
드디어 피드백을 받았다 !
사실 월요일에 받았는데 남자친구와 데이트를 해서 적용할 시간은 없었다.
우선 내가 지금까지 한 부분에 문제는 없었다.
심지어 잘했다구 칭찬도 받았다.😊
얘기 해주신 걸 정리 해보았다.

중복 행 제거
먼저 교통량 데이터와 매칭 데이터를 merge해주었을 때 행이 늘어나는 현상이 있었다.
이유는 중복되는 행이 있다는 것!
알려주신 방법은 데이터프레임을 엑셀로 변환해서 중복되는 행을 찾아보는 것이었다.
그래서 to_excel을 사용하여 엑셀파일로 저장했다.
df.to_excel('이름.xlsx')이렇게 해주면 기본 파일(?)에 저장된다.(구글 코랩에서 파일 아이콘을 누르면 나옴!)
맨 처음에는 경로를 지정해주어서 파일을 저장했는데 자꾸없는파일이라 떠서 지정해주진 못했다.
그래서 그냥 저장했더니 저기에 뜨더라..
아마 내가 구글 드라이브에 마운트 해줘서 경로가 없다고 뜨는 것 같다.
어쨋든 그렇게 해서 엑셀을 찾아보았는데..
필자는 엄청난 컴맹!
엑셀>데이터 에서
중복된 항목 제거로
일자와 링크아이디 열로 해주었는데...
...내 마음대로 되진 않았다.
엑셀로 중복된 것을 찾기에는 무리가 있다 생각했다.
(그리고 교통량 데이터에 중복 값이 있는지, 아니면 매칭 데이터에 중복 값이 있는지 알기 힘듦)
따라서 두 개를 합쳐 놓은 데이터 프레임(traffic_id)에서 무언갈 하기로 했다.
바로 duplicates()!
traffic_id.drop_duplicates()다음과 같이 하니까
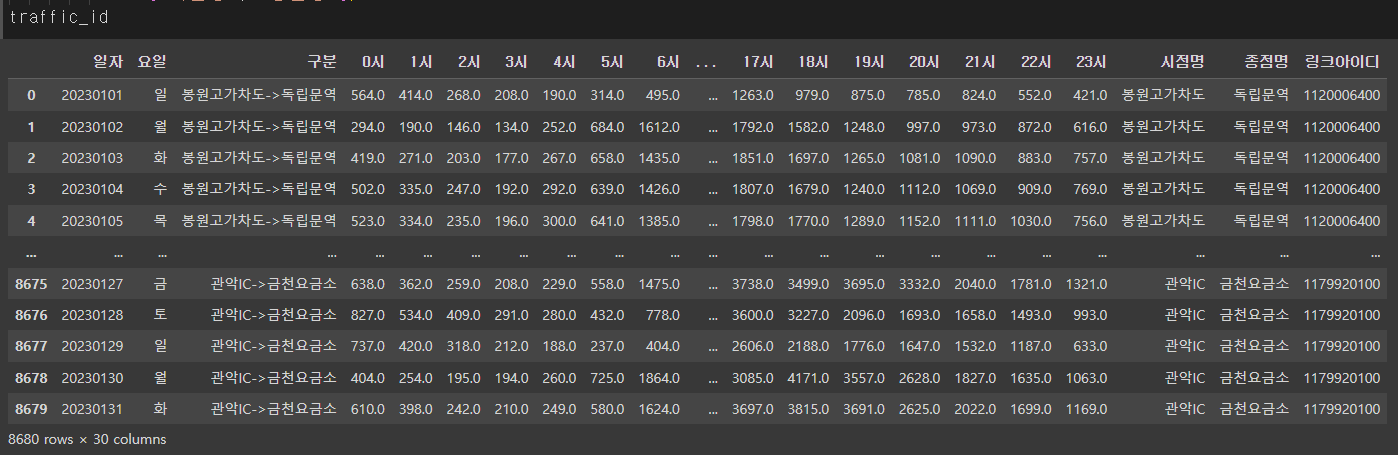
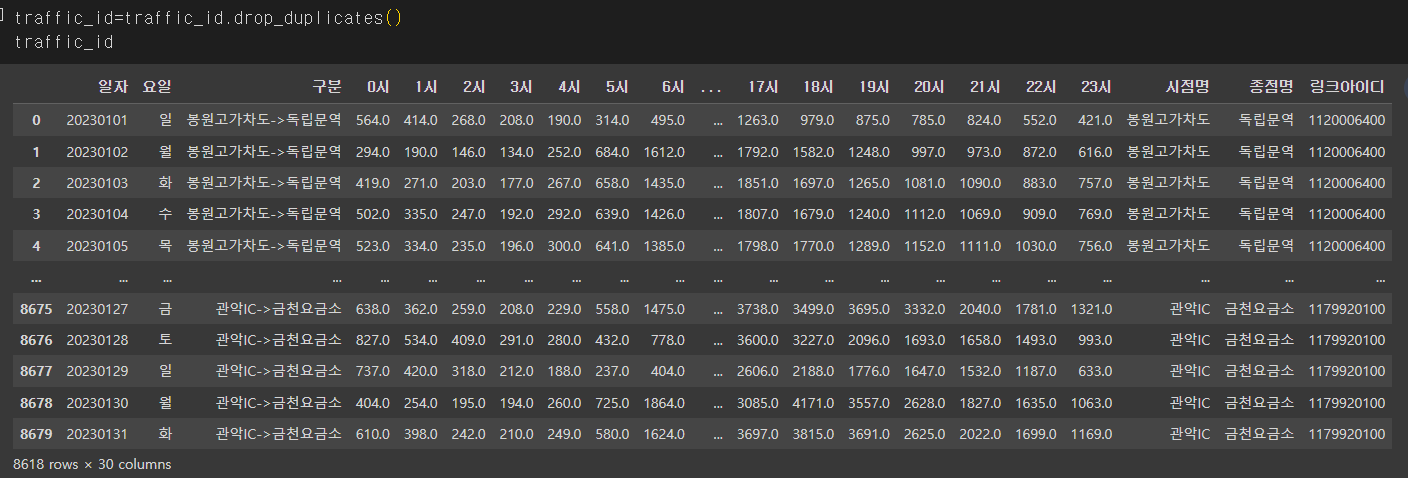
원래의 8618개의 행이 될 수 있었다!
