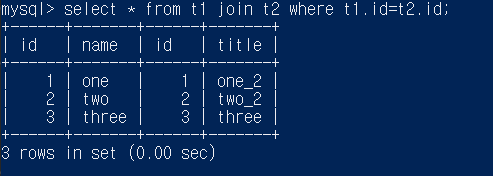
위의 결과는 id라는 column이 2개가 나왔다
이제 여기서 natrual join을 이용하면 중복되는 column은 한 개로 합쳐질 것이다
select * from t1 natural join t2 where t1.id=t2.id
결과는 아래와 같다
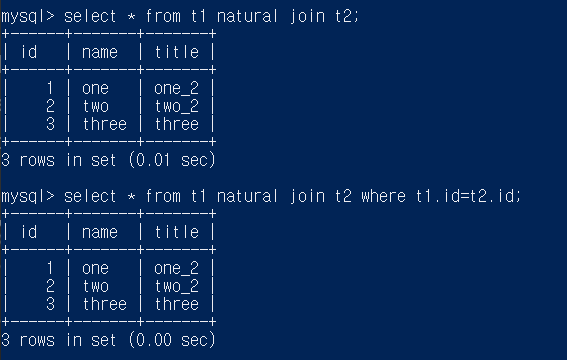
예상대로 결과가 나왔는데 이 때 지금 위의 결과를 보면 where~ 조건이 없어도 똑같이 나오는 것을 알 수 있다
natrual join은 조건이 필요없다고 하는데 그 이유는 확실하지는 않지만 natural join의 정의가 두 테이블의 column명과 그 column의 값도 같은 것들을 join하는 것이기 때문이 아닐까 추측 중 이다
아래 부터는 다른 예시임
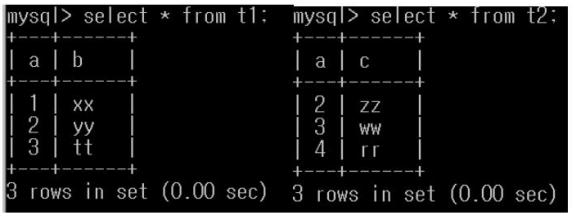
왼쪽은 t1, 오른쪽은 t2임
select * from t1 join where t1.a=t2.a;
는 합치는데 t1의 a와 t2의 a가 같은것만 합치라는 의미이고 이를 진행하면 아래와 같은 결과가 나온다
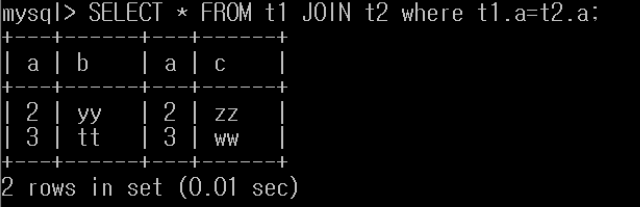
inner join
Equi join

원래는 아래와 같이 표현을 해줘야 하는데
implicit notation으로 위 처럼 많이 쓴다
Natural join
select * from t1 natural join t2;
column의 이름이 같고 또 값도 같으면 그 해당하는 row끼리 join한다
그래서 진행해보면 아래와 같은 결과가 나온다

