Encoder and Scaler
label encoder
대상이 되는 문자로 된 데이터를 숫자-카테고리컬한 데이터로 변경
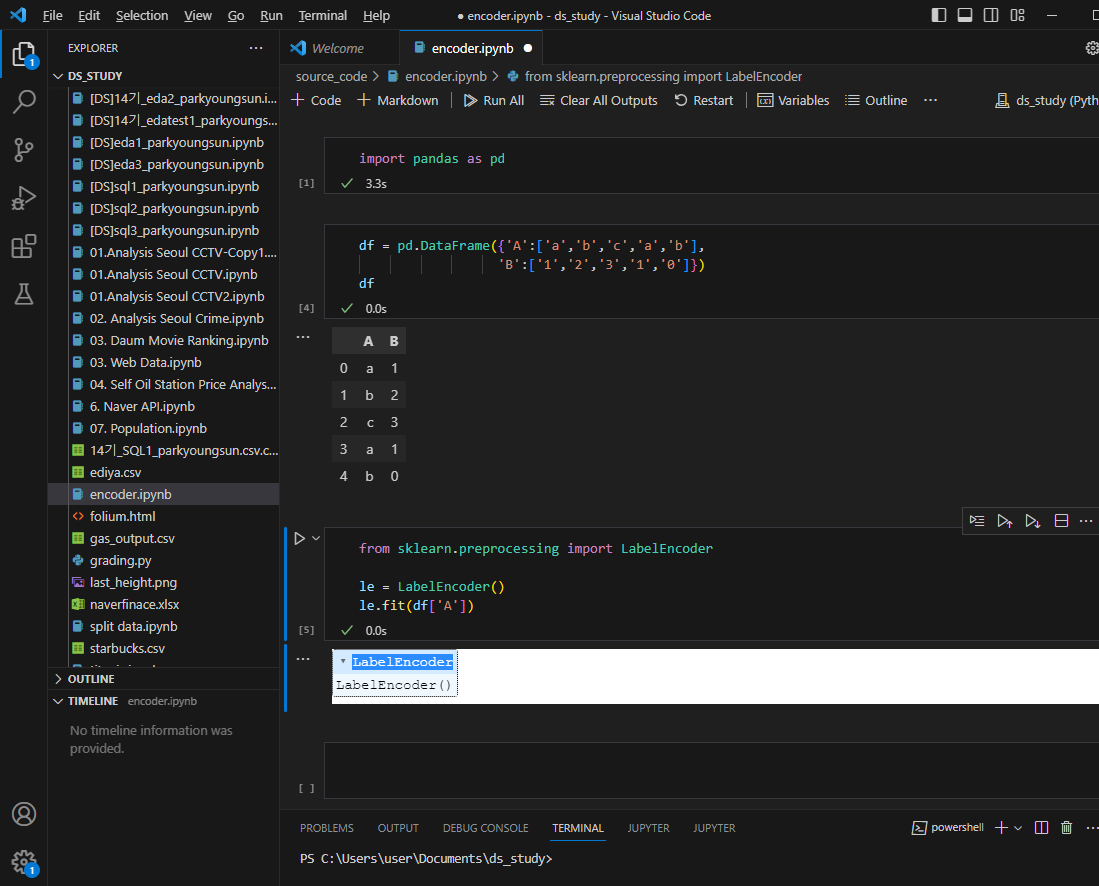
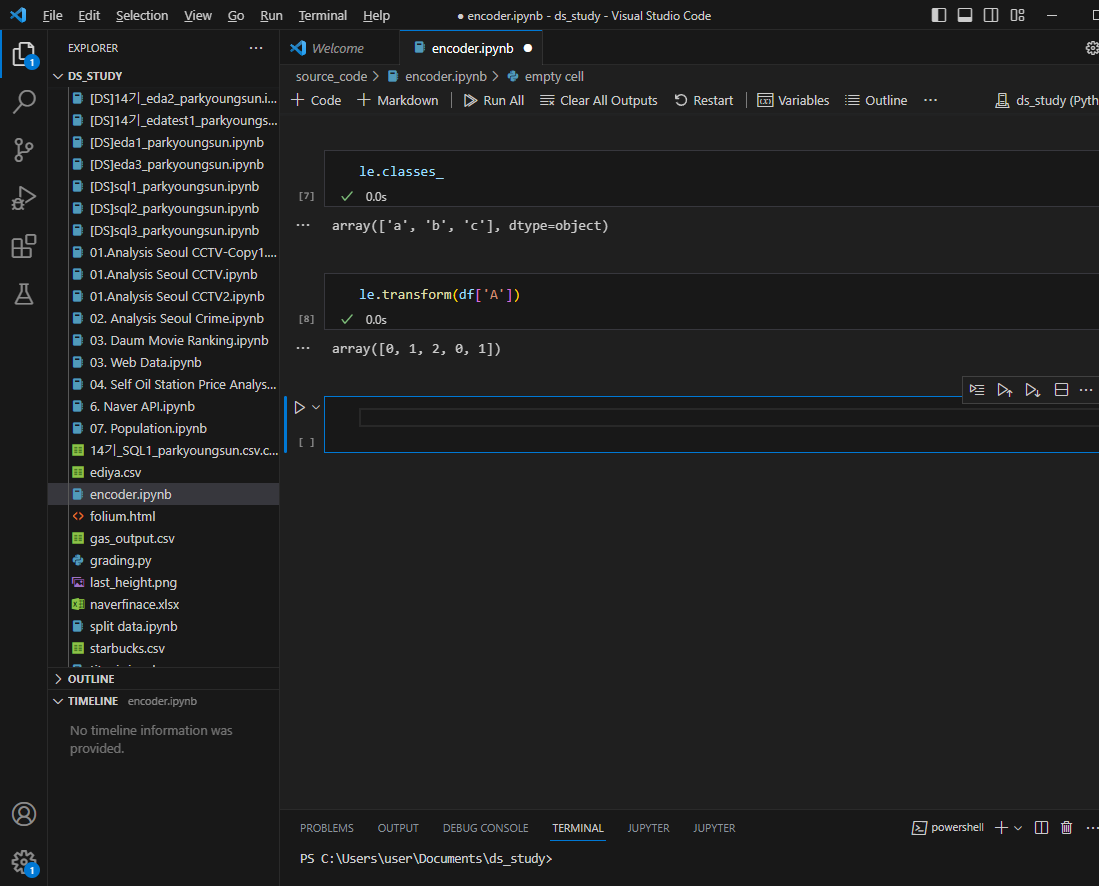
A컬럼이 알파벳에서 숫자로 바뀐것 확인 가능
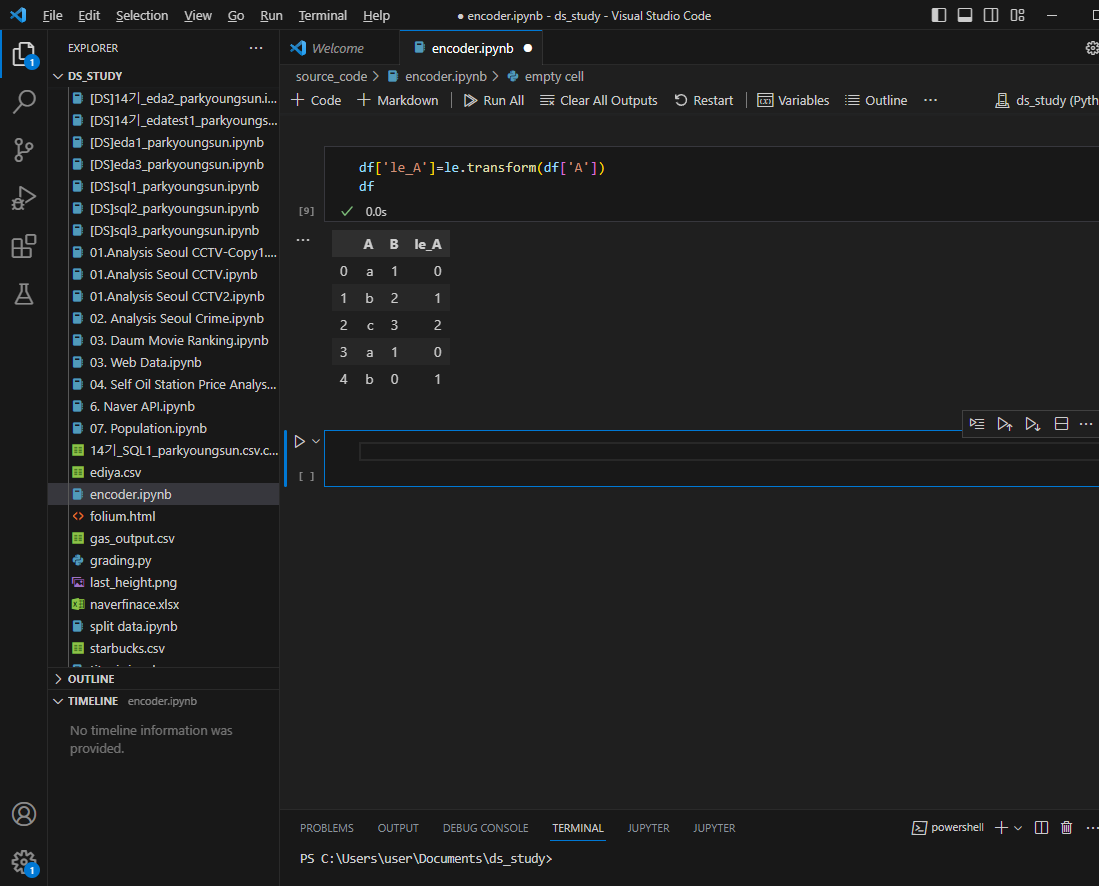
- fit과 transform 한번에 하는 것도 가능
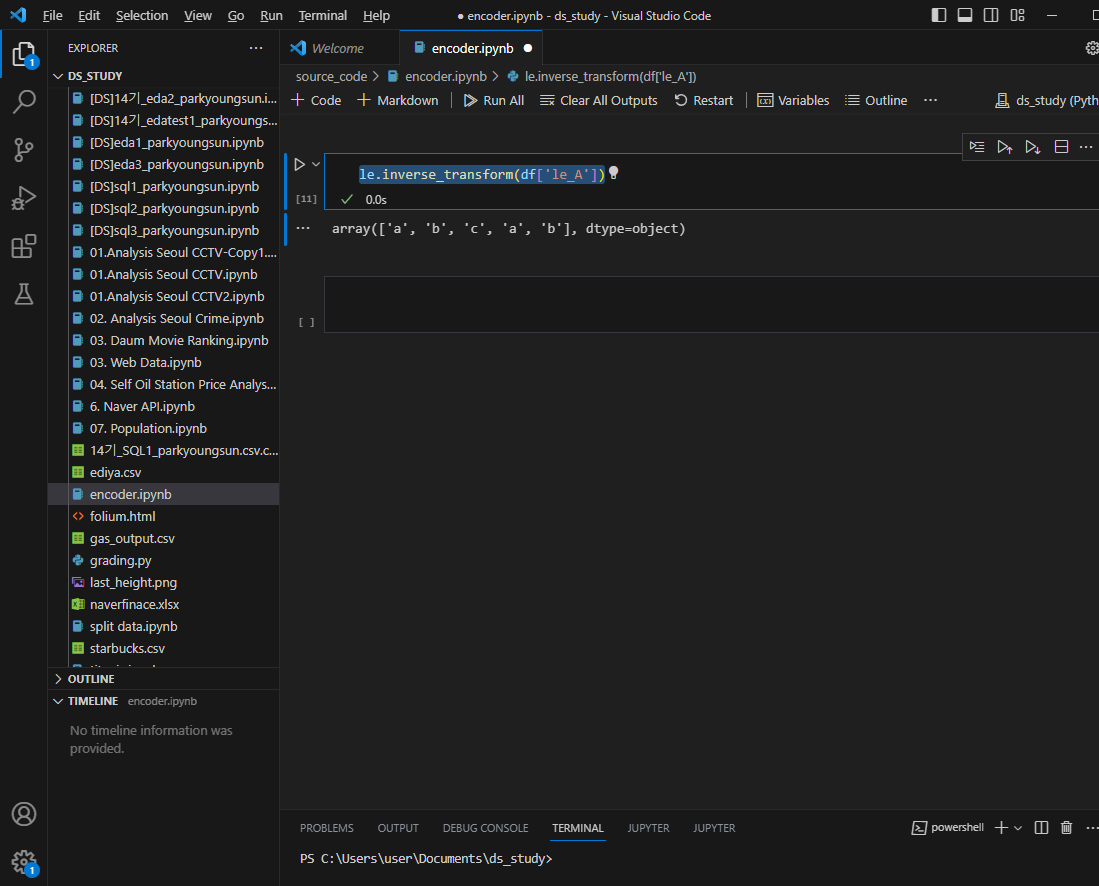