이렇게 해서 중복된 행은 처리 완❗
데이터의 NaN값 처리
나 혼자 삽질할 때도 난값이 골칫거리였다.
그러다 정답을 듣게 됐는데 난값을 단독으로 지우는게 아니라 두 개의 데이터를 서로 이용하여 난값을 지울 수 있는 거였다.
부연설명하자면 이 각 데이터에 어딘가에 몇 개인지모를 난값이 있을텐데 반대로 두 속성에 모두 채워지는 인덱스가 있을 것이다.
그것을 따로 모은 다음 그 값으로 를 그려 최적의 와 의 값을 모델링을 구하는 것이다.
그렇게 먼저 두 값을 머지함수의 outer로 더해주었다.
(겹치는걸 기준으로 출력해주니까 머지사용)
이때 기준은 일자와 링크아이디로 해주었다.
df=pd.merge(velo3_fin,traffic_fin,on=['일자','링크아이디'], how='outer')
더 기준을 많이 해보았는데 그렇게 되었을 때 하나라도 맞지 않는 것이 있으면 새로운 행을 만들어 내어 부정확할 수도 있다.
이렇게 해서 NaN값을 dropna로 없애주면
df.dropna(axis=0)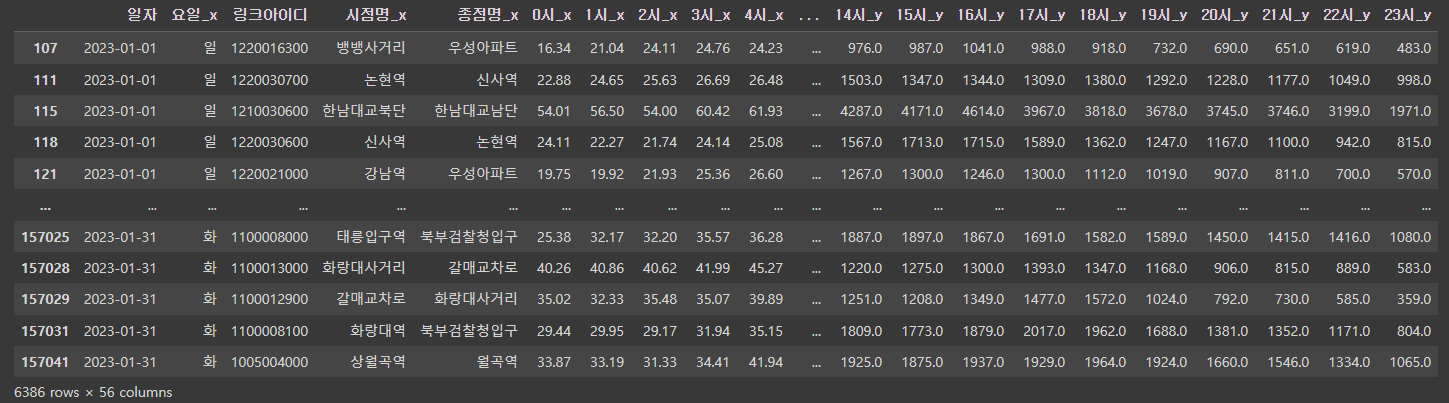
아주 잘 지워졌다..ㅎㅎ
쓸데 없는 열 지워주고
df=df.drop(['요일_x','요일_y', '시점명_x', '시점명_y', '종점명_x','종점명_y'],axis=1)마지막으로 두 개가 일치하게 붙여졌으니까 각각 속도와 교통량으로 데이터프레임을 나누어준다.