아래는 또 다른 두가지 예시임
예시 1
예시2

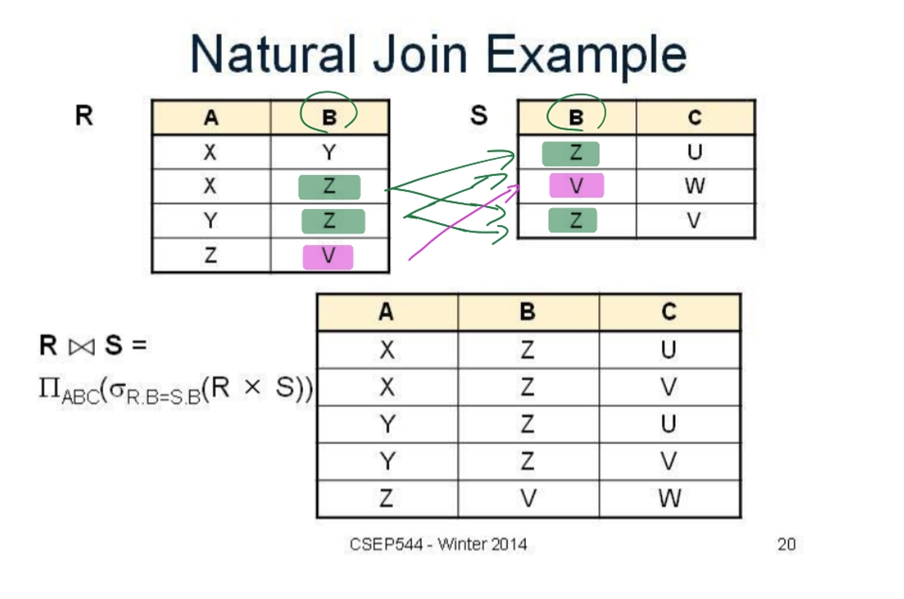
동등조인과 자연조인의 차이
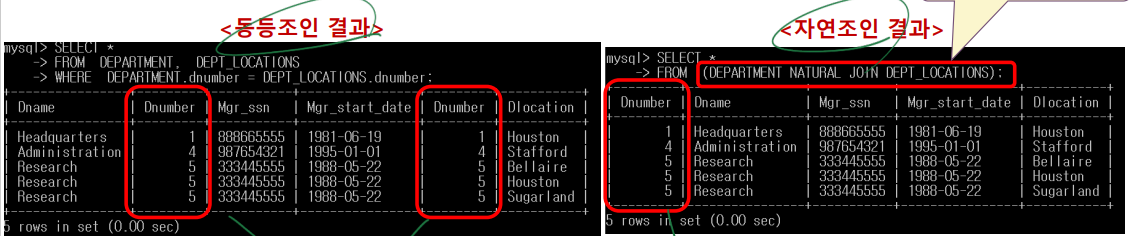
둘다 inner join으로 교집합의 느낌임 -> 컬럼명이 같고 값이 같은 부분을 기준으로 합침
동등조인은 column명이 같은것이 여전히 존재하고 (2개있으면 2개다 나옴)
자연조인은 column명이 같은것은 하나로 합쳐진다 (1개만 나옴)
outer join
Outer Join은 공통된 부분만 결합하는 Inner Join과 다르게 공통되지 않은 row도 유지한다.
이 때, 왼쪽 테이블의 row를 유지하면 Left Outer Join,
오른쪽 테이블의 row를 유지하면 Right Outer Join,
양쪽 테이블의 row를 모두 유지하면 Full Outer Join이다.
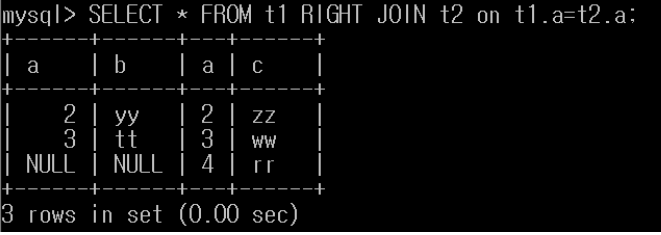
Right join
select * from t1 right join t2 on t1.a=t2.a
오른쪽 table(t2)기준으로 t1.a과t2.a가 일치하는 row결합
일치하지 않을 시 null로 표시함 (null을 안나오게 하려면 is not null을 붙여주면 됨)
기준이 되는 table은 모두 써주도록 한다
기준이 되는 table을 먼저 다 쓰고 그것에 맞춰서 t1을 작성하면됨
Left join
기준이 되는 table이 left인것 빼고는 Right join과 같다
Full join
mysql 은 full join 지원x
예제

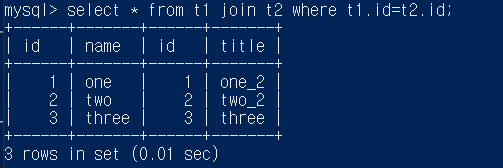
select * from t1 join where t1.id=t2.id;
select # from t1,t2 where t1.id=t2.id; 와 같음
(select # from t1 inner join t2 on t1.id=t2.id 와 같음(명시적표현))
(별 대신 #으로 썼음)
id라는 column명과 그의 값 1,2,3 이 같은 부분을 join
select * from t1 natural join t2;
id라는 column명과 그의 값 1,2,3 이 같은 부분을 join 하는데 그냥 join과 다르게 id column은 하나로 합쳐짐

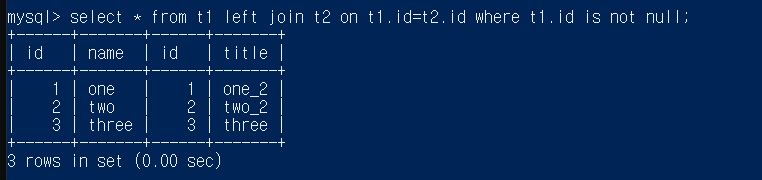
select * from t1 left join t2 on t1.id=t2.id;
기준인 t1을 먼저 놓고 그 옆에 t1의 id와 t2의 id가 같은 부분을 놓고
다른 부분은 null로 채워놓음

select * from t1 natural left join t2;

select * from t1 natural right join t2;

