분산분석
분산분석 : 셋 이상의 모집단의 평균차이를 검정
t-test : 두개의 모집단의 평균차이를 검정
분산분석의 이해
실험계획법 : 모집단의 특성에 대해 추론하기 위해 특별한 목적성 가지고
데이터를 수집하기 위한 실험 설계
반응변수 : 관심의 대상이 되는 변수
요인/인자 : 실험 환경 또는 조건을 구분하는 변수로 실험에 영향을 주는 변수
인자수준 : 인자가 취하는 개별값
왜 분산분석인가 : 모집단 평균들 비교하기위해 특성값의 분산 또는 변동을 분석
실험을 통해 얻은 편차의 제곱합을 통해 평균 차이 검정
일원 분산분석 : 한가지 요인을 기준으로 집단간 차이 조사
이원 분산분석 : 두가지 요인을 기준으로 집단간 차이 조사
다원 분산분석 : 세가지 이상 요인을 기준으로 집단간 차이 조사
Oneway ANOVA : 한개의 반응 변수와 한개의 독립인자

Twoway ANOVA : 한개의 반응ㅇ변수와 두개의 독립인자
상호작용 : 한 독립변수의 main effect가 다른 독립변수의 level에 따라서 원래 선형관계를 비선형환계로 변하는 경우
시계열
시계열분석 : 시계열(시간의 흐름에따라 기록된것) 자료와 여러변수 인과관계 분석
시계열 데이터 : 시간을 기준으로 관측된 데이터 일~년 또는 시간 등 따라 관측
연속시계열과 이산시계열로 구분
연속 시계열 : 자료가 연속적으로 생성
이산형 시계열 : 일정 시차(간격)을 두고 관측되는 형태의 데이터
시계열 분석의 목적
예측, 경향 등을 파악
전통적인 시계열 분석방법
이동 평균 모형 : 최근데이터의 평균을 예측치로 사용
자기 상관 모형 : 변수의 과거값의 선형 조합을 이용하여 예측
ARIMA : 관측값과 오차를 사용해서 모형을 만들어 미래를 예측
지수평활법 : 현재에 가까운 시점에 가장 많은 가중치 주고
멀어질수록 낮은 가중치주어 미래 예측
시계열분석 방법

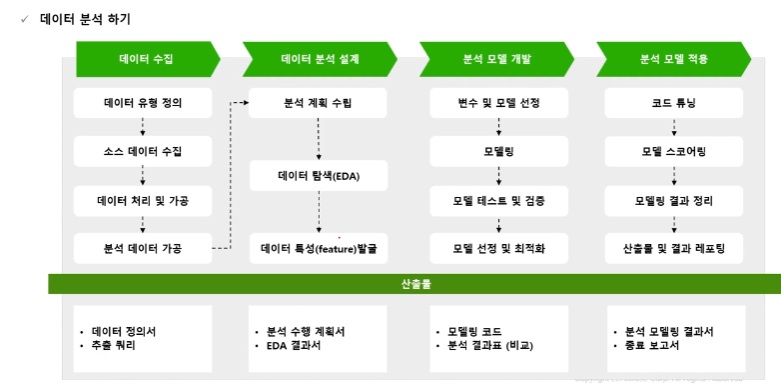
데이터 분석 프로세스
머신러닝 : 인공지능의 한 분야로 컴퓨터가 학습할 수 있도록 하는 알고리즘, 기술 개발
컴퓨터가 학습모형을 기반으로 주어진 데이터를 통해 스스로 학습하는 것
머신러닝은 task, experience, performance 세가지 요소 가지고 있음
분석하고자 하는 목표 T / 경험E를 정의하기위한 데이터 수집 /
퍼포먼스P를 향상시키기위한 방법을 정의함
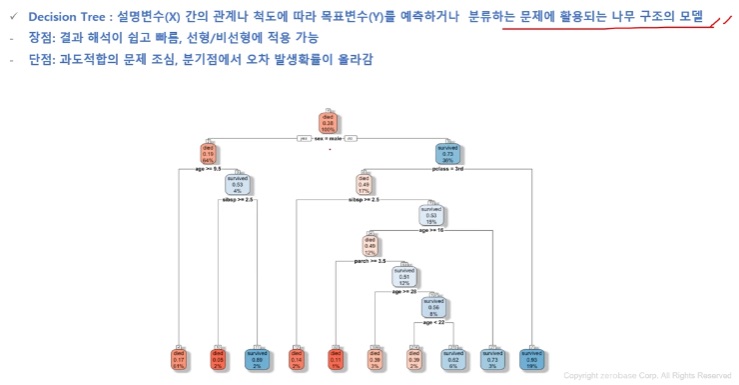
Decision Tree
앙상블 모형 : 배깅과 부스팅으로 나뉨