1.Kafka
1.1 Kafka가 왜 필요할까?
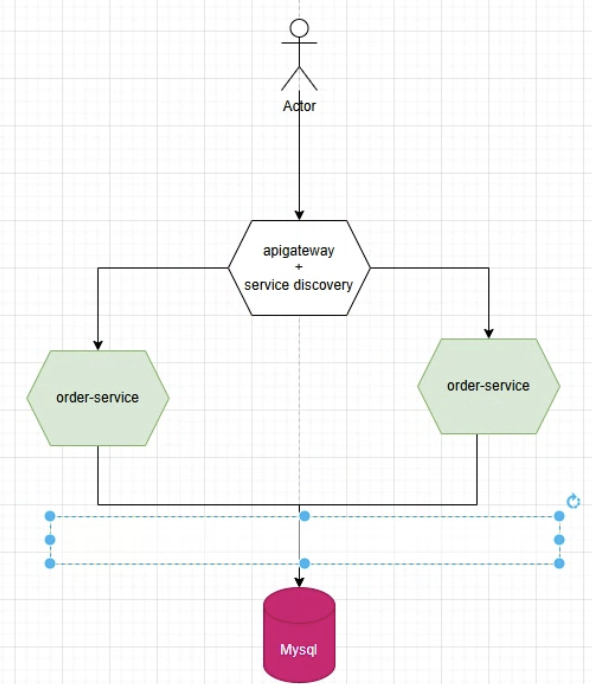
먼저 실습 전에 개념부터 이해해보자.
Kafka가 필요한 이유는 Order-Service가 여러 개일 때 위의 사진 중 파란색 박스 부분에서 병목현상이 생길 수도 있어서 여러개의 서버를 돌릴 때는 메세지 큐인 Kafka를 사용해서 중재 역할을 해줘야한다.
1.2 Kafka 전체 흐름
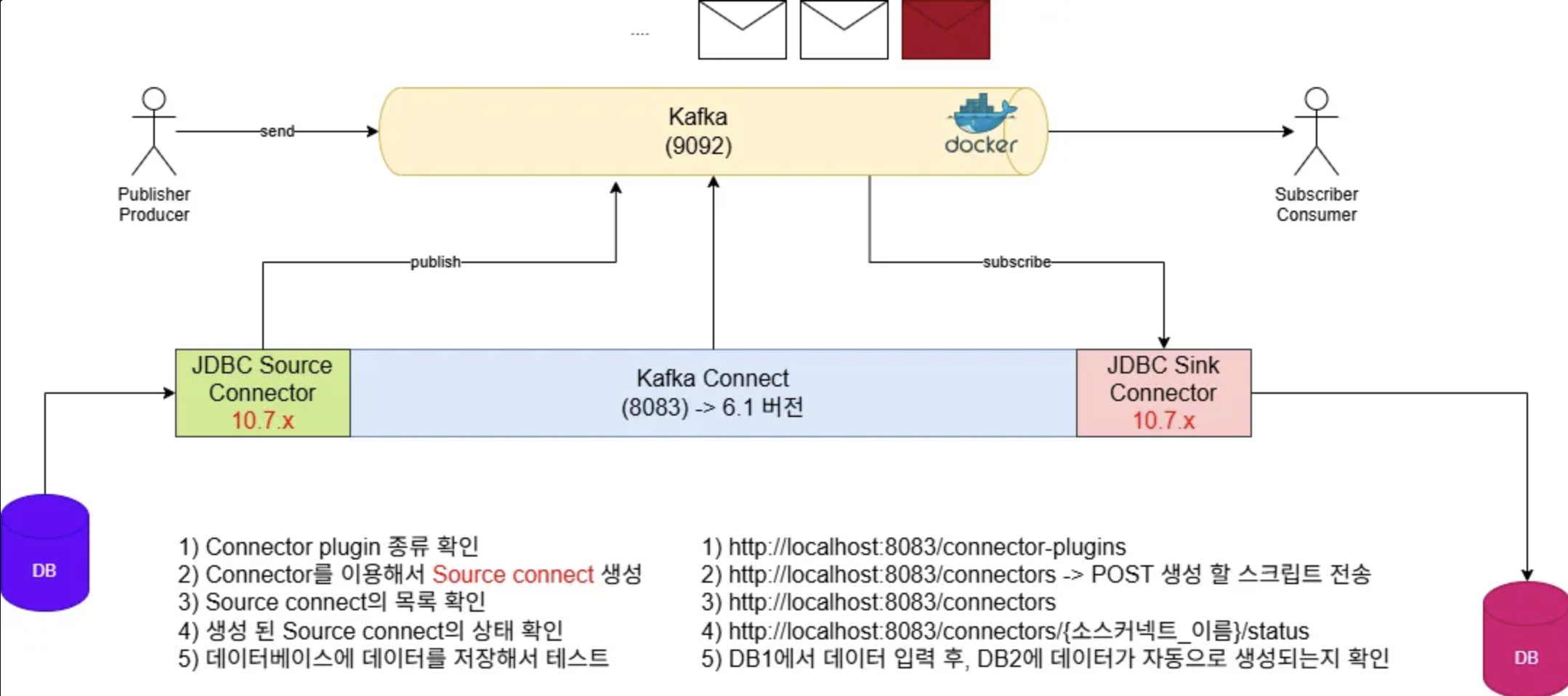
결론부터 보는 것이 이해가 쉬우므로 Kafka의 전체적인 데이터 흐름을 살펴보자.
