Legacy Application를 AWS 마이그레이션 하기
1. 배경
LG CNS Inspire Camp 1기에서 진행된 미니프로젝트2에서 Legacy Application의 Microservice 전환이라는 주제로 딱 일주일 동안 진행됐는데, 우리 조는 그중에서도 AM(Application Modernization)에 집중해서, Oracle 환경에 있던 Kitcha 서비스를 AWS로 옮기는 마이그레이션 작업을 주제로 선정했다.
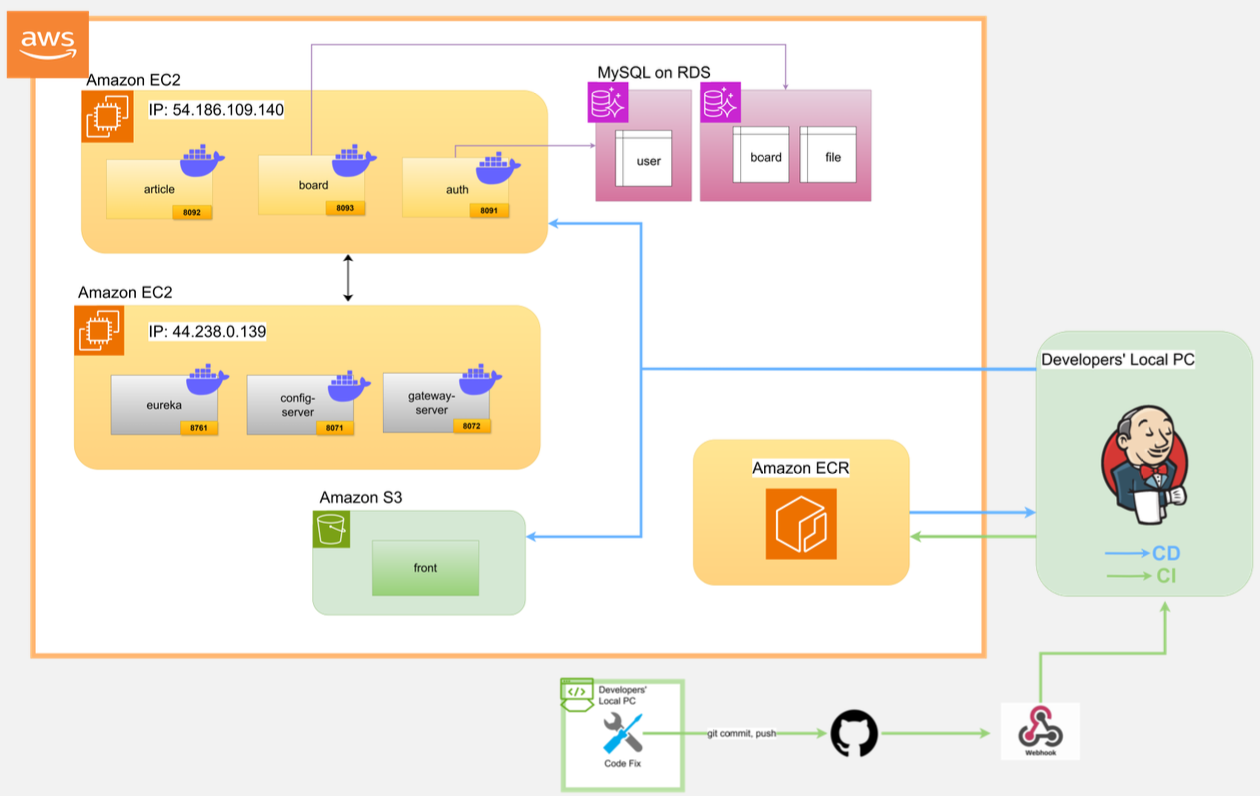
2. 기존 Kitcha 시스템 구조
2.1 기존 시스템 분석
우리가 전환 대상으로 삼은 Kitcha 시스템은 Oracle Cloud 환경에서 이미 MSA 구조로 구성된 상태였다.
하지만 자세히 들여다보면, 표면적으로만 마이크로서비스 구조를 따르고 있었을 뿐, 실제로는 여러 가지 한계가 존재했다.
백엔드 쪽은 article, board, auth 등으로 나뉘어 있는 여러 개의 서비스가 존재했지만, 이 서비스들이 모두 하나의 MySQL 데이터베이스를 공유하고 있었다. 예를 들어 user, board, file 같은 테이블을 공통으로 사용하다 보니, 서비스 간의 데이터 결합도가 높았고, 하나의 변경이 전체 시스템에 영향을 줄 수 있는 구조였다.
프론트엔드도 독립된 서버 없이 백엔드와 동일한 서버에서 함께 제공되는 방식이었고, 모든 서비스가 Docker 컨테이너로 패키징되어 있긴 했지만 결국엔 모두 같은 서버 인스턴스 위에서 동작하고 있었기 때문에, 확장성과 유연성 측면에서 많은 제약이 따랐다.
2.2 개선 방향
1. EC2 인스턴스 분할
• 기존에는 모든 서비스가 하나의 인스턴스에 몰려 있었지만, 이를 Inner Architecture와 Outer Architecture로 나누어 각각의 역할에 맞는 EC2 인스턴스로 분리 하기
2. AWS ECR + Jenkins를 활용한 배포 자동화
• 도커 이미지는 ECR에 저장하고
• Jenkins + GitHub + Webhook을 연동해 코드 푸시 → 자동 빌드 → 배포까지 자동화된 CI/CD 파이프라인을 구축 하기
3. 데이터베이스 도메인 분리
• 기존 단일 MySQL DB 구조를 board 게시판/사용자 정보를 별도 RDS로 분리 하기
4. 프론트엔드 분리 및 S3 정적 웹 호스팅
• 프론트엔드를 백엔드에서 분리해 Amazon S3에 정적 웹 호스팅으로 배포 하기
3. 변경 과정
기존 Kitcha 시스템은 말 그대로 모든 게 한 인스턴스에 몰려 있는 구조였다. 백엔드 서비스들뿐만 아니라 Config, Eureka, Gateway 같은 인프라 구성 요소까지 전부 단일 서버에서 돌고 있었기 때문에, 서비스가 하나라도 문제를 일으키면 전체 시스템이 영향을 받을 수밖에 없는 상황이었다.