le.fit_transform(df['A'])역으로 다시 알파벳으로 바꾸는 inverse
min-max scaling

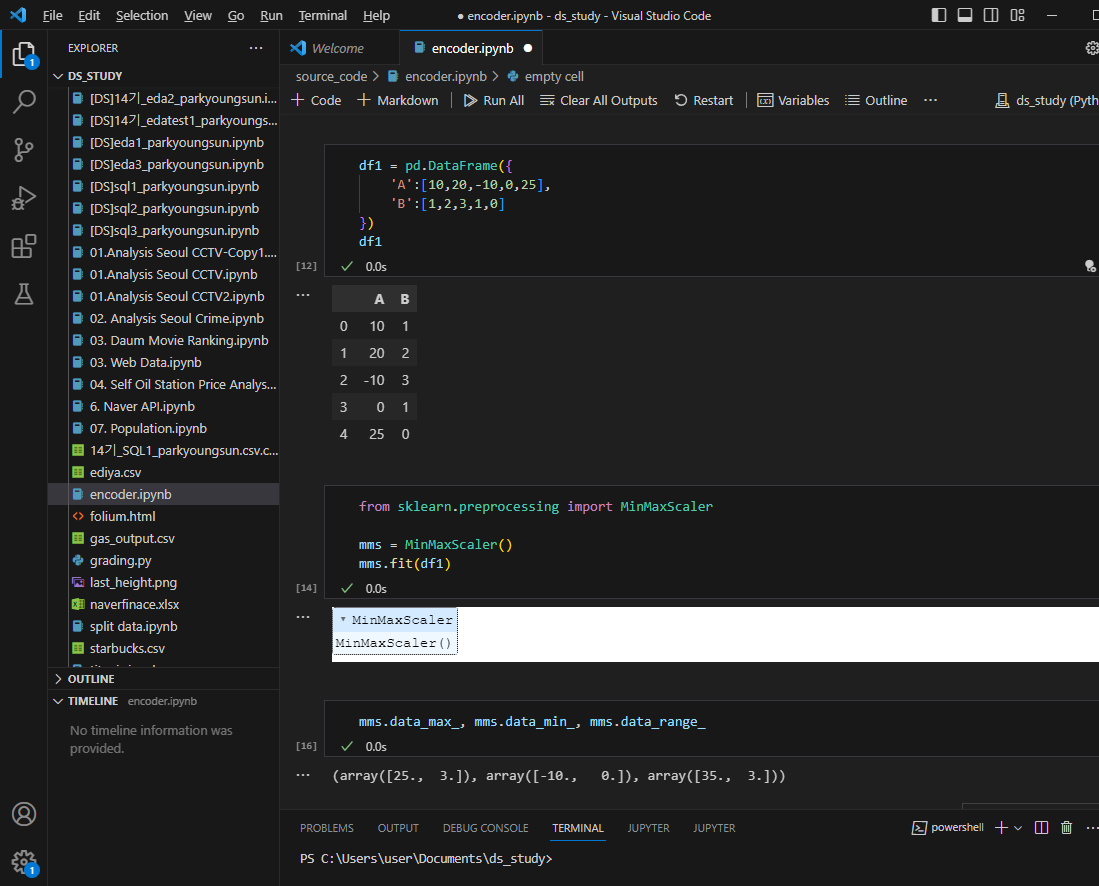
A컬럼의 맥시멈,미니멈,전체길이
B컬럼의 맥시멈,미니멈,전체길이 가 나온다
스케일러 적용
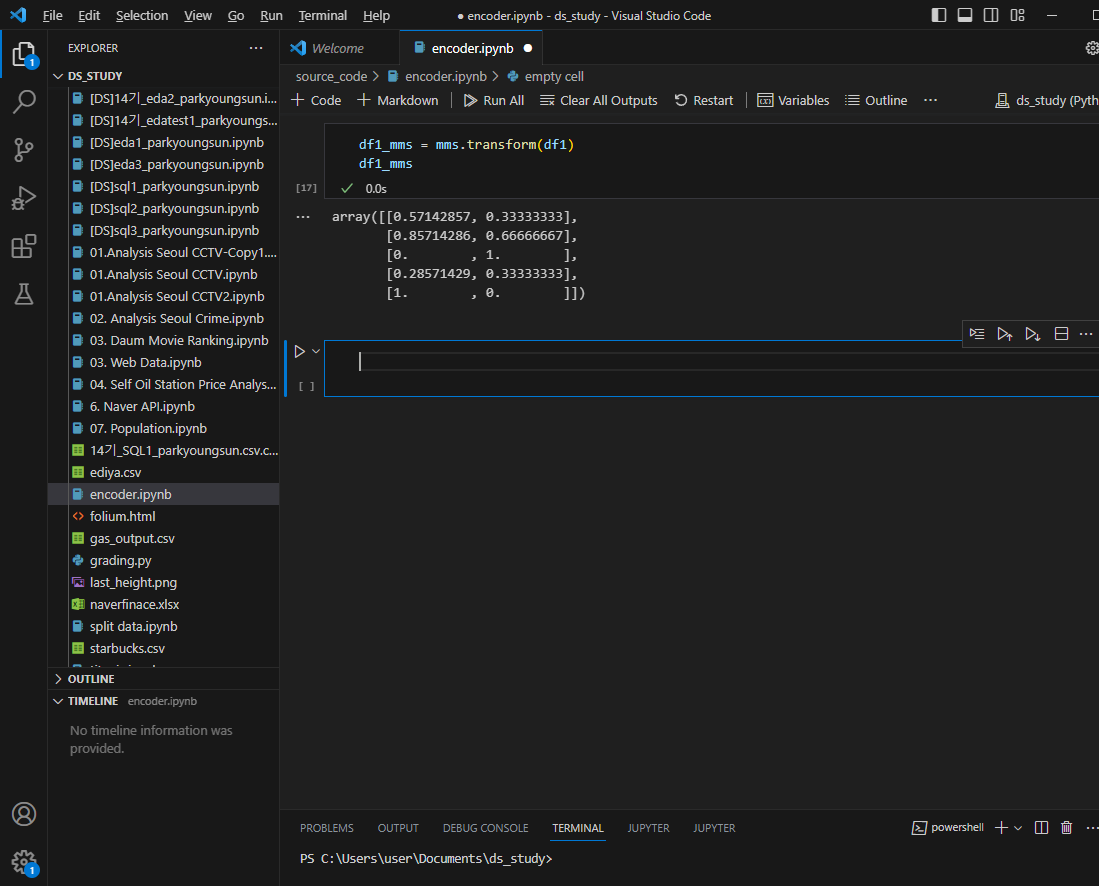
최소값이었던 A컬럼 -10이 0, 최대값인 25가 1
역변환은 inverse 적용
mms.inverse_transform(df1_mms)한번에는 fit.transform
standard scaler
표준화