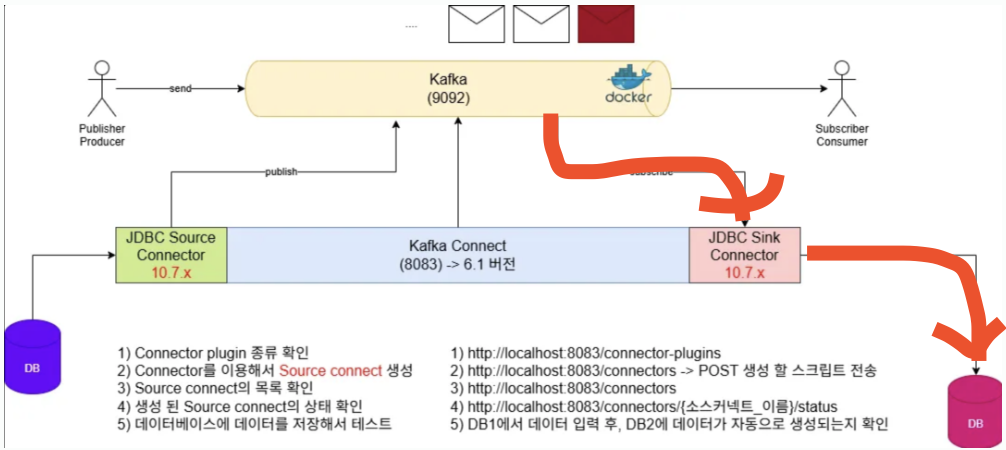
그림의 왼쪽부터 Order-Service에 데이터 입력 -> MYDB에 저장 -> JDBC Source Connector-> Kafka Topic -> JDBC Sink Connector -> MyDB2에 저장
위와 같은 과정을 통해서 Order-Service(보라색 DB)의 DB가 여러개 있더라도 Kafka를 통해서 데이터의 병목 현상을 막아주어 분홍색 DB의 데이터 병목 현상을 방지할 수 있다.
Kafka와 데이터베이스의 연결을 위해서는 Connector가 필요하다.
JDBC Connector란?
- JDBC Source Connector : Polling 방식으로 MYDB1의 데이터 변경을 감지하고 Kafka에 변경 사항을 반영 (보라색 DB -> Kafka)
- JDBC Sink Connector : Polling 방식으로 자동으로 Kafka의 데이터 변경을 감지하고 DB2에 변경 사항을 반영 (Kafka -> 분홍색 DB)
2. Kafka 적용
2.1 Kafka 적용 순서
실습 전에 순서를 정리해보자.
[Kafka 실행]
[Kafka Topic 생성]
[Kafka Connect 생성]
[DB 연동 확인]
이렇게 네가지 순서로 진행할 것이다.
2.2 Kafka 실행

Docker를 통해서 Kafka를 실행했다.
docker run -d -p 9092:9092 --name broker apache/kafka:latest

2.3 Kafka Topic 생성
Kafka Topic이란 Kafka의 데이터 저장 공간이라고 생각하면 편하다.
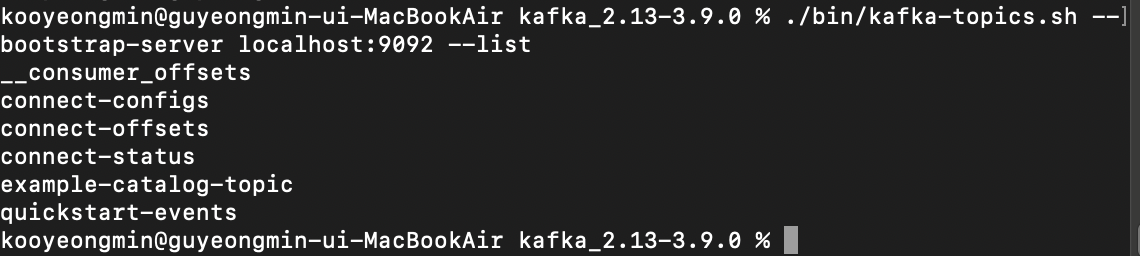
목록을 확인한 결과이다. quickstart-events Topic이 잘 생성되었다.
Kafka Topic 생성 명령어
./bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092 \ --partitions 1
Kafka Topic 목록 확인 명령어
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
Connector를 연동하기 전에 Topic에 들어온 값을 보기위해 Provider, Consumer를 통해서 Kafka Topic Test를 진행해보자.
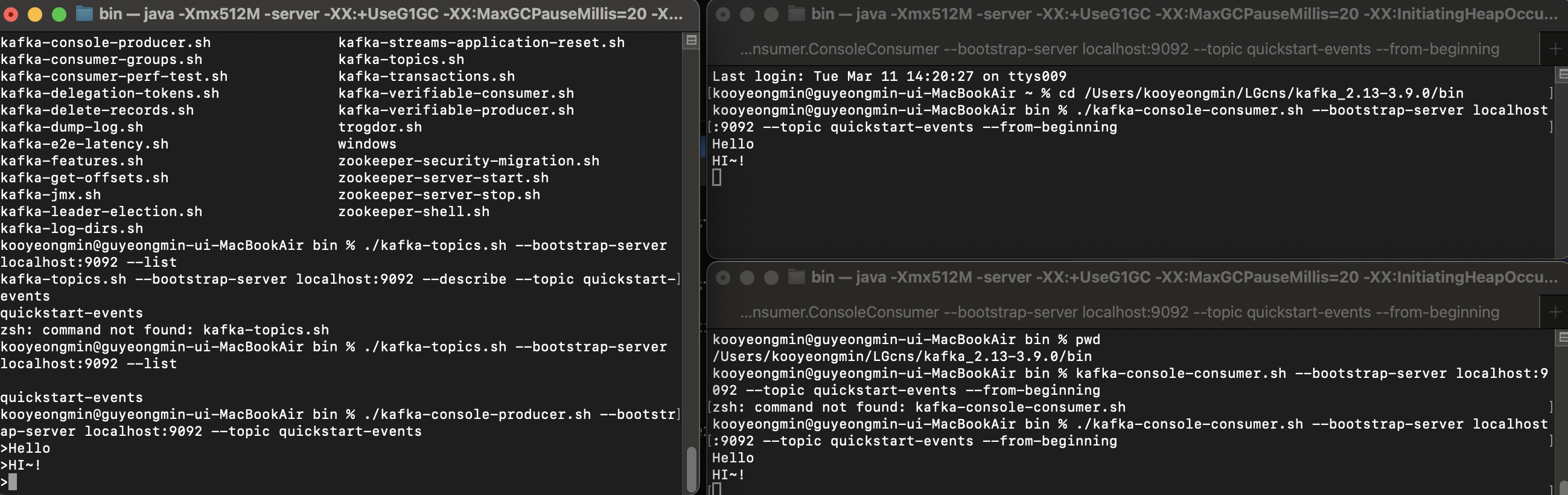
왼쪽 창의 한개의 Provider이고, 오른쪽 창은 두개의 Consumer이며 Provider를 통해서 Hello, HI~!라는 메세지가 잘 전송되는 것을 볼 수 있다.
