Bag of Words & Word Embeddding
추천 시스템을 공부하면서 예전부터 추천과 NLP는 유사한 부분들이 많다고 생각했었다. 그래서 한번 NLP 공부를 해보고 싶다는 생각을 했었고 이번 부캠 강의를 이용해 NLP를 한번 공부해보고자 한다.
00. 학습 내용
- NLP의 Trends
- Bag of Words
- Word Embeddding
01. NLP의 Trends
- Word2Vec이나 GloVe 등과 같은 알고리즘을 이용하여 단어를 Vector로 표현할 수 있음
- RNN-family model(LSTM, GRU)들은 단어의 Vector를 인풋으로 사용하며, 이 모델들은 NLP Task를 해결하기 위한 주요 architecture들임
- attention 기법과 Transformer의 등장으로 주요 NLP Task의 전반적인 성능이 향상됨
- Transformer가 등장하기 전에는 각 NLP Task 마다 맞춤 모델을 만들어 사용했지만, Transformer가 등장한 후에는 Transformer를 기본 베이스로 하여 매우 큰 모델을 만들어서 각 NLP Task에 적용함(BERT, GPT-3 등)
- self-supervised training등을 이용하여 pre-trained 모델을 만들고 본 모델을 transfer learning을 하는 방법이 많이 사용됨
- 현재 NLP Task는 많은 데이터, 큰 모델을 활용하는 것에 중점이 맞춰져 있어서 제한된 GPU 자원을 가지고 연구를 하는 것에는 많은 어려움이 있으며, 이러한 이유 때문에 거대기업이 주 NLP Task를 리드해나가는 중임
02. Bag of Words
- Bag of Words는 단어들의 순서를 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하여 텍스트 데이터를 표현하는 방법을 말함
1) Bag of Words 생성 방법
- 우선 주어진 전체 sentence에서 unique한 word를 추출하여 Vocabulary를 생성함
- 이제 sentence의 수 x unique한 word의 수로 이루어진 행렬에서 각 sentence안에 들어있는 단어의 빈도 수를 계산하면 Bag of Words가 생성됨
2) NaiveBayes Classifier를 이용한 Document Classification

- 위 그림과 같은 데이터 셋이 주어졌다고 했을 때 NaiveBayes Classifier를 이용하여 Test 데이터의 class를 예측하는 문제를 풀어보도록 하겠음
- NaiveBayes Classifier는 문서(d)가 주어졌을 때 해당 클래스(c)가 등장할 확률인 사후 확률을 최대화하는 문제(MAP)라고 볼 수 있음
- 위를 수식으로 표현하면 argmax P(c|d) 로 표현할 수 있으며, 해당 식은 Bayes Rule에 위하여 argmax (P(d|c) * P(c)) / P(d) 로 표현됨
- 여기서 P(d) 문서의 확률 값은 c에 상관 없이 모두 일정하기 때문에 상수로 볼 수 있고, 이에 P(d)는 생략할 수 있음
- 따라서 최종 수식은 argmax P(d|c) * P(c) 로 표현할 수 있음 (결국은 likehood와 사전 확률만을 사용하여 사후확률을 최대하 하는 문제임)
- P(d|c)는 c가 주어졌을 때 모든 문서의 확률 값이며, 이는 동일한 c를 가진 데이터들의 해당 word의 빈도 수 / 동일한 c를 가진 데이터들의 unique한 word의 수로 표현할 수 있음
- P(c)는 해당 클래스의 개수 / 전체 데이터의 개수로 표현할 수 있음
- 따라서 Test 데이터의 각 클래스에 해당하는 사후 확률은 다음과 같이 계산됨(동일한 c에 있는 d의 단어의 개수는 CV는 14개, NLP는 10개임 / 각 사건은 독립이기 때문에 곱셈으로 계산함)
- NLP = 2/4 1/14 1/14 1/14 1/14 = 0.0001
- CV = 2/4 1/10 2/10 1/10 1/10 = 0.00001
- 따라서 계산된 사후 확률에 따라서 해당 Test 데이터의 class는 NLP로 예측될 것임
- 그런데 본 방식은 Train 데이터에 등장하지 않은 단어가 Test 데이터에 출현하게 되면 해당 값을 0으로 처리해서 아무리 유사한 단어라도 값이 0이 된다는 단점이 존재함
03. Word Embeddding
- Word Embeddding은 단어를 벡터로 표현하는 방법임
- 유사한 단어는 유사한 vector representation을 가짐으로 서로 가깝게 위치하고, 유사하지 않은 단어는 반대로 서로 멀게 위치함
