계속 예제로 공부하다가 아파트 분양가격 분석에서 이용할 수 있는 것들이 많은 것 같아 바로 숙제로 주어진 데이터를 열어보았다😯
내가 사용한 데이터는
its 국가교통정보센터
https://www.its.go.kr/
에서 받은 2023년 01월 서울시 교통량 데이터와 차량통행속도 데이터를 사용했다.
그리고 추가로 교통량 데이터에는 링크 아이디가 없어서 링크아이디와 시점명,종점명을 매칭해 놓은 데이터도 따로 받았다!
(이건 연구 과제 유출 금지라 첨부하지 않겠다.)
코드
먼저 업그레이드를 시켜주고
!pip install --upgrade xlrd구글 드라이브에 마운트 해준다.
from google.colab import drive
drive.mount('/content/drive')그리고 나에게 주어진 데이터를 불러왔다.
교통량 데이터
traffic = pd.read_excel("/content/drive/MyDrive/Colab Notebooks/data/01월 서울시 교통량 조사자료(2023).xlsx")교통량 데이터는 traffic이라고 명명해주었다.
데이터의 정보는 다음과 같다⤵
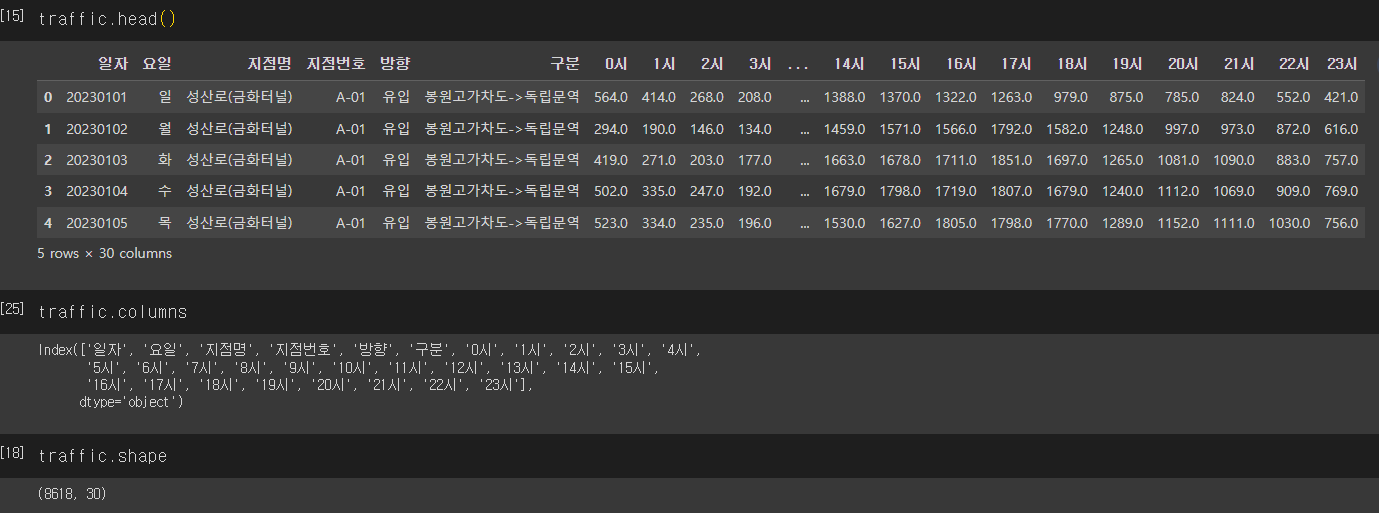
결측치도 출력해주었는데,
별 쓸모는 없어보인다..
통행속도 데이터
velo = pd.read_excel("/content/drive/MyDrive/Colab Notebooks/data/2023년 1월 서울시 차량통행속도.xlsx")통행속도 데이터는 velo라고 명명해주었다.