Provider, Consumer를 통해서 현재 Topic의 들어온 값을 볼 수 있다.
Provider 실행 명령어
./bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic quickstart-events
Consumer 실행 명령어
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic quickstart-events \ --from-beginning
2.4 Kafka Connect 생성
DB와 Kafka를 연동해주기 위해서 Kafka Connect를 생성해준다.
Kafka Connect 생성 명령어(Confluent6.1 경로에서)
./bin/connect-distributed ./etc/kafka/connect-distributed.properties

Topic 목록 확인하면 connect가 잘 생성되었다.
Topic 목록 확인
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
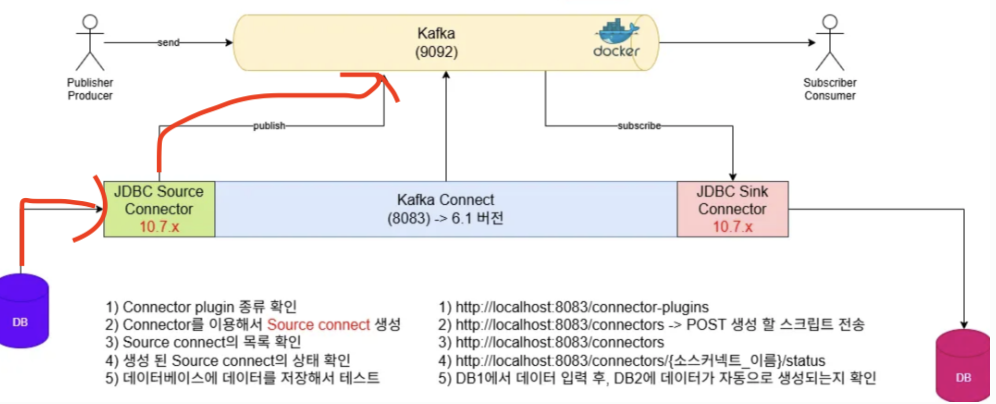
빨간색 화살표 부분의 작업을 해보자.
Polling 방식으로 데이터의 변경을 감지하기 위해서
DB1 -> Kafka 을 연결해주는 Source Connect가 필요하다.
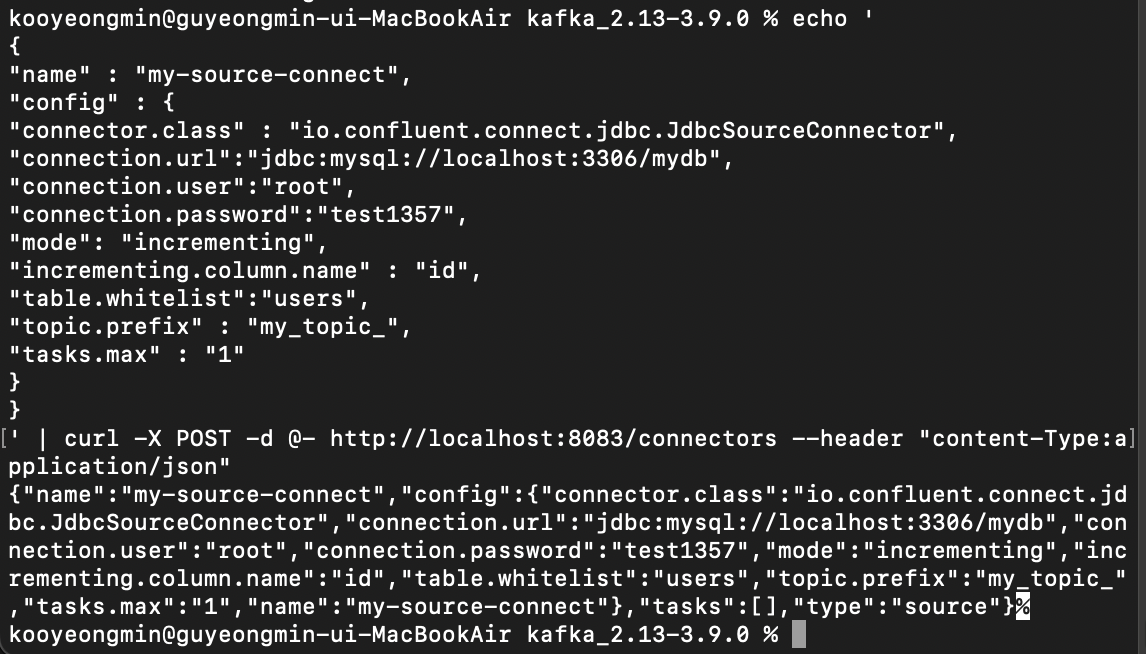
curl을 날려서 Source Connect를 추가할 수 있다.