그래서 우리는 이 구조를 조금 더 현실적인 수준에서 개선해보고자 했다.
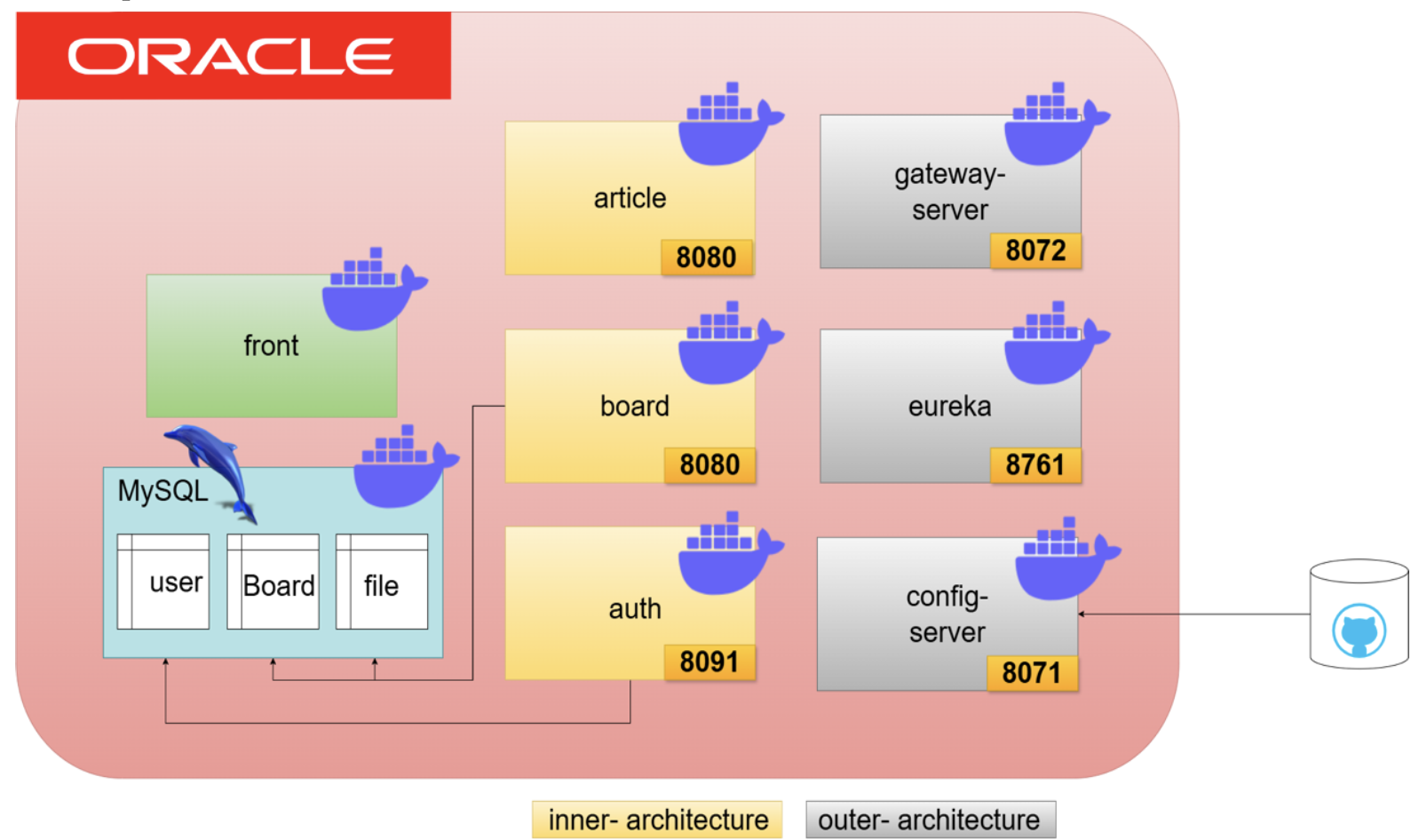
3.1 EC2 도입을 통한 Inner, Outer Architecture 분리

일단 인프라 비용이나 운영 복잡도 등을 고려해서 모든 서비스를 완전히 따로따로 쪼개서 배포하기보단, Inner와 Outer 서비스로 나눠서 두 개의 인스턴스로 분리하는 방향을 선택했다.
- Inner 서비스: 실제로 Kitcha의 핵심 비즈니스 로직을 담당하는 서비스들
(article, board, auth 등)을 하나의 인스턴스에 묶어서 배포
- Outer 서비스: 시스템 전반의 설정과 라우팅을 담당하는 인프라 서비스들
(Config Server, Eureka Server, API Gateway)을 다른 인스턴스에 분리 배포이렇게 구분한 이유는 우선 서비스 간 결합도를 낮춰서 운영 안정성을 확보할 수 있고, 무엇보다도 인프라 서비스는 상대적으로 리소스를 덜 소모하기 때문에, 굳이 고사양의 서버에 같이 올릴 필요가 없다고 판단했다.