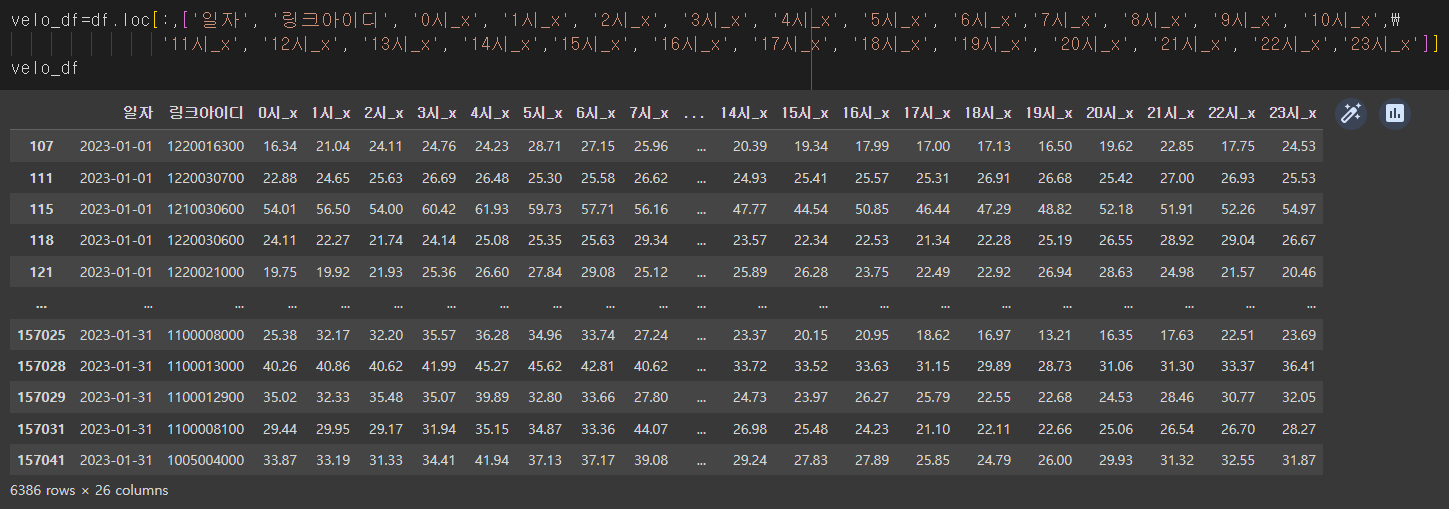
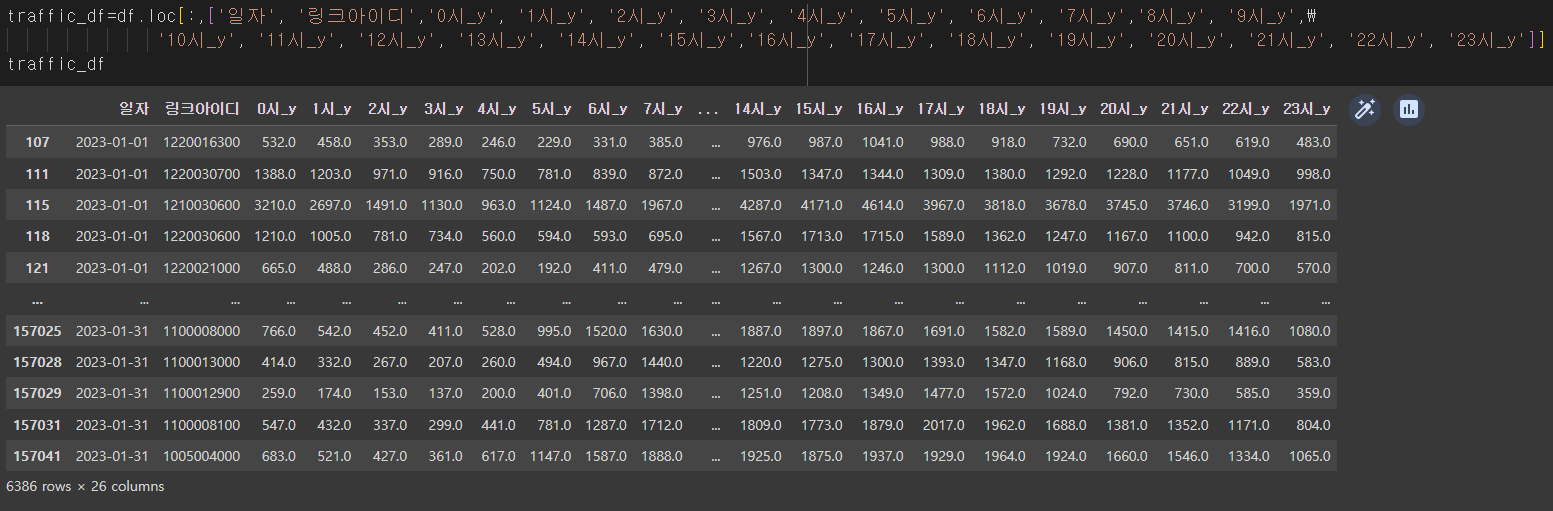
데이터 분할하기도 끝❗
이렇게 오늘까지 말씀 해주신 것 패드백 받아 진행했다.
조금 재밌을지도...ㅎㅎㅎ