Kafka Source Connect 추가
echo ' { "name" : "my-source-connect", "config" : { "connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector", "connection.url":"jdbc:mysql://localhost:3306/mydb", "connection.user":"root", "connection.password":"test", "mode": "incrementing", "incrementing.column.name" : "id", "table.whitelist":"users", "topic.prefix" : "mytopic", "tasks.max" : "1" } } ' | curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"
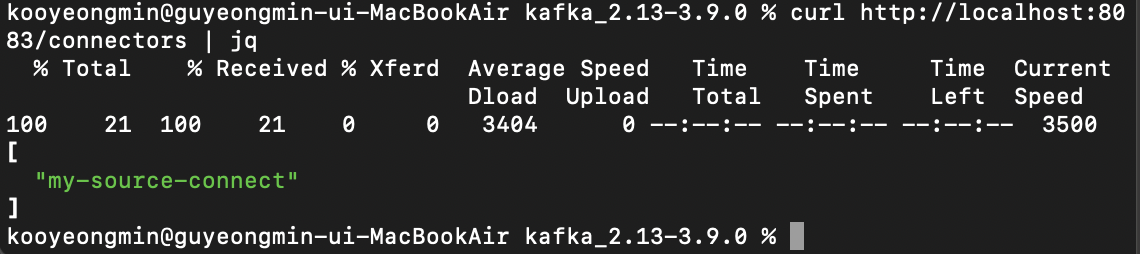
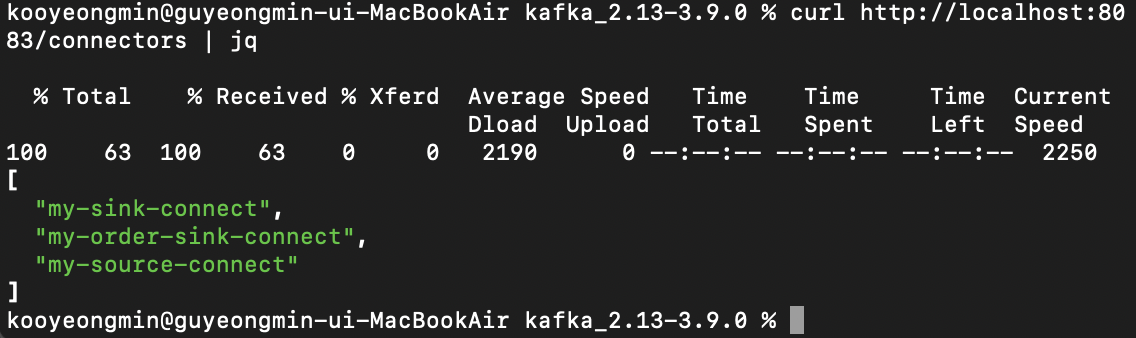
Connect 목록을 확인해보면 my-source-connect가 잘 생성되었다.
Connect 목록 확인
curl http://localhost:8083/connectors | jq
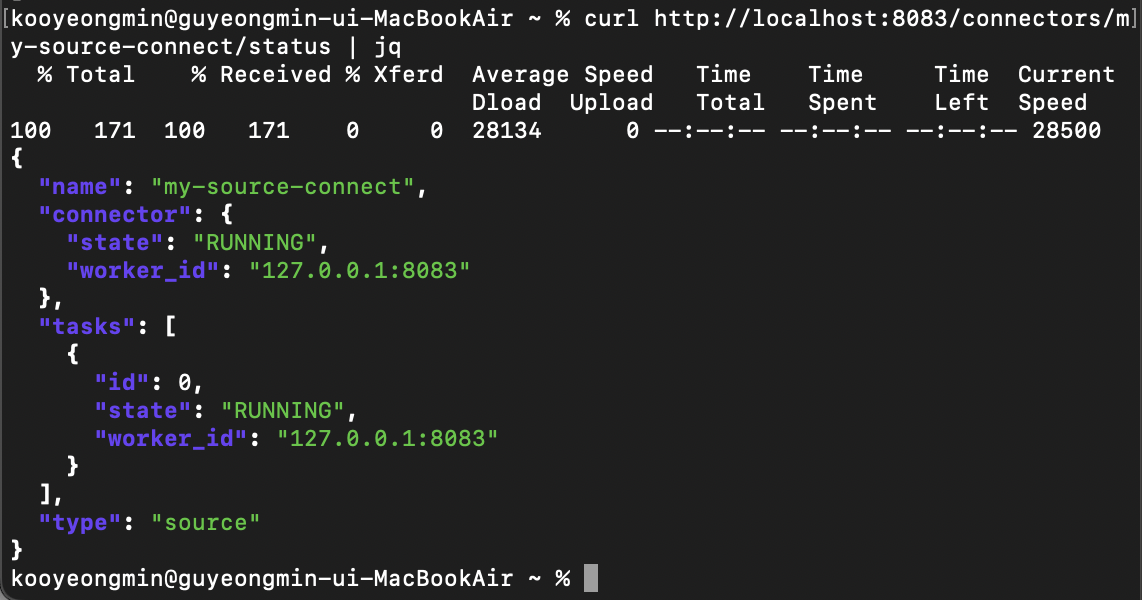
curl 명령어를 통해 Connect의 상태도 확인해볼 수 있다.
Source Connect가 잘 세팅된 것 같으니 이제 테스트를 해보자.
Kafka Connect 상태 확인
curl http://localhost:8083/connectors/my-source-connect/status | jq
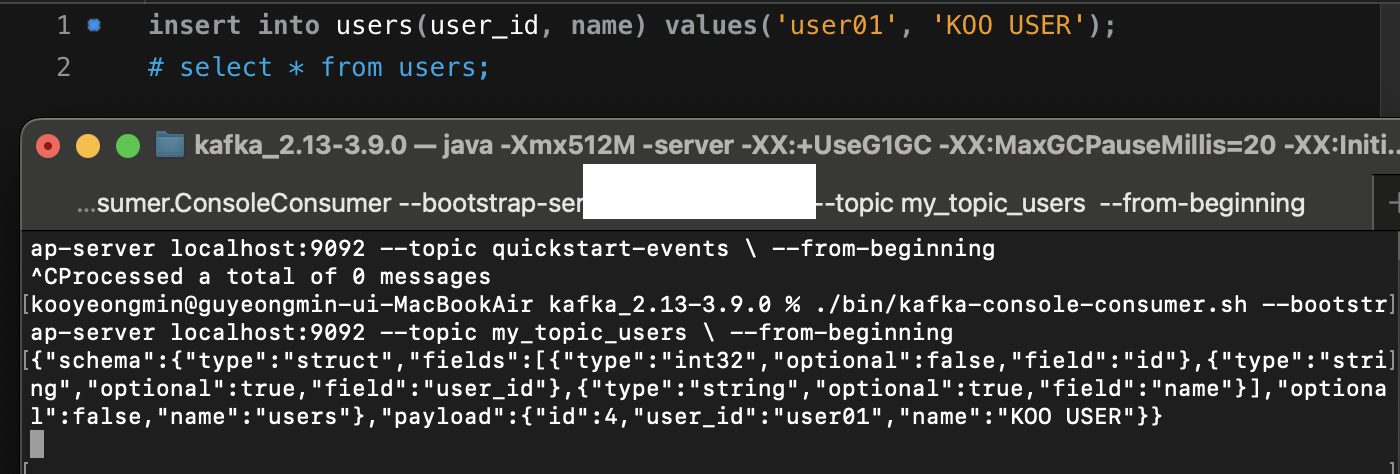
DB1(users)에 insert를 해보니 DB1을 Source Connect가 Polling 방식으로 데이터를 감지하고 자동으로 Topic에 데이터를 넣어줬다.
my-sink-connect도 위와 같은 방식으로 진행하면 된다.