아래는 데이터의 정보이다⤵
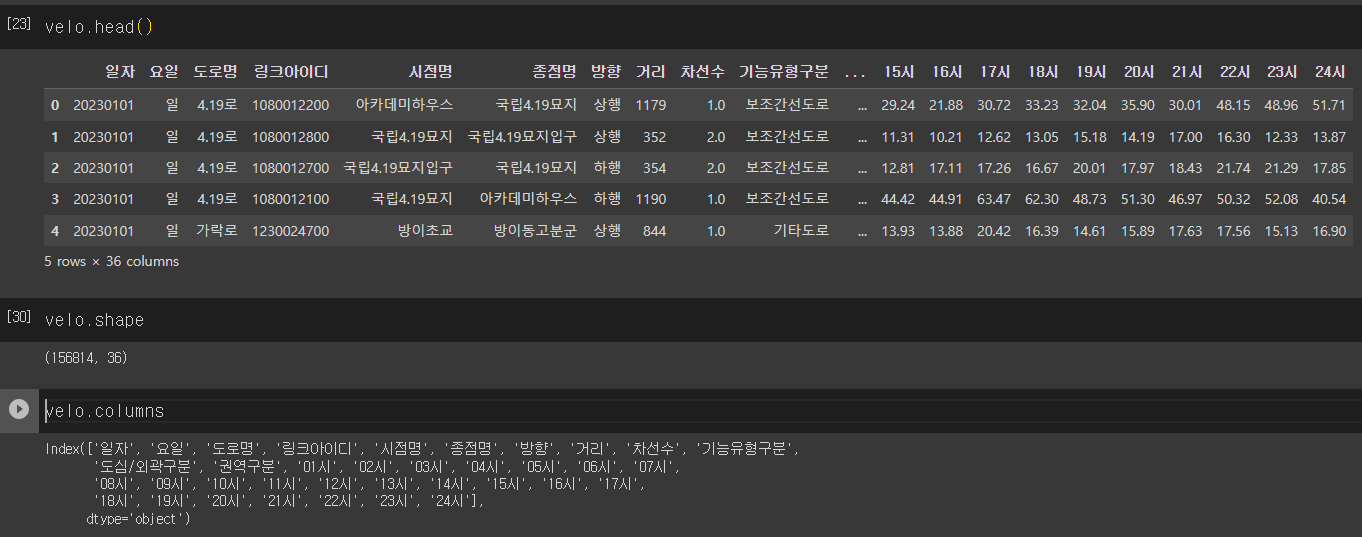
링크아이디 매칭 데이터
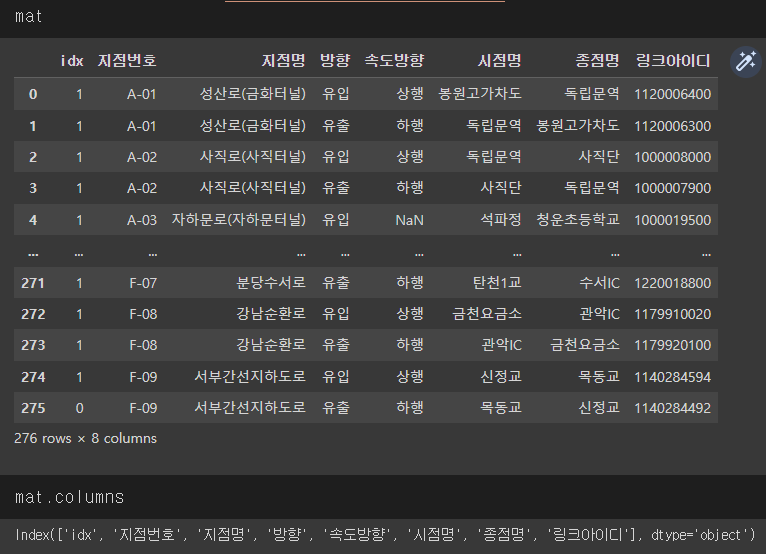
링크 아이디는 mat으로 명명했다.