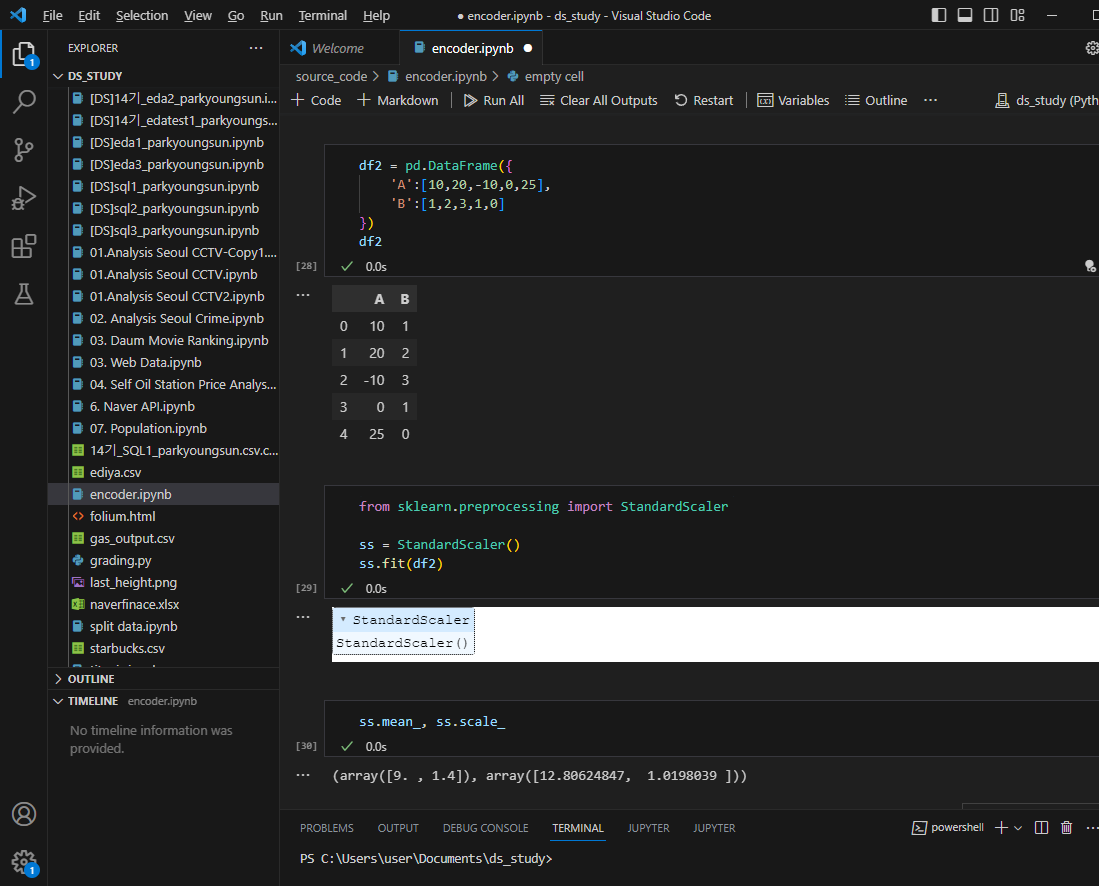
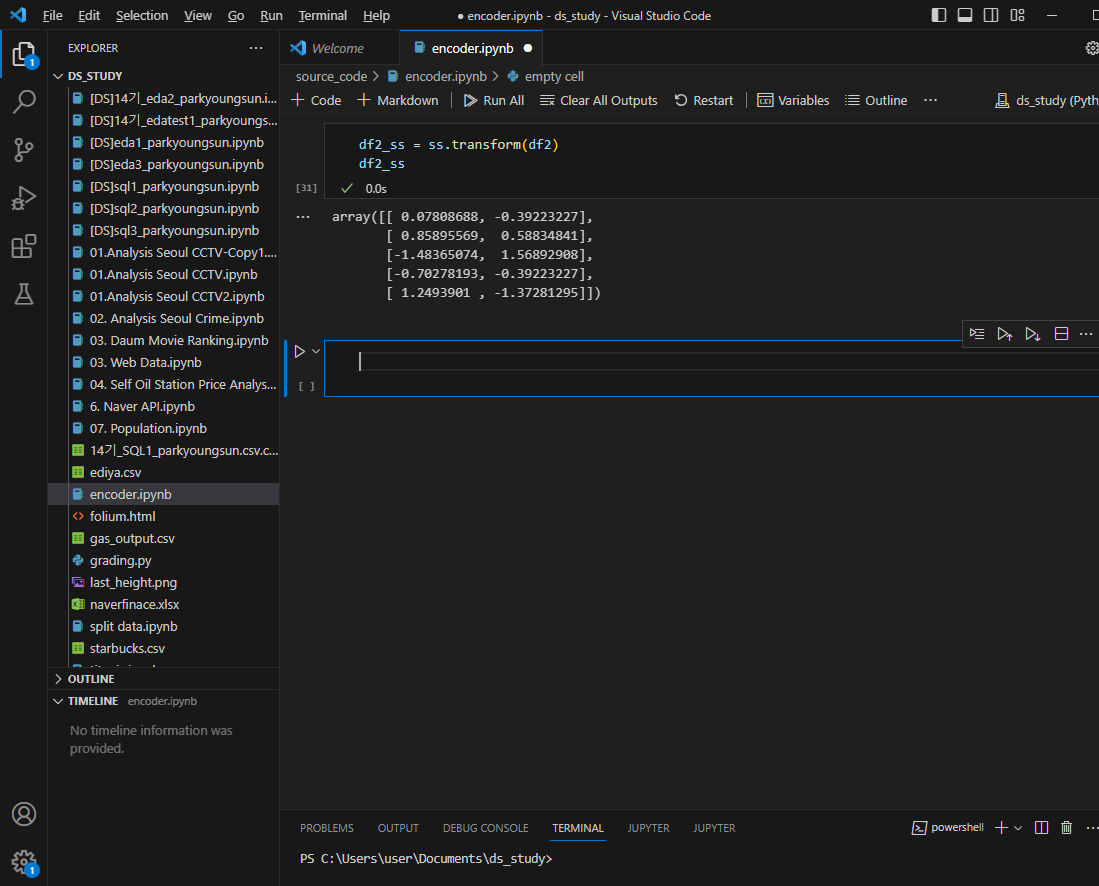
평균은 0이고 표준편차1인 데이터로 변경
robust scaler
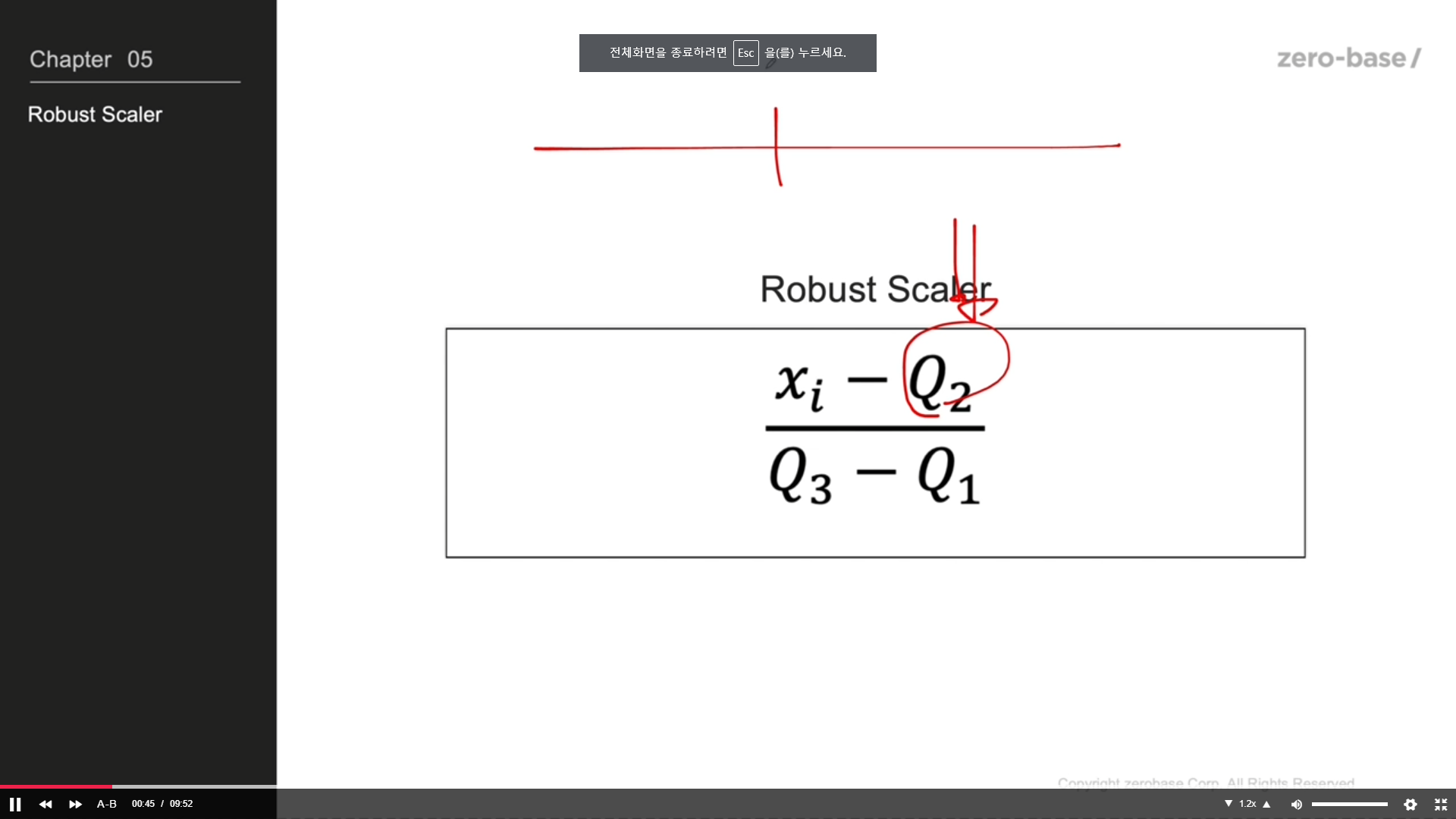
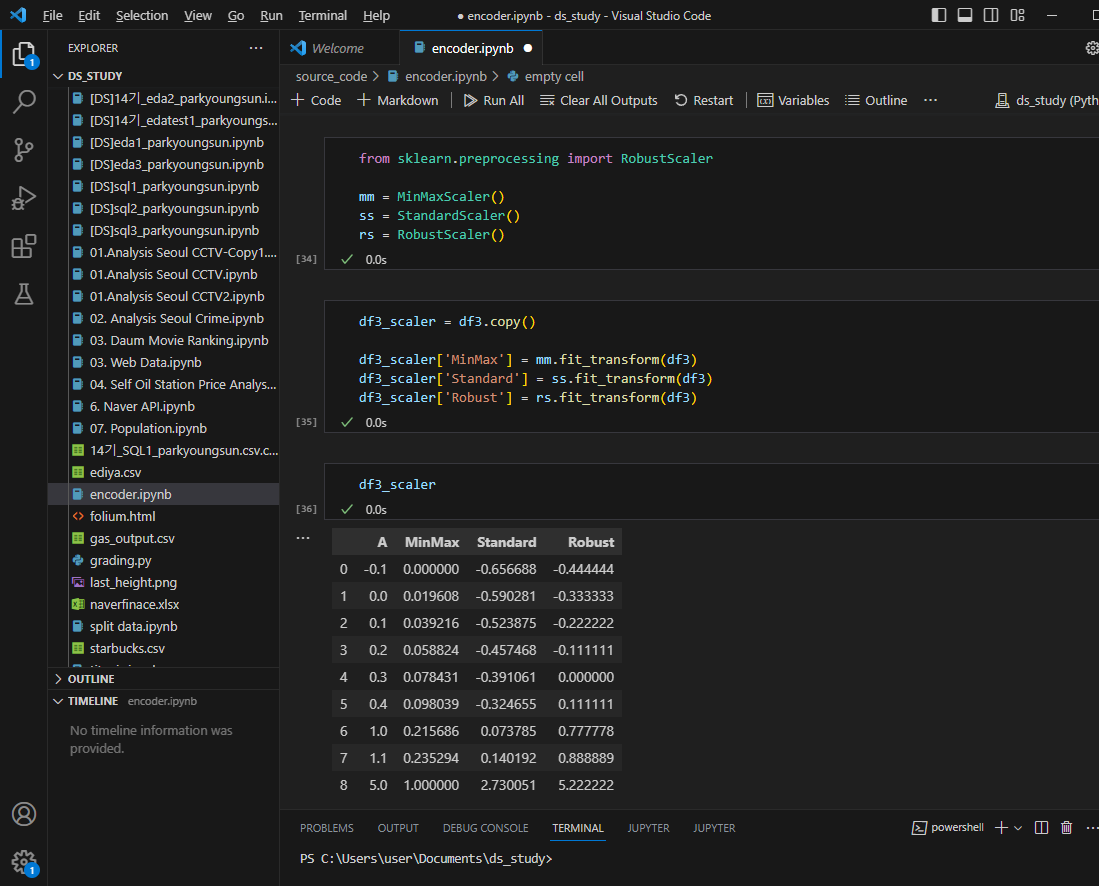
데이터값 입력
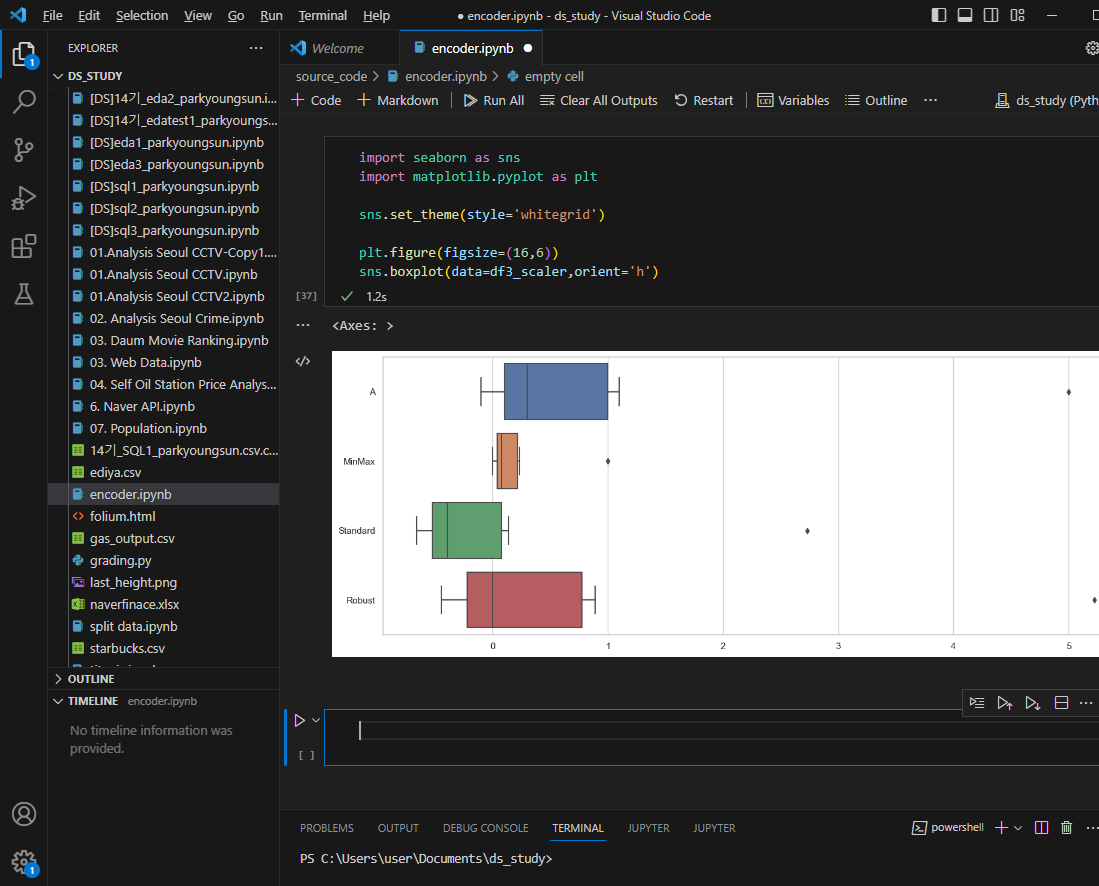
각 스케일링 적용
Decision Tree 이용한 와인데이터 분석
와인데이터
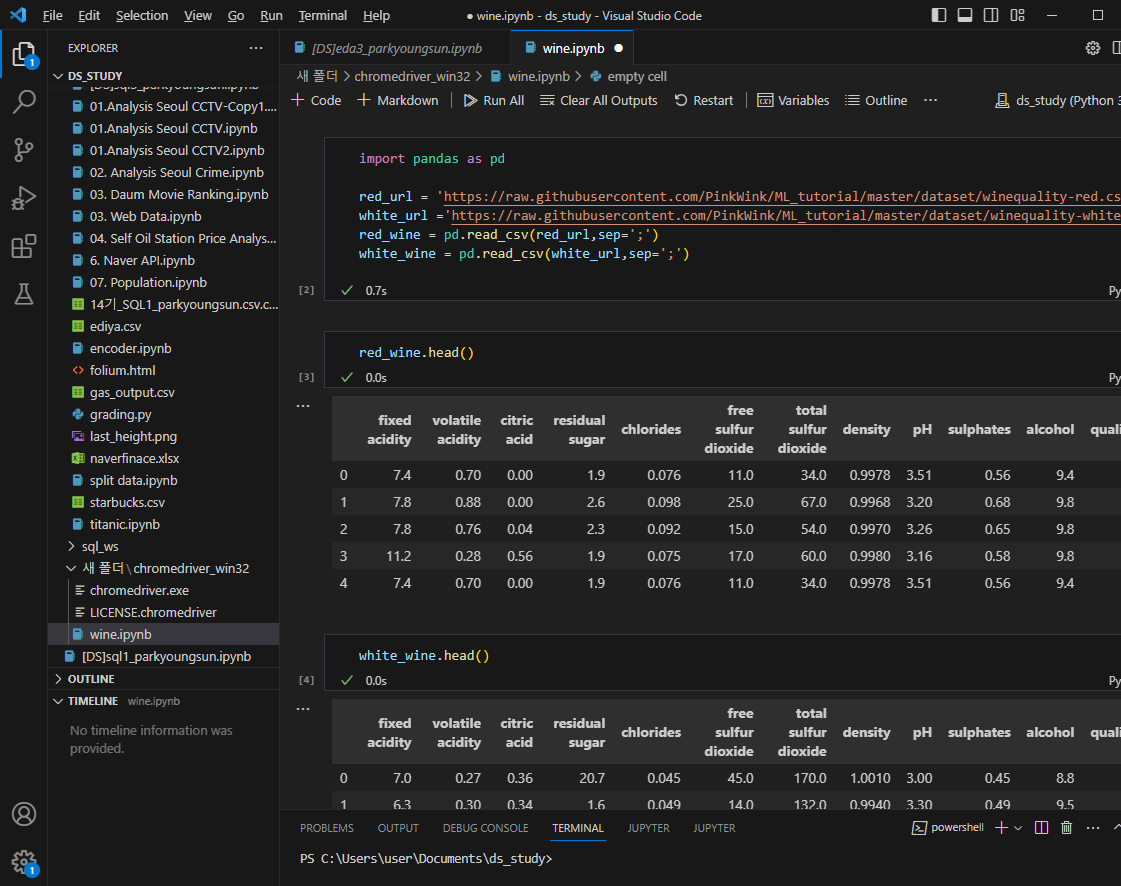