3.2 ECR 도입
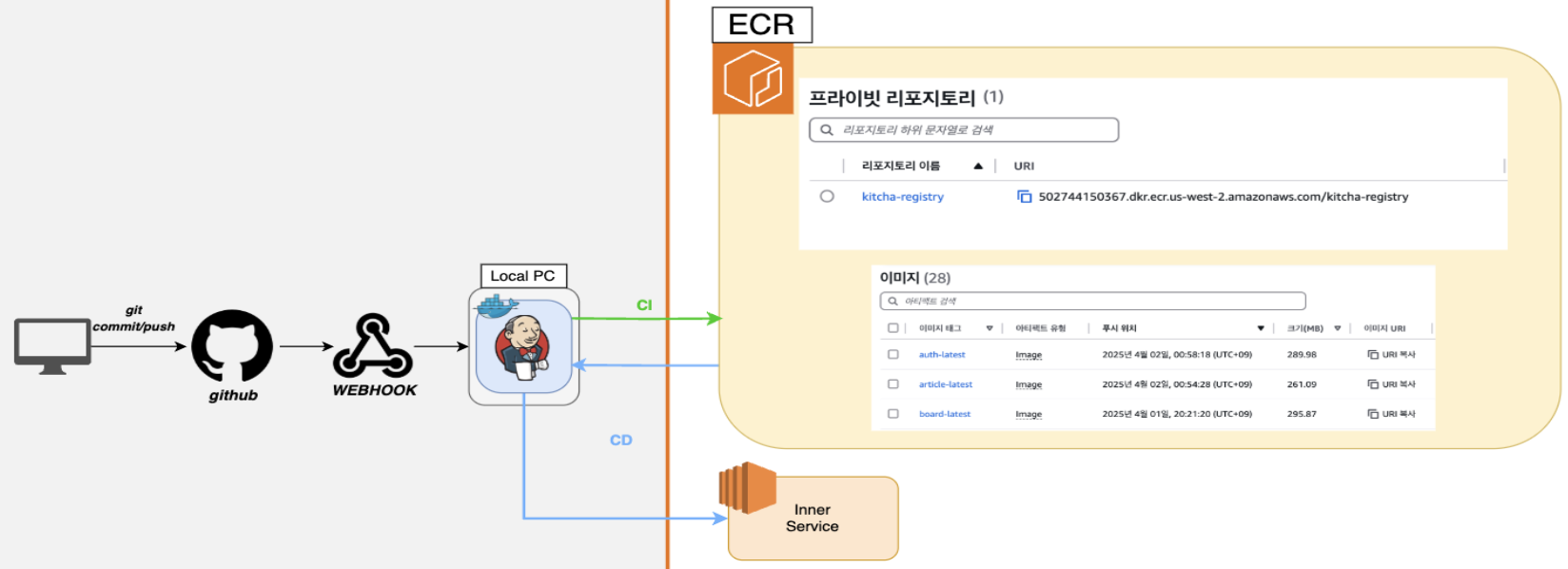
서비스 구조를 분리하고 나서, 다음으로 우리가 집중한 건 배포 자동화였다.
레거시 시스템에서는 새로운 기능을 배포할 때마다 수동으로 컨테이너 이미지를 빌드하고 서버에 올려야 했는데, 이 과정이 반복되다 보면 실수가 발생하기 쉽고, 개발 속도도 자연스럽게 느려질 수밖에 없다. 그래서 우리는 AWS 환경에 최적화된 CI/CD 파이프라인을 직접 구성해보기로 했다.
먼저, 컨테이너 이미지 레지스트리로는 AWS ECR(Elastic Container Registry)를 선택했다.
- AWS의 다른 인프라 서비스들과의 연동이 훨씬 쉽고,
- IAM 기반 인증으로 보안 측면에서도 안정적이며,
- 프라이빗 레지스트리로 사용할 수 있어서 관리 효율도 높았기 때문이다.
파이프라인 구성
1. 개발자가 Git에 코드 푸시
2. Git에서 설정된 Webhook을 통해 Jenkins가 트리거됨
3. Jenkins에서 해당 코드로 Docker 이미지를 빌드
4. 빌드된 이미지를 ECR에 푸시 (프라이빗 레지스트리)
5. 이후 해당 이미지를 운영 서버에 자동 배포3.3 RDS 도입
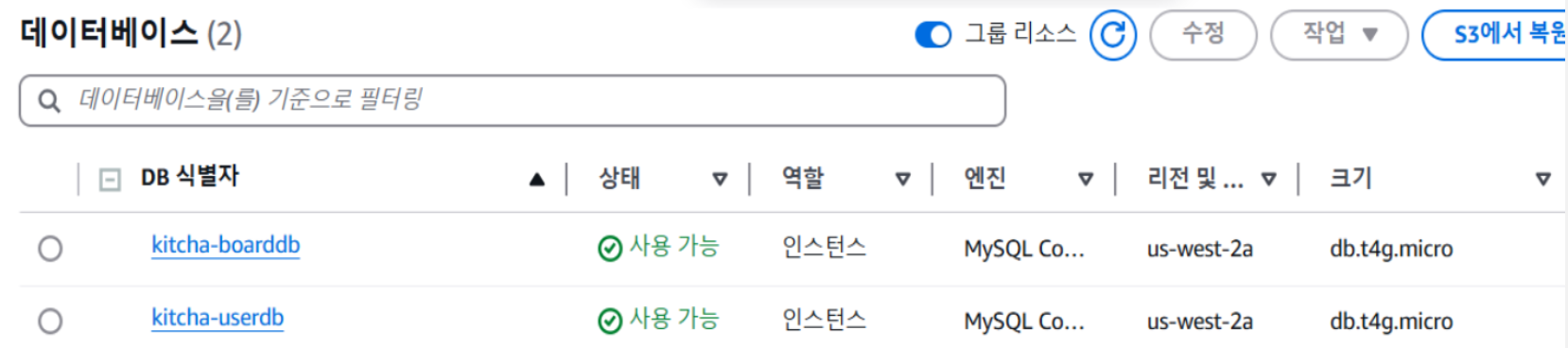
CI/CD 파이프라인을 구성한 이후, 우리가 고민한 또 다른 부분은 데이터베이스 구조였다.
기존 시스템에서는 모든 서비스가 하나의 MySQL 데이터베이스를 공유하고 있었기 때문에, 앞서 언급한 것처럼 데이터 간 결합도가 높고, 관리가 어렵다는 문제가 있었다.