이렇게 세 개의 데이터를 출력하고 생각을 해보았다.🤓
글로 정리하고 싶었는데 머리 속이 자꾸 엉켜서 손으로 적어가면서 정리했다.ㅎㅎ
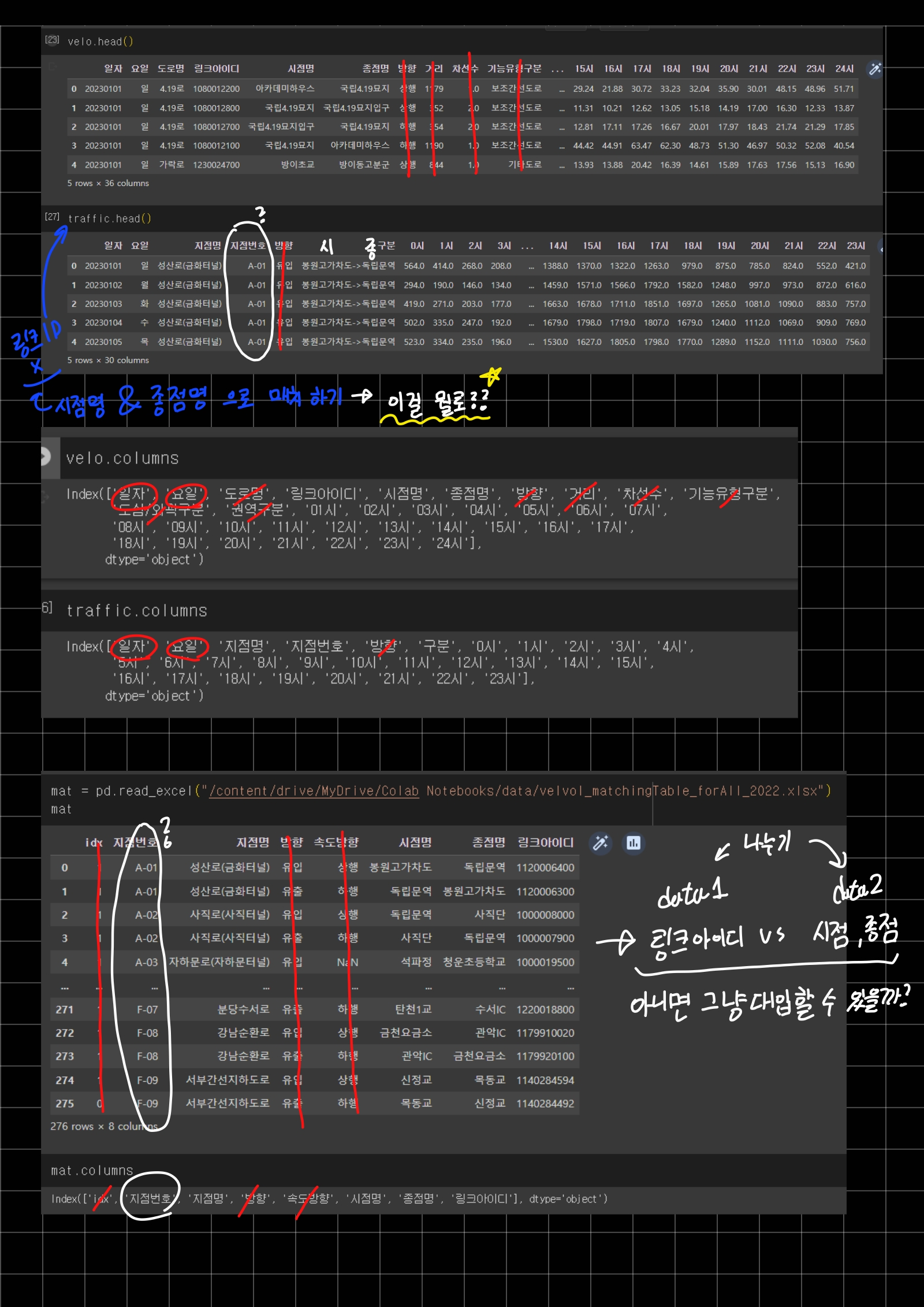

위의 두 개의 사진은 데이터를 가공하는 방법에 대해 고민한 흔적이다!
하는 방법은 어떻게든 구글하면 나올거라 방법에 대해서 집중적으로 생각해보았다.
내가 고민한 내용의 핵심은 링크아이디를 각 데이터에 부여하고 그것에 맞는 시점명&종점명을 넣고, 시간 컬럼을 같게 정리하는 것이었다.
1. 필요없는 열 제거
먼저 중요하지 않은 열을 drop()을 이용해서 제거했다.
- 교통량 데이터
traffic_del =traffic.drop(['지점명', '지점번호', '방향'], axis=1)대괄호에 제거할 것들을 넣고 axis=1를 꼭 붙여준다.
