
주의사항 동작의 차이
우선 in과 exists의 차이점을 알고있어야한다
in을 사용할 때는 in뒤의 쿼리문을 먼저 실행하고 그 이후에 in앞의 쿼리문을 실행한다
exists을 사용할 때는 exists 앞의 쿼리문을 먼저 실행하고 그 이후에 exists뒤의 쿼리문을 실행하게 된다
In
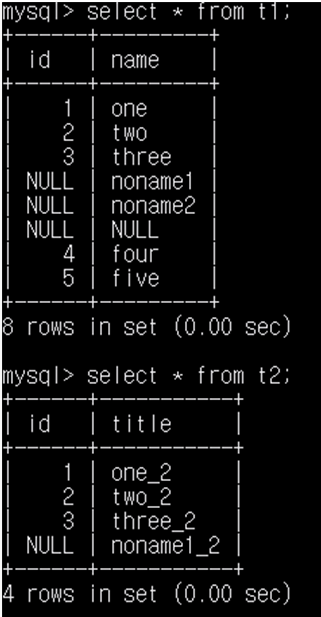
select * from t1 where id in (select id from t2);
t2의 id를 먼저 가져오고 t1의 id가 그곳에 속하는지 비교
NOT IN
select * from t1 where id not in (select id from t2);
t2의 id를 먼저 가져오고 t1의 id가 그것에 속하는지 비교
t1의 id가 4일때를 보면
아래에서 왼쪽이 t1의 id , 오른쪽이 t2의 id라면
4 =! 1
4 =! 2
4 =! 3
4 와 null은 비교하는 순간 unknown 이기 때문에 false로 판단해 4는 나오지않음 5도 마찬가지

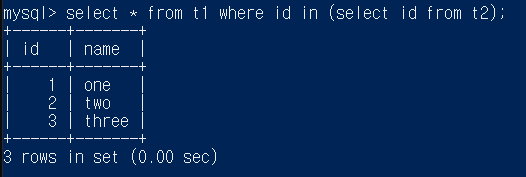
select * from t1 where id not in (select id from t2 where id is not null);
t2중에서 id가 null이 아닌것을 먼저 가져오고
t1의 id가 그것에 속하는지 아닌지 비교
4 =! 1 (여기서 이미 나가리) =!는 속하지 않는다는 의미
4 =! 2
4 =! 3
따라서 4는 ok ,이런식으로 5도 비교해보면 됨
EXISTS
select * from t1 where exists ( select # from t2);
별 대신에 # 씀 (양쪽으로 ** 하면 italic으로 변해서..
t1먼저 가져오는데
t1.id 1가져올 때 exists뒤에 존재하니까 where 은 true ->실행
t2.id 2가져올 때 exists뒤에 존재하니까 where 은 true ->실행
이런식으로 t1을 전부 가져와버리게됨

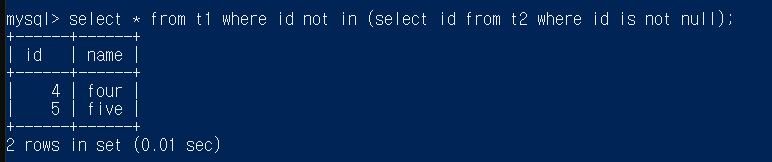
select * from t1 where exists ( select star from t2 where t1.id=t2.id);
t1을 모두 가져오고 exists뒤에 존재하는지 체크
가져온 t1의 id와 t2의 id가 같은 것만 가져옴
NOT EXISTS
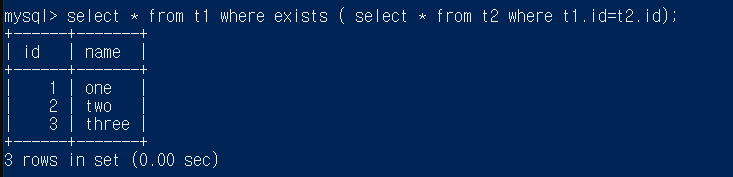
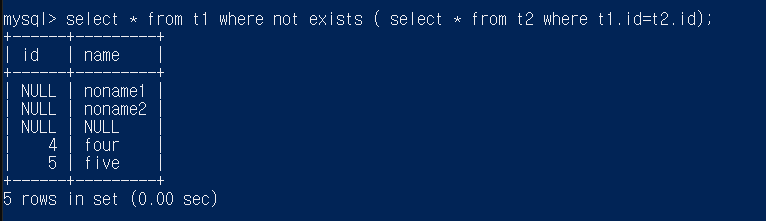
select * from t1 where not exists ( select star from t2 where t1.id=t2.id);
일단 t1을 모두가져옴 그리고 가져온 t1중에서 not exitst뒤의 쿼리문으로 체크
- t1.id가 1인 경우는 t2에도 존재 따라서 안됨
2,3도 마찬가지 - t1.id가 null 인 경우 null은 비교연산시 unknown이므로 where절이 true가 됨
- t1.id가 4인 경우는
4 =! 1
4 =! 2
4 =! 3
4 와 null 비교연산은 unknown이므로 where절이 true가 됨 (5도 마찬가지)
차이점(아닐 수도)
in 쓸 때는 where 필드이름 in ~ 이렇게쓰고 (필드에 대한 조건거는 느낌)
exists 쓸 때는 필드이름안쓰고 바로 where exists~
하는것 같다
참고: (정말 정리 잘 해놓으신 분!) https://doorbw.tistory.com/222