그래서 우리 조는 서비스의 도메인별로 데이터를 나누어, 게시판과 사용자 정보를 각각의 DB로 분리하는 방식으로 구조를 개선했다.
이렇게 나누면 서비스 간의 경계를 명확히 할 수 있고, 이후 특정 도메인에 대한 트래픽이 급증했을 때도 독립적으로 확장하거나 조치할 수 있는 여지가 생긴다.
3.4 S3 도입
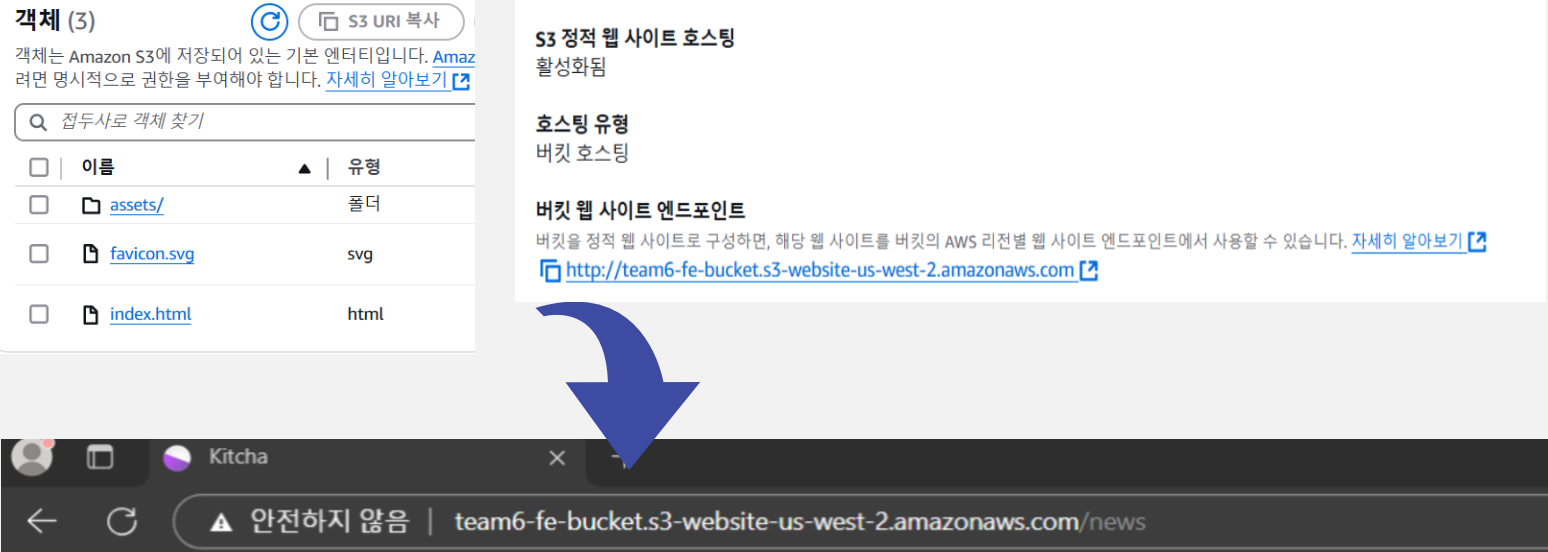
마지막으로, 프론트엔드 배포는 AWS S3의 정적 웹 호스팅 기능을 이용해 구성했다.
기존에는 프론트엔드가 백엔드 서버 인스턴스에서 함께 돌아가고 있었는데, 그렇게 되면 자연스럽게 서버 자원 소모가 커지고, 트래픽이 많아질 경우 서버가 불필요하게 과부하될 수 있다는 문제가 있었다.
그래서 우리는 프론트엔드를 백엔드 서버 인스턴스에서 완전히 분리해서 운영하기로 했다.
S3는 정적 파일을 호스팅하기에 최적화되어 있고,
- 비용도 저렴하고,
- 가용성도 높고,
- 설정만 잘 하면 CDN(CloudFront)과 연계해 배포 속도도 빠르게 만들 수 있다.
덕분에 사용자는 더 빠르고 안정적으로 정적 페이지에 접근할 수 있고, 백엔드 서버는 본연의 API 처리에만 집중할 수 있는 구조가 되었다.
프론트엔드 트래픽이 많더라도 EC2 서버에 직접 부담이 가지 않기 때문에, 서버 스펙을 낮게 유지하면서도 사용자 경험은 충분히 확보할 수 있는 구조를 만들 수 있었다는 점에서 만족스러웠다.
4. 트러블 슈팅
4.1 EC2 서버 분할 트러블 슈팅
AWS 마이그레이션을 진행하면서, 메모리 부족 이슈가 발생했다.
당시엔 EC2 small 인스턴스 한 대 위에 총 7개의 컨테이너를 올려서 서비스를 운영하고 있었는데, 어느 순간부터 서버가 계속 다운되기 시작했다. 메모리 부족 현상으로 서비스가 정상적으로 기동조차 되지 않는 상황이었다.
처음엔 급한 불부터 끄기 위해, 인스턴스를 small → large 유형으로 스케일 업하는 방식으로 문제를 해결했다.
확실히 리소스가 늘어나니 서버는 안정적으로 돌아갔고, 더 이상 메모리 부족 현상은 발생하지 않았다.
하지만 이 방법에는 비용이라는 치명적인 단점이 하나 있었다.
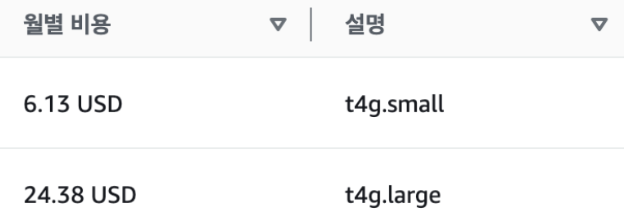
* small 인스턴스는 월 6.13달러
* large 인스턴스는 월 24.38달러단순 계산만 해도 거의 4배 가까이 비용이 증가한 셈이다.
