
저번에는 파일의 형태도 같지도 않은 두 개를 열심히 더해만 보았다❕😂
그래도 다 피가 되고 살이 될 과정이니까...시간이 아깝다는 생각은 안한다!
파일 형태를 변경해야하는데 두 가지 선택지가 있었다.
- 형태를 변경해주는 홈페이지에서 하기
- 코딩으로 변경해주기
첫 번째는 아마 잘못하면 컴퓨터에 바이러스가 깔릴 수도 있어서 두 번째 방법을 채택하기로..!
이 블로그를 참고했다!
LINK_ID가 있는 데이터가 shp파일이라 이것을 기준으로 바꾸어 주었다.
import glob
import gcgdf=gpd.GeoDataFrame.from_file("/content/drive/MyDrive/Colab Notebooks/data/[2023-02-10]NODELINKDATA/MOCT_LINK.shp",encoding='CP949')gdf로 불러와주고
new_file_name = "sample.csv"
gdf.to_csv(f"/content/drive/MyDrive/Colab Notebooks/data/{new_file_name}", encoding='utf8', index=False)지정해준 경로에 csv파일로 변경해서 저장해주었다.

짠!
그리고 삭제해주어서 메모리 정리를 해준다
del gdf #메모리 정리
gc.collect()그리고 매핑 정보도 엑셀이라 바꾸어준다.
matlink_csv = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/data/20210330_매핑정보.csv",index_col = 0) index_col = 0를 입력해주면 출력되는 데이터 프레임이 0부터 시작한다.
(저것 없이 출력하니까 unnamed:0 이라는 행이 출력되더라😙)
두 개의 데이터가 모두 같은 형태로 해주었으니까 저번에 해준 코드를 다시 실행시켜본다.
link_in_link = list(link_csv['LINK_ID'].unique())
mapping_data= matlink_csv.loc[matlink_csv['표준링크아이디'].isin(link_in_link)]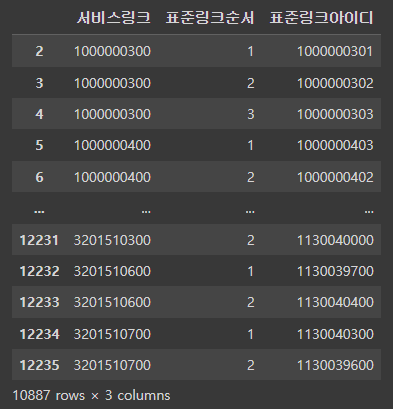
오호라 10887개의 행이 살아남는구나.
이제 한번 합쳐보면
pd.merge(link_csv,matlink_csv,left_on=['LINK_ID'],right_on=['표준링크아이디'],how='left')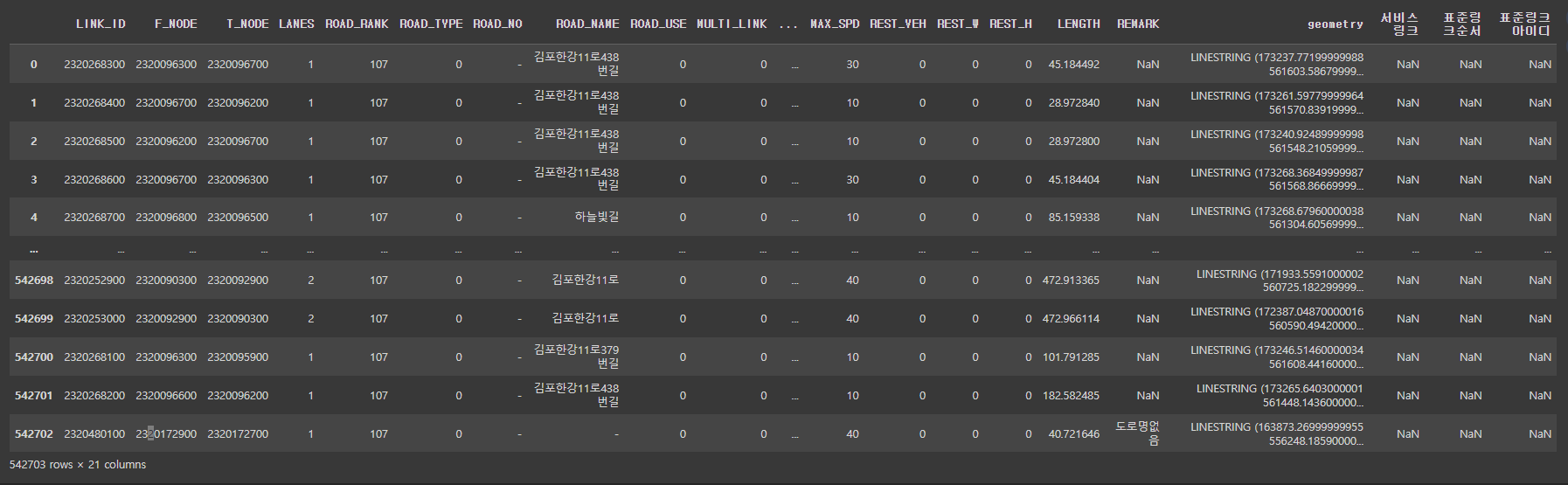
'link_csv'데이터와 열의 개수가 같아 잘 들어간 것 같다.