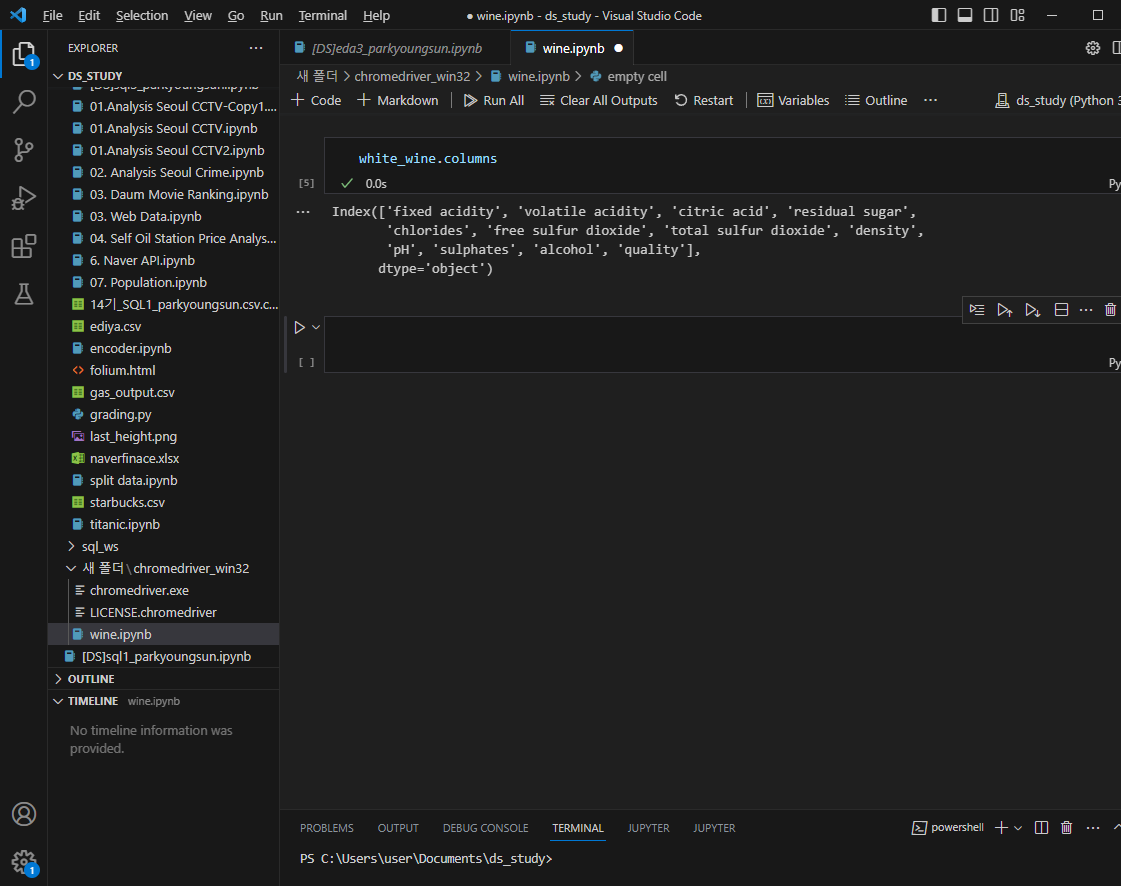
컬럼 종류 보기
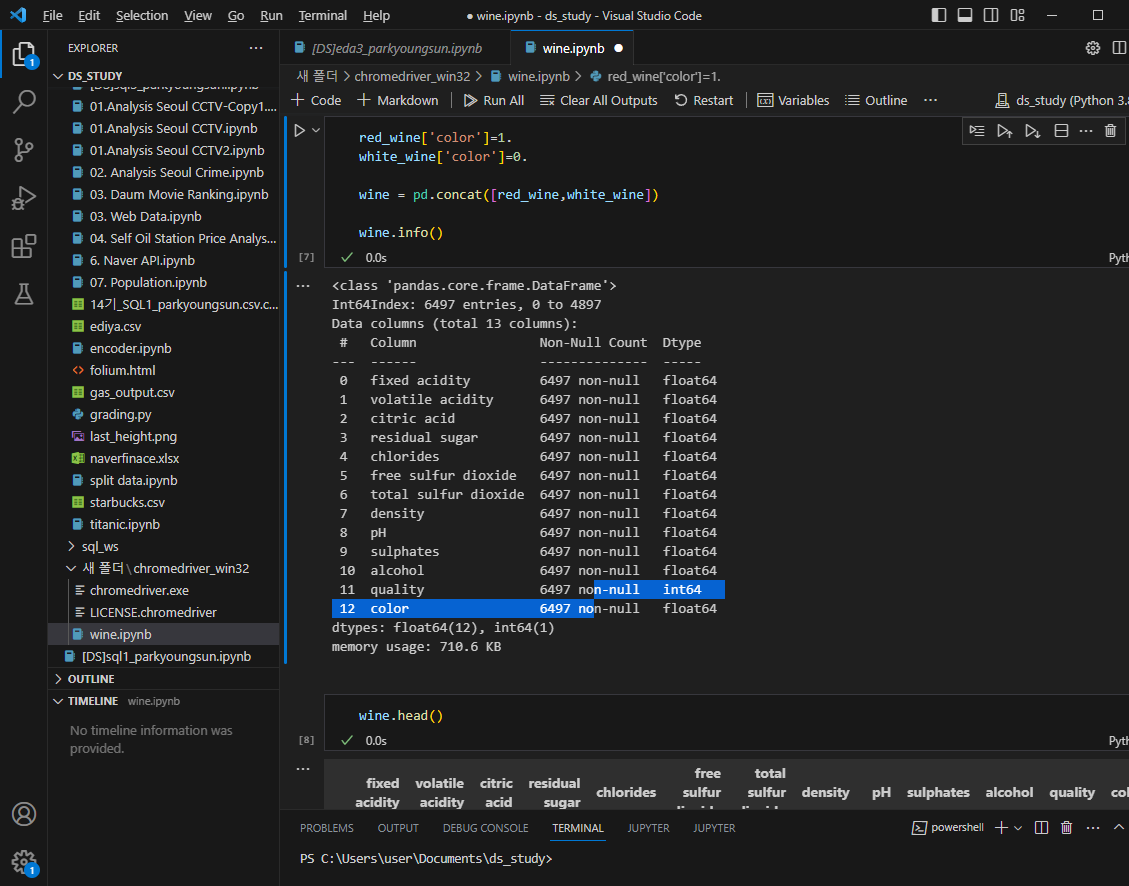
두 데이터를 합치자(두 데이터의 구조는 동일)
와인의 퀄리티 등급 확인
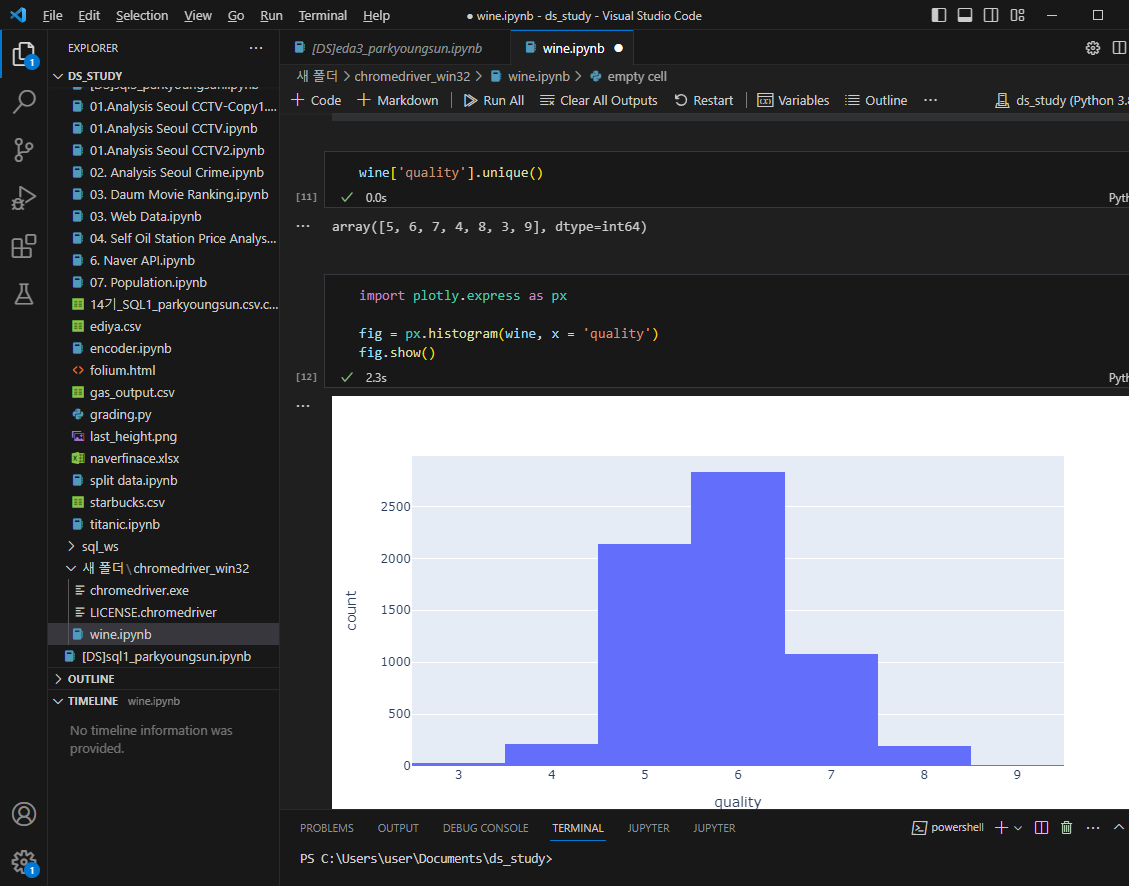
레드,화이트 구분 추가
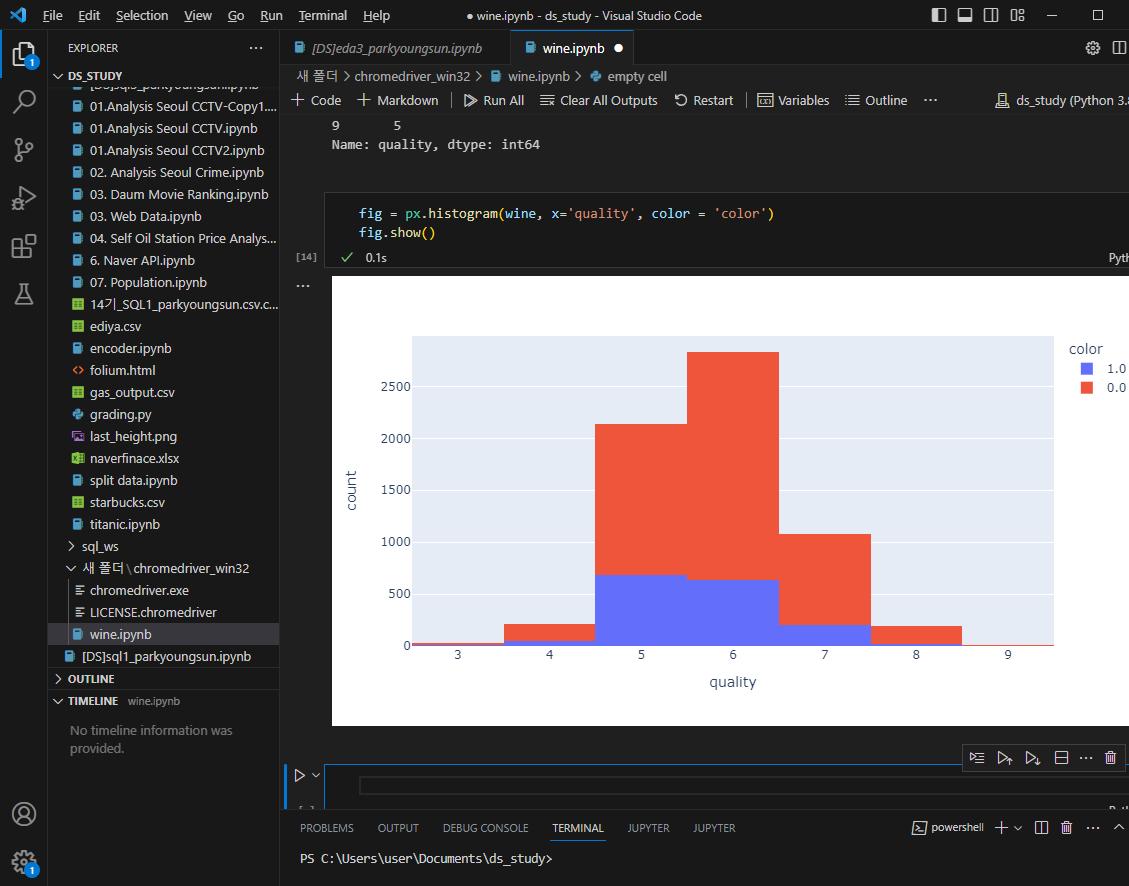
레드와인 화이트와인 분류기
라벨데이터 분리, 데이터를 훈련용과 테스트용으로 나눠주자
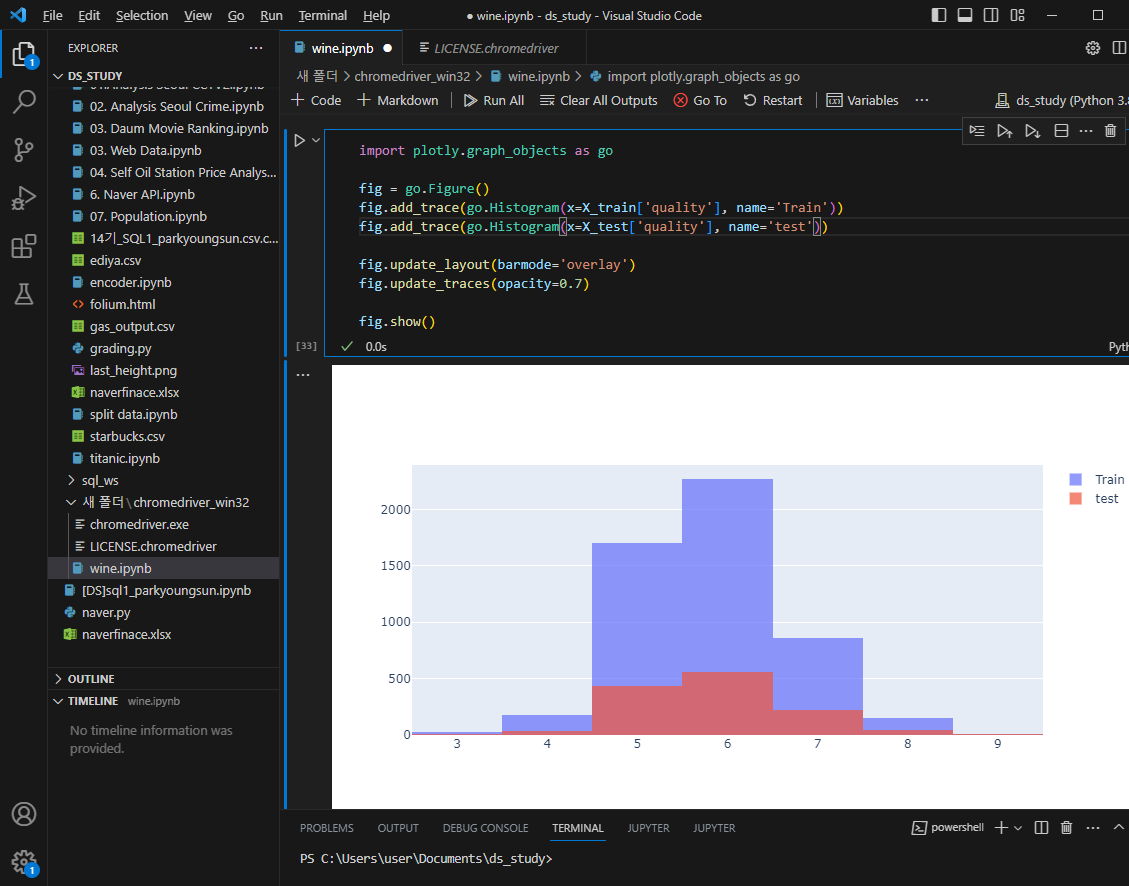