이건 단기적인 응급처치로는 괜찮지만, 장기적으로 유지하기엔 너무 비효율적이었다.
그래서 팀원들과 “스케일 업이 아닌, 더 효율적인 방법은 없을까?”를 함께 고민했다.
결국 우리가 선택한 해결책은 인스턴스를 분할해서 운영하는 것이었다.
즉, 하나의 large 인스턴스에 모든 서비스를 몰아넣는 대신,
- Inner Architecture (article, board, Authentication)과
- Outer Architecture (Config, Eureka, Gateway 등 인프라 구성 요소)로 나눠서, 각각을 별도의 small 인스턴스 두 대에 나눠 배포하는 방식을 선택했다.
이렇게 나누면 리소스도 더 효율적으로 분배할 수 있고, 무엇보다도 비용이 절반 가까이 줄어드는 장점이 있었다.
* large 인스턴스 (1대): 0.0848 달러/시간
* small 인스턴스 (2대): 0.0212 x 2 = 0.0424 달러/시간계산해보면, 서버 비용이 50% 절감되는 셈이다.
이렇게 구조를 나누면서 얻은 건 비용 절감뿐만이 아니었다.
* 한쪽 인스턴스에 문제가 생겨도 전체 서비스가 멈추지 않음
* 필요할 때마다 특정 아키텍처만 독립적으로 확장 가능
* 향후 쿠버네티스 같은 오케스트레이션 도구를 도입하기에도 더 적합한 구조AWS 환경에서는 리소스를 단순히 키우는 것보다, 어떻게 효율적으로 나누고 배치하느냐가 중요하다고 느꼈다.
하지만 EC2 분할 과정이 쉽지만은 않았다. 처음에는 “분리하면 끝이겠지!” 싶었는데, 막상 적용해보니 예상치 못한 통신 문제가 발생했다.
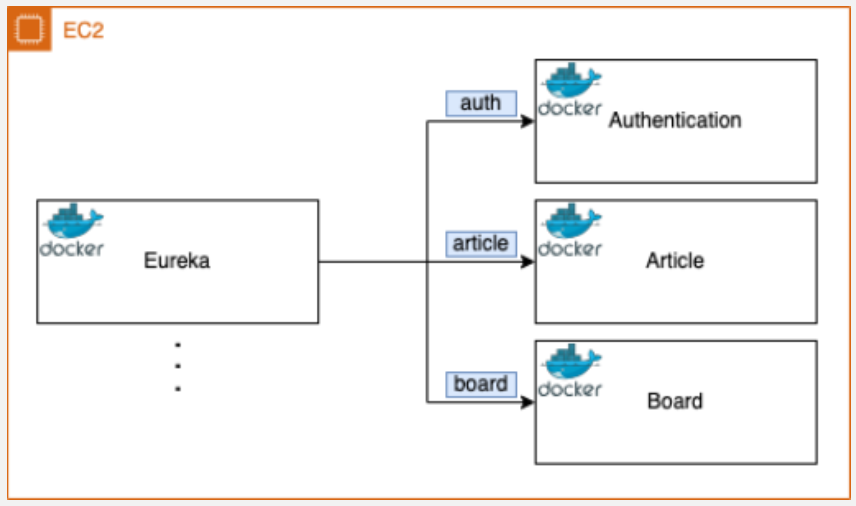
그림을 보면, 왼쪽의 EC2는 Outer 인스턴스로, Eureka 컨테이너가 올라가 있고 오른쪽의 EC2는 Inner 인스턴스로, Auth-Service, Article, Board 같은 여러 서비스 컨테이너들이 구동 중이다.
기존에는 모든 컨테이너가 하나의 EC2 내에서 돌아가고 있었기 때문에, 통신할 때 그냥 container name을 이용해서 연결하면 아무 문제 없이 동작했다.
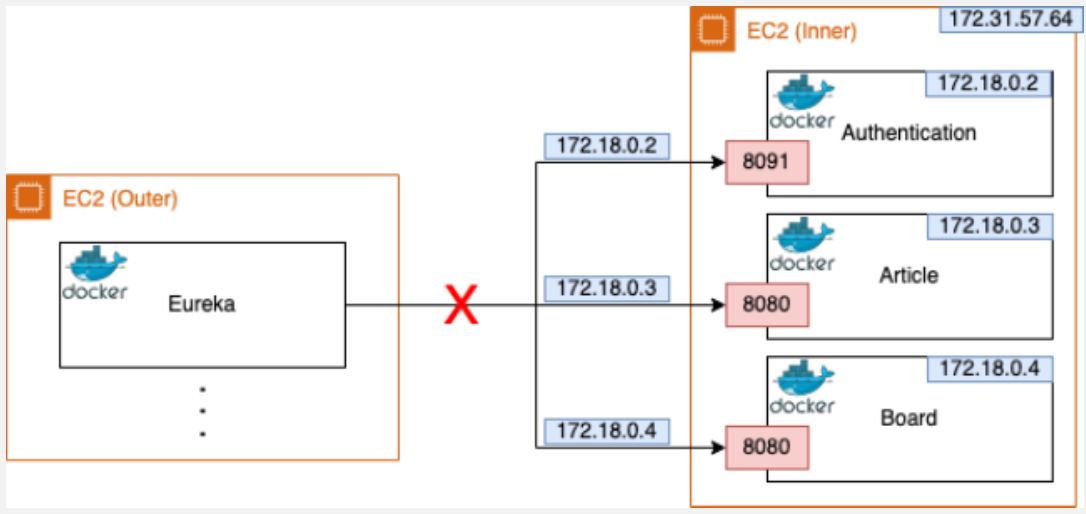
하지만 EC2를 분리하면서부터 문제가 생겼다.
서로 다른 인스턴스에 있는 컨테이너끼리는, 기본적으로 container 이름이나 내부 IP로는 접근이 불가능하기 때문이다.