Kafka Source Connect 추가
echo ' { "name":"my-sink-connect", "config":{ "connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url":"jdbc:mysql://localhost:3306/mydb", "connection.user":"root", "connection.password":"test", "auto.create":"true", "auto.evolve":"true", "delete.enabled":"false", "tasks.max":"1", "topics":"my_topic_users" } } '| curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"
my-source-connect, my-sink-connect를 모두 생성 후에,
Kafka를 통해서 데이터가 잘 저장되는지 테스트 해보자
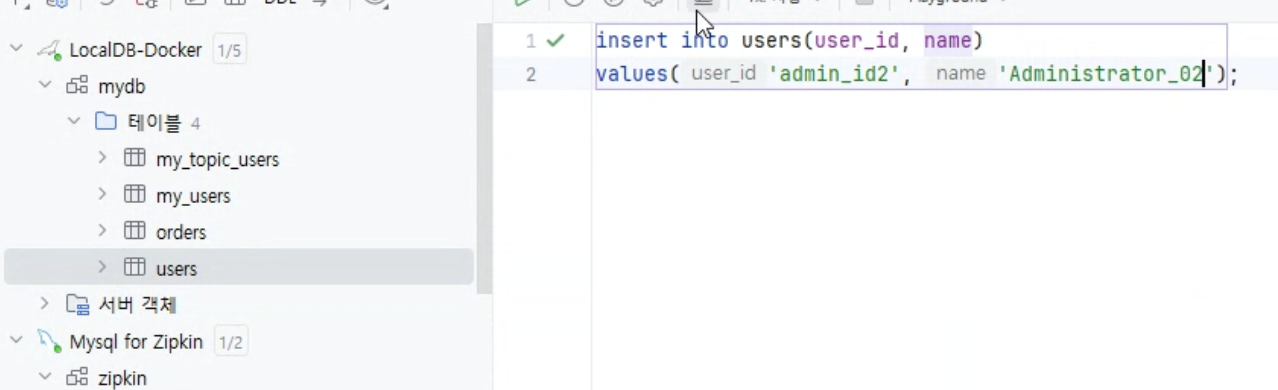
DB1(users)에 데이터를 insert하면
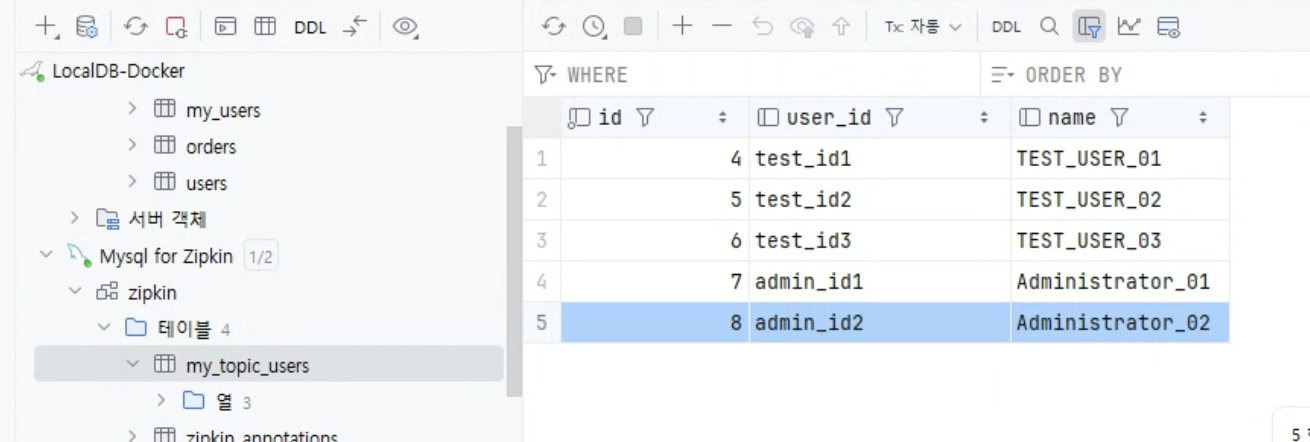
MYDB에 저장 -> JDBC Source Connector-> Kafka Topic -> JDBC Sink Connector -> MyDB2에 저장
위의 과정을 거쳐 데이터가 잘 저장되는 것을 볼 수있다.
2.5 msa-toy 프로젝트에 적용하기
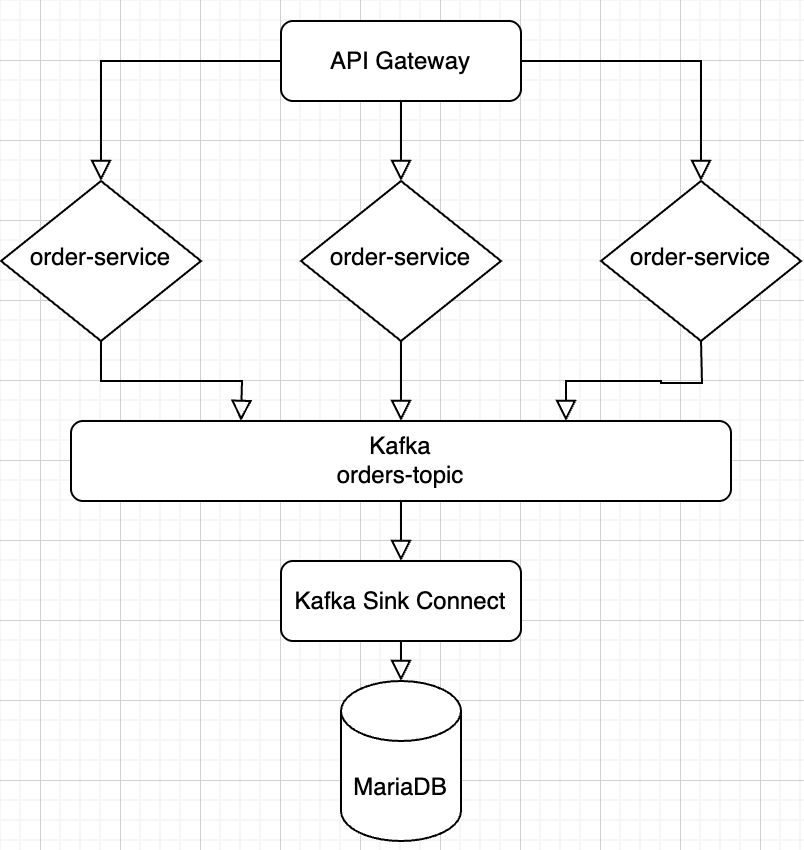
3개의 Order-Service가 보내는 요청을 Kafka를 통해서 데이터를 안전하게 저장할 수 있게 하고 싶다.