결정나무훈련
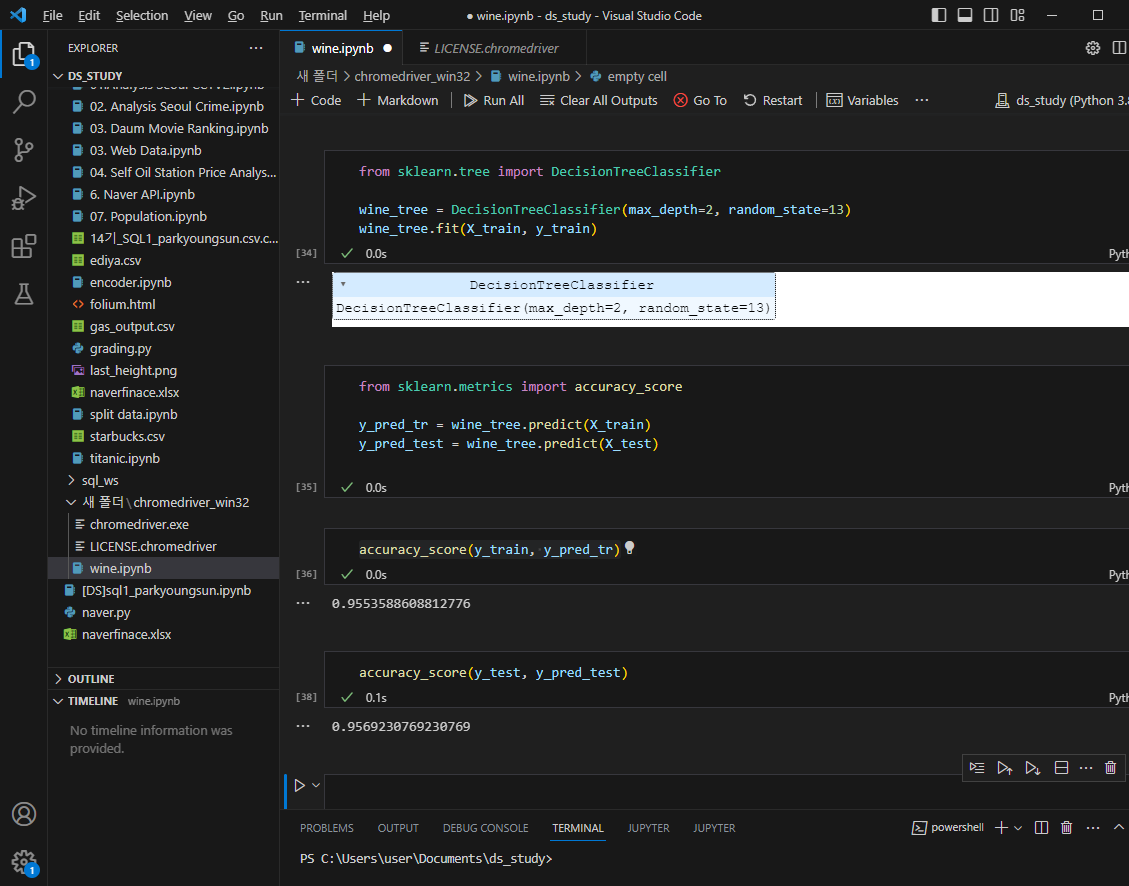
accuracy 측면에서 테스트, 트레인의 성능은 유사하다는거 확인
데이터 전처리
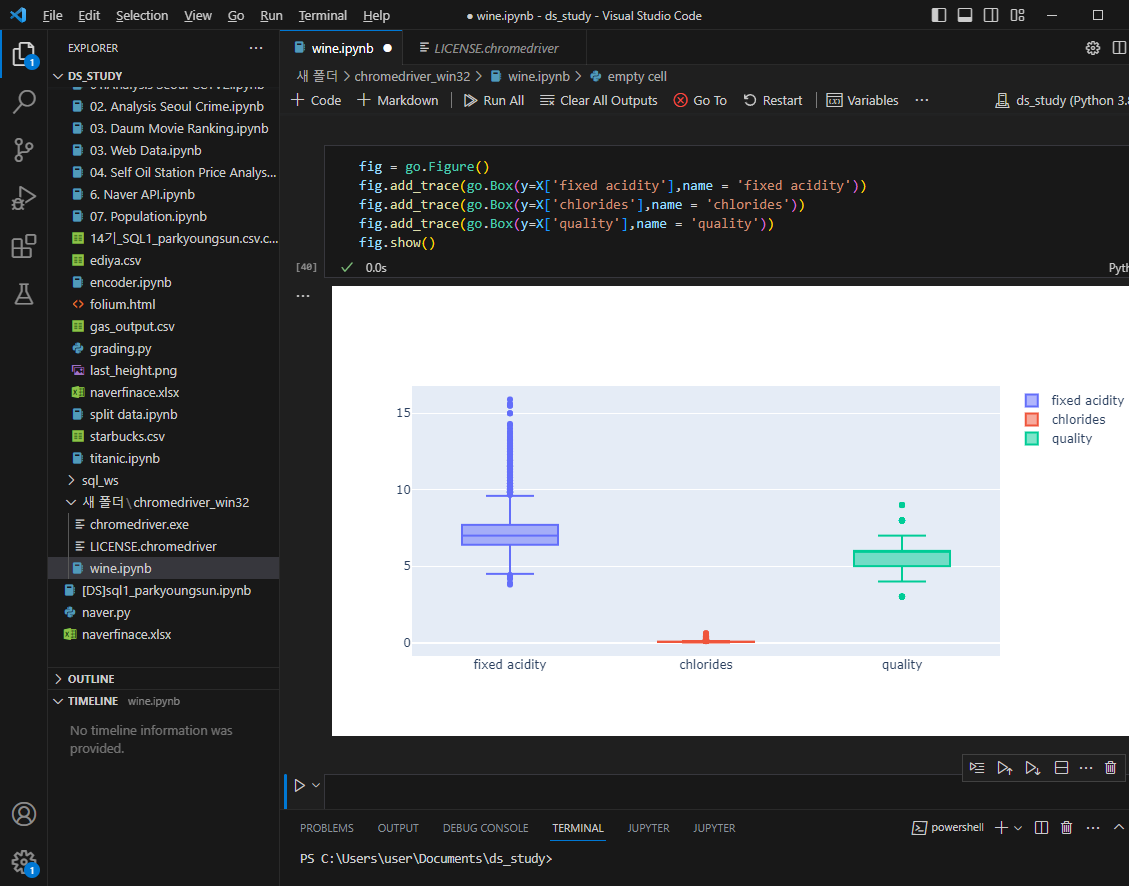

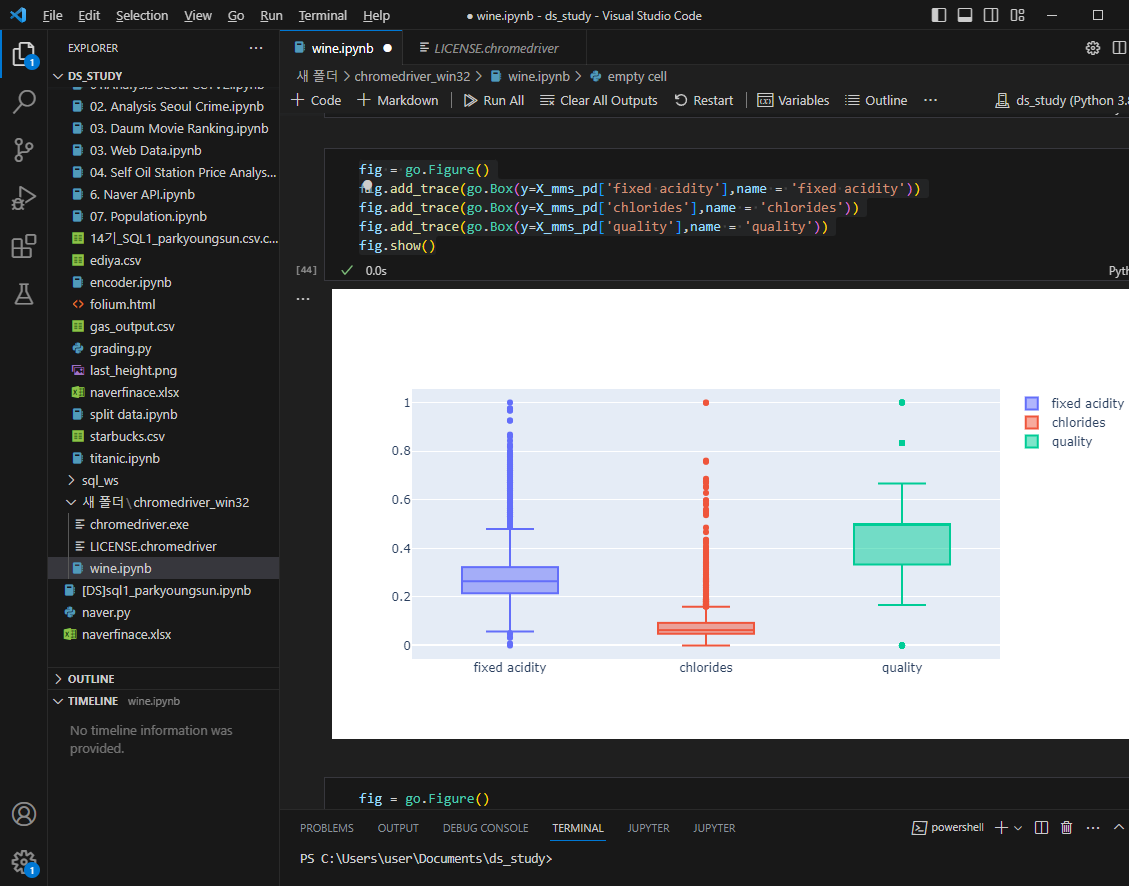
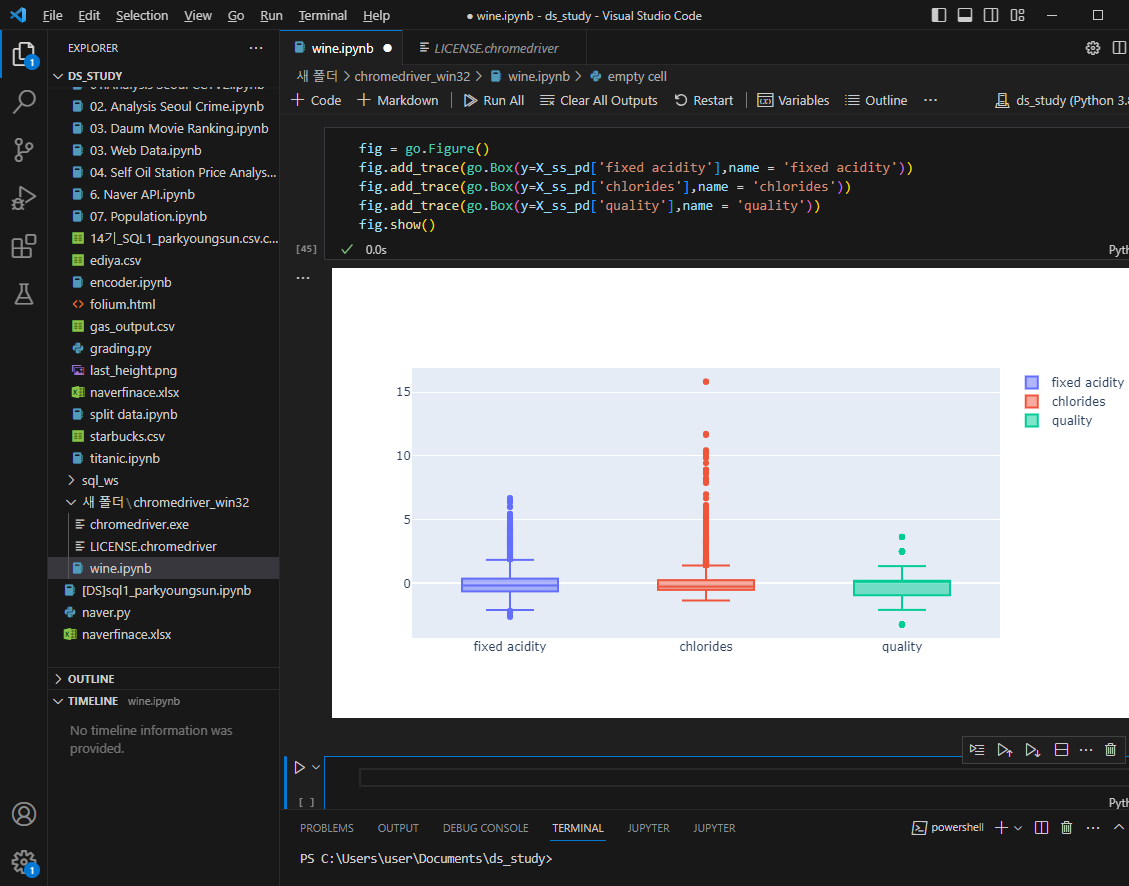
결정나무는 어떻게 화이트, 레드를 구분하나
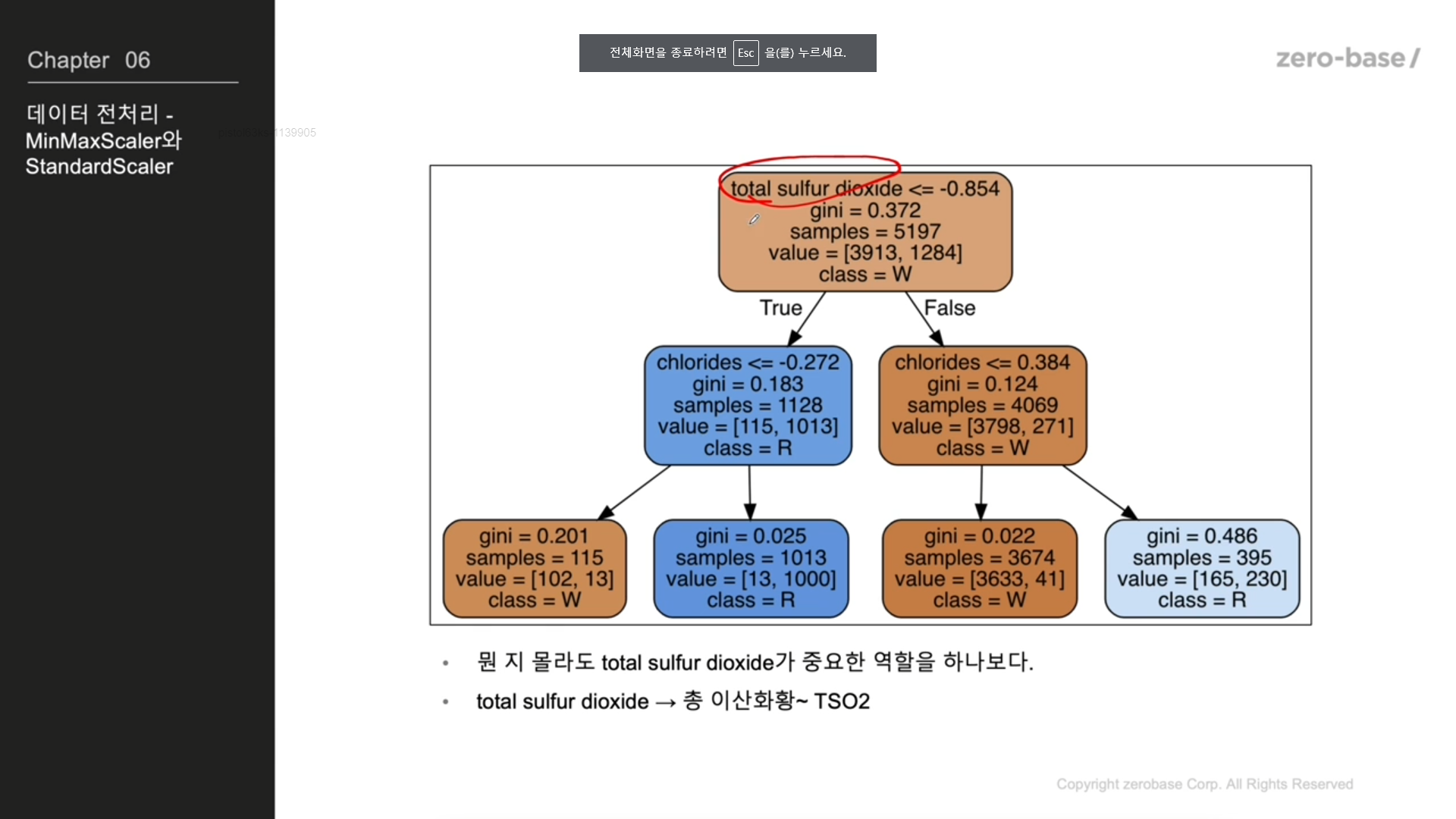
Decision Tree 와인 맛의 이진분류