Gateway에서 Auth-Service에 요청을 보낼 때,
- Eureka가 auth-service의 인스턴스 주소를 172.23.0.4 같은 Docker 내부 IP로 알려주는데,
- 이 IP는 실제로는 다른 EC2 인스턴스 내부에 있는 컨테이너 주소라, 외부에서는 전혀 접근할 수 없었다.
결과적으로, Gateway가 해당 주소로 요청을 보내도 timeout 에러가 발생했다.
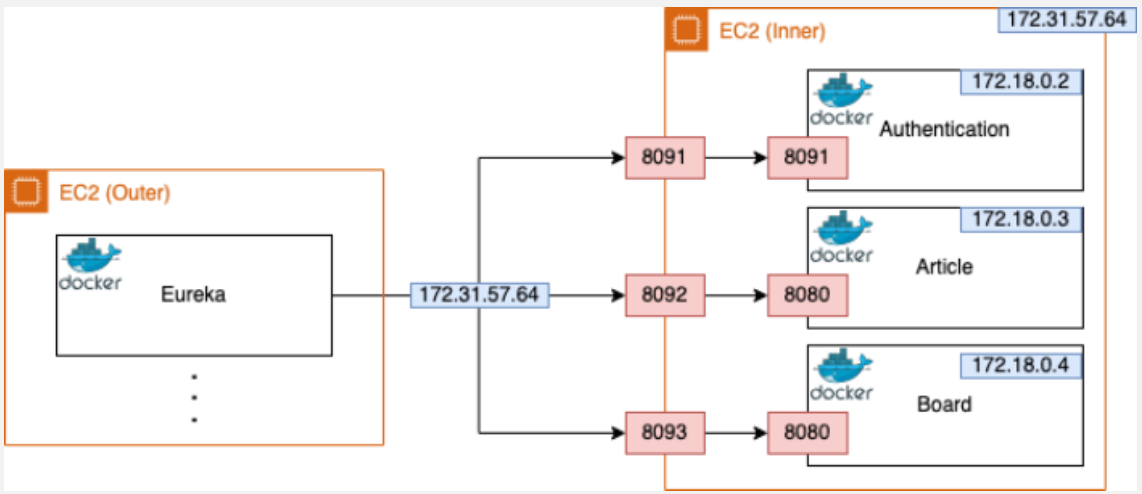
이 문제를 Inner EC2의 Private IP를 활용해서 포트 포워딩을 설정하는 방식을 사용하여 해결했다.
1. Inner EC2 인스턴스에서, 각 컨테이너의 포트를 EC2 외부 포트에 바인딩
2. Eureka에 서비스 등록 시, 컨테이너 내부 IP가 아닌 EC2의 Private IP + 포트 번호를 등록
이렇게 되면,
1. 다른 EC2의 Gateway에서도 해당 주소로 요청을 보내면
2. Inner EC2가 해당 요청을 받아
3. 내부 컨테이너 포트로 포워딩해주는 구조 완성이 방식 덕분에 Gateway는 더 이상 잘못된 Docker 내부 IP로 요청을 보내지 않고,
정상적인 Private 네트워크 기반 주소로 통신할 수 있게 되었다.
4.2 Jenkins Build 트러블 슈팅
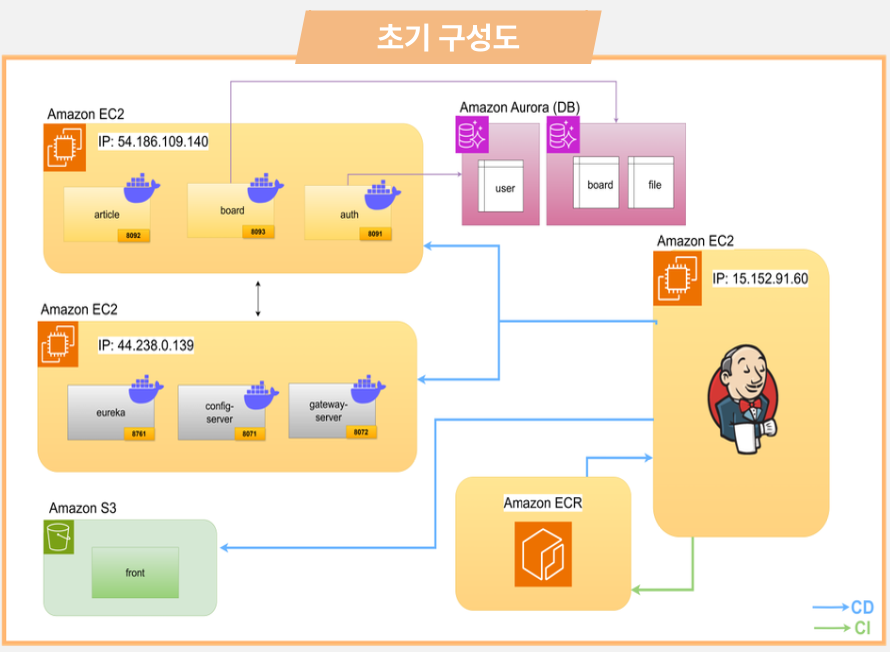
초기에 저희는 Jenkins도 다른 서비스들과 마찬가지로 EC2 인스턴스 위에서 구동하는 구조를 계획했다.
CI 서버용으로는 t2.small 인스턴스를 사용했는데, 직접 해보니 문제가 꽤 컸다.
Jenkins에서 빌드가 동시에 여러 개 돌아가거나, 컨테이너 이미지 빌드처럼 리소스를 많이 잡아먹는 작업이 시작되면 서버에 과부하가 걸려서 Jenkins 자체가 뻗는 경우가 생겼고,
심지어는 단일 서비스 하나의 빌드만 수행하는데도 1시간 이상 걸리는 상황도 있었다.