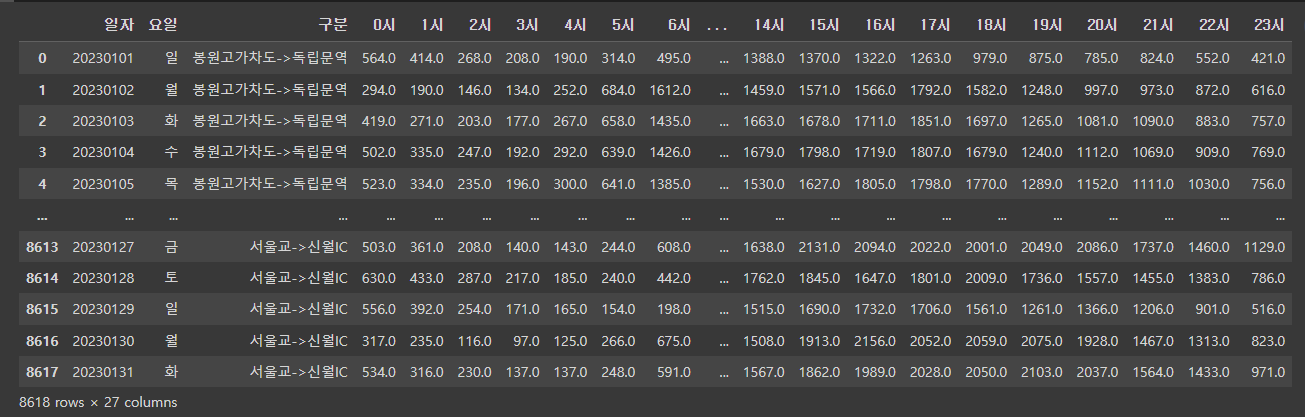
제거하면 다음과 같이 출력된다.
- 통행속도 데이터
velo_del = velo.drop(['도로명','방향','거리','차선수','기능유형구분','도심/외곽구분','권역구분'], axis=1)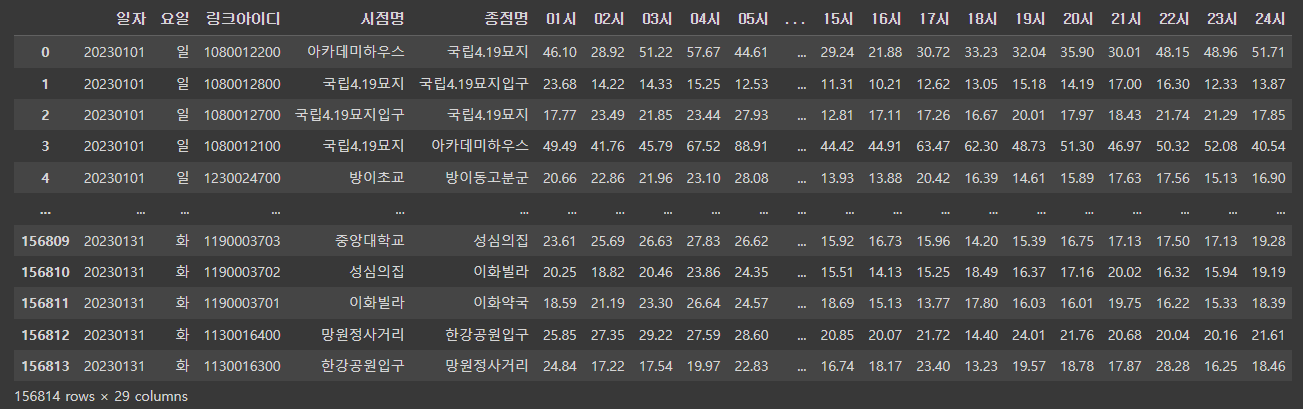
마찬가지로 잘 제거된 것을 볼 수 있다!
- 매치 데이터
mat_del = mat.drop(['idx', '지점번호', '지점명', '방향', '속도방향'], axis=1)
2.구분을 시점명과 종점명으로 나누기
여기는 연습했던 분양가격 분석에서 힌트를 얻어서 진행했다.
assort = "봉원고가차도->독립문역"def parse_start(assort) :
start = assort.split("->")[0]
return str(start)
y = parse_start(assort)
print(type(y))
y
데이터 타입(str)과 y값인 봉원고가차도가 성공적으로 출력됐다!!
def parse_fin(assort) :
fin = assort.split("->")[-1]
return str(fin)
parse_fin(assort)독립문역도 잘 출력됐다.😆😆
함수의 성능을 확인하고만든 함수를 데이터프레임에 적용해주었다.
traffic_del["시점명"] = traffic_del["구분"].apply(parse_start)구분에서 시점을 따로 빼내서 시점명이라는 컬럼을 새로 만들었다.