quality 컬럼 이진화
레드/화이트 와인분류와 동일과정 거치기
X = wine.drop(['taste'], axis=1)
y = wine['taste']
X_train, X_test, y_train, y_test = train_test_split(X_mms_pd, y, test_size=0.2, random_state= 13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)accuracy 계산
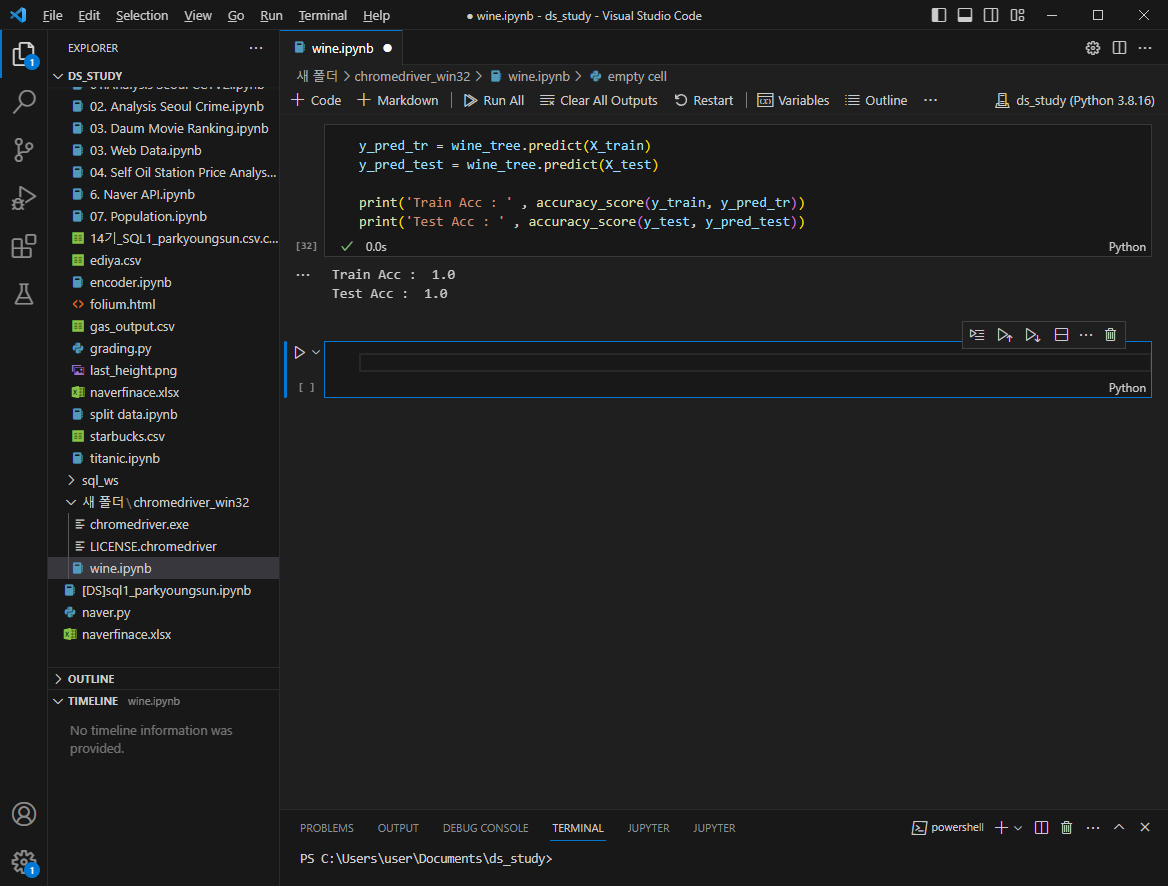
100%?? 이럴수가 있나?