- orders 이름을 가진 Topic을 생성해주고
- my-order-sink-connect를 생성해준다.
{
"name":"my-order-sink-connect",
"config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url": "jdbc:mysql://localhost:3306/mydb",
"connection.user": "root",
"connection.password": "test",
"auto.create":"true",
"auto.evolve":"true",
"delete.enabled":"false",
"tasks.max":"1",
"topics":"example-order-topic"
}
}
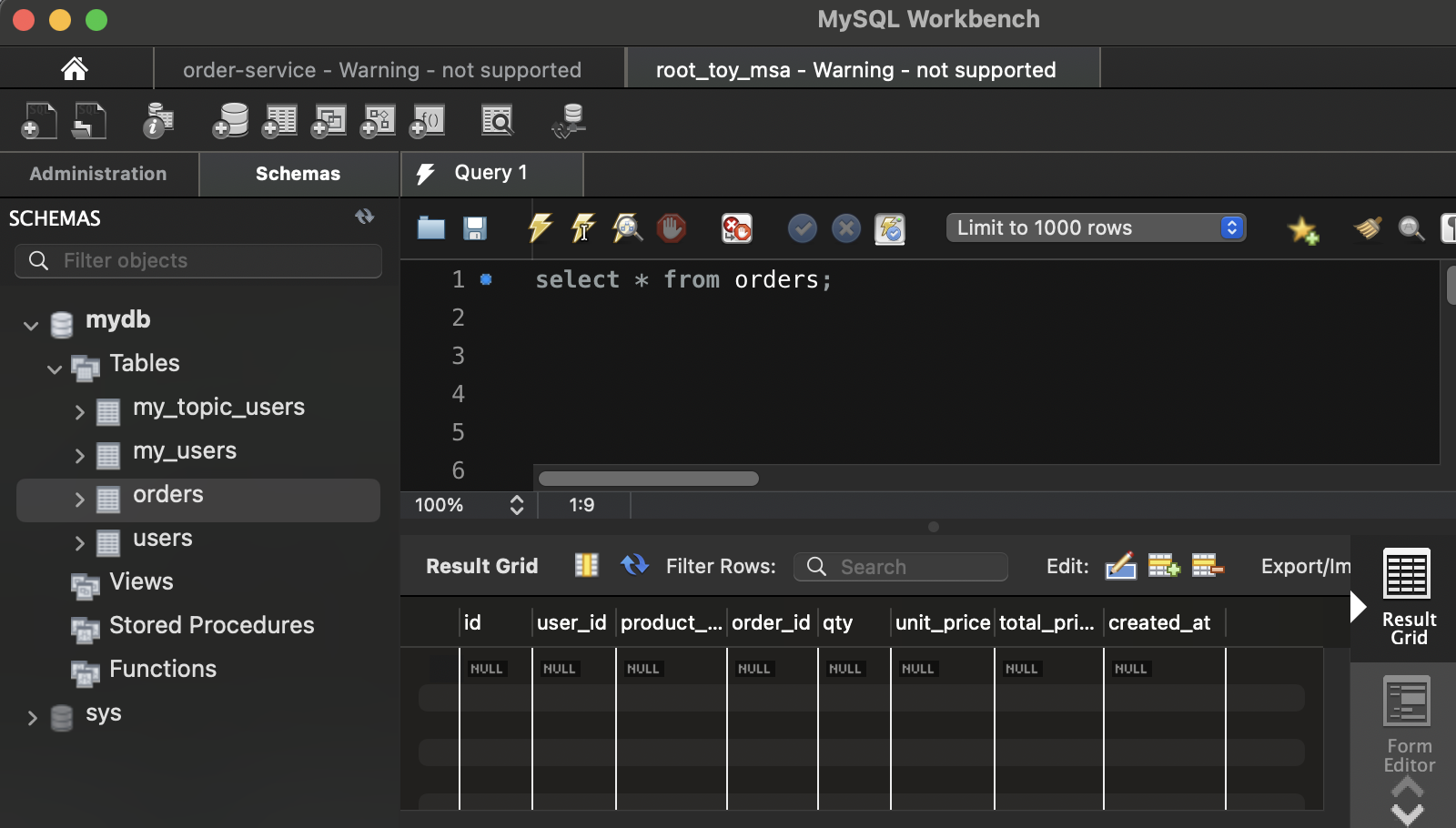
초기 데이터는 아무것도 없는 상태이다.