CI 파이프라인이라는 게 빠르게 반복되고 효율적으로 돌아가야 의미가 있는데,
이 정도면 의미 있는 자동화라고 보기 힘들겠다는 생각이 들었다.
그래서 Jenkins를 아예 로컬 PC에서 띄워서 사용하는 방식으로 전환하였다.
생각보다 이 변화는 엄청난 차이를 만들어냈다.
* 기존 EC2에서 빌드 시간: 1시간 16분
* 로컬 Jenkins 빌드 시간: 3분 43초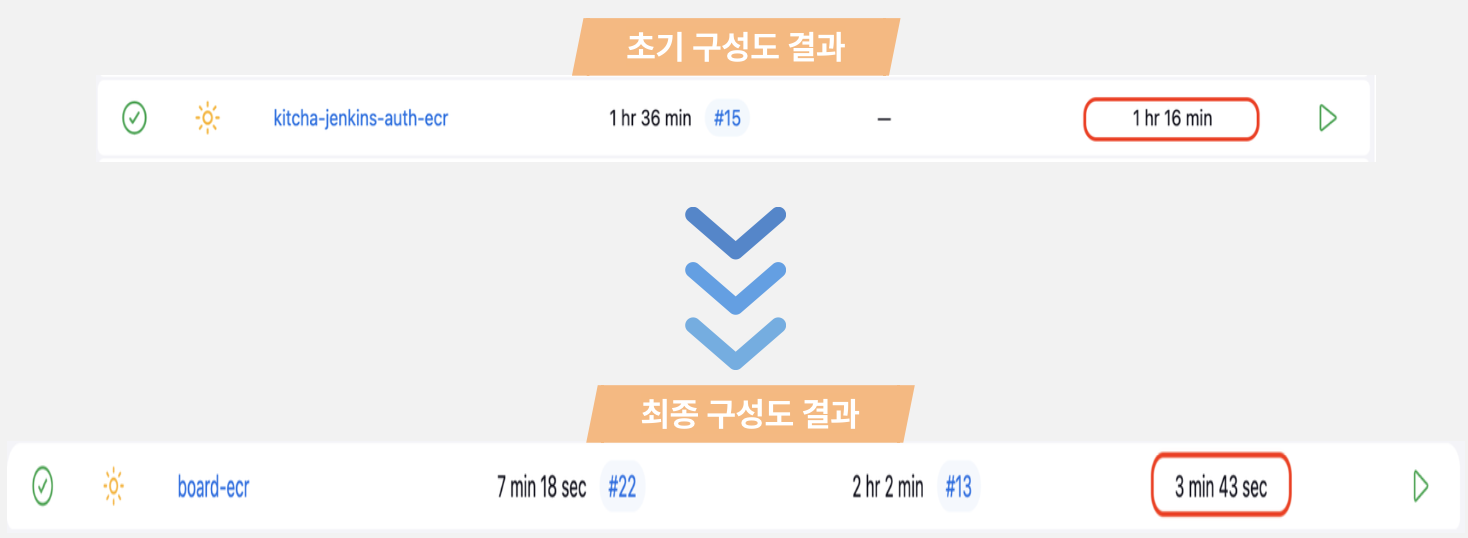
무려 95% 이상의 시간 단축을 이뤘고, 동시에 Jenkins 전용 인스턴스를 유지할 필요가 없어지면서 불필요한 AWS 리소스 비용도 절감할 수 있었다.
CI 과정은 그대로 유지되면서도, Jenkins만 클라우드에서 로컬 머신으로 옮긴 것이 전체적인 효율을 엄청나게 끌어올린 셈이다.
이 경험을 통해 느낀 건, 클라우드 자원을 사용하는 것이 항상 정답은 아니라는 것. 작업의 성격, 리소스 사용량, 트래픽 규모 등을 고려해서 “지금 단계에서 가장 효율적인 구조가 무엇인가?”를 계속 고민하는 게 정말 중요하다는 걸 깨달았다.
5. 마이그레이션 최종 결과 및 느낀 점
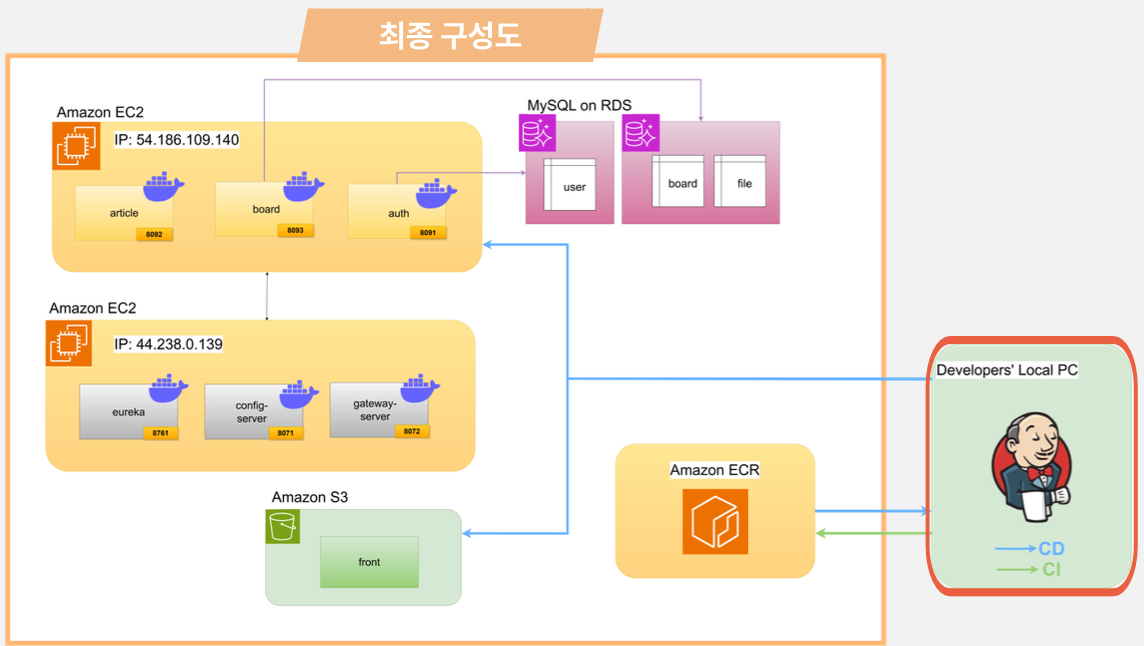