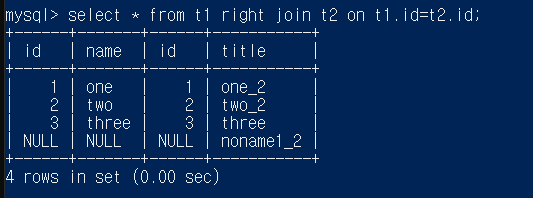
select * from t1 right join t2 on t1.id=t2.id;
t2를 우측에 먼저 놓고 t1의 t1.id=t2.id 인 부분을 놓고 남은 부분은 null로 채움
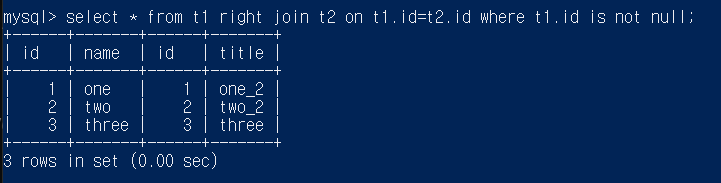
select * from t1 left join t2 on t1.id=t2.id where t1.id is not null;
select * from t1 right join t2 on t1.id=t2.id where t1.id is not null;
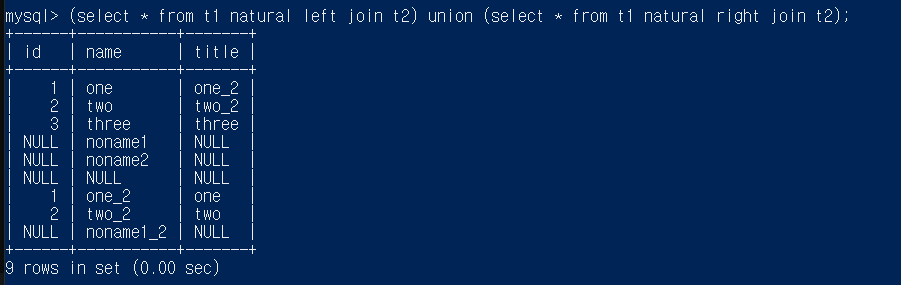
(select from t1 natural left join t2) union (select from t1 natural right join t2);
DISTINCT
LIKE
Group by
- 특정 애트리뷰트의 값이 같은 투플들을 모아서 그룹을 생성하고 이 그룹에 대하여 집단함수(sum / avg / count /max / min 등) 을 적용함
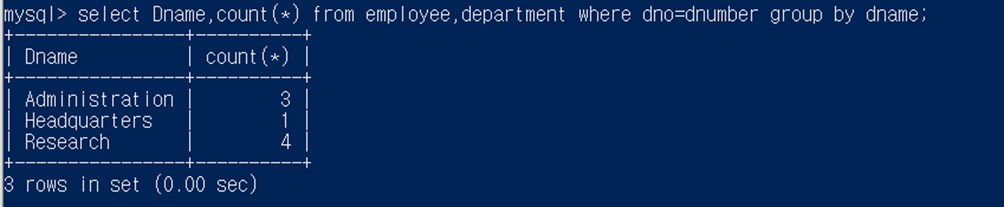
각 부서에서 근무하는 사원의 수를 검색하라. (부서이름과 소속 사원수를 제시)
먼저 employee투플들을 dname을 기준으로 분할하여 그룹을 생성한 후에 집단함수인 count함수를 적용한 것임
having
having은 group by절에 대한 조건을 제시할 수 있음
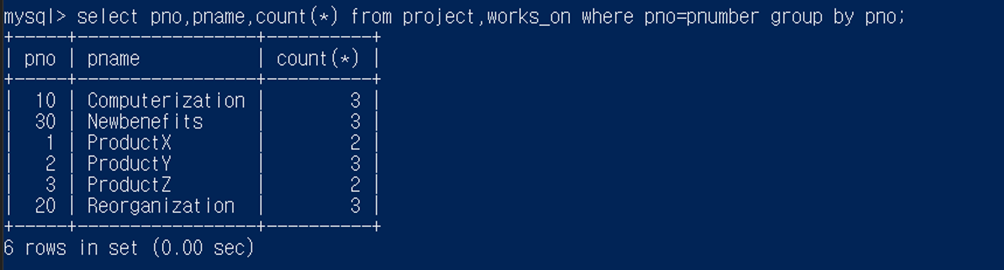
(먼저 having 없을 때) 프로젝트에 대해서 프로젝트 번호, 프로젝트 이름, 그 프로젝트에서 근무 하는 사원들의 수를 검색하라.
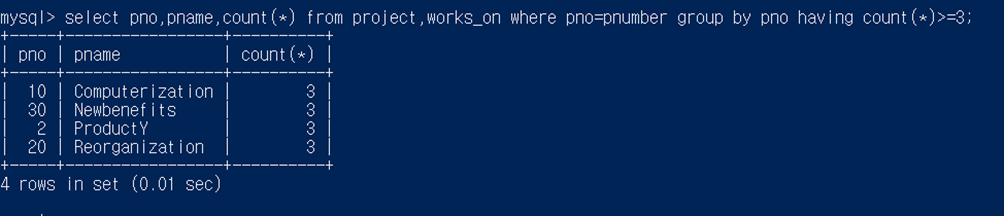
(having 있을 때) 세 명 이상의 사원이 근무하는 프로젝트에 대해서 프로젝트 번호, 프로젝 트 이름, 그 프로젝트에서 근무하는 사원들의 수를 검색하라.
BETWEEN
급여가 30,000달러에서 40,000달러 사이에 있는 5번 부서의 모든 사원을 검색하라
나는 처음에는 아래처럼 했다

근데 지금 아래에 있는 것처럼 해야 하나 봄

ORDER BY
내림차순(DESC)
모든 사원을 급여(높은 순서)로 제시

오름차순(ASC)
모든 사원을 생년월일(나이가 많은 순서)로 제시

INSERT
DELETE
UPDATE