Order-Service를 총 3개 실행시킨 후에 주문을 총 3번 진행해보자

mvn 명령어를 사용해서 총 3개의 Order-Service를 실행시키자
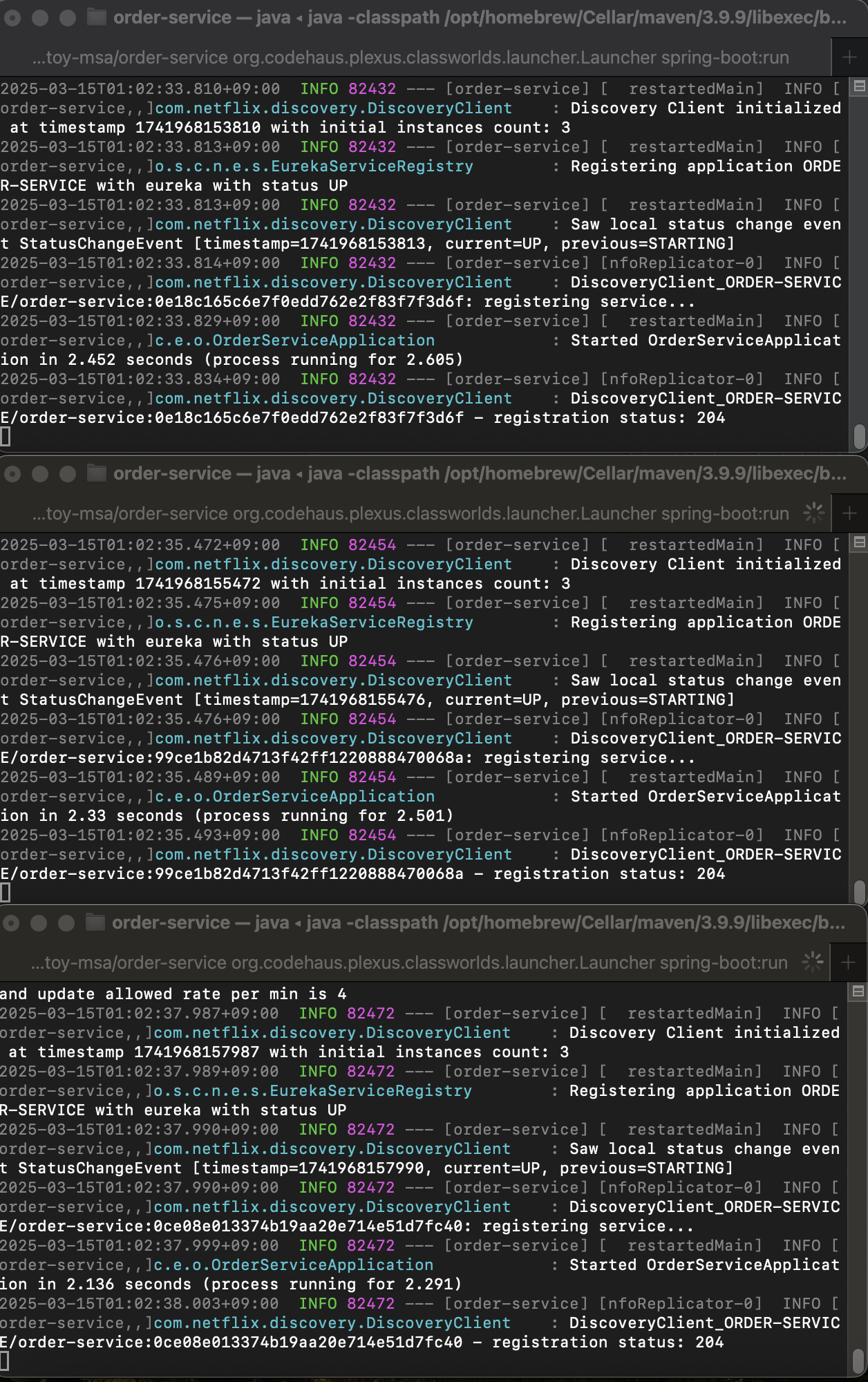
총 3개의 Order-Service가 정상적으로 실행되고 있다. 이제 Postman을 통해 Post 주문 요청을 3번하면 어떻게 될까?
테스트 용 더미 데이터이므로 수량 컬럼을 1,2,3으로만 바꿔서 Post요청을 보냈다.
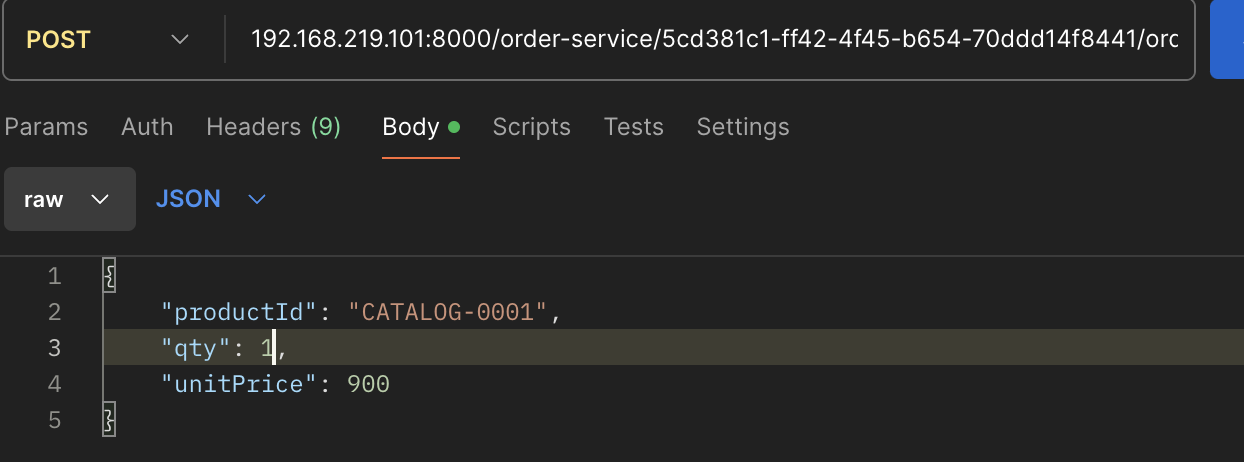
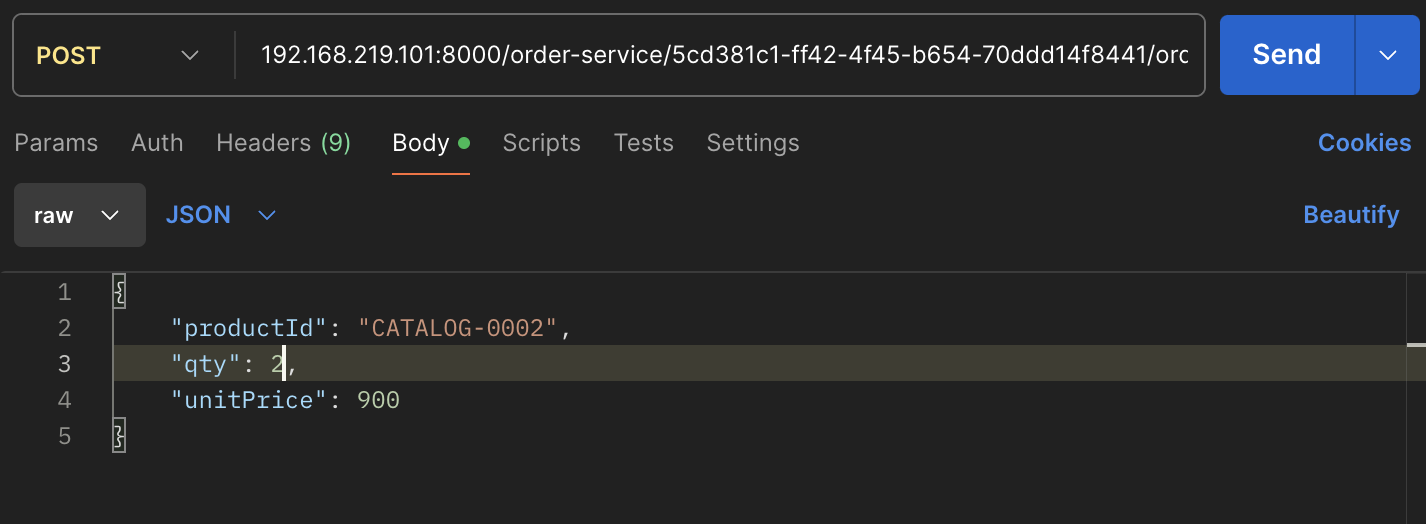
왼쪽부터 오른쪽이 데이터요청을 1번, 2번, 3번 했을 때의 서버의 변화이다.
첫번째 Post요청을 했을 때, 1번 서버에 요청이 처리되었다.