- Word Embeddding 방법 중 가장 대표적인 방법은 Word2Vec임
- Word2Vec은 유사한 단어는 동시 출현 빈도 또한 높을 것이다라는 가정을 통해서 만들어진 모델임
- 그런데 본 방식들은 단순히 동시 출현 빈도만을 고려하기 때문에 좋다, 싫다와 같이 의미는 서로 유사하지 않지만 동시에 출현하는 문맥이 비슷하다면 서로 비슷한 위치에 맵핑이 된다는 단점을 가짐(단어의 의미적 요소를 다르게 생각한다면 두 단어 또한 유사하다고 볼 수도 있을 것임)
1) Word2Vec - CBOW
- Word2Vec의 CBOW 방식은 주변 단어를 가지고 중심 단어를 예측하는 방식임
- 우선 주어진 모든 문장 속에서 unique한 단어를 구하고, 해당 단어의 index를 설정함(본 index가 곧 one-hot vector 상의 자신의 위치이며, 분류 시에 해당하는 값의 위치임)
- 우선 주어진 문장을 1씩 옆으로 움직이면서 중심 단어를 설정하고, 해당 중심 단어를 기준으로, 앞뒤로 설정한 Window 단위로 split 하여 input 데이터를 생성함
- 주변 단어를 각각 One-hot Vector로 형성하고, W1(unique한 단어의 수 x embedding-size)와 내적을 하여 주변 단어들의 모든 Vector를 생성
- 주변 단어들의 모든 Vector를 sum한 후에 주변 단어의 개수로 평균을 내어 주변 단어들의 모든 정보가 담긴 하나의 Vector를 생성
- 생성된 Vector를 W2(embedding-size x unique한 단어의 수)와 내적 한 후 해당 vector를 softmax를 취하여 probability Vector를 생성함
- 생성된 probability Vector를 cross entropy loss를 사용하여 중심 단어를 제대로 예측하는 방식으로 모델을 학습시킴
- 모델 학습 후에 W1이 단어들의 Embeddding임
2) Word2Vec - Skip-Gram
- Word2Vec의 Skip-Gram 방식은 중심 단어를 가지고 주변 단어를 예측하는 방식임
- input 데이터를 생성하는 방식 까지는 CBOW 방식과 동일함
- 중심 단어를 One-hot Vector로 형성하고, W1(unique한 단어의 수 x embedding-size)와 내적하여 중심 단어의 정보가 담긴 Vector를 생성
- 해당 벡터를 W2(embedding-size x unique한 단어의 수)와 내적 한 후 해당 vector를 softmax를 취하여 probability Vector를 생성함
- 생성된 probability Vector를 모든 주변 단어에 대하여 cross entropy loss를 사용해 주변 단어를 제대로 예측하는 방식으로 모델을 학습시킴
- 모델 학습 후에 W1이 단어들의 Embeddding으로 사용됨
- Skip-Gram은 모델 Update 시에 사용되는 주변 단어는 모두 독립적인 단어라는 가정으로 접근하기 때문에 CBOW 보다 업데이트에 사용되는 데이터의 개수가 많음(하나의 중심단어를 기준으로 CBOW는 1번만 업데이트 되지만, Skip-Gram은 주변 단어의 개수 만큼 업데이트 됨)
- 이러한 이유 때문에 Skip-Gram이 CBOW 보다 더 좋은 성능을 보인다고 함
3) GloVe
- 우리가 앞에서 다룬 Word2Vec 모델의 단점은 단순히 빈도 수 만을 고려했기 때문에, 빈도수가 많은 단어일 수록 더욱더 중요하게 생각한다는 점이 있음
- 하지만 어떻게 보면 단순히 빈도수 보다 두 단어 간의 동시출현확률이 높은 단어가 더욱더 유사한 단어일 수 있을 것임
- 예를 들어 a와 100번 출현한 단어 c와 10번 출현한 단어 d가 있을 때, 단순히 빈도수 관점으로 보면 c가 더 중요해 보임, 하지만 여기서 전체 등장 회수를 고려했을때 c는 100000번 출현한 단어이고, d는 딱 10번만 출현했던 단어라면 a에게 d 단어가 더 중요한 단어일 것임
- 이처럼 단어의 동시출현확률을 고려하여 단어를 임베딩 하는 모델이 바로 GloVe임
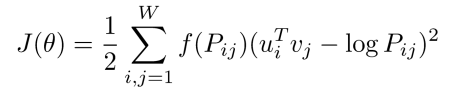
- GloVe의 Loss함수는 위와 같으며, 이는 임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시 등장 확률이 되도록 만드는 것이라고 말할 수 있음

Machine Learning Engineer at Konan Technology