그리고 NaN값을 지워주면~?
test.dropna(subset=['표준링크아이디'], how='any', axis=0).reset_index(drop=True, inplace=False)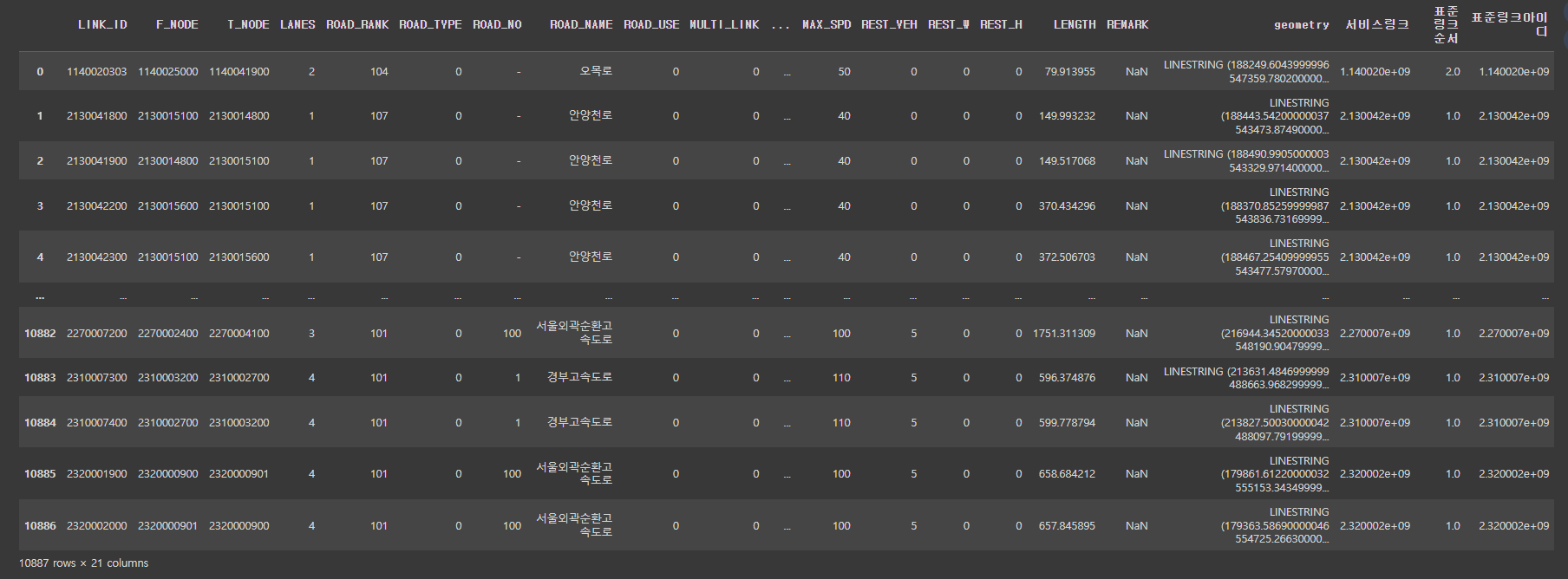
똑같이 10887개가 잘 매칭된 것을 확인할 수 있다❗
reset_index(drop=True, inplace=False)는 열을 0부터 시작하게 해주는 것
일단 하긴 해봤는데 사실 맞는 지는 확실하지가 않다.
서비스링크, 표준링크 등 용어 개념에 대한 이해가 조금 부족한 것 같아서 다음엔 더 공부하고 다른 컬럼들도 공부하려 어떤 것을 남겨야할지 고민해봐야겠다🤤

비전공자 주인장 일하느라 방치