import matplotlib.pyplot as plt
import sklearn.tree as tree
plt.figure(figsize=(12,0))
tree.plot_tree(wine_tree, feature_names=X.columns);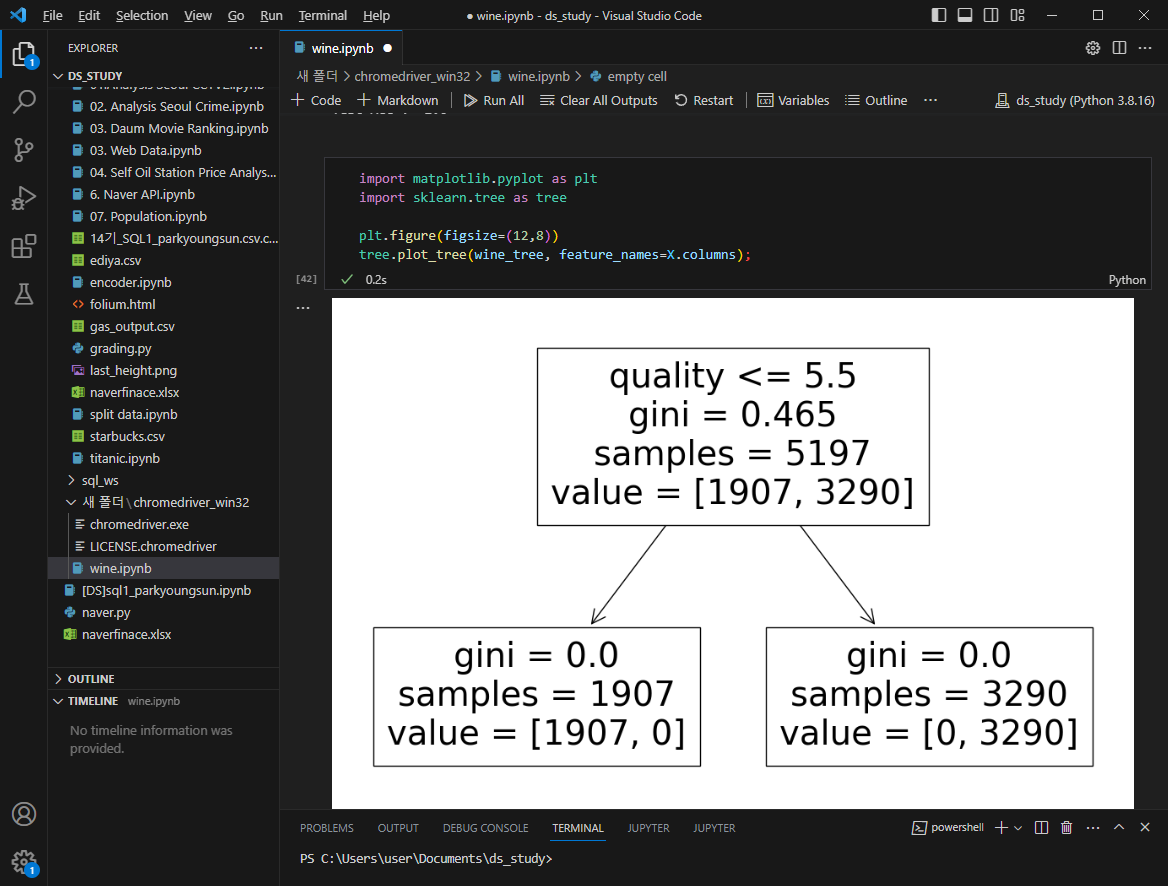
맛을 이진법으로 구분짓기 위해 사용했던 컬럼이 살아있으므로 없에고 해야함
X = wine.drop(['taste','quality'], axis=1)
y = wine['taste']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state= 13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)accuracy 재확인
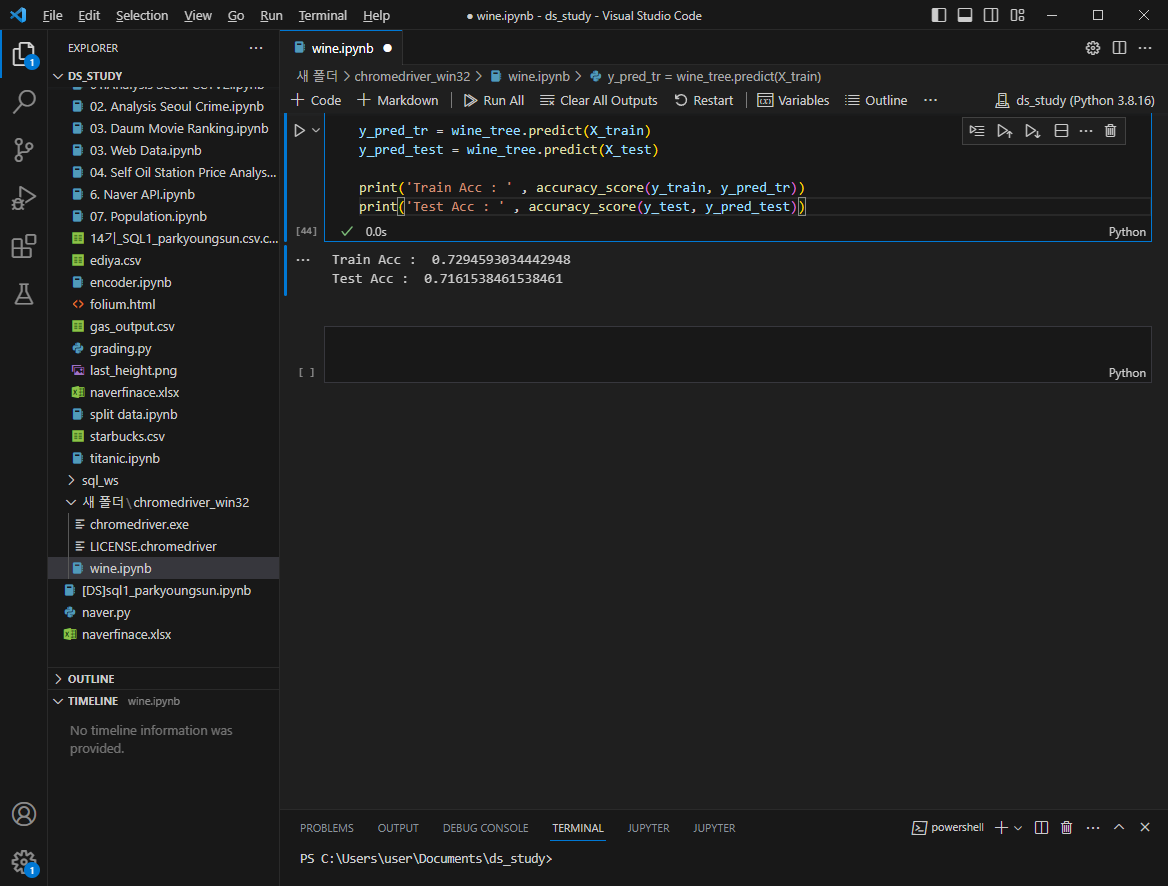
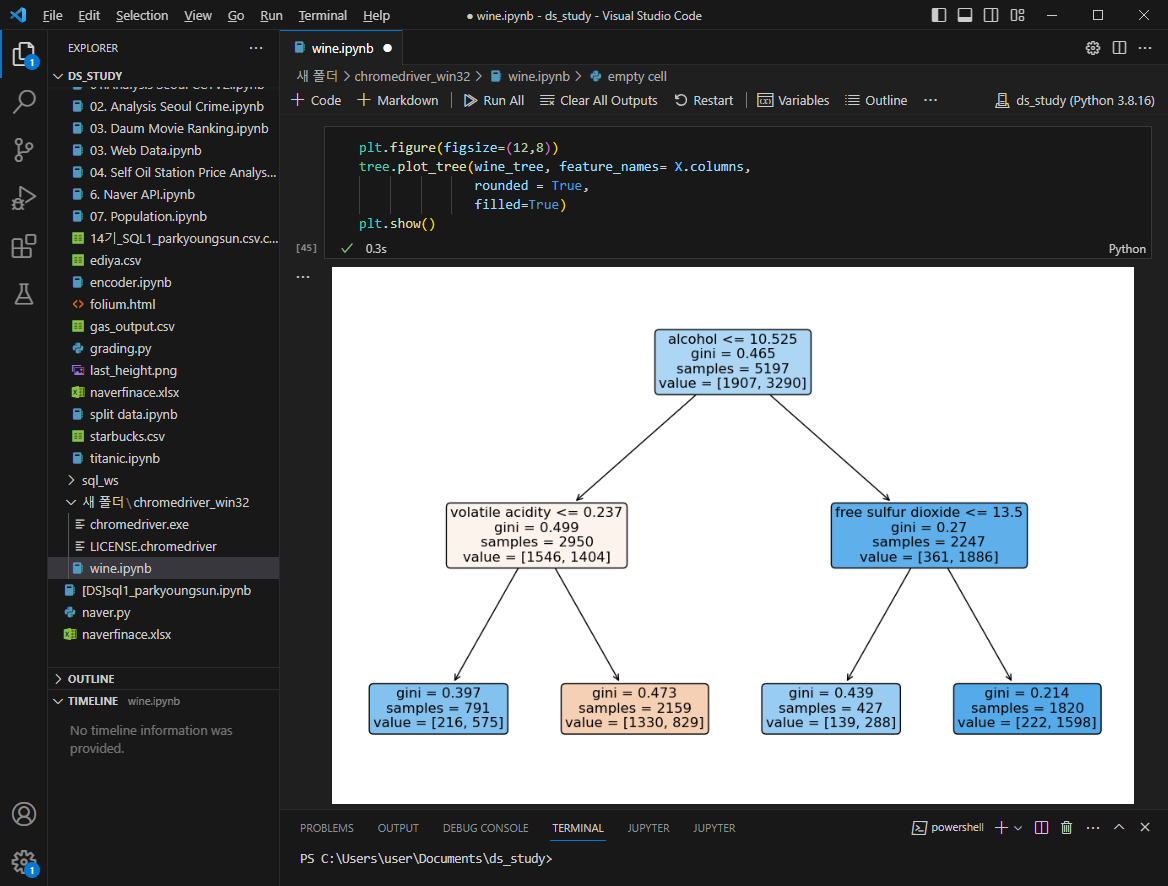
어떤 와인이 맛있나?