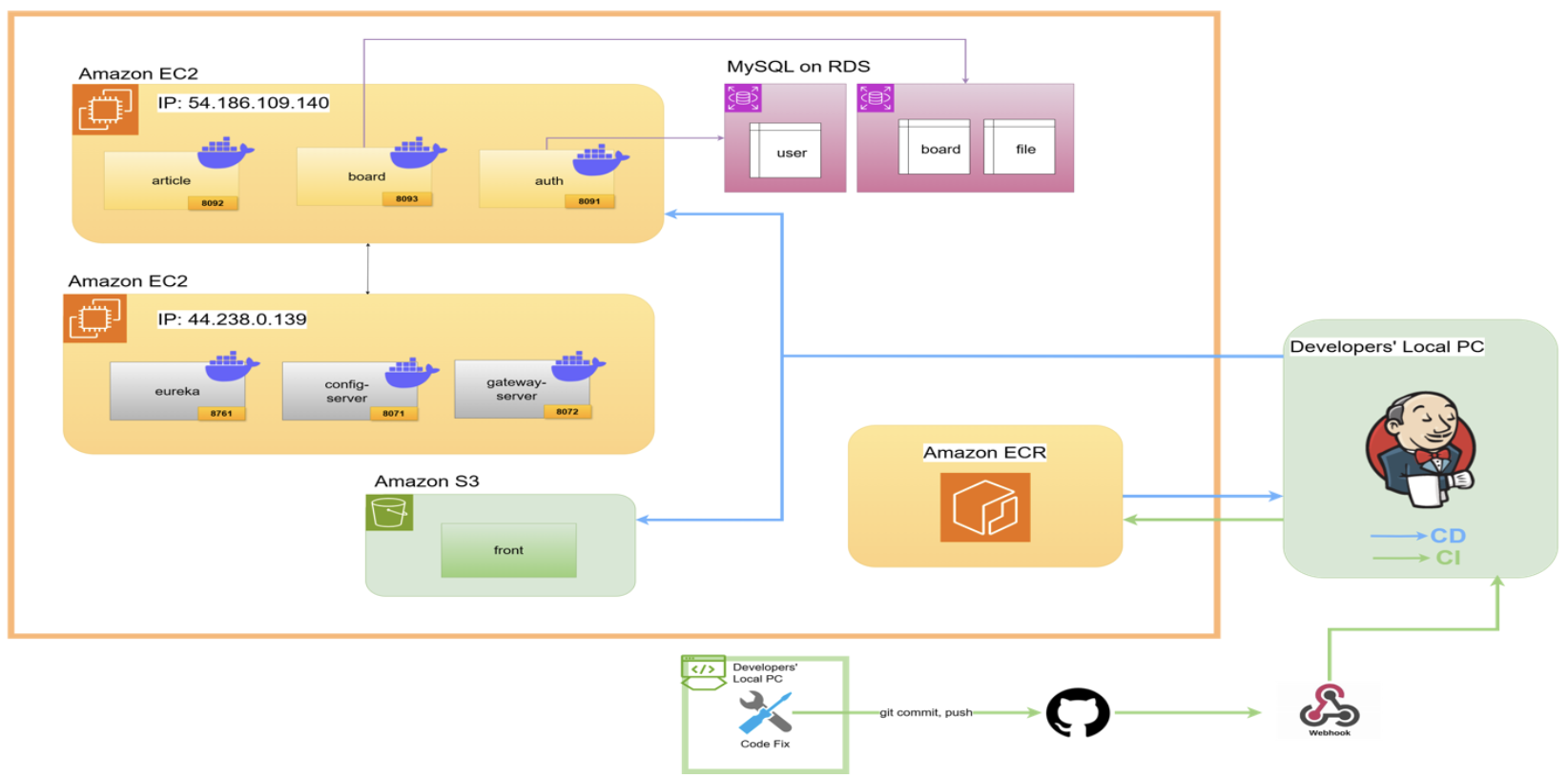
5.1 최종 아키텍처
5.2 느낀점
이번 프로젝트를 통해 AWS를 사용하면서 ‘비용까지 고려한 설계’가 얼마나 중요한지 직접 체감할 수 있었다.
단순히 서버 용량이 부족하다고 해서 막무가내로 인스턴스를 키우는 게 아니라,
서버의 시간당 비용, 성능, 활용도 등을 함께 고려해 구조적으로 접근하는 방식을 배울 수 있었다.
특히 일주일이라는 한정된 시간 안에서 최고의 퍼포먼스를 내기 위해, 역할을 분담하고 각자 맡은 영역에서 최선을 다한 경험은 정말 값졌다. 이 과정은 실제 회사에 들어가서도 마찬가지일 것이다. 자원과 시간이 제한된 환경 속에서 효율적으로 설계하고 빠르게 결과를 내는 경험을 미리 해볼 수 있었던 점이 큰 의미였다.
물론 아쉬운 점도 있다. RabbitMQ를 통한 Config 동기화나 Kafka를 활용한 비동기 메시징 등, 기능적인 확장이나 더 다양한 AWS 서비스(ECS, EKS, ALB 등)의 도입은 시간상 적용하지 못했다.
하지만 AWS 마이그레이션 프로젝트에서 보안 그룹 설정, Elastic IP 연결, EC2 인스턴스 세팅, RDS 구성, ECR까지 AWS의 핵심 인프라를 직접 다뤄보고 설계해본 것만으로도 큰 성과라고 생각한다.