두번째 Post요청을 했을 때 3번 서버에 요청이 처리되었다.
세번째 Post요청을 했을 때 2번 서버에 요청이 처리되었다.
Load Balancing은 제대로 처리된 것 같고 밑의 사진을 보면 데이터도 Kafka를 통해서 하나의 DB에 잘 모여있는 것을 확인할 수 있다.

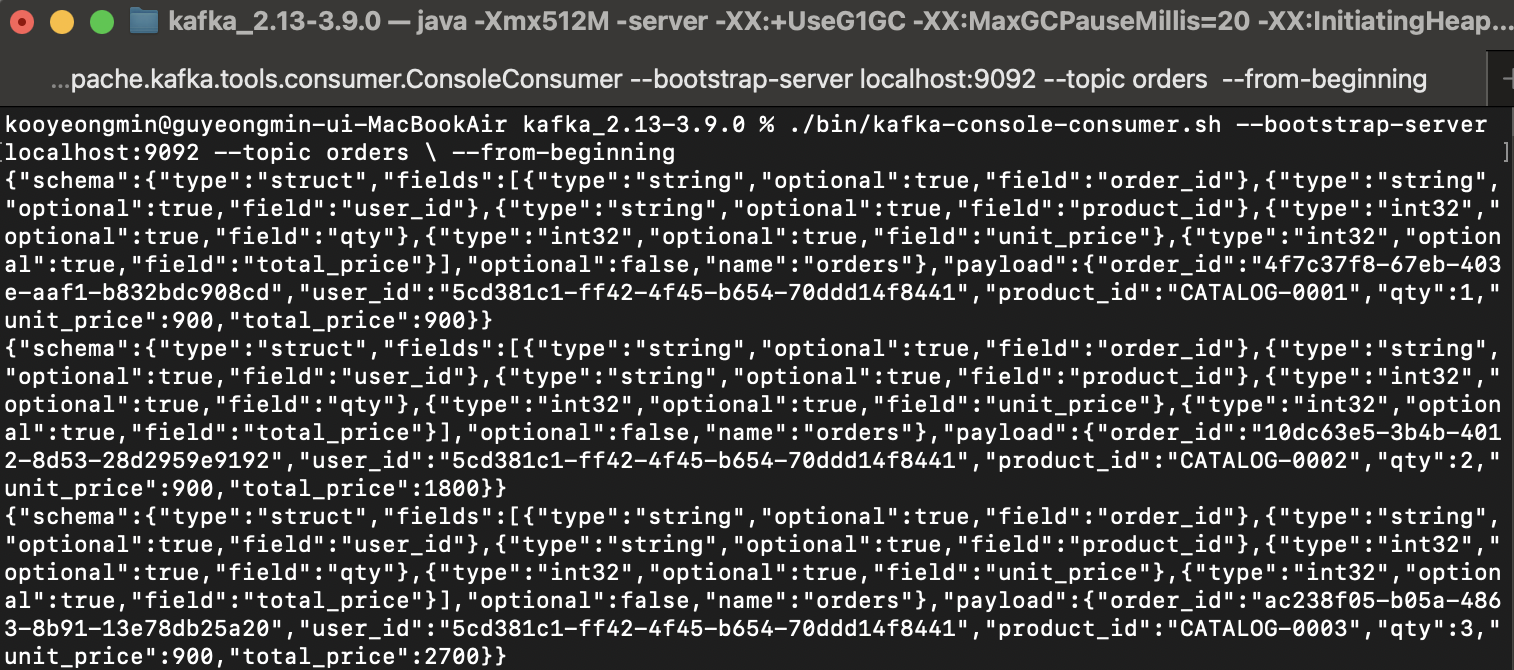
Topic에도 3개의 데이터가 잘 들어온 것을 확인할 수 있다.
후기
- Kafka를 잘 이용하면 대량의 데이터처리를 할 때 동시성 문제도 해결할 수 있을 것 같다.
- DB가 2개있을 때 양쪽 DB에 모두 Source Connector, Sink Connector를 달아주면 DB를 동기화 시키는 것에도 사용할 수 있을 것 같다.
어렵지만 더 깊이 공부해보면 유용하게 쓰일 기술이다.