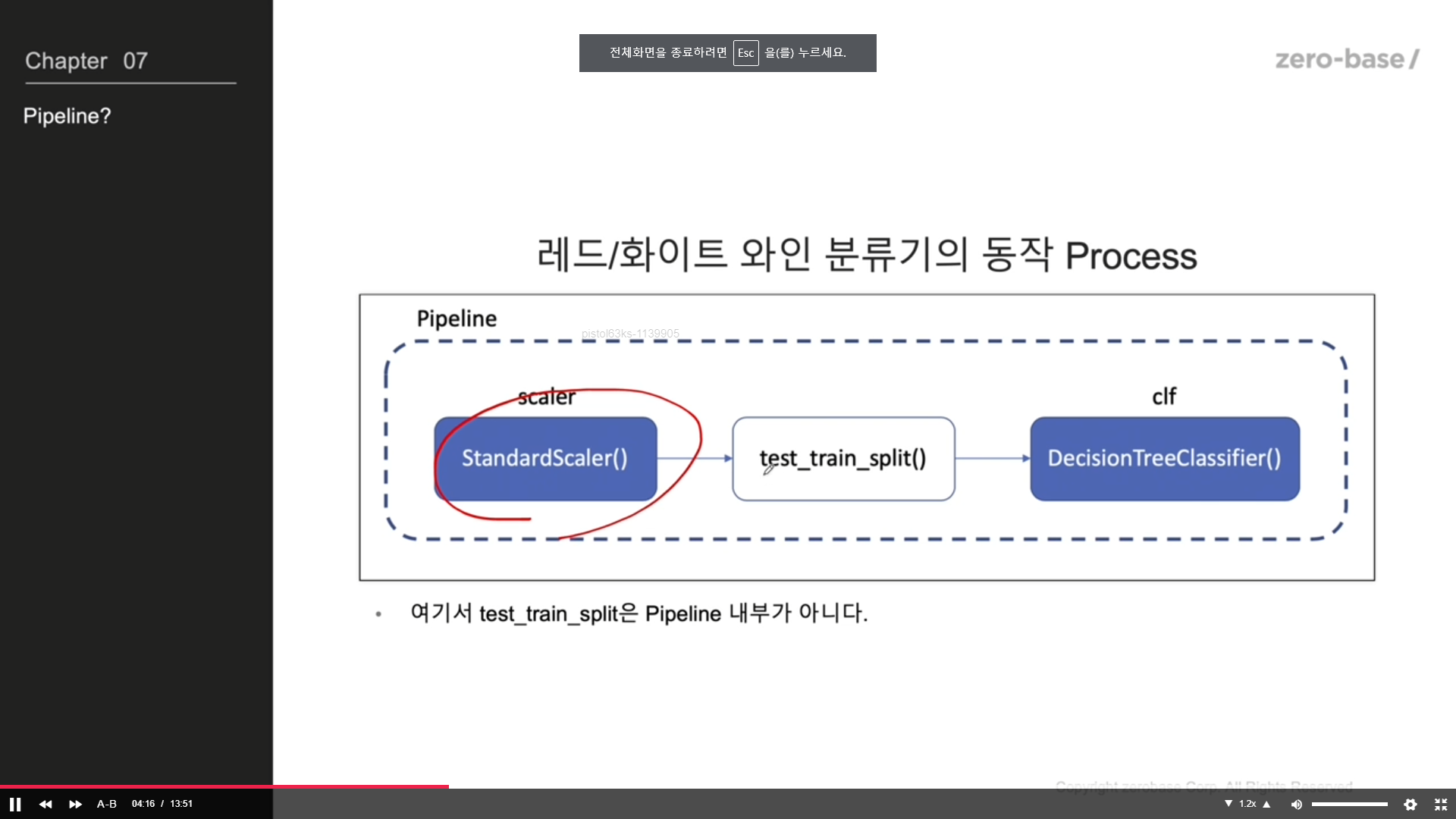
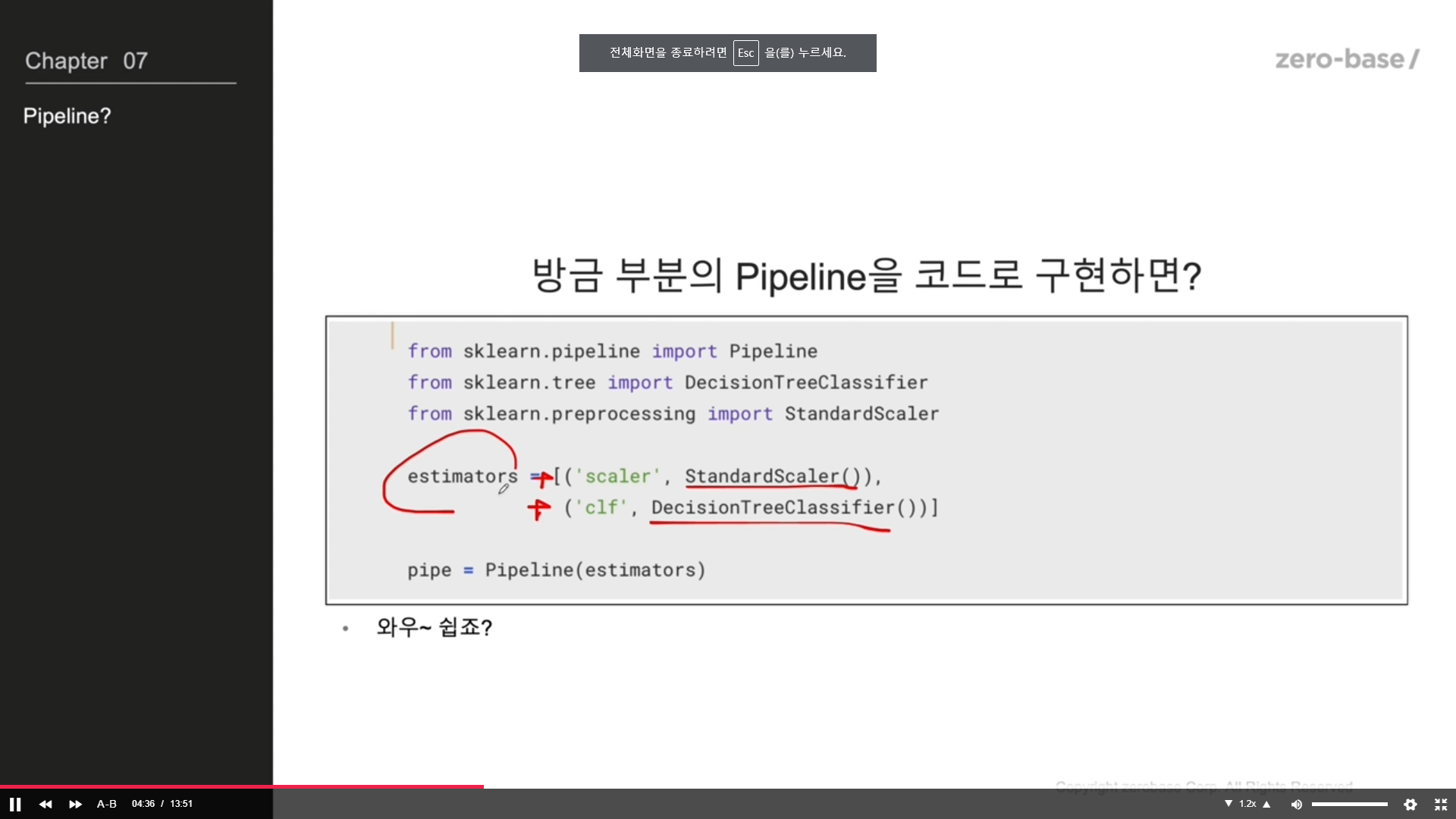
pipeline

하이퍼파라미터 튜닝
교차검증

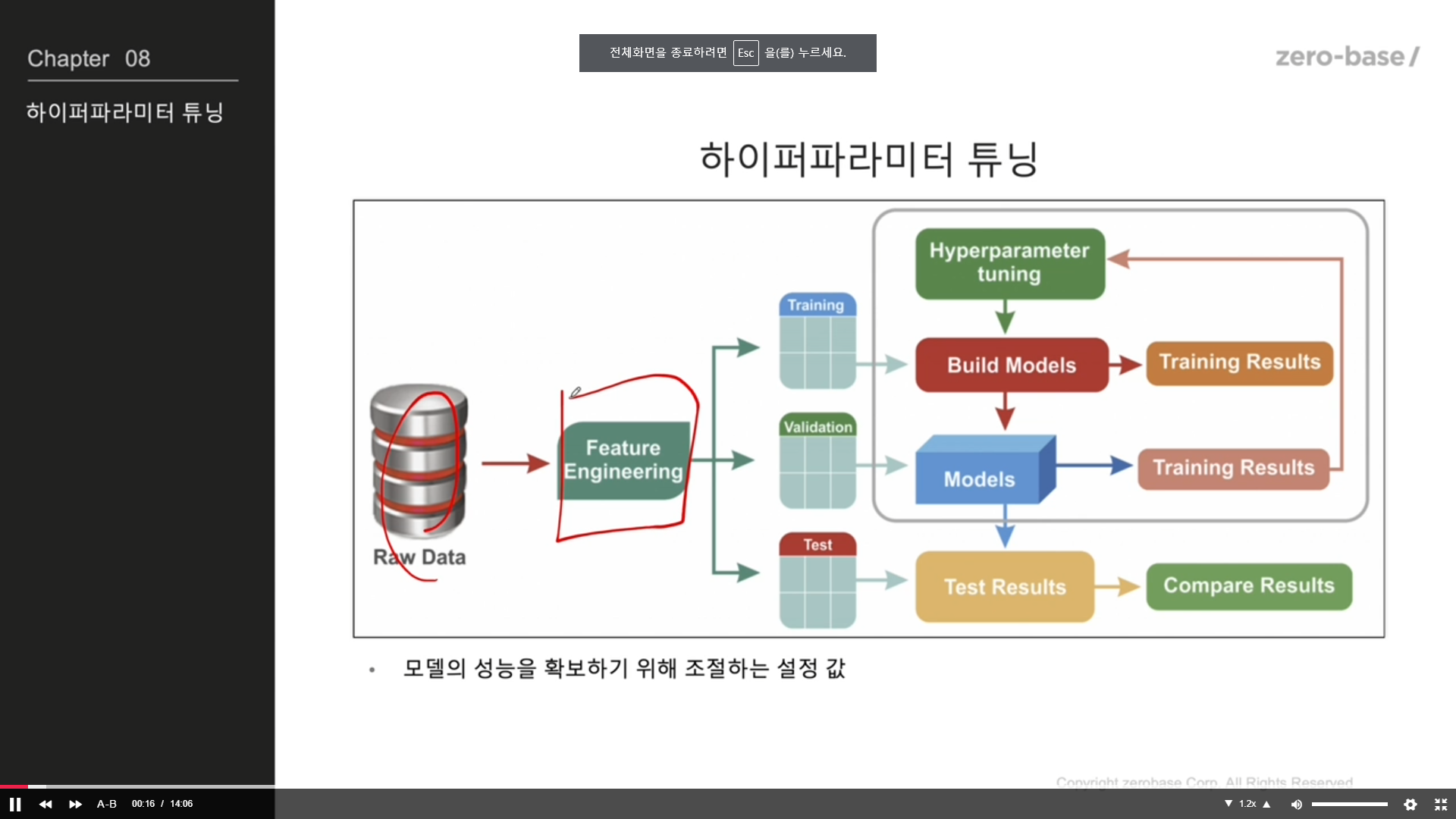
하이퍼파라미터 튜닝

데이터분석 공부 시작했습니다