맨끝에 시점명이 새로 생겼다..!😲
마찬가지로 종점명도 빼내서 만들어주었다.
traffic_del["종점명"] = traffic_del["구분"].apply(parse_fin)
종점명도 잘 만들어졌다ㅎㅎ
mat 데이터 대입
traffic_id = pd.merge(left=traffic_del,right=mat_del,how='inner',\
on = ['시점명', '종점명'])내부 컬럼이 같으므로 merge()함수를 사용했다.
(링크아이디 = 시점명 + 종점명 같은느낌?)
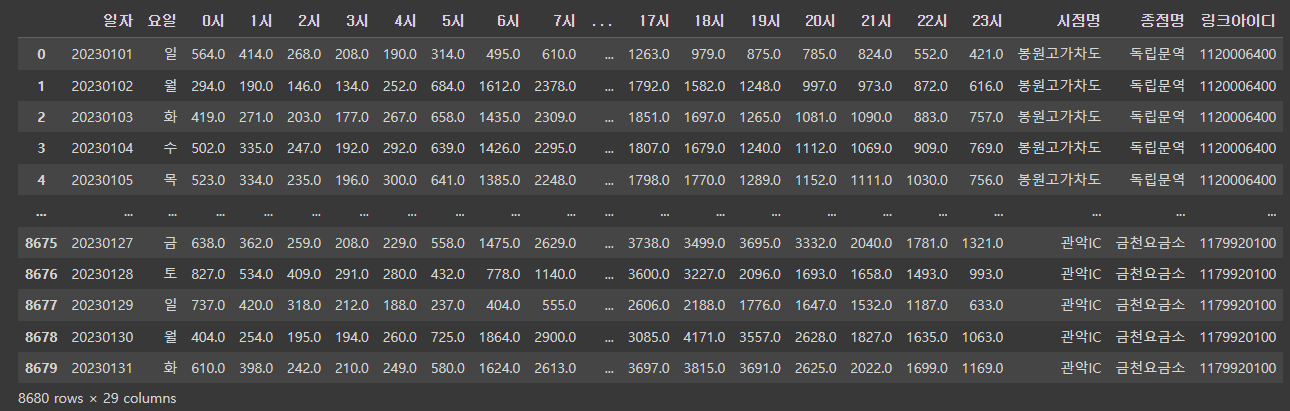
매치 데이터가 교통량을 잘 매치된 것 같다!
4.칼럼 이름 바꾸기(시간)
traffic데이터에는 0시,1시 이렇게 되어있어서 velo데이터의 이름도 맞춰주었다.
velo_del.rename(columns={"01시":"1시","02시":"2시","03시":"3시","04시":"4시","05시":"5시","06시":"6시","07시":"7시","08시":"8시","09시":"9시","24시":"0시"},inplace=True)rename사용!

컬럼 이름이 아주 잘 바뀌었다ㅎㅎ😀
5. 컬럼 순서 맞추기
두 데이터의 컬럼의 종류는 다 맞춰졌지만 조금 중구난방이라 reindex()를 이용해서 순서를 바꾸어주었다.
velo_fin = velo_del.reindex(['일자', '요일', '링크아이디', '시점명', '종점명','0시','1시', '2시', '3시', '4시', '5시', '6시',\
'7시', '8시', '9시', '10시', '11시', '12시', '13시', '14시', '15시', '16시','17시', '18시', '19시', '20시', '21시', '22시', '23시'],axis=1) 
traffic_fin = traffic_id.reindex(['일자', '요일','링크아이디','시점명', '종점명','0시', '1시', '2시', '3시', '4시', '5시', '6시', '7시', '8시', '9시',\
'10시', '11시', '12시', '13시', '14시', '15시', '16시', '17시', '18시', '19시', '20시', '21시', '22시', '23시'], axis=1)
인덱스 번호로 할 수도 있었지만 컬럼 이름이 숫자라 헷갈릴 것 같아서 그냥 하나씩 지정해주었다.
.
.
.
.
.
.
열 정리는 모두 끝났다!
처음으로 내 스스로 고민해보고 다듬어보았다.
생각보다 내가 생각한 대로 바로바로 돼서 좀 쎄함을 느끼지만 그래도 뿌듯하다><
응애 나 파이썬도 제대로 배운 적 없는 파린이👶-
조금씩 성장해간다~!!
